
💡 spaCy
spaCy 공식 사이트 설명이 nltk 라이브러리보다 깔끔하고 이해하기 쉽고 편한 것 같다.
Performance, 성능 및 속도
While NLTK returns results much slower than spaCy (spaCy is a memory hog!), spaCy’s performance is attributed to the fact that it was written in Cython from the ground up.
spaCy 설치하기(english)
pip install spacy
python -m spacy download en_core_web_sm아래처럼 사용할 수 있다.
import spacy
nlp = spacy.load("en_cor_web_sm")❓ What's spaCy?
python NLP를 위한 오픈소스 라이브러리이다.
❗spaCy는 research software가 아니다!
이는 교육 및 연구를 위해 만들어진 NLTK 또는 CoreNLP와는 상당히 다르게 설계되어 있다. 주요 차이점은 spaCy가 integrated 하고 opinionated라는 것이다. 즉, 사용자 입장에서 여러 알고리즘 중에서 선택하도록 요청하지 않고, "menu"를 작게 유지하며 더 나은 성능을 제공한다.
📌 Features
- Tokenization : 텍스트를 단어로, punctuation marks 등으로 토크나이징 한다.
- Part-of-speech(POS) Tagging : 품사 태깅
- Dependency Parsing : 주제 또는 object와 같은 개별 token 간의 관계를 설명하는 syntactic dependency 레이블을 지정한다.
- Lemmatization : 단어의 원형(base form)을 준다. 예를 들어 "was"의 lemma는 "be"이고, "rats"의 lemma는 "rat"이다.
- Sentence Boundary Detection(SBD) : 문장 분리
- Named Entity Recognition(NER) : 사람, 회사 또는 위치처럼 이름이 부여된 "실제" 개체에 레이블을 지정한다.
- Entity Linking(EL) : Disambiguating textual entities to unique identifiers in a knowledge base.
- Similarity : 단어, 텍스트 범위 및 문서를 비교하고 서로 얼마나 유사한지 비교한다.
- Text Classification
- Rule-based Matching
- Training
- Serialization
Statistical models
spaCy의 일부 기능은 독립적으로 작동하지만 다른 기능은 학습된 pipeline을 로드해야 linguistic annotation을 예측할 수 있다. (예를 들어 단어가 동사인지, 명사인지 여부)
pipeline 패키지는 크기, 속도, 메모리 사용량, 정확도 및 포함된 데이터가 다를 수 있다.
일반적으로 다음 구성 요소가 포함된다.
- Binary weights: POS tagger, dependency parser, named entity recognizer을 위함
- Lexical entries: 단어와 단어의 형태, 철자 등 문맥과 독립적인 속성
- Word vectors: 단어가 서로 얼마나 유사한지 확인할 수 있음
- Configuration options
📌 Linguistic Annotations
텍스트의 문법 구조에 대한 통찰력을 제고하는 다양한 linguistic annotationsㅇ을 제공한다.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_)전처리 되기 이전의 텍스트 데이터를 보존할 수 있게 사용 가능하다.
📌 Tokenization
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text)먼저, whitespace(공백) 기준으로 split한다. (text.split(' ') 처럼)
그 다음으로, tokenizer가 다음 두 가지를 확인하면서 토크나이징 한다.
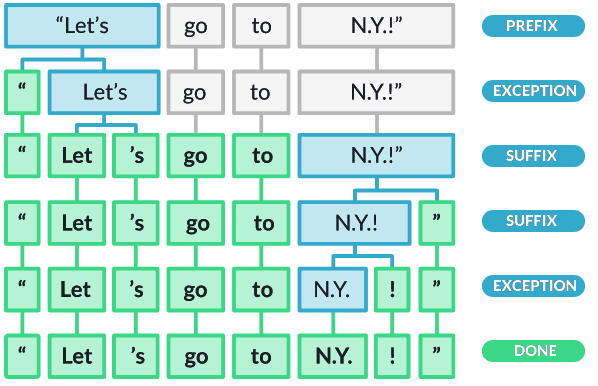
🔎1. substring이 토크나이저 예외 규칙과 일치하는가?
Tokenizer exception: 구두점 규칙이 적용될 때 문자열을 여러 토큰으로 분할(예를 들어 "don't"는 공백을 포함하지 않지만 "do"와 "n't"라는 두 개의 토큰으로 분할되어야 함)하거나, 토큰이 분할되지 않도록 하는("U.K"는 공백을 포함하지 않지만 항상 하나의 토큰으로 유지되어야 함) 특수한 경우 규칙이다.
🔎2. prefix, suffix 또는 infix를 분리할 수 있는가?
Prefix: Character(s) at the beginning, e.g. $, (, “, ¿.
Suffix: Character(s) at the end, e.g. km, ), ”, !.
Infix: Character(s) in between, e.g. -, --, /, ….
예를 들어 쉼표(,), 마침표(.), 하이픈(-) 또는 따옴표(")와 같은 구두점이다.
📖 Tokenization rules
토크나이저 커스터마이징 하기
📌 Part-of-speech, 품사 태깅과 Dependencies
parse와 tag을 할 수 있다. 여기서 학습된 pipeline과 statistical model이 사용되는 부분인데, 해당 텍스트 안에서 어떤 tag 혹은 label이 가장 likely 한지 spaCy가 predict 하게 해준다.
