💡 영화 리뷰 데이터 분류하기
🔎 문제 소개
🍿 워드 팝콘
인터넷 영화 데이터베이스(IMDB)에서 나온 영화 평점 데이터를 활용한 캐글 문제다.
📌 데이터 구성
영화 리뷰 텍스트, 평점에 따른 감정 값(긍정/부정)으로 구성돼 있다.
📌 목표
- 데이터 불러오기 + 데이터 전처리
- 데이터 분석하기
- 알고리즘 모델링
🔎데이터 분석 및 전처리
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 그래프를 주피터 노트북에서 바로 그리게 함📌 (1) 데이터 불러오기
train_data=pd.read_csv("../input/kumarmanoj-bag-of-words-meets-bags-of-popcorn/labeledTrainData.tsv", header=0, delimiter="\t", quoting=3)
train_data.head()
데이터 분석은 다음과 같은 순서로 진행한다.
- 데이터 크기
- 데이터 개수
- 각 리뷰의 문자 길이 분포
- 많이 사용된 단어
- 긍정, 부정 데이터의 분포
- 각 리뷰의 단어 개수 분포
- 특수문자 및 대문자, 소문자 비율
🚩 1. 데이터 크기
해다 경로의 파일 목록을 가져오고, tsv 파일 중에서 zip 파일이 아닌 파일들의 크기를 출력한다.
# 데이터 크기 확이
print("파일 크기: ")
for file in os.listdir(DATA_IN_PATH):
if 'tsv' in file and 'zip' not in file:
print(file.ljust(30) + str(round(os.path.getsize(DATA_IN_PATH + file)/1000000,2))+'MB')
라벨이 없는 학습 데이터의 크기가 가장 큰 것을 확인할 수 있다.
🚩 2. 데이터 개수
전체 학습 데이터의 개수는 아래와 같다.
print('전체 학습 데이터의 개수: {}'.format(len(train_data)))전체 학습 데이터의 개수: 25000🚩 3. 각 리뷰의 문자 길이 분포
train_length=train_data['review'].apply(len)
train_length.head()각 리뷰의 길이가 담겨 있다.
0 2304
1 948
2 2451
3 2247
4 2233
Name: review, dtype: int64# 그래프에 대한 이미지 크기 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(12,5))
# 히스토그램 선언
# bins: 히스토그램 값에 대한 버킷 범위
# alpha: 그래프 색상 투명도
# color: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(train_length, bins=200, alpha=0.5, color='r', label='word')
plt.yscale('log')
# 그래프 제목
plt.title('Log-Histogram of length of review')
# 그래프 x축 라벨
plt.xlabel('Length of review')
# 그래프 y축 라벨
plt.ylabel('Number of review')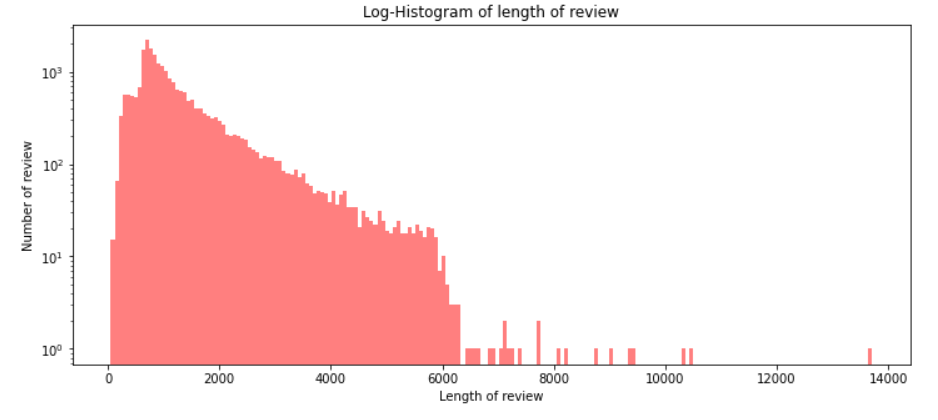
분포를 보면 각 리뷰의 문자 길이가 대부분 6000 이하이고 대부분 2000 이하에 분포돼 있음을 알 수 있다.
