💡 영화 리뷰 데이터 분류하기
🔎 모델링 소개
선형 회귀 모델, Random Forest 모델, 딥러닝 모델 - CNN, RNN을 살펴본다.
📌 회귀(Regression) 모델
연속적인 데이터에 대해서 변수들 사이의 모델을 구한 뒤, 특정 입력값에 대한 결과값을 예측하는 것.
🚩 선형 회귀(Linear Regression) 모델
선형 회귀 모델은 종속변수와 독립변수 간의 상관관계를 모델링하는 방법이다.
하나의 선형 방정식으로 표현해 예측할 데이터를 분류하는 모델이다.
데이터들을 가로지르는 최적의 선형의 함수를 찾는 것이 목적이다.
그렇다면 어떻게 최적의 함수를 찾는가?
주어진 데이터와 오차가 최소화되도록 하는데, 오차는 직선의 방정식으로 구할 수 있다.
모든 데이터에 대한 y값들과 f(x)간의 오차들을 합해서 전체적인 오차를 평가하는 함수를 Cost Function, 비용 함수라고 한다.
최종적으로
minimize cost(W,b), 즉 cost function 값을 최소화하는W와b를 찾는 것이 선형 회귀이다.
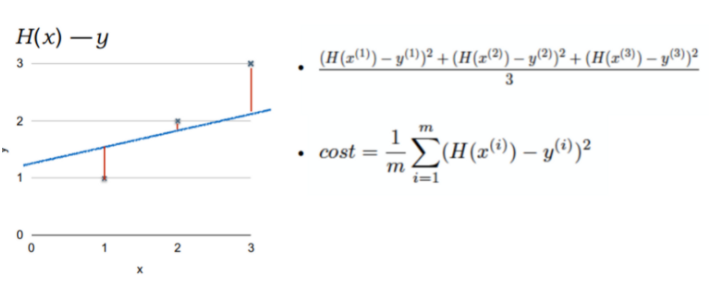
위의 공식은 cost function 방법 중 '평균 제곱 오차' 라는 방법으로, 보편적으로 많이 사용되는 방법이다.
cost Function을 정의하는 것, 즉 cost function을 최소화하는 가중치를 찾는 것이 머신러닝의 core! 라고 할 수 있다.
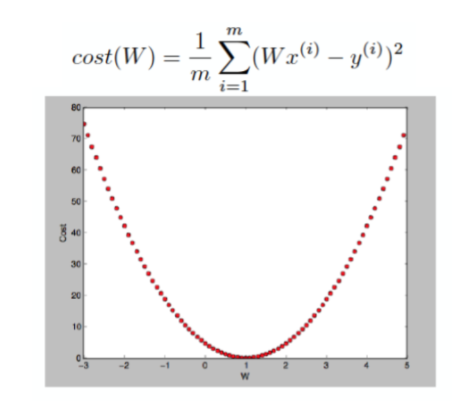
W 값에 따른 cost의 변화 그래프는 위와 같다.
이러한 형태를 convex function, 볼록 함수라고 한다.
결국 기울기가 0인 지점을 차증면 된다. 어떻게?
대표적인 알고리즘이 Gradient Descent Algorithm이다.
- Cost function을 최소화하는 알고리즘
- 주어진 cost (W, b)에 대하여
cost를 최소화 하는W,b탐색
<동작 원리>
a. 초기 값으로 탐색 시작 (0,0 혹은 특정 값)
b. W와 b값을 조금씩 변화 시키며 cost값을 감소시키는 gradient를 선택
c. Minimum에 수렴할때까지 반복
- 어디에서 시작하든 **minimum에 도달
🚩 로지스틱 회귀(Logistic Regression) 모델
결과 값이 항상 범위 [0,1] 사이에 있도록 하기 위해 로짓 변환을 한다.
🚩 (1) TF-IDF를 활용한 모델 구현
TfidfVectorizer를 사용하므로 입력값이 텍스트 형태여야 한다.
DATA_IN_PATH = "./"
TRAIN_CLEAN_DATA='train_clean.csv'
train_data=pd.read_csv(DATA_IN_PATH + TRAIN_CLEAN_DATA)
reviews=list(train_data['review'])
sentiments=list(train_data['sentiment'])- TF-IDF 벡터화를 진행한다.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer=TfidfVectorizer(min_df=0.0, analyzer="char", sublinear_tf=True,
ngram_range=(1,3), max_features=5000)
X=vectorizer.fit_transform(reviews)min_df: 설정한 값보다 특정 토큰의 df 값이 더 적게 나오면 벡터화 과정에서 제거analyzer: 분석하기 위한 기준 단위,word: 단어 하나,char: 문자 하나sublinear_tf: 문서의 단어 빈도 수(term frequency)에 대한 스무딩(smoothing) 여부 설정ngram_range: 빈도의 기본 단위를 어느 범위의 n-gram으로 설정할 것인지max_features: 각 벡터의 최대 길이
TfidfVectorizer 생성 후 fit_transform 함수 사용해 전체 문장에 대한 특징 벡터 데이터 X를 생성한다.
- 학습과 검증 데이터셋 분리
20퍼센트를 검증 데이터로 나눈다.
from sklearn.model_selection import train_test_split
import numpy as np
RANDOM_SEED = 42
TEST_SPLIT=0.2
y=np.array(sentiments)
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=TEST_SPLIT, random_state=RANDOM_SEED)- 모델 선언 및 학습
LogisticRegression 클래스 객체 생서 및 fit 함수 호출하여 데이터에 대한 모델 학습 진행하기.
from sklearn.linear_model import LogisticRegression
lgs=LogisticRegression(class_weight='balanced')
lgs.fit(X_train, y_train)class_weight를 balanced로 설정해서 각 라벨에 대해 균형 있게 학습할 수 있게 한다.