다른 NLP 라이브러리들처럼, spaCy도 메모리 사용량과 효율성을 높이기 위해 모든 string을 has values로 인코딩한다.
따라서 readable한 문자열 표현을 얻기 위해서는 아래처럼 _를 붙여야 한다.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
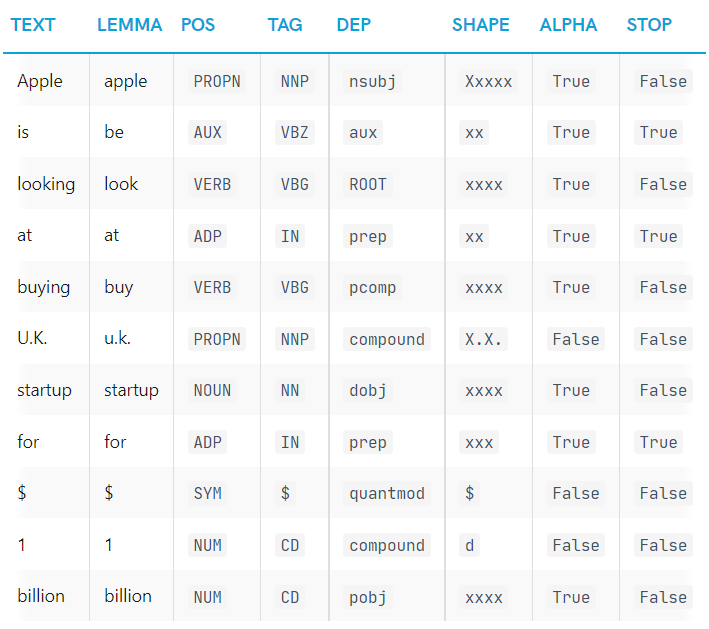
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)text: 원래 word 텍스트lemma: base form of the wordpos: Universal POS tagstag: detailed 품사 태깅dep: syntactic dependency, 토큰 간의 관계shape: word의 shape – 대문자, 구두점, 숫자is_alpha: 알파벳인지 여부is_stop: 불용어인지 여부
📖 Part-of-speech tagging and morphology
품사 태깅 민 rule-based 형태에 대해 더 자세히 알아보려면 아래 참고.
parse tree를 더 효과적으로 탐색하고 사용하는 방법 알아보려면 아래 참고.
pos tagging
using th dependency parse
📌 Named Entities
Named Entity란 사람, 국가, 제품 또는 책 제목과 같이 이름이 할당된 "실제 개체"이다.
여기서도 model의 prediction을 통해 Named Entity를 인식할 수 있다. statistical하고 example 기반으로 동작하기 때문에 항상 완벽하게 작동하는 것은 아니며, 사용 사례에 따라 튜닝이 필요하다.
doc의 ents로 접근할 수 있다.
import spacy
nlp = spacy.load("en_core_web_sm")
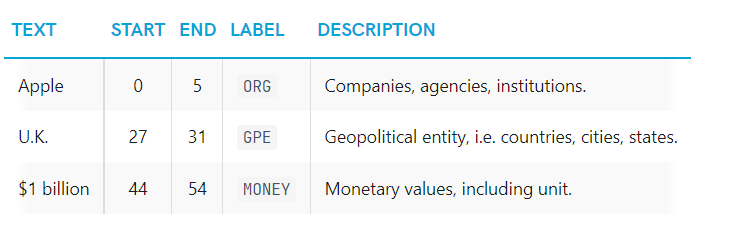
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)text: 원래 entity 텍스트start_char: entity의 시작 indexend_char: entity의 끝 indexlabel: entity 레이블, type이 뭔지.
📖 Named Entity Recognition
나의 entity를 추가하는 방법 & 모델의 entity prediction을 train하고 update 하는 방법을 알고 싶다면 아래 참고
named entity recognition
training pipelines
📌 Word vectors and similarity
Similarity, 즉 유사도는 word vectors 또는 word embedding의 비교를 통해 이루어진다.
단어 벡터 또는 단어 임베딩 예시는 아래와 같다.
