
정의
물건을 크기순으로 오름차순(ascending order)이나 내림차순(descending order)으로 나열하는 것을 의미.
분류
단순하지만 비효율적인 방법 - 삽입 정렬, 선택 정렬, 버블 정렬 등.
복잡하지만 효율적인 방법 - 퀵 정렬, 히프 정렬, 합병 정렬, 기수 정렬 등.
내부 정렬 : 정렬하기 전에 모든 데이터가 메인 메모리에 올라와 있는 정렬.
외부 정렬: 외부 기억 장치에 대부분의 데이터가 있고 일부만 메모리에 올려놓은 상태에서 정렬.
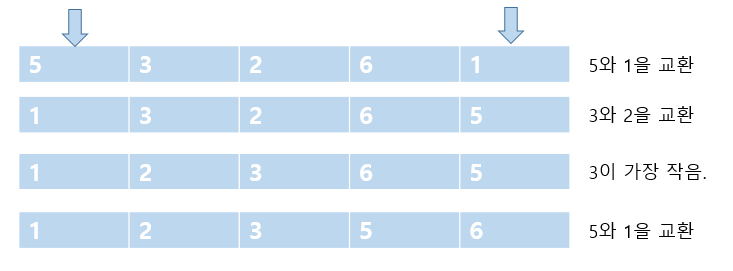
선택 정렬
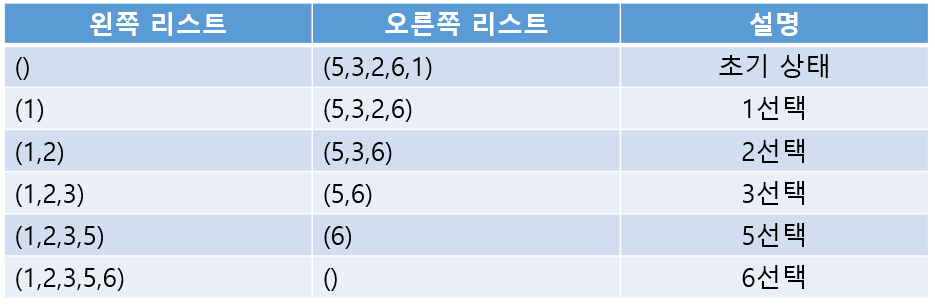
왼쪽 리스트와 오른쪽 리스트, 두 개의 리스트가 있다고 가정하고, 왼쪽 리스트에는 정렬이 완료된 숫자들이 들어가게 되며 오른쪽 리스트에는 정렬되지 않은 숫자들이 들어 있다. 초기 상태에서 왼쪽 리스트는 비어 있고 정렬되어야 할 숫자들은 모두 오른쪽 리스트에 들어 있다. 오른쪽 리스트에서 가장 작은 숫자를 선택하여 왼쪽 리스트로 이동하는 작업을 되풀이 한다. 오른쪽 리스트가 공백이 될 때까지 반복한다.
>코드
#include<stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10
#define SWAP(x,y,t) ((t)=(x), (x)=(y), (y)=(t))
void selectionSort(int list[], int n)
{
int i, j, least, temp;
for (i = 0;i < n;i++) {
least = i;
for (j = i + 1; j < n;j++)
if (list[least] > list[j]) least = j;
SWAP(list[i], list[least], temp);
}
}
void print(int list[], int n)
{
int i;
for (i = 0;i < n;i++)
printf("%d ", list[i]);
printf("\n");
}
void main()
{
int i;
int a[MAX_SIZE] = { 1,3,4,9,7,6,5,8,2,10 };
printf("정렬 전: ");
print(a, 10);
selectionSort(a, 10);
printf("정렬 후: ");
print(a, 10);
int list[10];
for (i = 0;i < 10;i++)
list[i] = rand() % 100;
printf("정렬 전: ");
print(list, 10);
selectionSort(list, 10);
printf("정렬 후: ");
print(list, 10);
}
분석
비교횟수: (n-1) + (n-2) + ... + 1 = n(n-1)/2 = O(n^2)
레코드 교환 횟수는 외부 루프의 실행 횟수와 같으며 한번 교환하기 위하여 3번의 이동이 필요하므로 3(n-1)
장점 : 자료 이동 횟수가 미리 결정된다.
단점 : 이동 횟수가 상당히 큰 편이고, 안정성을 만족하지 않는다.