이상치로 1000 이상의 값을 가지고 있다.
print('리뷰 최대 길이: {}'.format(np.max(train_length)))
print('리뷰 최소 길이: {}'.format(np.min(train_length)))
print('리뷰 평균 길이: {:.2f}'.format(np.mean(train_length)))
print('리뷰 길이 표준편차: {:.2f}'.format(np.std(train_length)))
print('리뷰 중간 길이: {}'.format(np.median(train_length)))
# 사분위의 대한 경우는 0~100 스케일로 돼 있음
print('리뷰 길이 제1사분위 길이: {}'.format(np.percentile(train_length, 25)))
print('리뷰 길이 제3사분위: {}'.format(np.percentile(train_length, 75)))리뷰 최대 길이: 13710
리뷰 최소 길이: 54
리뷰 평균 길이: 1329.71
리뷰 길이 표준편차: 1005.22
리뷰 중간 길이: 983.0
리뷰 길이 제1사분위 길이: 705.0
리뷰 길이 제3사분위: 1619.0히스토그램에서 확인한 것처럼 평균 길이가 1300 정도이고, 최대값이 13000임을 알 수 있다.
plt.figure(figsize=(12,5))
# 박스 플롯 생성
# 첫 번째 인자: 여러 분포에 대한 데이터 리스트를 입력
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 마크함
plt.boxplot([train_length], labels=['counts'],showmeans=True)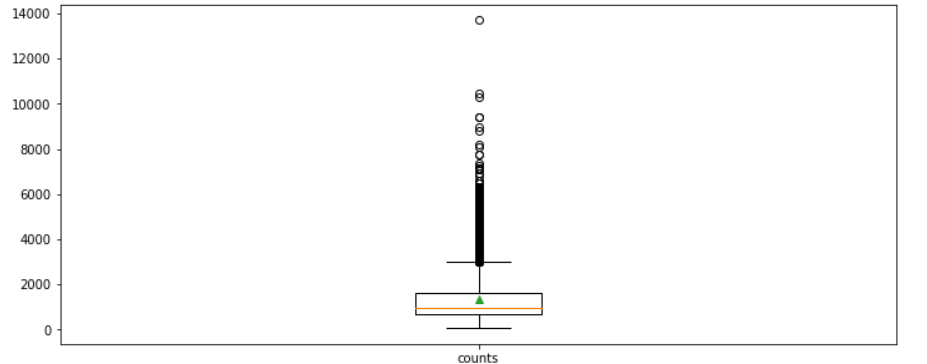
박스 플롯을 보면 데이터의 길이가 대부분 2000 이하로 평균이 1500 이하인데, 길이가 4000 이상인 이상치 데이터도 많이 분포돼 있는 것을 확인할 수 있다.
🚩 4. 많이 사용된 단어
워드클라우드로 리뷰에서 많이 사용된 단어를 확인해보자.
from wordcloud import WordCloud, STOPWORDS
wordcloud = WordCloud(stopwords=STOPWORDS, background_color='black', width=800, height=600).generate(' '.join(train_data['review']))
plt.figure(figsize=(20,15))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()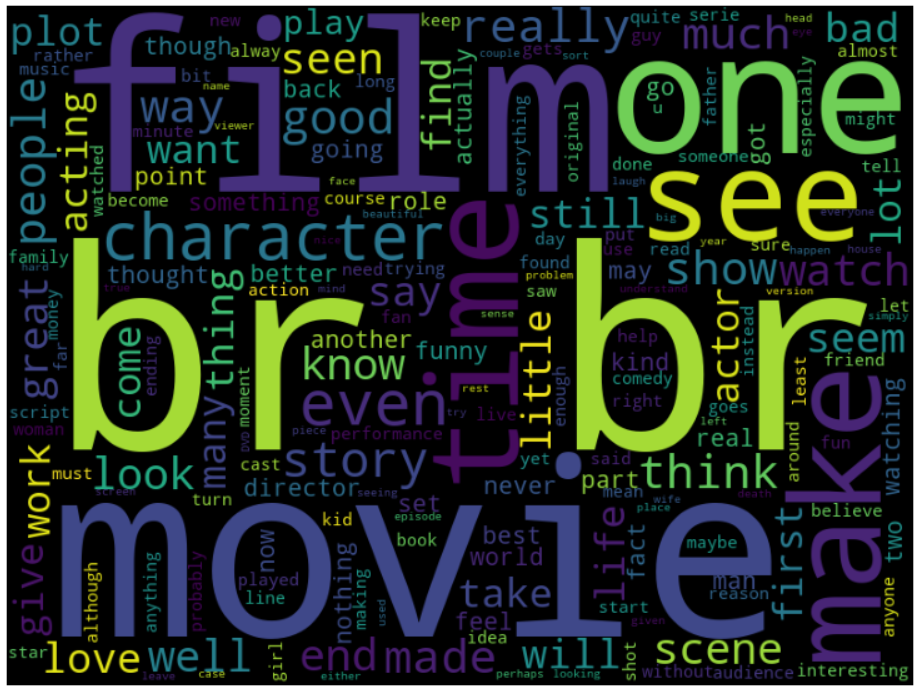
br 은 HTML 태그 중 하나로, 정제되어야 하는 데이터이다.
