진행하고 있는 프로젝트에서 특정 키워드(keyword)가 입력으로 들어오는 문장에 포함되어 있는지 확인하는 알고리즘을 구성해봐야 한다.
근데 예를 들어 keyword로 "man"이 주어졌을 때, 문장에 "men"이 있다면 포함되어 있다고 봐야하지만, 단순 일치로 알고리즘을 짤 경우 원하는 결과가 나오지 않는다.
이처럼 원형 단어에서 변형된 단어들의 경우 lemmatizer(표제어 추출)를 사용하여 키워드 포함 여부를 판단할 수 있다.
하지만 더 복잡한 문제는 아래와 같은 경우다.
"man"이 키워드로 주어졌을 때, 문장이 "What is the perfect environment for a person to live a life happily?" 이라면, 의미상 "man" 이라는 단어가 문장에 포함되어 있다고 봐야 하는데, 이걸 어떻게 구현할 수 있을까..?? 혹은 "woman"이 키워드로 주어졌을 때는??
문장과 문장 간의 유사도를 계산하는 것에 대해서는 구글링해보면 많이 나오는데, single word 와 문장 속 single word의 유사도를 계산하는 것에 대한 글은 아직 찾지 못했다...
(근데 두 단어를 문맥상 같은 단어라고 볼지에 대한 기준? 도 어떻게 정의할 수 있는지, 그니까 어떤 경우에 두 단어가 "similar" 한지를 어떻게 정의할 수 있는지를 모르겠다. 스택오버플로우에 올라온 질문에 대한 답변들을 보면 pre-trained model 사용하는 방법이나 rule-base를 말하던데, 실제로 애플의 siri는 방대한 데이터로 만든 파워 rule-base 시스템이라고 한다.)
아직 Word2Vec이나 유사도 계산 방식에 대한 충분한 학습이 안 되어서 그런 것 같고, 논문이나 여러 영어 원문 글들 보면서 차근차근 살펴보려고 한다!!
📌 stackoverflow에 올라온 관련된 질문들
https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec
https://stackoverflow.com/questions/65199011/is-there-a-way-to-check-similarity-between-two-full-sentences-in-python
https://stackoverflow.com/questions/72716877/how-to-identify-the-similar-words-using-the-word2vec/
https://stackoverflow.com/questions/60698839/how-to-use-nlp-to-find-out-if-two-words-have-the-same-definition
그러다가 발견한 논문인데, Abstract 만 읽어봤을 때 굉장히 흥미로운 주제인 것 같아서 한 번 정리해보려고 한다!
Based on billions of words on the internet, people = men (1 April, 2022)
Abstract
이제는 두 단어가 유사한 맥락에서 사용된 단어들인지 어느정도 정확하게 측정할 수 있게 되었다. 이는 언어적 맥락에서 단어들 간의 유사도에 대한 척도를 알아내는 것이고, 어떻게 보면 개념의 유사도에 대한 측정이라고도 할 수 있다.
방대한 텍스트 말뭉치에서 발견되는 언어 유사도 측정은 결국 광범위한 사고 방식을 반영하고, 강화하는 개념인 어떤 collective concepts(집단적 개념?) 에 대한 통찰력을 제공할 수 있다.
이 논문에서는 사회적 의사 결정 및 정책 결정이 기반을 형성하는 사람들을 조사했다. 6,300억개가 넘는 영어 단어 모음에서 추출한 smiliarity metrics를 사용하여 연구한 결과, 이들의 collective concepts은 중립적이지 않고 오히려 남성을 여성보다 우선시한다는 것을 발견했다.
자연어 처리의 발전으로 인해 인지 과학자들은 인간 개념의 내용 및 관계를 특성화할 수 있게 되었다. 개념 연구에 대한 이 language-based 접근 방식의 기본 가정은 굉장히 간단하다.
👉 유사한 문맥(context)에서 사용되는 단어는 유사한 개념(concept)를 표현한다. 방대한 언어 말뭉치에서 단어 간의 유사도를 측정하기 위한 tool의 개발은 "collective concept" 이라고 부르는 연구의 문을 열었다. 둘 다 어떠한 사고 방식을 반영하고 강화한다.
이러한 collective concept이 인간 종을 어떻게 대표하는지, 특정 그룹이 다른 그룹보다 특권이 있는지 와 같은 질문들에 대해 이 논문은 근본적인 편향을 발견했다고 말한다.
📌 Language(언어)와 Collective Concepts(집단적 개념)
Word Embedding이란, 간단히 말해서 주어진 말뭉치에서 다른 단어와 함께 등장하는 단어의 패턴을 나타내는, 압축된 형식의 고차원 벡터이다.