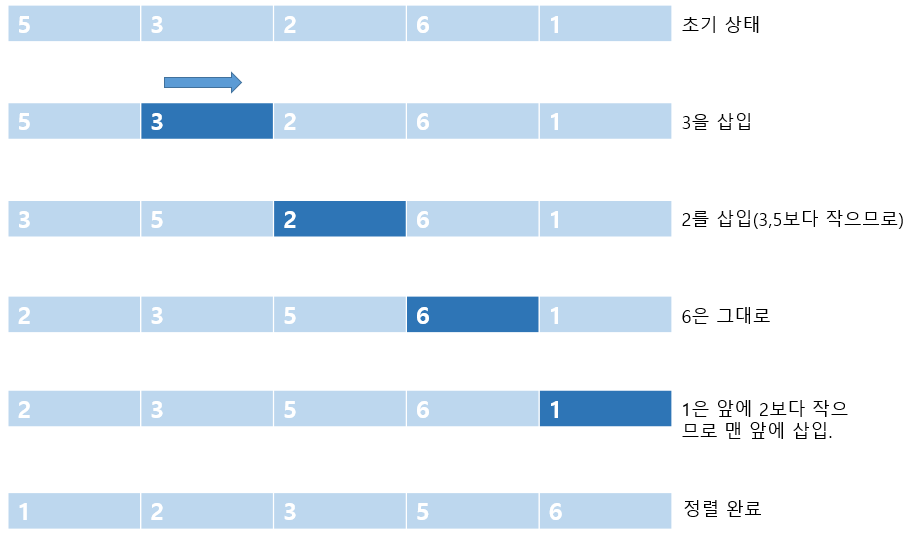
삽입 정렬
정렬되어 있는 리스트에 새로운 레코드를 적절한 위치에 삽입하는 과정을 반복.
코드
#include<stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10
#define SWAP(x,y,t) ((t)=(x), (x)=(y), (y)=(t))
void insertionSort(int list[], int n)
{
int i, j, key;
for (i = 1;i < n;i++) {
key = list[i];
for (j = i - 1;j >= 0 && list[j] > key;j--)
list[j + 1] = list[j];
list[j + 1] = key;
}
}
void print(int list[], int n)
{
int i;
for (i = 0;i < n;i++)
printf("%d ", list[i]);
printf("\n");
}
void main()
{
int i;
int a[6] = { 1,3,4,9,7,6 };
printf("정렬 전: ");
print(a, 6);
insertionSort(a,6);
printf("정렬 후: ");
print(a, 6);
int n = MAX_SIZE;
int list[MAX_SIZE];
for (i = 0;i < n;i++) {
list[i] = rand() % n + 1;
}
printf("정렬 전: ");
print(list, n);
insertionSort(list, n);
printf("정렬 후: ");
print(list, n);
}분석
비교 횟수: n-1번
총 이동 횟수: 2(n-1)번
시간 복잡도: O(n), 최악일 경우:입력 자료가 역순일 경우 -> O(n^2)
장점: 레코드 수가 적을 경우 알고리즘 자체가 매우 간단하므로 다른 복잡한 정렬보다 유리할 수 있고, 대부분의 레코드가 이미 정렬되어 있는 경우에 매우 효율적인다.
단점: 레코드 양이 많고 레코드 크기가 클 경우 적합하지 않다.
버블 정렬
인접한 2개의 레코드를 비교하여 크기가 순서대로 되어있지 않으면 서로 교환하는 비교-교환 과정을 리스트의 왼쪽 끝에서 시작하여 오른쪽 끝까지 진행한다. 이 과정이 한번 완료되면 가장 큰 레코드가 리스트의 오른쪽 끝으로 이동된다. 이 과정이 전체가 정렬이 될 때까지 반복을 한다. 정렬이 안된 오른쪽 리스트를 한번 스캔하면 오른쪽 리스트의 오른쪽 끝에 가장 큰 레코드가 위치하게 되고, 오른쪽 리스트는 추가된 레코드를 포함하여 정렬된 상태가 된다.

코드
#include<stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10
#define SWAP(x,y,t) ((t)=(x), (x)=(y), (y)=(t))
void bubbleSort(int list[], int n)
{
int i, j, temp;
for (i = n - 1;i > 0;i--) {
for (j = 0;j < i;j++)
if (list[j] > list[j + 1])
SWAP(list[j], list[j + 1], temp);
}
}
void print(int list[], int n)
{
int i;
for (i = 0;i < n;i++)
printf("%d ", list[i]);
printf("\n");
}
void main()
{
int i;
int a[6] = { 1,3,4,9,7,6 };
printf("정렬 전: ");
print(a, 6);
bubbleSort(a,6);
printf("정렬 후: ");
print(a, 6);
int n = MAX_SIZE;
int list[MAX_SIZE];
for (i = 0;i < n;i++) {
list[i] = rand() % n + 1;
}
printf("정렬 전: ");
print(list, n);
bubbleSort(list, n);
printf("정렬 후: ");
print(list, n);
}분석
비교 횟수: 최선, 평균, 최악 -> O(n^2)
이동 횟수: 최악 -> 역순으로 정렬되어 있는 경우 비교연산*3, 최선->이미 정렬되어 있는 경우 => 결국 O(n^6)
단점: 순서에 맞지 않은 요소를 인접한 요소와 교환한다. 일반적으로 자료의 교환 작업이 자료의 이동작업보다 더 복잡하기 때문에 버블 정렬은 그 단순성에도 불구하고 거의 쓰이지 않는다.
