개요
Decision Tree Classifier는 트리 모양의 순차형 다이어그램을 통해 주어진 데이터를 분류한다. 데이터를 기반으로 조건을 자동 생성 및 판단하고, 이를 통해 최종 결과에 이른다. 대표적인 트리 생성 알고리즘에는 CART가 있다.
트리 분할
기본적으로 클래스별로 데이터를 잘 분류할 수 있으면 좋은 분할이라 한다. 그러나 하나의 Feature와 그 Feature 값으로 전체 데이터를 클래스 별로 완벽하게 분류할 수 없으므로, 단계적으로 분할 조건을 탐색한다.
트리 분할 측정 척도
각 Feature와 그 값들이 가장 잘 조합된 결과를 선택하기 위해 분할이 얼마나 잘 이루어졌는지 측정한다.
지니 계수 (Gini Impurity)
where : 번째 클래스에 해당하는 데이터의 비율
데이터가 클래스별로 고르게 분포되어 있는지, 아니면 특정 클래스에 편중되어 분포되어 있는지 나타낸다. 특정 클래스에 치우칠수록 값이 작고, 클래스별 분포가 균등할수록 값이 크다.
분할한 결과로 만들어진 각 자식 노드에 대해서 지니 계수를 구하고 가중 평균하여 분할 결과를 측정한다.
where : 자식 노드 집합, : 자식 노드 에 있는 데이터의 지니 계수, : 부모 노드 에 속하는 데이터 수, : 자식 노드 에 속하는 데이터 수
해당 값이 작을수록 분할을 잘 수행했음을 나타낸다.
정보 이득
트리 분할 후 얼마나 순도가 더 좋아졌는지 평가한다. 즉, 트리 분할을 통해 불확실성이 얼마나 낮아졌는지 측정한다.
✏️ 불확실성이 높다는 것은 클래스 별로 고르게 분포되어 있음을 의미한다. 모든 클래스에 대해 동일한 비율로 데이터가 존재하면, 임의로 데이터를 뽑았을 때 해당 데이터가 어떤 클래스에 속할지 불확실하다.
정보 이득은 트리 분할 전후의 엔트로피 값 차이로 계산한다.
where : 번째 클래스에 해당하는 데이터의 비율
정보 이득이 클수록, 즉 트리 분할 전후의 엔트로피의 차가 클수록 분할을 잘 수행했음을 나타낸다.
✏️ 지니 계수&엔트로피 계산
Decision Tree (CART 알고리즘 기반)
학습 데이터를 사용하여 각 노드를 왼쪽 자식 노드와 오른쪽 자식 노드로 분할해 가며 트리를 생성한다.
각 노드에서 분할을 위한 Feature와 해당 Feature의 값 조합을 Greedy 방식으로 탐색하며, 분할 후 만들어질 노드의 샘플 수가 일정 수준 이하이거나 트리의 깊이가 일정 수준 이상일 때 분할을 정지한다. 오분류율이 높거나 부적절한 추론 규칙을 가지고 있는 가지는 제거 (Pruning)한다. 분할되지 않은 마지막 노드에 대해서는 각 노드에 있는 데이터의 클래스 중 가장 다수의 클래스를 해당 노드의 클래스 라벨로 할당한다.
고객 신용 점수, 고객 세분화, 캠페인 반응 분석, 광고 효과 측정 등에 활용한다.
장단점
장점
직관적이고 이해하기 쉽다.
규칙 기반으로 분류/예측을 수행하고 결과 해석이 간단하다.
모델 시각화가 가능하고, 비전문가도 이해하기 쉽다.
데이터 전처리 부담이 적다.
범주형 데이터와 연속형 데이터를 모두 처리할 수 있다.
표준화나 정규화 등의 작업이 필요하지 않다.
이상치, 결측치에 덜 민감하다.
변수 중요도를 파악할 수 있다.
분할 기준으로 사용된 Feature를 기반으로 데이터에서 가장 중요한 변수를 쉽게 파악할 수 있다.