🚩 5. 긍정, 부정 데이터의 분포
import seaborn as sns
sentiment = train_data['sentiment'].value_counts()
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6,3)
sns.countplot(train_data['sentiment'])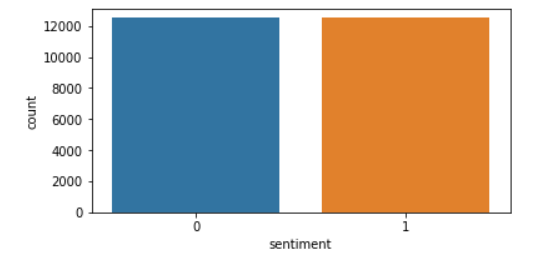
print("긍정 리뷰 개수:{}".format(train_data['sentiment'].value_counts()[1]))
print("부정 리뷰 개수:{}".format(train_data['sentiment'].value_counts()[0]))긍정 리뷰 개수:12500
부정 리뷰 개수:12500🚩 6. 각 리뷰의 단어 개수 분포
train_word_counts=train_data['review'].apply(lambda x:len(x.split(' ')))
# 그래프에 대한 이미지 크기 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(15,10))
# 히스토그램 선언
plt.hist(train_word_counts, bins=50, facecolor='r', label='train')
plt.yscale('log')
# 그래프 제목
plt.title('Log-Histogram of word count in review', fontsize=15)
plt.legend()
# 그래프 x축 라벨
plt.xlabel('Number of words', fontsize=15)
# 그래프 y축 라벨
plt.ylabel('Number of reviews', fontsize=15)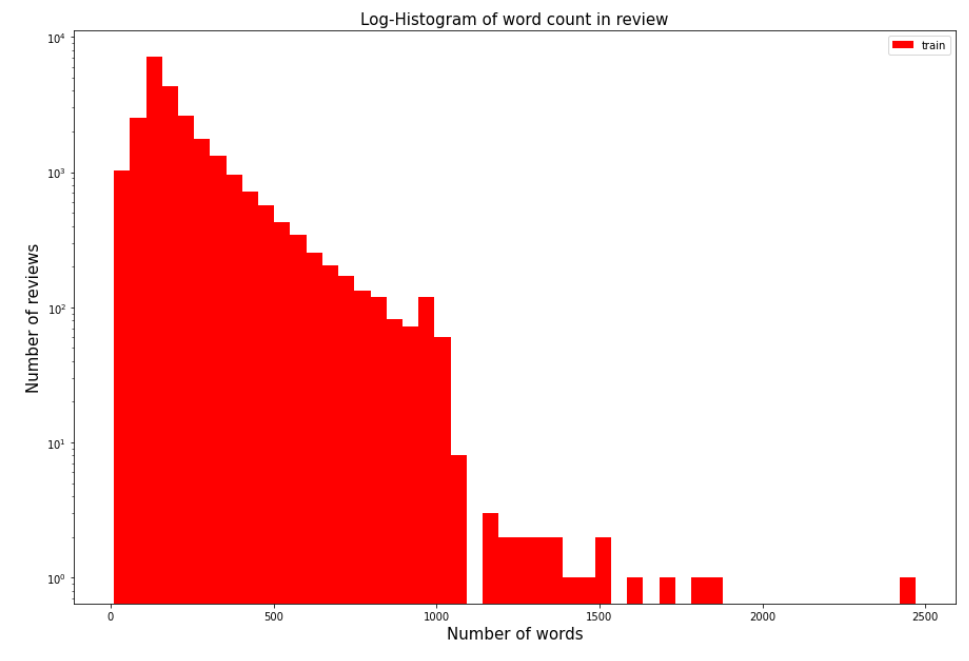
print('리뷰 단어 개수 최댓값: {}'.format(np.max(train_word_counts)))
print('리뷰 단어 개수 최솟값: {}'.format(np.min(train_word_counts)))
print('리뷰 단어 개수 평균값: {:.2f}'.format(np.mean(train_word_counts)))
print('리뷰 단어 개수 표준편차: {:.2f}'.format(np.std(train_word_counts)))
print('리뷰 단어 개수 중간값: {}'.format(np.median(train_word_counts)))
# 사분위의 대한 경우는 0~100 스케일로 돼 있음
print('리뷰 단어 개수 제1사분위: {}'.format(np.percentile(train_word_counts, 25)))
print('리뷰 단어 개수 제3사분위: {}'.format(np.percentile(train_word_counts, 75)))리뷰 단어 개수 최댓값: 2470
리뷰 단어 개수 최솟값: 10
리뷰 단어 개수 평균값: 233.79
리뷰 단어 개수 표준편차: 173.74
리뷰 단어 개수 중간값: 174.0
리뷰 단어 개수 제1사분위: 127.0
리뷰 단어 개수 제3사분위: 284.0단어 개수 평균이 233개이고, 최댓값의 경우 2,470개의 단어를 가지고 있다.