- 검증 데이터로 성능 평가
print("Accuracy: %f"%lgs.score(X_eval, y_eval)) # 검증 데이터로 성능 측정Accuracy: 0.859800여기서는 정확도(Accuracy)만 측정했지만, 이 외에도 다양한 성능 평가지표가 있다.
🔎 정밀도(precision), 재현율(recall), f1-score, auc 등
약 86%의 정확도를 보였다.
앞으로 모데를 어떻게 튜닝 - 하이퍼파라미터 수정, 다른 기법 추가 - 해서 성능을 높일 수 있을지 생각해보자.
- 데이터 제출하기
DATA_IN_PATH = "./"
TEST_CLEAN_DATA='test_clean.csv'
test_data=pd.read_csv(DATA_IN_PATH+TEST_CLEAN_DATA)
testDataVecs=vectorizer.transform(test_data['review'])평가 데이터에 대해서는 fit을 호출하지 않고 그대로 transform만 호출한다.
test_predicted=lgs.predict(testDataVecs)
print(test_predicted)[1 0 1 ... 0 1 0]결과를 보면 각 데이터에 대해 긍정(1), 부정(0) 값을 가지고 있다.
CSV 파일로 저장할 때, 각 데이터의 고유한 id 값과 결과값으로 구성돼 있어야 한다.
DATA_OUT_PATH= "./"
if not os.path.exists(DATA_OUT_PATH):
os.makedirs(DATA_OUT_PATH)
ids = list(test_data['id'])
answer_dataset=pd.DataFrame({'id': ids, 'sentiment': test_predicted})
answer_dataset.to_csv(DATA_OUT_PATH+'lgs_tfidf_answer.csv', index=False, quoting=3)🚩 (2) Word2Vec를 활용한 모델 구현
word2vec은 단어로 표현된 리스트를 입력값으로 넣어야 하므로 전처리된 텍스트 데이터를 불러온다.
DATA_IN_PATH = "./"
TRAIN_CLEAN_DATA='train_clean.csv'
train_data=pd.read_csv(DATA_IN_PATH+TRAIN_CLEAN_DATA)
reviews=list(train_data['review'])
sentiments=list(train_data['sentiment'])
sentences=[]
for review in reviews:
sentences.append(review.split())
아래는 word2vec 모델의 하이퍼파라미터 설정이다.
# 학습 시 필요한 하이퍼파라미터
num_features = 300 # 워드 벡터 특징값 수
min_word_count = 40 # 단어에 대한 최소 빈도 수
num_workers = 4 # 프로세스 개수
context =10 # 컨텍스트 윈도우 크기
downsampling = 1e-3 # 다운 샘플링 비율num_features: 각 단어에 대해 임베딩된 벡터의 차원을 정한다.min_word_count: 모델에 의미 있는 단어를 가지고 학습하기 위해 적은 빈도 수의 단어들은 학습하지 않는다.num_workers: 모델 학습 시 학습을 위한 프로세스 개수context: word2vec 수행하기 위한 컨텍스트 윈도 크기downsampling: word2vec 학습을 수행할 때 빠른 학습을 위해 정답 단어 라벨에 대한 다운샘플링 비율을 지정. (보통0.001이 좋은 성능)
from gensim.models import word2vec
print("Training model...")
model=word2vec.Word2Vec(sentences,
workers=num_workers,
vector_size=num_features,
min_count=min_word_count,
window=context,
sample=downsampling)모델은 아래처럼 저장할 수 있다.
# 모델을 저장하면 Word2Vec.load()를 통해 모델을 다시 사용할 수 있다.
model_name = "300features_40minwords_10context"
model.save(model_name)이제 만들어진 word2vec 모델을 활용하여 선형 회귀 모델을 학습해보자.
지금 word2vec 모델에서 각 단어가 벡터로 표현돼 있다. 또한 리뷰마다 단어의 개수가 모두 다르므로 입력값을 하나의 형태로 만들어보자.
가장 단순한 방법은 문장에 있는 모든 단어의 벡터값에 대해 평균을 내서 리뷰 하나당 하나의 벡터로 만드는 방법이 있다.
하나의 리뷰에 대해 전체 단어의 평균값을 계산하는 함수를 구현한다.
def get_features(words, model, num_features):
# 출력 벡터 초기화
feature_vector= np.zeros((num_features), dtype=np.float32)
num_words=0
# 어휘사전 준비
index2word_set=list(model.wv.index_to_key)
for w in words:
if w in index2word_set:
num_words +=1
# 사전에 해당하는 단어에 대해 단어 벡터를 더함
feature_vector = np.add(feature_vector, model.wv[w])
# 문장의 단어 수만큼 나누어 단어 벡터의 평균값을 문장 벡터로 함
feature_vector = np.divide(feature_vector, num_words)
return feature_vector주의할 점 1)
model.wv.index2word대신model.wv.index_to_key로 바꿔주기.
주의할 점 2)model[w]대신model.wv[w]로 접근하기
# 전체 리뷰에 대해 각 리뷰의 평균 벡터를 구하는 함수
def get_dataset(reviews, model, num_features):
dataset=list()
for s in reviews:
dataset.append(get_features(s, model, num_features))
reviewFeatureVecs=np.stack(dataset)
return reviewFeatureVecstest_data_vecs=get_dataset(sentences, model, num_features)정확도는 아래와 같다.
Accuracy: 0.863600출처: "텐서플로 2와 머신러닝으로 시작하는 자연어 처리" - 전창욱, 최태균, 조중현, 신성진 지음
