한국어의 경우 띄어쓰기 단위가 되는 단위를 '어절'이라고 하는데 어절 토큰화는 한국어 NLP 데이터에 적합한 처리가 아니다.
그 이유는 한국어가 교착어, 즉 조사, 어미 등이 붙는 언어이기 때문이다.
1) 교착어 특성
서로 다른 조사를 분리해줄 필요가 있다.
조사를 분리하기 위해 영어처럼 띄어쓰기 단위로 토큰화를 할 수 없으므로 이를 전부 분리해줘야 한다.
🚩형태소(morpheme)란, 뜻을 가진 가장 작은 말의 단위를 말한다.
-
자립 형태소 : 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소. 그 자체로 단어가 된다.
체언(명사, 대명사, 수사), 수식언(관형사, 부사), 감탄사 등이 있다. -
의존 형태소 : 다른 형태소와 결합하여 사용되는 형태소.
접사, 어미, 조사, 어간를 말한다.
이처럼 한국어는 형태소 토큰화를 수행해야 한다.
2) 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
한국어의 경우 띄어쓰기가 지켜지지 않아도 글을 쉽게 이해할 수 있는 언어이기 때문에, 영어보다 띄어쓰기가 잘 지켜지지 않는 경향이 있다.
🔎 한국어 토큰화 하기
Konlpy를 통해 Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma) 형태소 분석기를 사용할 수 있다.
🔎 한국어에서의 어간 추출
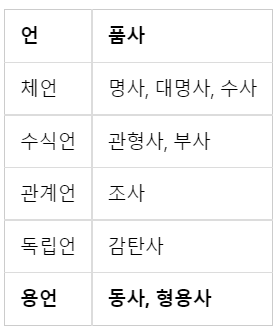
한국어는 위 표처럼 5언 9품사의 구조를 가지고 있다.
이 중 용언, 즉 '동사'와 '형용사'는 어간(stem)과 어미(ending)의 결합으로 구성된다.
(1) 활용 (conjugation)
활용이란 용언의 어간(stem)이 어미(ending)를 가지는 일을 말한다.
-
어간(stem) : 용언(동사, 형용사)을 활용할 때, 원칙적으로 모양이 변하지 않는 부분. 활용에서 어미에 선행하는 부분. 때론 어간의 모양도 바뀔 수 있음(예: 긋다, 긋고, 그어서, 그어라).
-
어미(ending) : 용언의 어간 뒤에 붙어서 활용하면서 변하는 부분이며, 여러 문법적 기능을 수행
활용은 어간이 어미를 취할 때, 어간의 모습이 일정하다면 규칙 활용, 어간이나 어미의 모습이 변하는 불규칙 활용으로 나뉜다.
(2) 규칙 활용
아래의 예제는 어간과 어미가 합쳐질 때, 어간의 형태가 바뀌지 않음을 보여준다.
잡/어간 + 다/어미
이 경우에는 규칙 기반으로 어미를 단순히 분리해주면 어간 추출이 됩니다.
(3) 불규칙 활용
불규칙 활용은 어간이 어미를 취할 때 어간의 모습이 바뀌거나 취하는 어미가 특수한 어미일 경우를 말한다.
-
어간의 형식이 달라지는 경우
‘듣-, 돕-, 곱-, 잇-, 오르-, 노랗-’등이‘듣/들-, 돕/도우-, 곱/고우-, 잇/이-, 올/올-, 노랗/노라-’와 같이 어간의 형식이 달라짐 -
특수한 어미를 취하는 경우
‘오르+ 아/어→올라, 하+아/어→하여, 이르+아/어→이르러, 푸르+아/어→푸르러’
이 경우에는 좀 더 복잡한 규칙을 필요로 한다.
📌 한국어 전처리 패키지
-
PyKoSpacing
띄어쓰기가 되어있지 않은 문장을 띄어쓰기를 한 문장으로 변환해주는 패키지 -
Py-Hanspell
네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지 -
SOYNLP를 이용한 단어 토큰화
텍스트 데이터에서 특정 문자 시퀀스가 함께 자주 등장하는 빈도가 높고, 앞 뒤로 조사 또는 완전히 다른 단어가 등장하는 것을 고려해서 해당 문자 시퀀스를 형태소라고 판단하는 단어 토크나이저이다.
soynlp는 기본적으로 학습에 기반한 토크나이저이다.
예를 들어 신조어 문제를 해결할 수 있다.
- SOYNLP의 L tokenizer
- Customized KoNLPy
형태소 분석기에 사용자 사전을 추가한다.