3사분위 값이 284개로 리뷰의 75%가 300개 이하의 단어를 가지고 있다.
🚩 7. 특수문자 및 대문자, 소문자 비율
qmarks=np.mean(train_data['review'].apply(lambda x: '?' in x))
fullstop=np.mean(train_data['review'].apply(lambda x: '.' in x))
capital_first=np.mean(train_data['review'].apply(lambda x: x[0].isupper())) # 첫 번째 대문자
capitals=np.mean(train_data['review'].apply(lambda x: max([y.isupper() for y in x]))) # 대문자 개수
numbers=np.mean(train_data['review'].apply(lambda x: max([y.isdigit() for y in x]))) # 숫자 개수
print('물음표가 있는 질문: {:.2f}%'.format(qmarks*100))
print('마침표가 있는 질문: {:.2f}%'.format(fullstop*100))
print('첫 글자가 대문자인 질문: {:.2f}%'.format(capital_first*100))
print('대문자가 있는 질문: {:.2f}%'.format(capitals*100))
print('숫자가 있는 질문: {:.2f}%'.format(numbers*100))물음표가 있는 질문: 29.55%
마침표가 있는 질문: 99.69%
첫 글자가 대문자인 질문: 0.00%
대문자가 있는 질문: 99.59%
숫자가 있는 질문: 56.66%대부분 마짐표 포함, 대문자도 대부분 사용하고 있다.
따라서 전처리 과정에서 대문자를 모두 소문자로 바꾸고 특수 문자는 제거한다.
📌 (1) 데이터 전처리
import re
import pandas
import numpy
import json
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.preprocessing.text import Tokenizer데이터를 불러온 후 첫 번째 학습 데이터의 리뷰를 출력해보자.
DATA_IN_PATH = "../input/kumarmanoj-bag-of-words-meets-bags-of-popcorn/"
train_data=pd.read_csv(DATA_IN_PATH + "labeledTrainData.tsv", header=0, delimiter="\t", quoting=3)
print(train_data['review'][0])BeautifulSoup으로 HTML 태그를 제거하고 re.sub으로 특수문자를 제거한다.
review=train_data['review'][0]
review_text=BeautifulSoup(review, "html5lib").get_text() # HTML 태그 제거
review_text=re.sub("[^a-zA-Z]", " ", review_text) # 영어 문자 제외 나머지 제거
print(review_text)다음으로 불용어(stopword)를 삭제한다.
불용어란 문장에서 자주 출현하나 전체적인 의미에 큰 영향을 주지 않는 단어를 말한다.
영어에서는 조사, 관사 등이 있다.
불용어를 제거하는지 여부는 풀고자 하는 문제에 따라 적절하게 판단해야 한다.
일반적으로 라이브러리에서 정의해놓은 불용어 사전을 이용한다.
NLTK의 불용어 사전을 이용해보자.
stop_words =set(stopwords.words('english'))
review_text=review_text.lower()
words=review_text.split()
words=[w for w in words if w not in stop_words]
clean_review=' '.join(words)
print(clean_review)이 모든 과정을 하나의 함수로 정의하여 데이터 전처리 작업을 수행한다.
clean_train_df = pd.DataFrame({'review': clean_train_reviews, 'sentiment':train_data['sentiment']})
tokenizer=Tokenizer()
tokenizer.fit_on_texts(clean_train_reviews)
text_sequences=tokenizer.texts_to_sequences(clean_train_reviews)
print(text_sequences[0])위와 같이 하면 각 리뷰가 텍스트가 아닌 벡터로 구성될 것이다.
즉, 각 단어의 인덱스로 바뀐 것을 볼 수 있다.
