❓자연어 처리는 어떤 문제를 해결하는가?
크게 💡텍스트 분류, 텍스트 유사도, 텍스트 생성, 기계 독해💡 - 4가지 문제가 있다.
📌단어 표현
단어 표현은 모든 자연어 처리 문제의 기본 바탕이 되는 개념이다.
자연어를 어떻게 표현할지 정하는 것이 문제를 해결하기 위한 출발점이다.
데이터를 이해하는 것이 매우 중요한데, 데이터가 어떤 구조이고, 어떤 특성이 있는지 파악한 후 모델을 만드는 과정이 필요하다.
어떤 방식으로 텍스트를 표현해야 자연어 처리 모델에 적용할 수 있을까?에 대한 답을 찾는 것이 "단어 표현(Word Presentation)" 분야다.
언어적인 특성을 반영해서 단어를 수치화하는 방법을 찾는다. 이때 "Word Embedding", 즉 단어 임베딩 또는 "Word vector", 단어 벡터로 표현하기도 한다.
단어 표현 자체가 계속 연구되는 분야이므로 다양한 방법이 있다.
단어를 표현하는 가장 기본적인 방법이 💡원-핫 인코딩(one-hot encoding)💡 방식이다. 0 혹은 1 만 갖는 하나의 벡터(vector)로 표현하는 방법이다.
예를 들어 6개의 단어를 표현해야 한다고 할 때, 각 단어를 표현하는 벡터의 크기는 6이 되고, 각 단어의 벡터는 총 6개의 값을 가지며, 이 중에 하나만 1이 된다.
간단하며 이해하기 쉬운 방법이지만, 문제점이 있다.
- 표현해야 하는 단어의 개수가 수십만, 수백만 개를 넘어가면 각 단어 벡터의 크기가 너무 커지고 매우 비효율적이다.
- 단순히 단어가 뭔지만 알려 줄 수 있고, 벡터값 자체에는 단어의 의미나 특성이 전혀 표현되지 않는다.
이에 따라 다른 인코딩 방법들이 제안되었는데, 벡터의 크기가 작으면서도 벡터가 단어의 의미를 표현할 수 있는 방법들로, 💡분포 가설(distributed hypothesis)💡을 기반으로 한다.
🔎 분포 가설(Distributed Hypothesis): 같은 문맥의 단어, 즉 비슷한 위치에 나오는 단어는 비슷한 의미를 가진다, 는 개념
어떤 글에서 비슷한 위치에 존재하는 단어는 단어 간의 유사도가 높다고 판단하는 방법으로, 크게 두 가지 방법이 있다.
📌 카운트 기반(count-base) 방법
어떤 글의 문맥 안에 단어가 동시에 등장하는 횟수를 세는 방법이다.
영어로 Co-occurrence라고 한다.
기본적으로 동시 등장 횟수를 하나의 행렬로 나타낸 뒤 그 행렬을 수치화해서 단어 벡터로 만드는 방법을 사용하는 방식이다.
- 특이값 분해(Singular Value Decomposition, SVD)
- 잠재의미분석(Latent Semantic Analysis, LSA)
- Hyperspace Analogue to Language(HAL)
- Hellinger PCA(Principal Component Analysis)
위 방법들 모두 출현 행렬(Co-occurrence Matrix)을 만들고 그 행렬들을 변형하는 방식이다.
카운트 기반 방법의 장점은 빠르다는 것으로, 적은 시간으로 단어 벡터를 만들 수 있다. 예측(predictive) 방법보다 이전에 만들어진 방법이지만 데이터가 많을 경우 효율적이어서 아직까지도 많이 사용한다.
📌예측(predictive) 방법
예측(predictive) 방법이란 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식이다.
- Word2vec
- NNLM(Neural Network Language Model)
- RNNLM(Recurrent Neural Network Language Model)
🔎 Word2Vec
가장 많이 사용되는 단어 표현 방법, Word2Vec 이다.