작은 데이터셋에 적합하다.
비교적 작은 데이터셋에서도 잘 동작하며, 빠르게 학습이 가능하다.
단점
과적합 가능성
나무가 깊게 성장할수록 학습 데이터에 과적합될 가능성이 높다. 이를 방지하기 위해 가지 치기, 최대 깊이 제한이 필요하다.
불안정성
데이터에 민감하여 작은 변화를 반영한 별도 트리를 생성할 수 있다. 이를 극복하기 위해 앙상블 기법이 자주 사용된다.
모델의 일반화 성능이 낮을 수 있다.
나무의 깊이에 따라 일반화 성능이 낮아질 수 있다.
단일 트리는 복잡한 데이터 특징을 반영하는 데 한계가 있다.
데이터셋 영향
큰 데이터셋에서는 분할 기준을 찾는 과정에서 계산량이 많아질 수 있다.
클래스 불균형 데이터에서는 잘못된 분류 결과를 계산할 가능성이 있다.
Random Forest
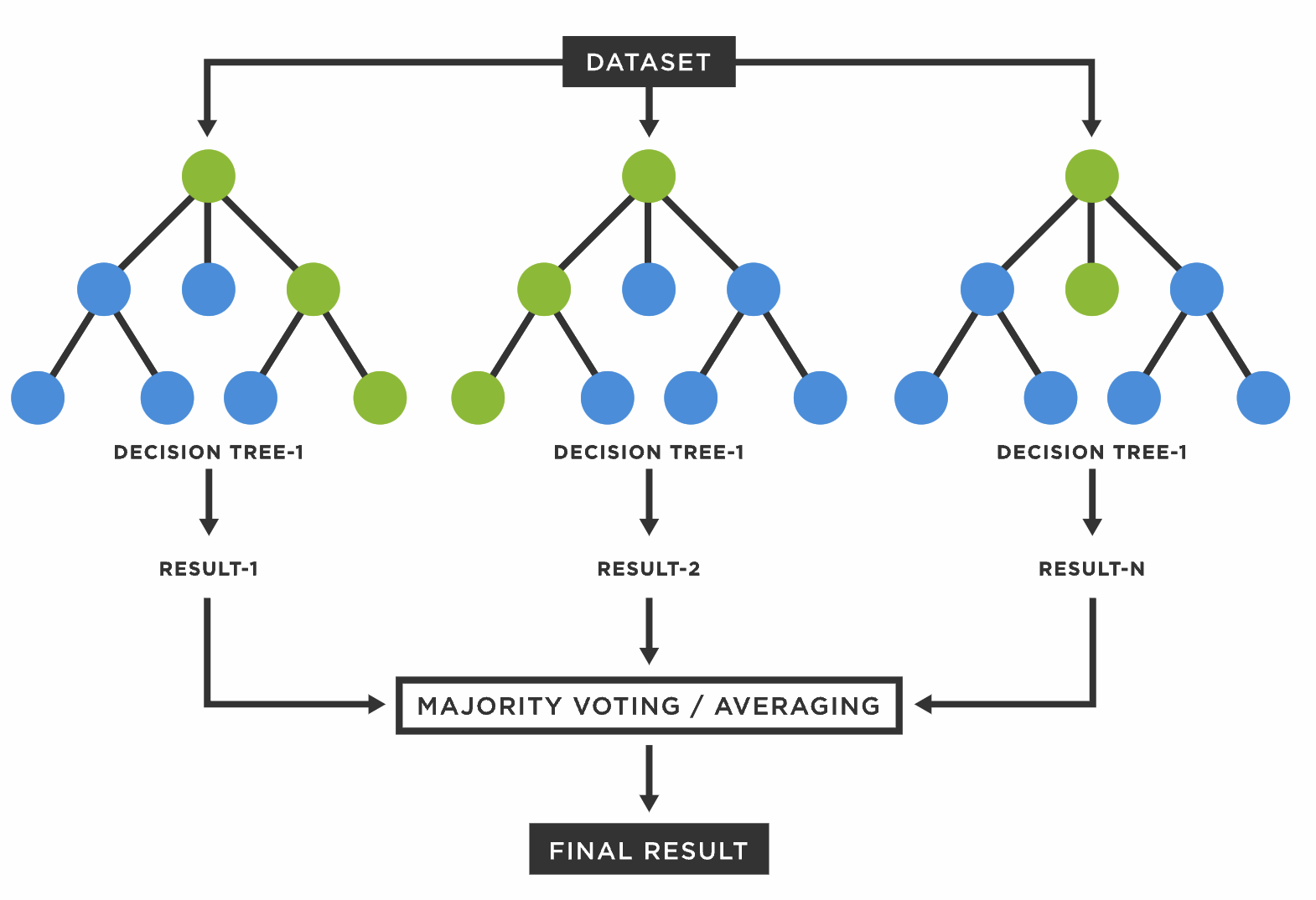
여러 개의 Decision Tree 모델을 조합하여 사용하는 Bagging 방식이다.