[404, 70, 419, 8815, 506, 2456, 115, 54, 873, 516, 178, 18686, 178, 11242, 165, 78, 14, 662, 2457, 117, 92, 10, 499, 4074, 165, 22, 210, 581, 2333, 1194, 11242, 71, 4826, 71, 635, 2, 253, 70, 11, 302, 1663, 486, 1144, 3265, 8815, 411, 793, 3342, 17, 441, 600, 1500, 15, 4424, 1851, 998, 146, 342, 1442, 743, 2424, 4, 8815, 418, 70, 637, 69, 237, 94, 541, 8815, 26055, 26056, 120, 1, 8815, 323, 8, 47, 20, 323, 167, 10, 207, 633, 635, 2, 116, 291, 382, 121, 15535, 3315, 1501, 574, 734, 10013, 923, 11578, 822, 1239, 1408, 360, 8815, 221, 15, 576, 8815, 22224, 2274, 13426, 734, 10013, 27, 28606, 340, 16, 41, 18687, 1500, 388, 11243, 165, 3962, 8815, 115, 627, 499, 79, 4, 8815, 1430, 380, 2163, 114, 1919, 2503, 574, 17, 60, 100, 4875, 5100, 260, 1268, 26057, 15, 574, 493, 744, 637, 631, 3, 394, 164, 446, 114, 615, 3266, 1160, 684, 48, 1175, 224, 1, 16, 4, 8815, 3, 507, 62, 25, 16, 640, 133, 231, 95, 7426, 600, 3439, 8815, 37248, 1864, 1, 128, 342, 1442, 247, 3, 865, 16, 42, 1487, 997, 2333, 12, 549, 386, 717, 6920, 12, 41, 16, 158, 362, 4392, 3388, 41, 87, 225, 438, 207, 254, 117, 3, 18688, 18689, 316, 1356]전체 데이터가 인덱스로 구성돼 있을 것이므로 각 인덱스가 어떤 단어를 의미하는지 확인할 수 있는 단어 사전이 필요하다.
word_vocab=tokenizer.word_index
word_vocab["<PAD>"]=0
print(word_vocab)
print(len(word_vocab))전체 단어 개수: 74066# 단어 사전과 전체 단어 개수에 대한 정보를 저장해둔다.
data_configs={}
data_configs['vocab']=word_vocab
data_configs['vocab_size']=len(word_vocab)마지막 전처리 과정은 서로 다른 길이의 데이터를 특정 길이로 자르거나 패딩 작업을 한다.
MAX_SEQUENCE_LENGTH=174 # 문장 최대 길이
train_inputs = pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
print('Shape of train data: ', train_inputs.shape)Shape of train data: (25000, 174)문장 최대 길이를 174로 했는데, 이 값은 단어 개수의 통계를 계산했을 때 나왔던 중간값이다. 보통 평균값이 아닌 중간값을 사용하는 경우가 많은데, 일부 이상치 데이터가 길이가 지나치게 길면 평균이 급격히 올라갈 수 있기 때문에 적당한 값인 중간값을 사용하는 것이다.
25,000개의 데이터가 동일한 174 길이로 통일 되었음을 볼 수 있다.
train_labels=np.array(train_data['sentiment'])
print('Shape of label tensor: ', train_labels.shape)Shape of label tensor: (25000,)원본 텍스트 데이터를 인덱스 벡터로 변환(인덱싱 단어 사전 생성 및 활용), 고저된 길이에 대해 패딩 처리 => 각 리뷰가 하나의 벡터로 변환됨
- 텍스트 데이터는 csv파일로 저장
- 벡터화한 데이터, 정답 라벨은 넘파이 파일로 저장
- 데이터 정보는 json 파일로 저장
DATA_IN_PATH='./'
TRAIN_INPUT_DATA='train_input.npy'
TRAIN_LABEL_DATA='train_label.npy'
TRAIN_CLEAN_DATA='train_clean.csv'
DATA_CONFIGS='data_configs.json'
import os
if not os.path.exists(DATA_IN_PATH):
os.makedirs(DATA_IN_PATH)
# 전처리된 데이터를 넘파이 형태로 저장
np.save(open(DATA_IN_PATH+TRAIN_INPUT_DATA,'wb'), train_inputs)
np.save(open(DATA_IN_PATH+TRAIN_LABEL_DATA,'wb'), train_labels)
# 정제된 텍스트를 csv 형태로 저장
clean_train_df.to_csv(DATA_IN_PATH+TRAIN_CLEAN_DATA, index=False)
# 데이터 사전을 JSON 형태로 저장
json.dump(data_configs, open(DATA_IN_PATH+DATA_CONFIGS, 'w'), ensure_ascii=False)평가 데이터 전처리 시 중요한 점은 토크나이저를 통해 인덱스 벡터로 만들 때 기존에 학습 데이터에 적용한 토크나이저 객체를 사용해야 한다는 것이다.
출처: "텐서플로 2와 머신러닝으로 시작하는 자연어 처리" - 전창욱, 최태균, 조중현, 신성진 지음