따라서 벡터 공간에서 cosine 각도로 계산되는 word embedding 간의 유사도는 해당 단어가 유사한 방식으로 사용되는 경향의 정도를 나타낸다.
예를 들어, "scientist"와 "researcher"은 거의 같은 의미로 사용되는 단어로, 다른 맥락에서 발생하는 단어(예를 들어 "instead"나 "smart")의 임베딩보다 더 유사하다. 유사도 측정값의 최대값이 1이라고 했을 때 researcher은 0.767, smart는 0.204, instead는 0.036 으로 계산된다.
즉 word embedding은 단어 사용의 유사도를 측정할 수 있게 해주는 도구이다.
단어 사용의 유사성(similarity in word use) 이 개념의 유사성(similarity in concepts)을 측정하는 데 사용될 수 있다는 주장은
유사한 언어 문맥에서 발생하는 단어가 유사한 의미를 갖는다는 가설에서 시작된다.
언어학자 J.R Firth는 이 가설을 다음과 같이 요약했다.
예를 들어 "balak"이라는 생소한 단어를 들었을 때, 듣는 사람은 이 단어를 모른다고 해도, 이 단어가 사용되는 "언어적 맥락"를 고려하면 그 의미를 이해할 수 있다.
🔎 "매일 아침 Joe는 차를 위해 balak에 물을 끓였다."🔎 라고 말하면 듣는 사람은balak이주전자와 유사한 것을 의미한다고 추측할 수 있다.
이게 바로 word embedding가 동작하는 방식이다.
즉, word embedding은 특정 단어의 의미를 나타내기 위해 다른 단어와 동시 발생하는 단어의 패턴을 포착한다.
또한 단어(word)가 개념(concept)를 나타내기 때문에 word embedding vector는 개념(concept)에 대한 proxy로 동일하게 설명될 수 있다.
그리고 수백만 명이 쓴 말뭉치 데이터에서 추출한 word embedding은 집단적 개념(collective concept, 혹은 커뮤니티에서 공유된 사고방식을 반영하고 강화하는 개념)을 조사하는 데 사용할 수 있다!
여기서 말하는 "집단적 개념"이란 커뮤니티를 특징 짓고 해당 커뮤니티의 개인이 생각하는 것 이상을 넘어서는 개념, 가치 및 관행의 시스템이다. 따라서 "집단적 개념"이라는 용어는 개념(concept, 예를 들어 "사람")과 관련된 집단적 또는 사회적 표현을 의미한다.
결국 이 논문은 "Person", 사람의 집단적 개념에 대해 살펴본다.
그리고 similarity(people, men) > similarity(people, women) 임을 말한다.
뉴스 보도와 출판된 책에서 수백만 명의 개인이 사용하는 언어를 보면 "she" 보다는 "he"가 더 자주 나타난다. 이는 people=men이라는 가설과 일치하는 현상이다.
하지만 성별을 알 수 없는 사람을 지칭할 때 'she' 대신 'he'를 사용하는 언어적 관행은 성별 편견 때문이 아니라 문법적 관습에 의한 것일 수도 있다. 따라서 단순히 등장 빈도수로 해석하는 방법은 모호하다.
반면, Word Embedding은 co-occurrences(동시 발생) 및 higher-order co-occurrences) 을 포함하여 판단한다.
(예를 들어, do “he” and “person” occur alongside the same words more often than “she” and “person”?)
따라서 person의 집단적 개념(collective concept)이 여성(women) 보다는 남성(men)과 더 유사한지 여부를 조사하는 데 더 적합하다.
"사람, person"의 성 편견에 대한 연구는 굉장히 적고 또 대규모 연구는 없다. 반면, 과학이 여성보다는 남성과 더 관련이 있다는 것과 같은 다른 형태의 성별 편향에 대한 연구는 이루어져왔다.
💡 Results(결과)
similarity(people, men) > similarity(people, women) 을 테스트하기 위해 2017년 5월 Common Crawl corpus에서 추출한 Word Embedding을 사용했다.
이 대규모 말뭉치에서 추출한 Word Embedding을 사용하여 단어 간의 언어적 맥락에서의 유사성(혹은 개념 간의 유사성에 대한 proxy)을 벡터 공간에서 Cosine Similarity로 계산했다.