array([2.02280000e-01, -7.66180009e-02, 3.70319992e-01,
3.28450017e-02, -4.19569999e-01, 7.20689967e-02,
-3.74760002e-01, 5.74599989e-02, -1.24009997e-02,
5.29489994e-01, -5.23800015e-01, -1.97710007e-01,
-3.41470003e-01, 5.33169985e-01, -2.53309999e-02,
1.73800007e-01, 1.67720005e-01, 8.39839995e-01,
5.51070012e-02, 1.05470002e-01, 3.78719985e-01,
2.42750004e-01, 1.47449998e-02, 5.59509993e-01,
1.25210002e-01, -6.75960004e-01, 3.58420014e-01,
# ... and so on ...
3.66849989e-01, 2.52470002e-03, -6.40089989e-01,
-2.97650009e-01, 7.89430022e-01, 3.31680000e-01,
-1.19659996e+00, -4.71559986e-02, 5.31750023e-01], dtype=float32)❗
sm으로 끝나는 모든 패키지는 compact하고 fast하게 만들기 위한 패키지로, word vectors가 제공되지 않으며 👉context-sensitive tensors만 포함한다. 즉,similarity()함수를 사용할 수 있지만 결과는 좋지 않으며 개별 토큰에는 할당된 벡터가 없다. 따라서 실제 단어 벡터를 사용하려면 더 큰 파이프라인 패키지를 다운로드해야 한다.- python -m spacy download en_core_web_sm + python -m spacy download en_core_web_lg
import spacy
nlp = spacy.load("en_core_web_md")
tokens = nlp("dog cat banana afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
RUNtext: 원래 entity 텍스트has_vactor: 해당 토큰이 vector 표현이 있는가?vector_norm: 토큰 벡터의 L2 norm 값is_oov: out-of-vocabulary
예를 들어 'dog'나 'cat'은 pipeline의 vocabulary에 포함되는 단어로 단어 벡터가 있지만, 'afskfsd'와 같은 단어는 out-of-vocabulary라서 0으로 구성된 300차원의 벡터로 표현된다. 즉 존재하지 않는 벡터라는 것. en_core_web_lg는 full vector 패키지로, 658k 의 벡터를 포함한다.
spaCy는 두 object의 similarity를 예측할 수 있다. 유사도 예측은 추천 시스템이나 flagging duplicates와 같은 작업에 사용될 수 있다.
물론, similarity는 주관적인 판단이다.
spaCy는 general-purpose 로서 'similarity'를 정의한다.
word vector은 Token.vector 로 사용 가능하다.
Doc, Span, Token, Lexeme 모두 .similarity 함수를 제공한다. 👉 similarity method
📝 Things to try
📌 1. Compare two different tokens and try to find the two most dissimilar tokens in the texts with the lowest similarity score (according to the vectors).
📌 2. Compare the similarity of twoLexemeobjects, entries in the vocabulary. You can get a lexeme via the.lexattribute of a token. You should see that the similarity results are identical to the token similarity.
doc1 = nlp("~")
doc2 = nlp("~")
print(doc1.similarity(doc2))💡 What to expect from similarity results
유사도 계산 관련하여 고려해야 할 중요한 사항들을 확인하자.
- ✨ Similarity에 대한 객관적인 정의는 없다.
예를 들어 "I like burgers"와 "I like pasta"가 similar한가? 라고 물어보면, 1) 음식 선호도에 대해 이야기하므로 비슷하다 혹은 2) 다른 음식에 대해 이야기하기 때문에 상당히 다르다 라고 판달할 수 있다.
- ✨
Doc와Span개체의 similarity는 기본적으로 토큰 벡터의 평균이다.
예를 들어 "fast food"에 대한 벡터는 "fast"와 "food"에 대한 벡터의 평균이며, 반드시 "fast food"라는 문구를 대표하지 않는다는 것을 의미한다.
- ✨벡터 평균화는 여러 토큰의 벡터가 단어의 순서에 둔감하다는 것을 의미한다.
다른 문구로 동일한 의미를 표현하는 두 개의 문서는 동일한 단어로 다른 의미를 표현하는 두 개의 문서보다 낮은 유사성 점수를 반환한다.
💡Tip: Check out
sense2vec
sense2vec는 spaCy를 기반으로 개발된 라이브러리다.
📖Word vectors
word vector, customize하고 자신의 vector을 spaCy에 로드하는 방법을 알려면 아래를 참고.
(https://spacy.io/usage/linguistic-features#vectors-similarity)[https://spacy.io/usage/linguistic-features#vectors-similarity]
📌 Pipelines
nlp를 호출하면, spaCy는 먼저 Doc object를 생성하기 위해 토크나이징을 한다. Doc은 그 다음에 processing pipeline 에 해당하는 여러 단계를 거치며 처리된다.
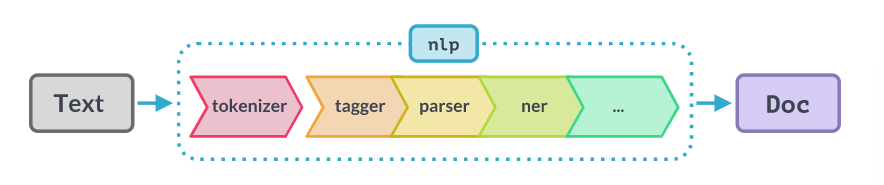
학습된 pipeline을 사용하는 pipeline은 🔨tagger, 🔨lemmatizer, 🔨parser, 그리고 🔨entity recognizer을 포함한다. 각 pipeline 컴포넌트는 처리된 Doc을 return하여 다음 컴포넌트로 전달해준다.