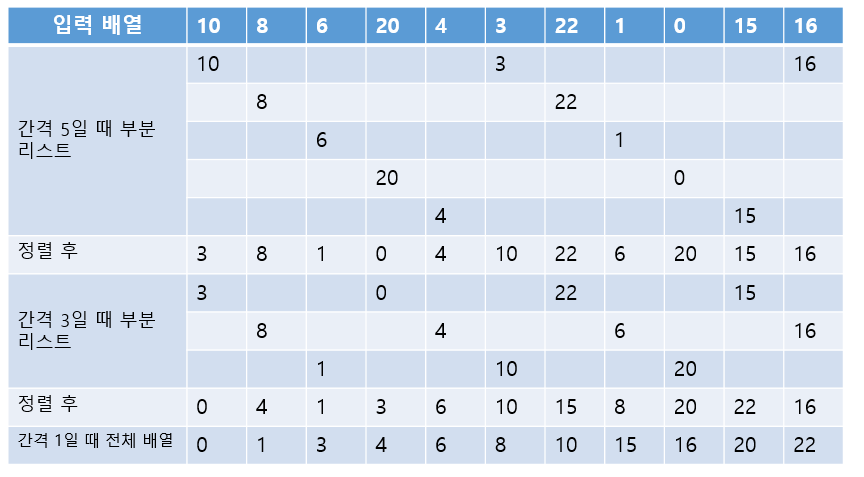
쉘 정렬
삽입 정렬과는 다르게 쉘 정렬은 전체의 리스트를 한 번에 정렬하지 않는다. 대신에 먼저 정렬해야할 리스트를 일정한 기준에 따라 분류하여 연속적이지 않은 여러 개의 부분 리스트를 만들고, 각 부분 리스트를 삽입 정렬을 이용하여 정렬한다. 모든 부분 리스트가 정렬되면 쉘 정렬은 다시 전체 리스트를 더 적은 개수의 부분 리스트로 만든 후에 알고리즘을 되풀이 한다. 위의 과정은 부분 리스트의 개수가 1이 될 때까지 되풀이 된다. 부분 리스트를 구성할 때는 각 k번째 요소를 추출한다. 각 스텝마다 k를 줄여가므로 반복될 때마다 하나의 부분 리스트에 속하는 레코드들의 개수는 증가된다. 마지막 스텝에서는 k가 1이된다.
코드
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10
#define SWAP(x,y,t) ((t) =(x),(x)=(y),(y)=(t))
void inc_insertion_sort(int list[], int first, int last, int gap)
{
int i, j, key;
for (i = first + gap;i <= last;i = i + gap) {
key = list[i];
for (j = i - gap;j >= first && key < list[j];j = j - gap)
list[j + gap] = list[j];
list[j + gap] = key;
}
}
void shell_sort(int list[], int n)
{
int i, gap;
for (gap = n / 2;gap > 0;gap = gap / 2)
{
if ((gap % 2) == 0) gap++;
for (i = 0;i < gap;i++)
inc_insertion_sort(list, i, n - 1, gap);
}
}
void printList(int list[], int n)
{
int i;
for (i = 0;i < n;i++)
printf("%d ", list[i]);
printf("\n");
}
void main()
{
int i;
int a[6] = { 1,3,4,9,7,6 };
printf("정렬 전: ");
printList(a, 6);
shell_sort(a, 6);
printf("정렬 후: ");
for (i = 0;i < 6;i++)
printf("%d ", a[i]);
printf("\n");
int n = MAX_SIZE;
int list[MAX_SIZE];
for (i = 0;i < n;i++)
list[i] = rand() % n + 1;
printf("정렬 전: ");
printList(list, n);
shell_sort(list, n);
printf("정렬 후: ");
printList(list, n);
}분석
장점1: 연속적이지 않은 부분 리스트에서 자료의 교환이 일어나면 더 큰 거리를 이동한다. 반면 삽입정렬에서는 한 번에 한 칸씩만 이동한다. 따라서 교환되는 자료들이 삽입 정렬보다는 최종 위치에 더 가까이 있을 가능성이 높아진다.
장점2: 부분 리스트는 어느 정도 정렬이 된 상태이기 때문에 부분 리스트의 개수가 1이 되게 되면 쉘 정렬은 기본적으로 삽입 정렬을 수행하는 것이지만 빠르게 수행된다.