🔎 Study 1. Words for PEOPLE과 words for WOMEN, MEN 단어 비교
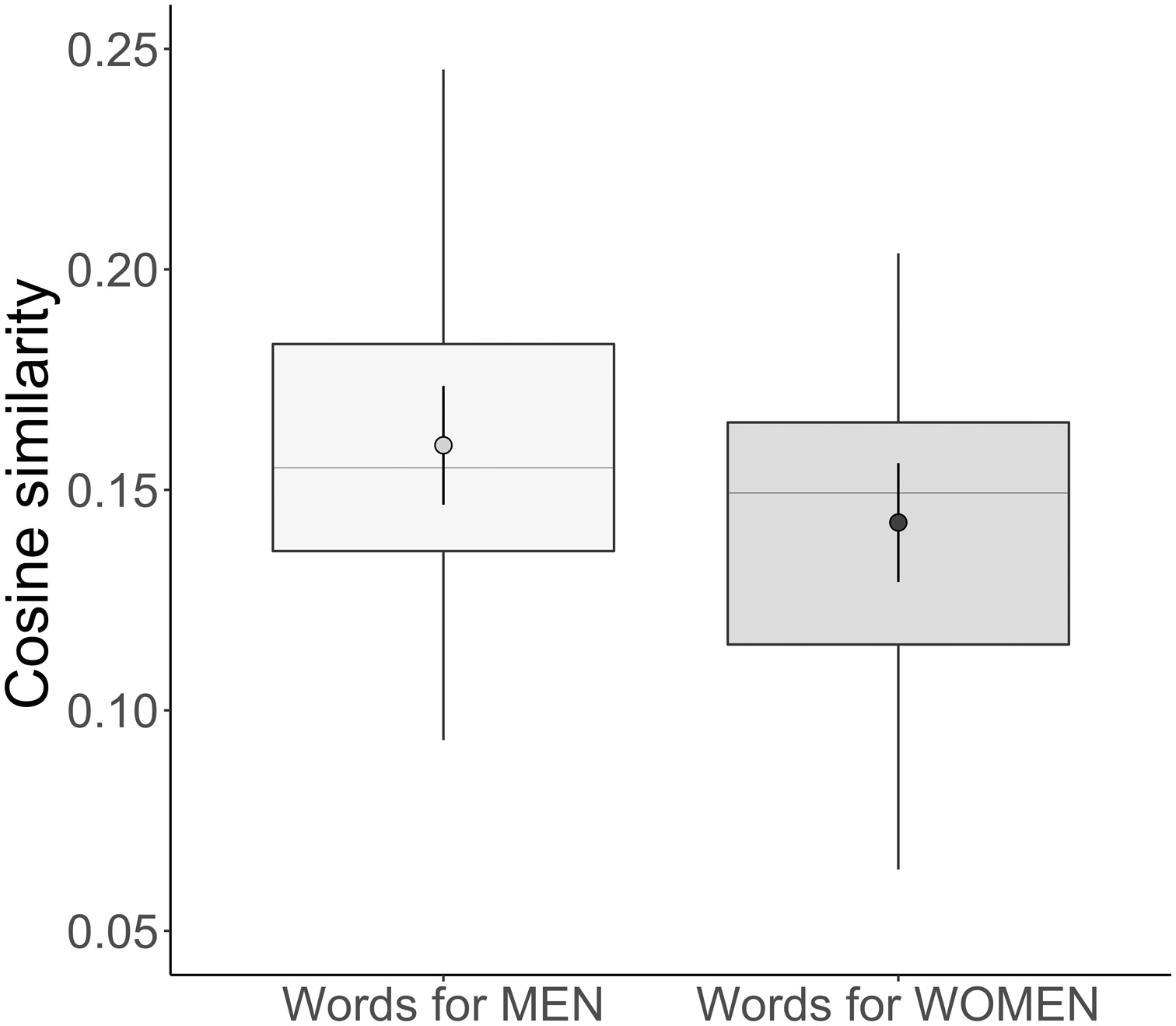
PEOPL과 MEN, PEOPLE과 WOMEN 단어 간의 코사인 유사도 계산 결과이다.