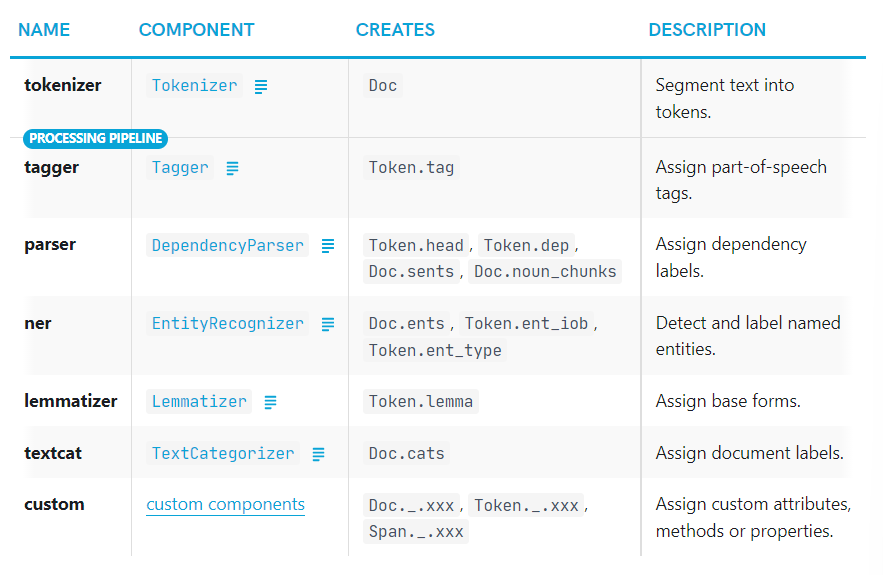
- tokenizer: Tokenizer
- tagger: Tagger
- parser: DependencyParser
- ner: EntityRecognizer
- lemmatizer: Lemmatizer
- textcat: [TextCategorizer](https://spacy.io/api/textcategorizer
- custom: custom components
processing pipeline의 성능은 언제나 이 컴포넌트들에 의해 좌우된다. 예를 들어, named entity 인식을 위한 pipeline으 경우, entity 레이블의 prediction(예측)을 가능하게 하는 statistical 모델과 weights들과 함께 🔨학습된 name entity recognizer 컴포넌트가 필요하다.
이것이 바로 pipeline이 각 컴포넌트들과 설정을 config에서 설정하는 이유다.
❓pipeline의 컴포넌트들의 순서는 영향을 미치는가?
❗🔨tagger 혹은 🔨parser처럼 statistical 컴포넌트들은 독립적이고 서로 데이터를 공유하지 않는다.
- 예를 들어, 🔨named entity recognizer은 🔨tagger 혹은 🔨parser에서 설정된 feature를 사용하지 않는다. 즉, 컴포넌트들의 순서를 바꾸거나 pipeline에서 특정 컴포넌트를 없애도 된다는 의미고, 이러한 변화는 다른 컴포넌트들에 영향을 주지 않는다.
❗하지만, Tok2Vec이나 Transformer와 같은 컴포넌트들은 "token-to-vector"을 공유할 수 있다. (Shared embeeding layers 참고하기.)
❗Custom 컴포넌트들 또한 다른 컴포넌트들에 의해 세팅된 annotation에 의해 좌우될 수 있다.
- 예를 들어, 🔨custom lemmatizer은 pos tag를 필요로하므로, 🔨tagger 컴포넌트가 적용된 이후에만 작동할 것이다.
🔨parser는 미리 정의된 sentence boundaries를 고려할 것이므로, 만약 pipeline의 이전의 컴포넌트가 이를 세팅하면, dependency 예측은 또 달라질 것이다.
비슷하게 만약 🔨statistical entity recognizer EntityRuler을 이전 혹은 이후에 추가하느냐에 따라 달라질 것이다. (이전 - 🔨entity recognizer 는 존재하는 entities를 사용하여 prediction을 수행하라 것이다.)
EntityLinker의 경우, (named entities를 knowledge base ID로 resolve함) EntityRecognizer 컴포넌트 이후에 수행되어야 할 것이다.
❓Why is the tokenizer special?
tokenizer "special"한 컴포넌트로, regular pipeline의 부분이 아니다. 따라서 nlp.pipe_name에도 없다.
그 이유는 1) tokenizer은 오직 하나만 있을 수 있고,
2) 다른 pipeline 컴포넌트들은 👉Doc을 입력으로 받고 처리된 object를 return하지만, tokenizer은 👉문자열, string을 입력으로 받고 Doc으로 바꿔주기 때문이다.
💡그럼에도 tokenizer을 customize 할 수 있다.
Tokenizer class from scratch 혹은 entirely custom function를 통해 가능.
📖 Processing pipelines
processing pipeline이 자세하게 어떻게 동작하는지, 또한 어떻게 컴포넌트들을 enable/disable하는지, 자신의 pipeline을 어떻게 만드는지 알고 싶다면 language processing pipelines 참고하기.