시간 복잡도: 최악 -> O(n^2), 평균 -> O(n^1.5)
합병 정렬
하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트를 얻는 정렬이다. 분할 정복 기법을 기반으로 작은 2개의 문제로 분리하고, 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 기법이다. 분리된 문제가 아직도 해결하기 어렵다면(충분히 작지 않다면) 분할 정복 기법을 연속하여 다시 적용한다.
1. 분할: 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
2. 정복: 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 기법을 적용한다.
3. 결합: 정렬된 부분 배열들을 하나의 배열에 통합한다.
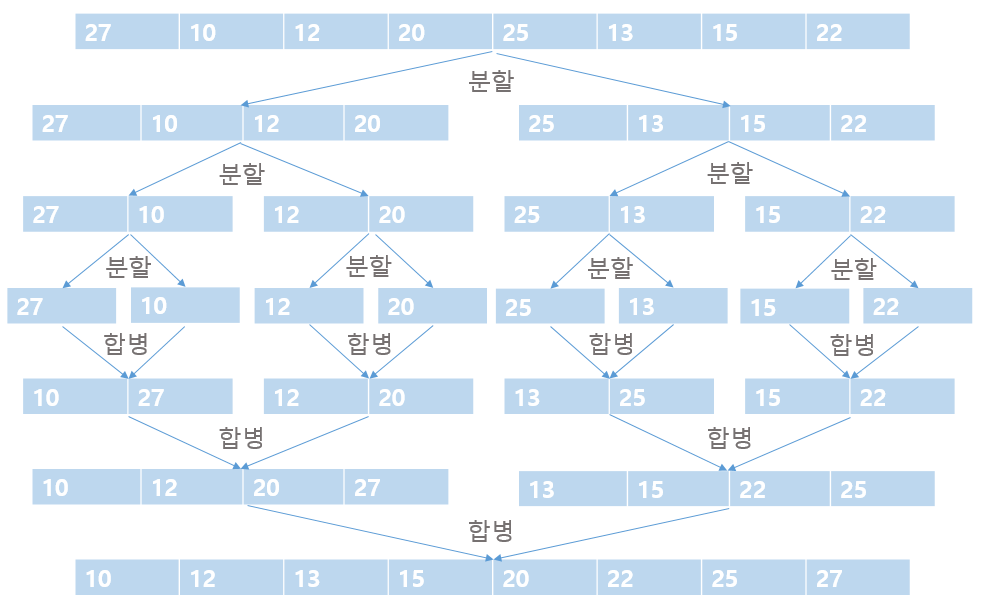
실제로 합병이 이루어지는 시점은 2개의 리스트를 합병하는 단계이다. 그리고 그림상으로는 리스트가 2개로 나뉘어지지만 코드로 살펴보면 구간을 나누는 것 뿐이고, 합병을 하면서 2개 리스트의 각 데이터들을 비교해가면서 작은 데이터를 먼저 골라서 새롭게 생성한 리스트에 순서대로 넣고 그 리스트를 반환하는게 합병에서 이뤄지는 작업이다.
코드
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZES 20
//int sorted[MAX_SIZES];
void merge(int list[], int left, int mid, int right)
{
int i, j, k, l;
i = left; j = mid + 1; k = left;
//int *sorted=new int[right+1];
int* sorted = (int*)malloc(sizeof(int) * (right + 1));
/* 분할 정렬된 list의 합병 */
while (i <= mid && j <= right) {
if (list[i] <= list[j])
sorted[k++] = list[i++];
else
sorted[k++] = list[j++];
}
if (i > mid) /* 남아 있는 레코드의 일괄 복사 */
for (l = j; l <= right; l++)
sorted[k++] = list[l];
else /* 남아 있는 레코드의 일괄 복사 */
for (l = i; l <= mid; l++)
sorted[k++] = list[l];
/* 배열 sorted[]의 리스트를 배열 list[]로 재복사 */
for (l = left; l <= right; l++)
list[l] = sorted[l];
// delete []sorted;
free(sorted);
}
//
void mergeSort(int list[], int left, int right)
{
int mid;
if (left < right) {
mid = (left + right) / 2; /* 리스트의 균등 분할 */
mergeSort(list, left, mid); /* 부분 리스트 정렬 */
mergeSort(list, mid + 1, right); /* 부분 리스트 정렬 */
merge(list, left, mid, right); /* 합병 */ // 안나눠질때까지 나눈 후 merge함수 실행
}
}
void main()
{
int list[10] = { 6,56,3,2,47,4,5,12,23,10 };
// int list[MAX_SIZES];
int n = 10;
int i;
printf("정렬 전: \n");
for (i = 0;i < n;i++)
printf("%d ", list[i]);
printf("\n");
mergeSort(list, 0, n - 1);
printf("정렬 후: \n");
for (i = 0;i < n;i++)
printf("%d ", list[i]);
printf("\n");
}

한성공대생