🔎 Study 2. PEOPLE를 묘사하는 Trait words과 WOMEN, MEN 비교
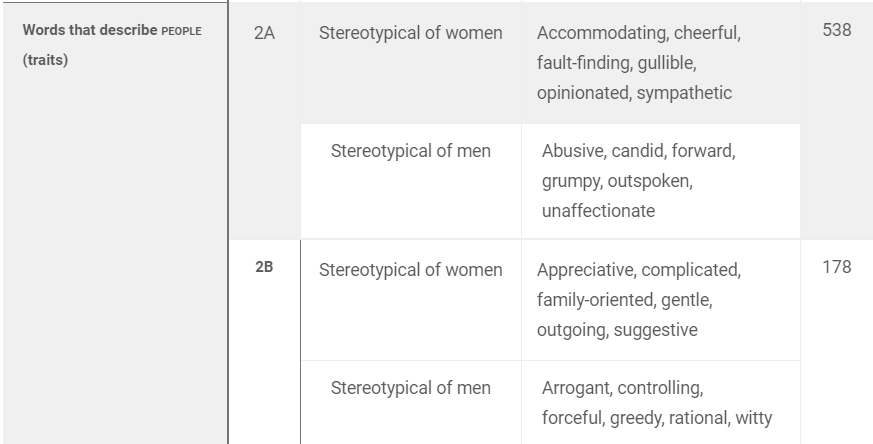
두 번째 실험은 "People"에 대한 단어에 초점을 맞추는 대신, 특히 사람들이 어떤 사람인지 일반적으로 설명하는 특성에 대한 단어(Trait words)를 조사했다.
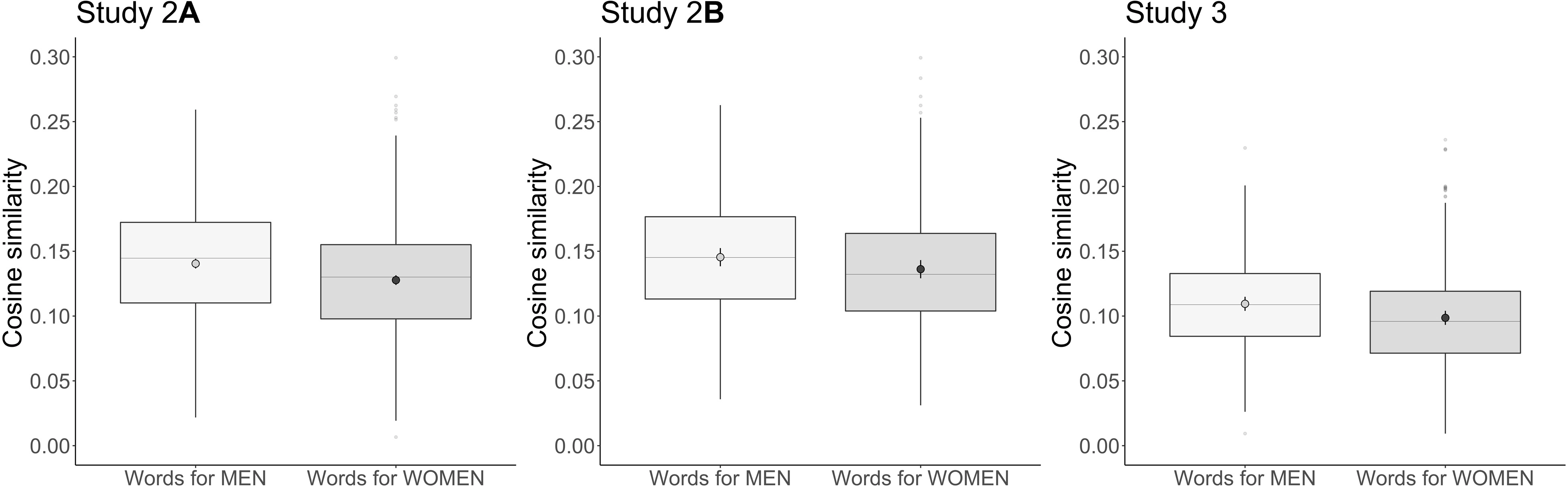
❗이 연구에서 발견한 놀라운 사실은!
지금까지의 여성과 남성에 대한 심리적 고정관념에 대한 연구에서 성별 고정관념은 종종 대칭적인 것으로 나타났다.
예를 들어, 여성은 "용감함" 과 같은 행위적 특성보다는 "동정심"과 같은 공동체적 특성을 갖는 것으로 정형화된 반면,
남성은 공동체적 특성보다는 행위적 특성을 갖는 것으로 고정관념화 된다.
그러나 이 연구 논문에서는 Collective Concepts, 집단적 개념에서 성 고정관념적 연관성이 비대칭적일 것이라고 예측했다.