📌 Architecture
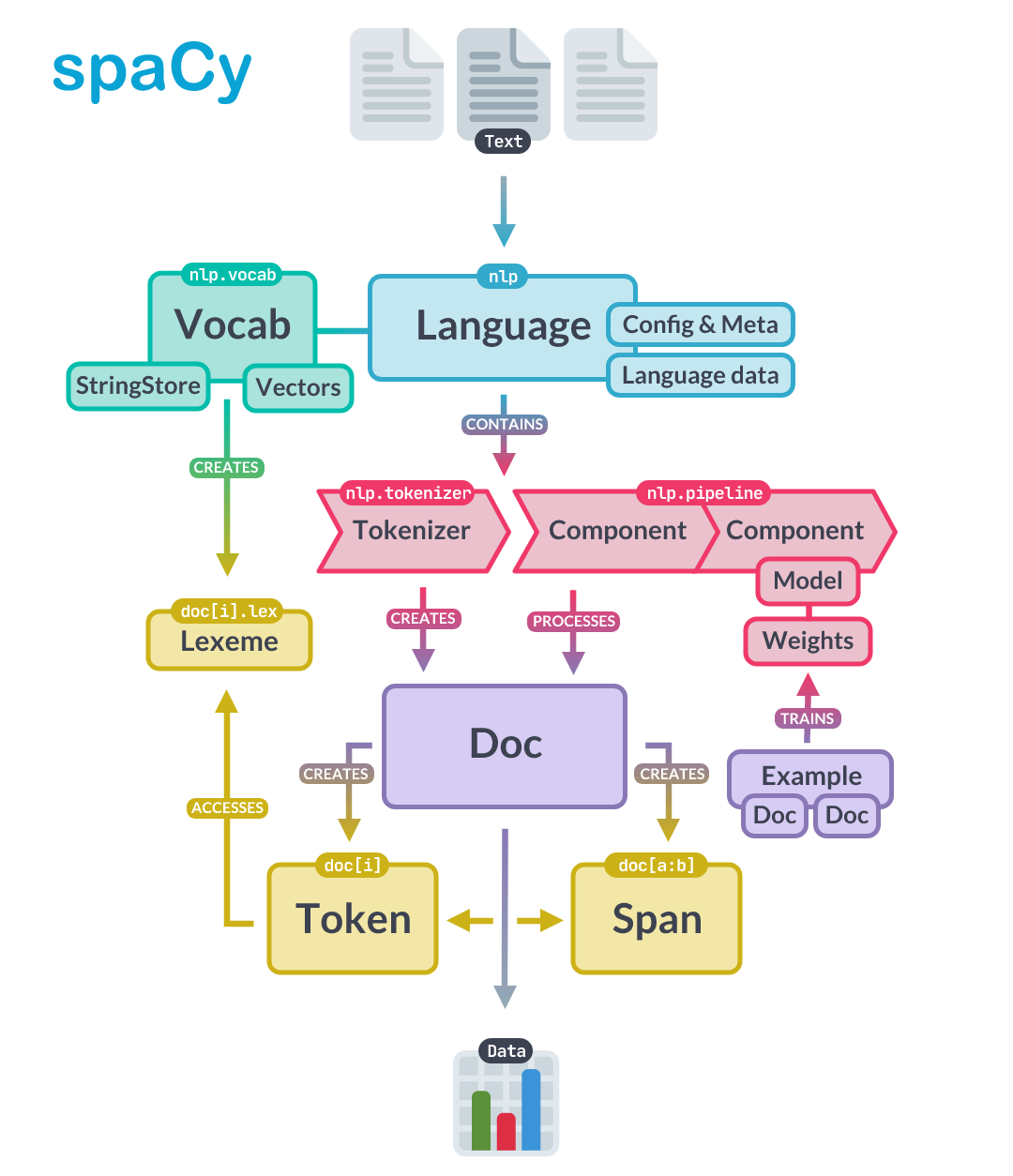
spaCy의 주요 데이터 구조는 Language 클래스와 Vocab, 그리고 Doc object이다.
Language: 텍스트를 처리하여Docobject(nlp에 저장되더 있음)로 만든다.Doc: sequence of tokens와 annotation을 가지고 있다.Vocab: word vector과 lexical attributes가 있다. 여러 개의 데이터 복사본을 가지고 있지 않고, 이로써 메모리 저장공간을 확보하며 single source of truth을 보장한다.
📌Text annotation: Doc obejct가 data를 가지고 있고, Span과 Token이 으로 접근 가능하다.
doc = nlp("Give it back! He pleaded.")
# span
span = doc[1:4]
assert [t.text for t in span] == ["it", "back", "!"]
# token
token = doc[0]
assert token.text=="Give"✨Doc object는 👉Tokenizer에 의해 만들어지고, pipeline의 컴포넌트들에 의해 modified in place 된다.
✨Language object는 이 컴포넌트들을 coordinate한다.
raw text를 pipeline으로 보내주고, 📝annotated document를 return해준다. training과 serialization도 orchestration한다.
📝 Container objects

📝 Processing Pipeline
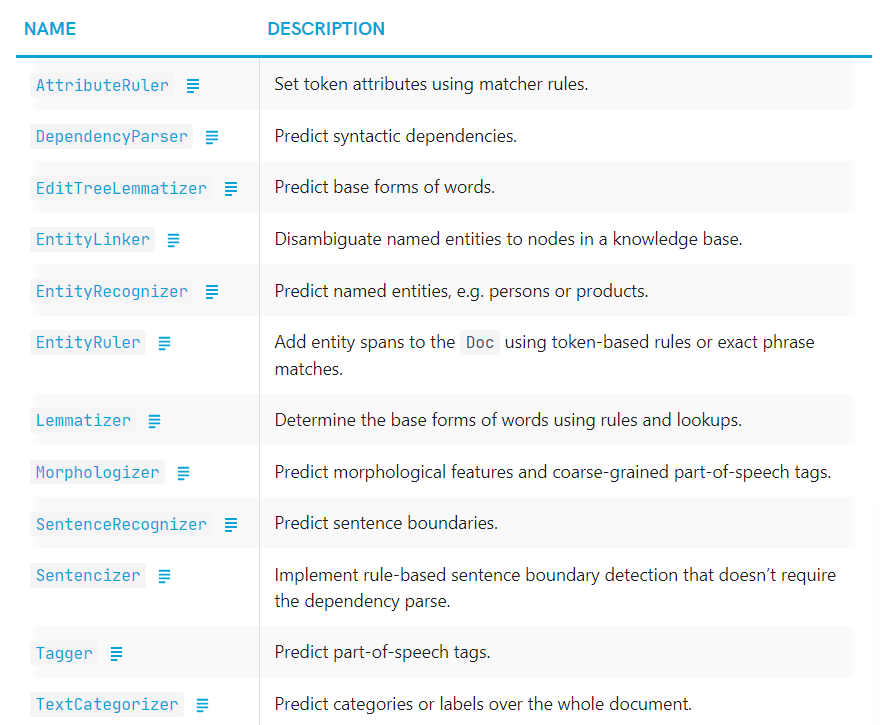
processing pipeline은 Doc에서 호출된 하나 이상의 pipeline components로 이루어진다. Language.add_pipe로 추가 가능하다. statistical model이나 trained weights, 또는 Doc에 rule-based modifications를 만들 수 있다.
