개요
SVM (Support Vector Machine)은 클래스별 데이터를 가장 잘 구분하는 최적의 Hyperplane을 찾는 알고리즘이다. 최적의 하이퍼플레인은 하이퍼플레인에 의해 양분된 두 공간 내에 있는 가장 가까운 데이터 포인트 간의 거리 (Margin)이 최대가 되도록다.
✏️ Hyperplane (하이퍼플레인)?
데이터가 분포되어 있는 n차원 feature space를 두 공간으로 나누는 n−1차원의 평면
✏️ Support Vector (서포트 벡터)?
하이퍼플레인에 의해 양분된 두 공간 내에 있는 가장 가까운 데이터 포인트
동작 방식
하이퍼플레인도 하나의 부분 공간이므로, 하이퍼플레인은 같이 정의할 수 있다.
w⋅x+b=0
최적의 하이퍼플레인은 아래 조건을 만족해야 한다.
- 2개 클래스 중 한 쪽에 속한 모든 데이터 x에 대해 w⋅x+b>0
- 2개 클래스 중 다른 쪽에 속한 모든 데이터 x에 대해 w⋅x+b<0
- 서포트 벡터 사이의 거리인 Margin이 최대여야 한다.
Decision/Positive/Negative Hyperplane
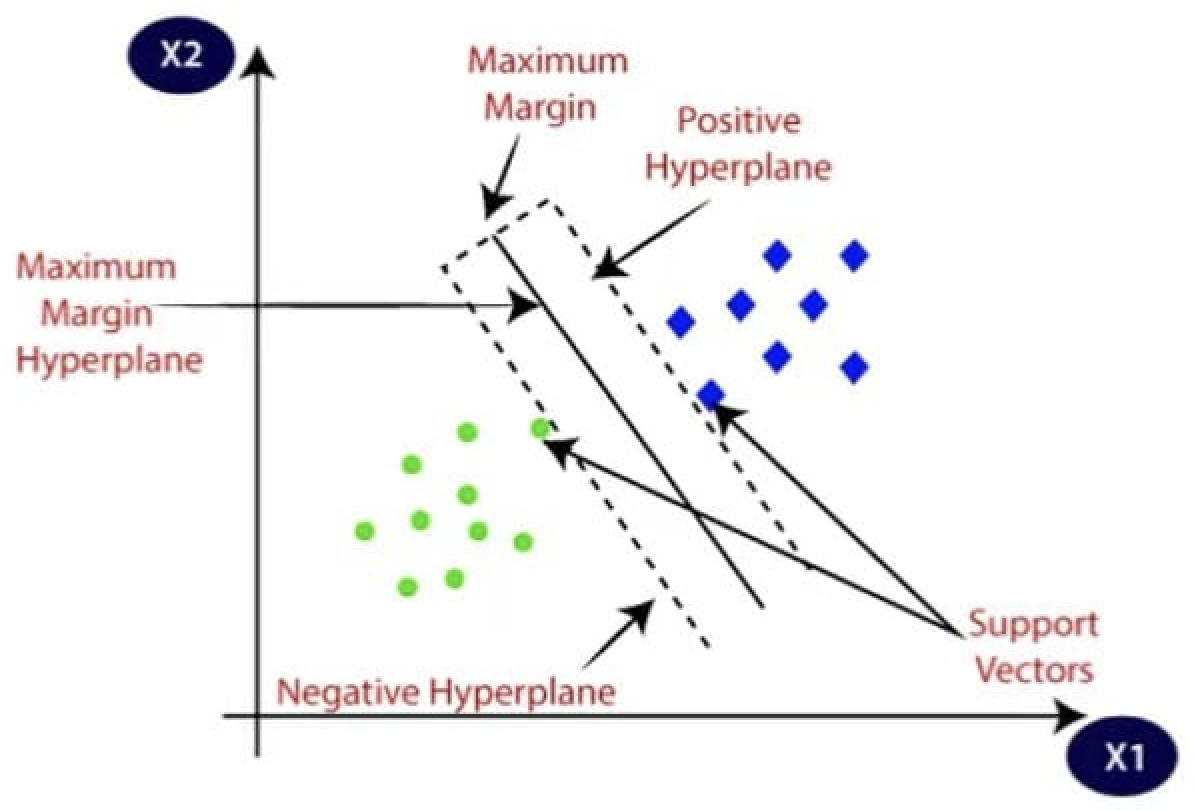
Decision Hyperplane
두 공간을 양분하는 하이퍼플레인
w⋅x+b=0
Positive Hyperplane
Desicion Hyperplane 위쪽에 평행한 하이퍼플레인
w⋅x(p)+b=1
Negative Hyperplane
Desicion Hyperplane 아래쪽에 평행한 하이퍼플레인
w⋅x(n)+b=−1
Positive/Negative Hyperplane은 위치한 공간에서 Desicion Hyperplane과 가장 가까운 데이터를 포함하며, 해당 데이터 포인트가 서포트 벡터이다.