즉, 남성 을 나타내는 단어는 일반적인 person-descriptor 특성("용감함"과 "자비로운" 둘 다)에 대한 사용이 유사할 수 있는 반면,
여성을 나타내는 단어는 보다 구체적인 집합에 대한 사용이 유사할 수 있다.(예를 들어 "용감함" 보다는 "자비심")
그니까,
사람이라는 단어를 나타낼 수 있는 단어들(예를 들어 "용감함" 과 "자비심")이**남성**이라는 단어와는 유사도가 동시에 높지만,**여성**의 경우는 특정 단어들만 유사도가 높다? 는 의미 같음.
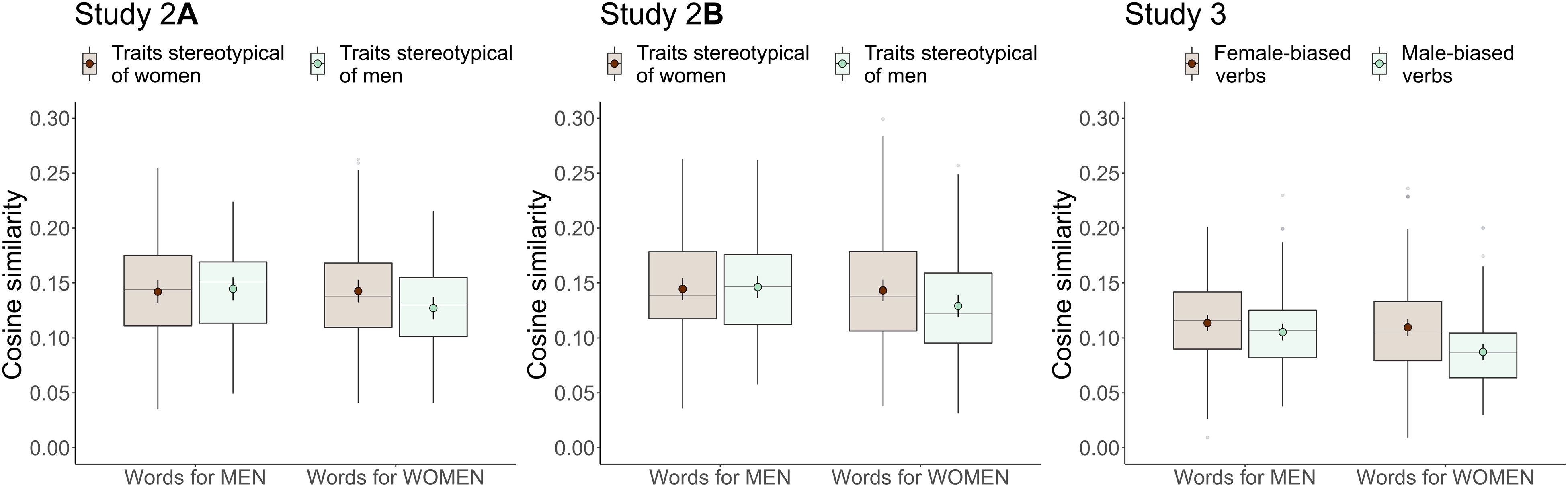
위 결과를 보면 남성의 경우 남성 고정관념 단어, 여성 고정관념 단어간의 유사도 차이가 거의 없는데, 여성의 경우 그 차이가 더 뚜렷하다는 것..
즉 여성에 대한 단어(words for women)은 여성의 정형으로 평가된 trait word(Traits stereotypical of women)와 더 유사한 언어적 맥락에서 나타났다.
🔎 Study 2B.
Study 2가 3명의 평가자에 의해 평가된 person-descriptor traits에 의존했다면, Study 2B는 심리학의 성별 고정관념 문헌에서 추출한 178개의 person-descriptor 목록을 가지고 실험했다.
결과는 동일했다.
🔎 Study 3. Trait words 대신 동사(verb)를 조사
동일하게 남성에 대한 단어는 언어적 맥락이 남성 및 여성 편향된 person 동사의 맥락과의 유사도 간의 차이가 거의 없었지만,
여성에 대한 단어는 남성 편향 동사보다 여성 편향 동사와의 유사도가 더 높았다.
이게 정확한 분석인가.. 에 대해 묻는다면
이 논문이 사용한 단어 임베딩이 추출된 말뭉치에서 남성에 대한 단어는 여성에 대한 단어보다 훨씬 더 자주 발생하지 않았다.
따라서 빈도의 차이는 사람(person)의 집합적 개념이 여성(women)보다 (men)과 더 유사하다는 이 논문의 발견을 설명할 수 없다.
새로운 통찰력을 주는 논문이었다!!
사실 어떻게 실험하고 계산했는지를 보기 위해 읽은거라, Materials And Methods에 대한 부분은 다음 포스트에서 다루는 걸로..