spaCy는 아래처럼 🔨built-in components들을 제공한다.

📝 Matchers
Doc object에서 찾고자하는 sequence를 describe하는 match pattern 바탕으로 정보를 찾고 추출할 수 있게 해준다.
A matcher operates on a Doc and gives you access to the matched tokens in context.

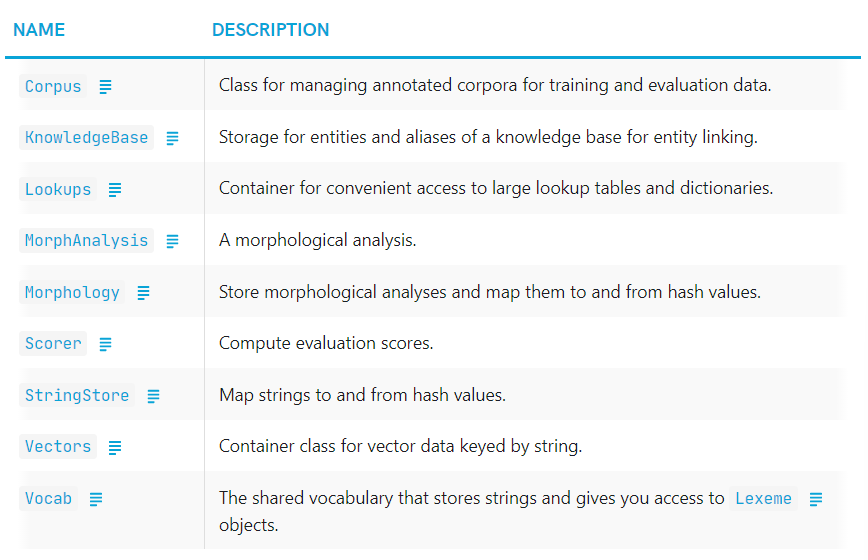
📝 Other classes
📌 Vocab, hashes and lexemes
spaCy의 ✨Vocab는 여러 documents들 사이에 공유된다. 메모리 사용량을 줄이기 위해, 모든 문자열을 hash values로 인코딩한다.
(예를 들어 "coffee"는 3197928453018144401 라는 해시값을 갖는다.)
👉Entity label (ORG)나 👉POS tag(VERB)도 인코딩되어 있다. 즉, spaCy "hash value"를 통해서만 동작한다.

해시 처리한 string과 hash값을 StringStore에 저장한다. 즉, StringStore은 💡양방향으로 작동하는 lookup table이라고 생각하면 된다.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee'💡각 vocab의 entry를 뜻하는 Lexeme 또한 👉context-independent 정보를 담고 있다.
- 예를 들어, "love"이란 단어가 동사로 쓰이든, 명사로 쓰이든 해당 단어와 hash 값은 언제나 동일하다. 특정 단어에 대한 해시값은 언제나 동일!!
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
for word in doc:
lexeme = doc.vocab[word.text]
print(lexeme.text, lexeme.orth, lexeme.shape_, lexeme.prefix_, lexeme.suffix_,
lexeme.is_alpha, lexeme.is_digit, lexeme.is_title, lexeme.lang_)I 4690420944186131903 X I I True False True en
love 3702023516439754181 xxxx l ove True False False en
coffee 3197928453018144401 xxxx c fee True False False entext: lexeme의 original textorth: lexeme의 hash값shape: abstract한 word의 모양prefixsuffixis_alphais_digit
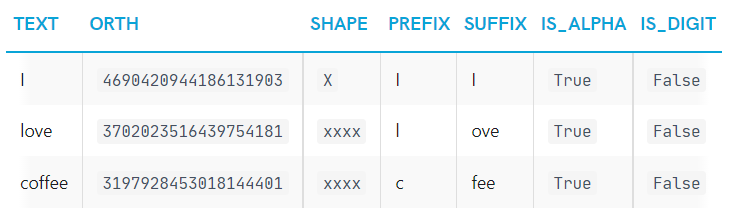
❗ 그러나, 3197928453018144401 해시값으로부터 “coffee”를 얻을 수 없다. vocabulary 사전에서 look it up 하는 방법으로만 얻을 수 있다. 아래 예시를 보면 더 이해가 될 것이다.
import spacy
from spacy.tokens import Doc
from spacy.vocab import Vocab
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee") # Original Doc
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee' 👍
empty_doc = Doc(Vocab()) # New Doc with empty Vocab
# empty_doc.vocab.strings[3197928453018144401] will raise an error :(
empty_doc.vocab.strings.add("coffee") # Add "coffee" and generate hash
print(empty_doc.vocab.strings[3197928453018144401]) # 'coffee' 👍
new_doc = Doc(doc.vocab) # Create new doc with first doc's vocab
print(new_doc.vocab.strings[3197928453018144401]) # 'coffee' 👍💡 spaCy는 Doc나 nlp obejct를 저장하면 자동으로 Vocab을 export해준다.
