분석
1. 비교연산: 하나의 합병 단계에서 최대 n번의 비교연산이 필요함으로 최대 nlog2n번 필요하다.
2. 이동연산: 부분 배열에 들어 있는 요소의 개수가 n인 경우, 레코드의 이동이 2n번 발생하므로 하나의 합병 단계에서 2n개가 필요하다. 따라서 log₂n개의 합병 단계가 필요하므로 총 2nlog₂n개의 이동 연산이 필요하다.
결론 : 둘 다 O(nlog₂n)의 복잡도를 가진다.
3. 장점 : 안정적인 정렬 방법, 데이터의 분포에 영향을 덜 받는다. 최악, 평균 ,최선 모두 O(nlog₂n)인 정렬 방법이다.
4. 단점 : 임시 배열이 필요하다는 것, 레코드들의 크기가 큰 경우, 이동 횟수가 많으므로 매우 큰 시간적 낭비를 초래
퀵 정렬
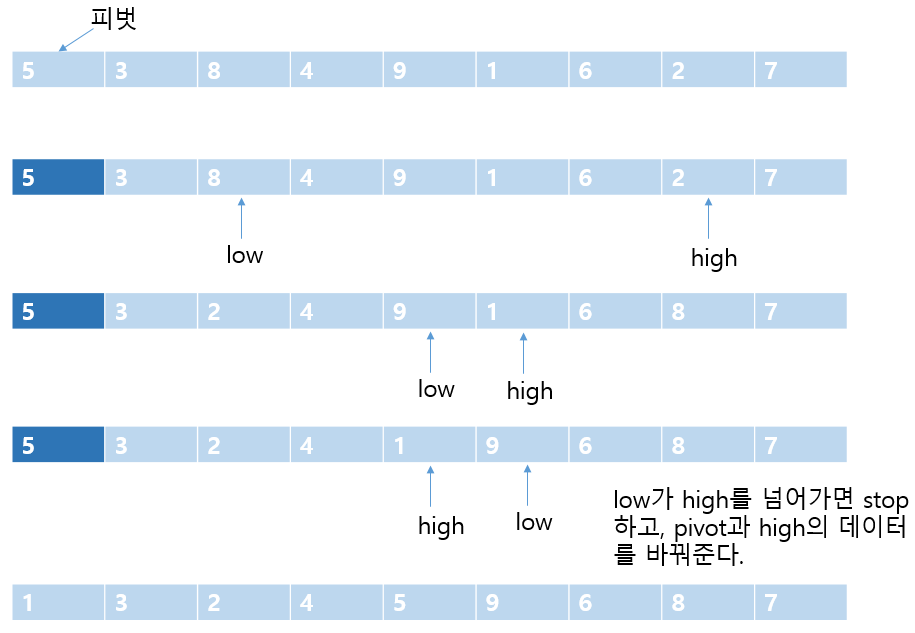
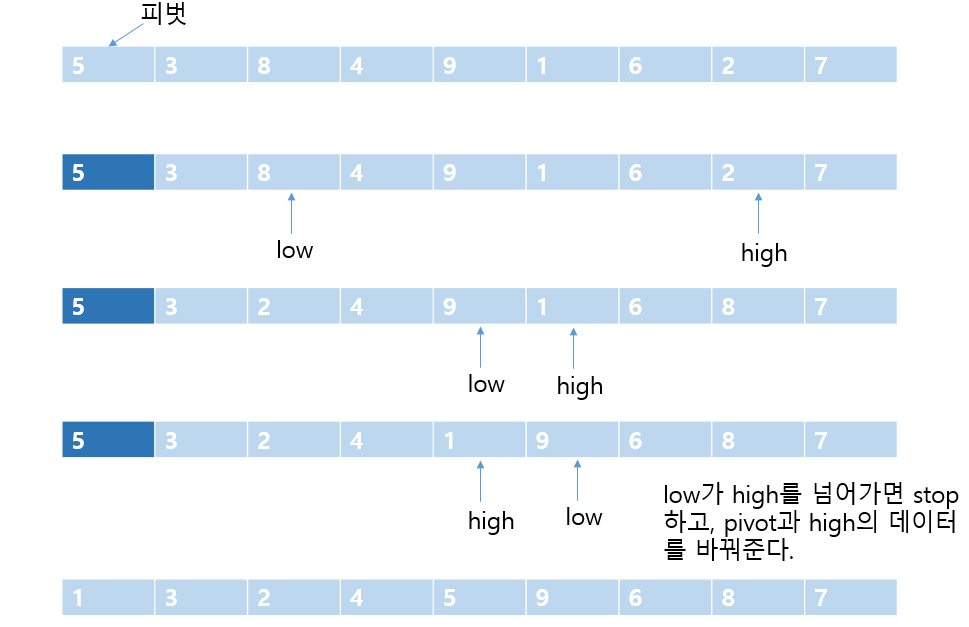
분할 정복 기법에 근거하고, 합병 정렬과 비슷하게 전체 리스트를 2개의 부분 리스트로 분할하고, 각각의 부분 리스트를 다시 퀵정렬하는 분할-정복법을 사용한다. 하지만 합병 정렬과 다르게 비균등하게 분할한다. 먼저 리스트 안에서 한 요소를 피벗(pivot)으로 설정한다. 첫 번째 요소를 피벗으로 설정하고, 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고 큰 요소들은 모두 피벗의 오른쪽으로 옮겨진다. 결과적으로 왼쪽은 피벗보다 작은, 오른쪽은 피벗보다 큰 요소들로 이루어진다. 이 상태에서 피벗을 제외한 왼쪽, 오른쪽 리스트를 다시 정렬하면 전체 리스트가 정렬된다. 위와 같은 작업이 2개로 나뉘어지는 부분 리스트들이 더 이상 분할이 불가능할 때까지 나뉘어진다.
코드
#include <stdio.h>
#define MAX_SIZE 9
//int n = 9;
int list[MAX_SIZE] = { 9, 8, 7, 6, 5, 4, 3, 2, 1 };
//int list[MAX_SIZE] = { 9, 9,9,9,9,9,9,9,9};
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) )
//
void print(int list[], int n)
{
int i;
for (i = 0; i < n; i++)