CBOW(Continuous Bag of Words)와 Skip-Gram 이라는 두 가지 모델로 나뉜다.
CBOW는 어떤 단어를 문맥 안의 주변 단어들을 통해 예측하는 방법이고,
Skip-Gram은 반대로 어떤 단어를 가지고 특정 문맥 안의 주변 단어들을 예측하는 방법이다.
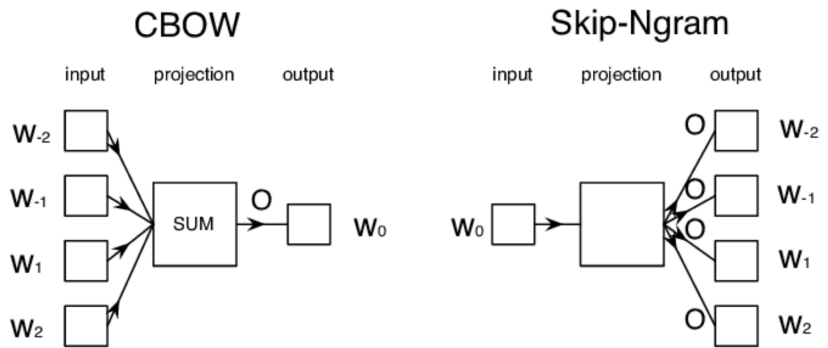
👉 CBOW의 학습 순서는
- 각 주변 단어를 one-hot 벡터로 만들어 입력값으로 사용(입력층 벡터)
- 가중치 행렬(weight matrix)을 각 원-핫 벡터에 곱해서 n-차원 벡터를 만든다(N-차원 은닉층)
- 만들어진 n-차원 벡터를 모두 더한 후 개수로 나눠 평균 n-차원 벡터 만든다(출력층 벡터)
- n-차원 벡터에 다시 가중치 행렬을 곱해서 one-hot 벡터와 같은 차원의 벡터로 만든다.
- 만들어진 벡터를 실제 예측하려고 하는 단어의 one-hot 벡터와 비교해서 학습
👉 Skip-Gram의 학습 순서는
- 하나의 단어를 one-hot 벡터로 만들어서 입력값으로 사용(입력층 벡터)
- 가중치 행렬(weight matrix)을 각 원-핫 벡터에 곱해서 n-차원 벡터를 만든다(N-차원 은닉층)
- n-차원 벡터에 다시 가중치 행렬을 곱해서 one-hot 벡터와 같은 차원의 벡터로 만든다.(출력층 벡터)
- 만들어진 벡터를 실제 예측하려고 하는 단어의 one-hot 벡터와 비교해서 학습
즉 두 방법의 차이점은 입력값으로 사용하는 단어의 개수!
CBOW는 여러 개의 단어를 사용, 학습을 위해 하나의 단어와 비교
Skip-Gram은 입력값이 하나의 단어를 사용, 학습을 위해 주변의 여러 단어와 비교
장점: 단어 간의 유사도를 잘 측정하고, 단어들의 복잡한 특징까지도 잡아낸다. + 유의미한 관계 측정 가능. (예를 들어 '엄마', '아빠'라는 단어 벡터 사이의 거리 = '여자'와 '남자'라는 단어 벡터 사이의 거리)
보통 📌Skip-Gram이 성능이 좋다고 하지만, 적절하게 선택하는 것이 중요하다.
또한 보통 📌예측 기반 방법을 사용,
카운트 기반 + 예측 기반 모두 포함하는 📌Glove 라는 방법도 자주 사용된다.
항상 가장 좋은 성능을 내는 유일한 방법이 있는 것은 아니므로, 해결해야 하는 문제에 따라 맞게 사용하는 것이 중요하다.
출처: "텐서플로 2와 머신러닝으로 시작하는 자연어 처리" - 전창욱, 최태균, 조중현, 신성진 지음