📌 Serialization
pipeline, vocabulary, vectors, entities, component model을 수정했다면 이를 ✨저장할 수 있어야 한다. 즉, nlp object 안에 있는 모든 것을 저장하고 싶을 경우!!
이를 위해 contents와 structure을 저장할 수 있는 포맷으로(file이나 byte string) 변환시키는 것을 serialization이라고 한다.
spaCy는 built-in serialization method를 가지고 있고, Pickle protocol을 support한다.
📖 Saving and loading
자신의 pipeline을 저장하고 로드하는 방법을 알고 싶다면 아래 참고.
saving and loading
📌 Training
spaCy의 tagger, parser, text categorizer과 다른 많은 component들은 ✨statistical model을 통해 개선할 수 있다.
component들의 모든 prediction - 예를 들어 어떻게 품사 태깅을 하는지, 해당 단어가 named entity인지 판별 -은 model의 👉weight values를 기반으로 한다.
👉weight values는 model의 학습에 사용된 example로 만들어진 값이다.
model을 학습시키기 위해서는 먼저 👉training data(text와 label)이 필요하다. 데이터는 pos tag, named entity 혹은 또다른 정보일 수 있다.
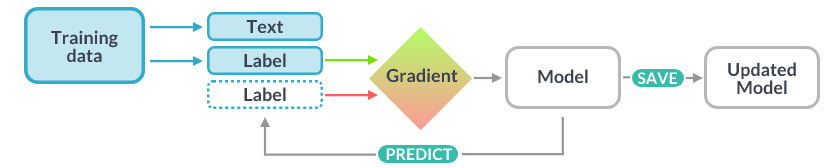
model을 학습시키는 과정은 generalized across unseen data 될 수 있도록 이루어진다.
- 예를 들어 "Amazon"이 기업이다 라고 학습시키는 것이 아니라, 이러한 context에서는 기업일 가능성이 가장 높다 처럼 학습시키는 것이다.
즉 training data가 무엇인지에 따라 model이 달라지는 것!!
또한 training data오 더불어 model의 성능을 테스트하기 위한 evaluation data가 필요하다.
📖 Training pipelines and models
pipeline을 학습시고 update 시키는 방법, training data를 만들고 spaCy의 model의 성능을 개선하고 싶다면 training 확인하기.
📝 Training config and lifecycle