printf("%d ", list[i]);
printf("\n");
}
//
int partition(int list[], int left, int right)
{
int pivot, temp;
int low, high;
low = left;
high = right + 1;
pivot = list[left]; /* 피벗 설정 */
do {
do
low++;
/* 왼쪽 리스트에서 피벗보다 큰 레코드 선택 */
while (low <= right && list[low] < pivot);
do
high--;
/* 오른쪽 리스트에서 피벗보다 작은 레코드 선택 */
while (high >= left && list[high] > pivot);
if (low < high) SWAP(list[low], list[high], temp); /* 선택된 두 레코드 교환 */
} while (low < high); /* 인덱스 i,j가 엇갈리지 않는 한 반복 */
SWAP(list[left], list[high], temp); /* 인텍스 j가 가리키는 레코드와 피벗 교환 */
return high;
}
//
void quickSort(int list[], int left, int right)
{
if (left < right) { /* 리스트에 2개 이상의 레코드가 있을 경우 */
int q = partition(list, left, right);
//print(list, 9);
quickSort(list, left, q - 1); /* 왼쪽 부분리스트를 퀵정렬 */
quickSort(list, q + 1, right); /* 오른쪽 부분리스트를 퀵정렬 */
}
}
//
int main()
{
print(list, 9);
quickSort(list, 0, 8);
print(list, 9);
}
분석
1. 비교연산 : O(nlog₂n) 여기서 레코드의 이동 횟수는 비교 횟수보다 적으므로 무시할 수 있다.
2. 최악의 경우 : 리스트가 계속 불균형하게 나누어질 경우, O(n²)이 된다. 이럼에도 불구하고, 평균적인 경우의 시간 복잡도가 O(nlog₂n)으로 나타난다.
3. 장점 : 속도가 빠르고 추가 메모리 공간을 필요로 하지 않는다.
4. 단점 : 정렬되어 있는 리스트에 대해서 오히려 수행시간이 더 많이 걸린다.

한성공대생