원본 데이터에서 무작위로 데이터를 추출하여 여러 개의 학습 데이터셋을 구축하고, 각 데이터셋에 대해 모델을 학습시켜 여러 개의 학습 모델을 생성한다. 이후 새로운 데이터가 들어오면 개별 학습 모델이 판단한 결과를 통합하여 다수 모델이 선택한 결과를 최종 결과로 선택한다.
✏️ 모든 Feature를 똑같이 모두 사용하면, Random Forest에서 사용하는 개별 모델이 비슷해지기 쉬워 큰 차이를 만들기 어렵다. 따라서 서로 다른 Feature Set을 임의로 구성해 개별 모델을 학습한다.
Decision Tree 기반 Boosting
같은 가중치를 가지는 여러 개의 성능이 낮은 모델을 생성하고, 오분류 데이터를 보완하는 방향으로 반복 학습하여 점진적으로 오차를 최소화하는 모델을 생성한다.
AdaBoost (Adaptive Boosting)
정확도가 높지 않은 약한 학습 모델을 연속적으로 이어붙여서 결과를 점진적으로 개선한다. 한 모델의 예측 결과를 다음 모델 학습에 반영하고, 앞에서 잘못 맞춘 데이터 샘플에 더 가중치를 주어서 다음 모델에서 더 집중적으로 학습할 수 있도록 한다.
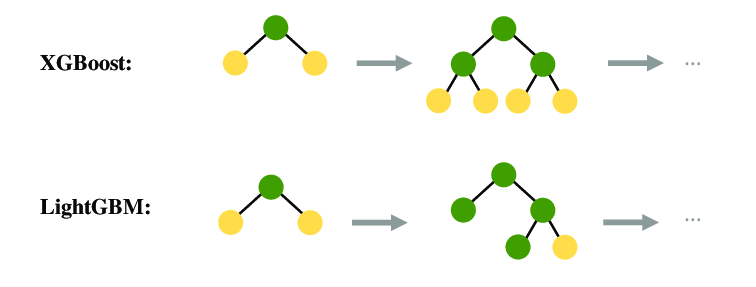
XGBoost (Extreme Gradient Boosting)
Depth-Wise 방식을 기반으로 순차적으로 이전 트리보다 더 나은 트리를 만들어내는 알고리즘으로, 예측 성능이 좋은 편이다. 변수 종류가 많고 데이터가 클수록 상대적으로 뛰어난 성능을 보인다. 복잡한 모델인 만큼 모델 해석에 어려움이 있다.
LightGBM (Light Gradient Boosting Method)
Leaf-Wise 방식을 채택하여 트리를 분할한다. XGBoost보다 빠르고 높은 정확도를 보여주는 경우가 많다. 변수 종류가 많고 데이터가 클수록 뛰어난 성능을 보인다.