Training config 파일은 pipeline을 학습하기 위한 모든 setting과 hyperparameter을 저장한다. 커맨드라인에서 config.cfg 파일을 인자로 전달해주면 된다.
📄 config.cfg 파일 예시
[training]
accumulate_gradient = 3
[training.optimizer]
@optimizers = "Adam.v1"
[training.optimizer.learn_rate]
@schedules = "warmup_linear.v1"
warmup_steps = 250
total_steps = 20000
initial_rate = 0.01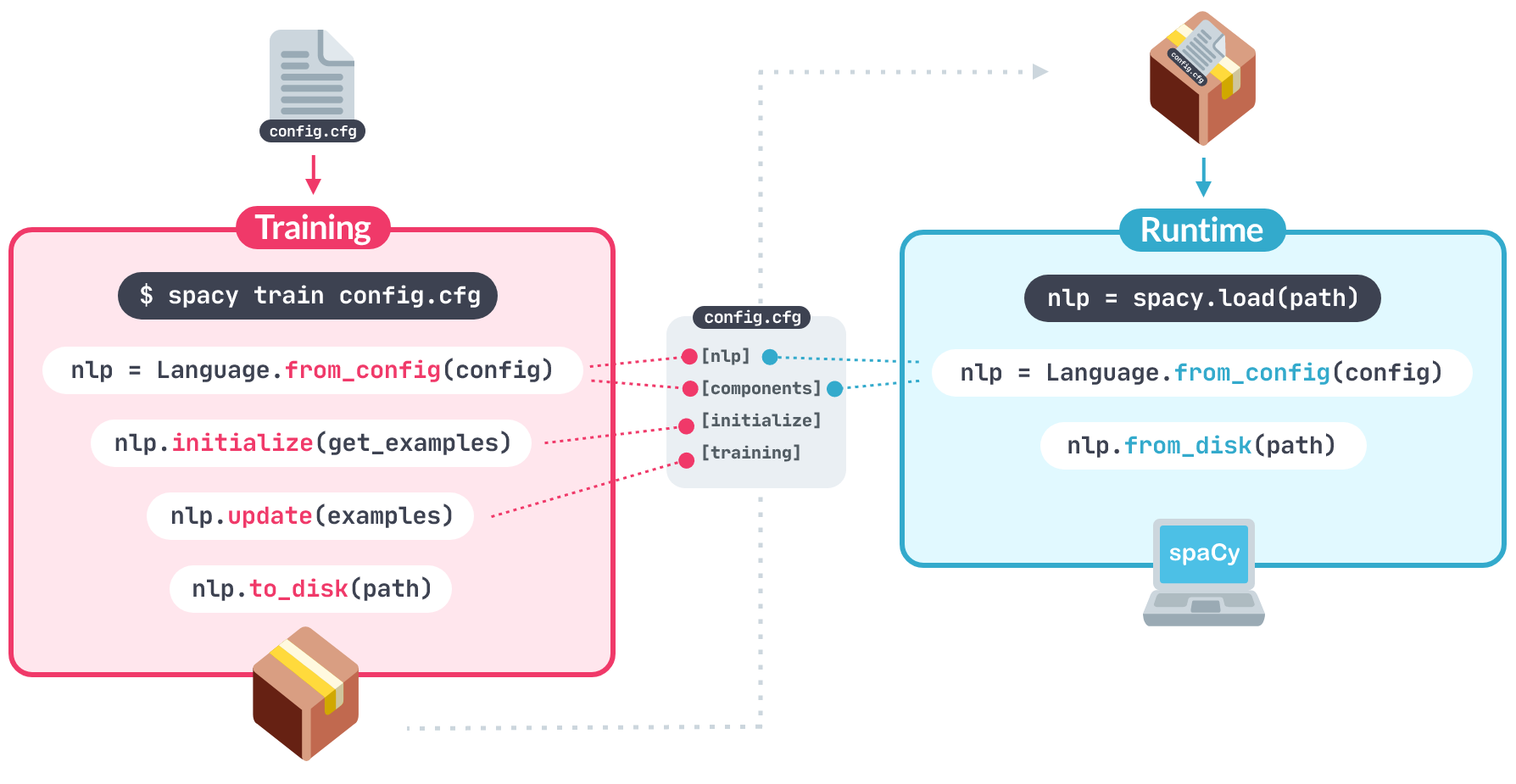
📖 Training configuration system
pipeline의 component, component model, trainig setting과 hyperparameter를 customize 하기 위해 spaCy의 ✨configuration system을 어떻게 사용하는지 알고싶다면 training config 확인하기.
📝 Trainable components
spaCy의 Pipe 클래스는 model instance를 가지고 있고, Doc object로 prediction을 수행할 수 있으며 spacy train으로 update 가능한, 학습 가능한 component를 implement할 수 있게 해준다.
아래 config.cfg 파일로 설정할 수 있다.
[components.my_component]
factory = "my_component"
[components.my_component.model]
@architectures = "my_model.v1"
width = 128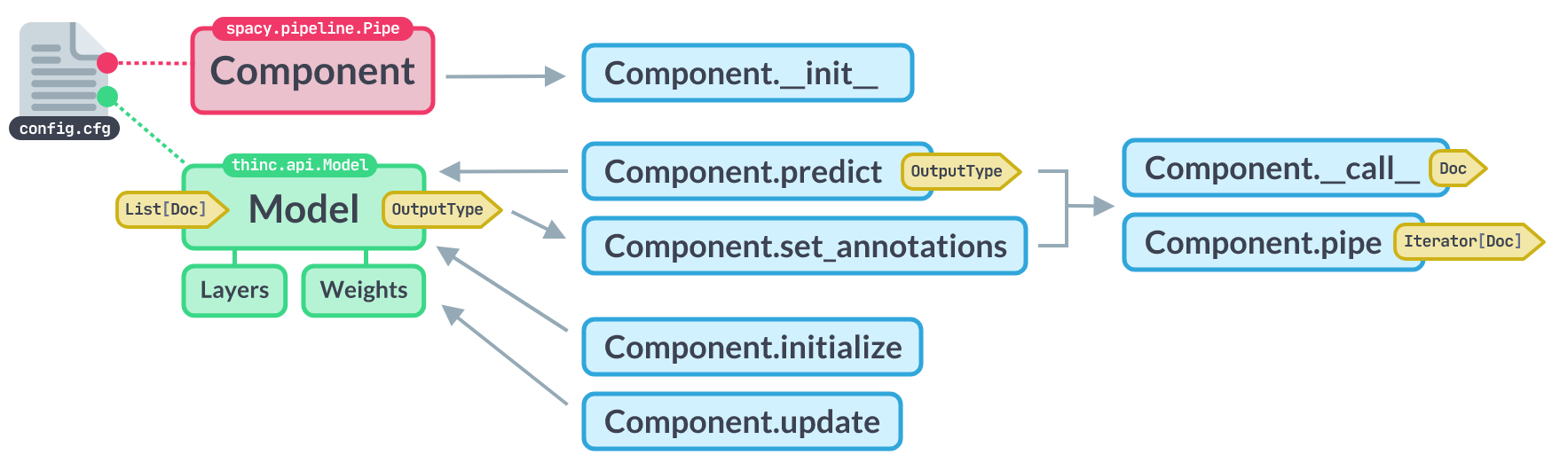
📖 Custom trainable components
자신만의 model arghitecture을 implement하는 방법, 그리고 이를 사용하여 custom trainbable component를 강화시킬 수 있는 방법을 알고 싶다면 trainable component API와 layers and architectures 확인하기.
Spacy 공식 사이트
https://www.activestate.com/blog/natural-language-processing-nltk-vs-spacy/