데이터 양분
- 2개 클래스 중 한 쪽에 속한 모든 데이터 x에 대해 w⋅x+b>0
- 2개 클래스 중 다른 쪽에 속한 모든 데이터 x에 대해 w⋅x+b<0
위 조건을 양성/음성 하이퍼플레인에 대한 표현으로 바꾸면,
w⋅x(i)+b≥1 if y(i)=1w⋅x(i)+b≤−1 if y(i)=−1
where (x(i),y(i)): i번째 데이터의 feature와 class label
위 식을 하나로 정리하면,
y(i)(w⋅x(i)+b)≥1
Margin의 표현
양성 하이퍼플레인의 점 x(p)에서 직선 w⋅x+b=0 사이의 거리:
d(p)=∥w∥∣w⋅x(p)+b∣=∥w∥1
음성 하이퍼플레인의 점 x(n)에서 직선 w⋅x+b=0 사이의 거리:
d(n)=∥w∥∣w⋅x(n)+b∣=∥w∥1
따라서 Margin은 아래와 같이 표현할 수 있다.
d(p)+d(n)=∥w∥2
결과적으로 Margin이 최대가 되게 하기 위해서는 ∥w∥를 최소화해야 한다.
최적의 하이퍼플레인
결론적으로, 아래 조건을 만족하는 하이퍼플레인을 찾는 것이 SVM의 학습 과정이다.
조건1: 데이터 양분
모든 학습 데이터 (x(i),y(i))에 대하여
y(i)(w⋅x(i)+b)≥1
조건2: 최대 Margin
∥w∥ 최소화
✏️ Soft-margin SVM?
현실적으로 모든 학습 데이터를 정확하게 양분하는 선형식을 찾기는 어렵다. 따라서 학습 단계에서 margin 안에 일정 수준의 noise/outlier를 포함하도록 허용하는 완화된 기준을 적용한다. 이에 따라 현재 선형식으로 학습 데이터를 분류하였을 때 올바르게 양분되지 못한 경우를 수치화한 Hinge Loss를 정의하고, 이를 최소가 되게 하는 조건을 추가한다.
Multi-Class SVM
OvR (One vs Rest)
K-Class 문제에 대해 K개의 서로 다른 Binary SVM Classifier를 생성한다. k번째 분류기는 k번째 클래스를 양성 케이스로 처리하고, 나머지 k−1개의 클래스는 음성 케이스로 처리한다. 이를 학습하여 하이퍼플레인 wk⋅x+bk=0를 찾는다. 학습 후 x′의 클래스 y′은 Binary Classifier wk⋅x+bk의 값이 가장 큰 값을 가지는 클래스 k로 결정한다.
OvO (One vs One)
클래스의 각 쌍을 구분하는 Binary SVM Classifier를 생성한다. K개의 클래스가 있으면, 2K(K−1)개 분류기를 생성한다. 학습 후 새로운 데이터 x′를 분류할 때는 모든 Binary Classifier에 데이터를 넣고 예측을 수행한 뒤, 가장 많이 예측된 클래스를 x′의 최종 예측 클래스 y′으로 결정한다.
Kernel
기본적으로 SVM은 선형식으로 표현되는 하이퍼플레인에 기반하기 때문에 비선형 문제에 적합하지 않다. 그러나 선형으로 양분할 수 있도록 Feature Space를 변환한 뒤에 SVM을 적용하는 것이 가능하다.
대표 커널 함수
Polynomial Kernel
K(x,z)=(x⋅z+1)p
RBF (Radial Basis Function) Kernel
K(x,z)=exp(−2σ2∥x−z∥2)
Hyperbolic Tangent Kernel
K(x,z)=tanh(αx⋅z+β)
하이퍼파라미터
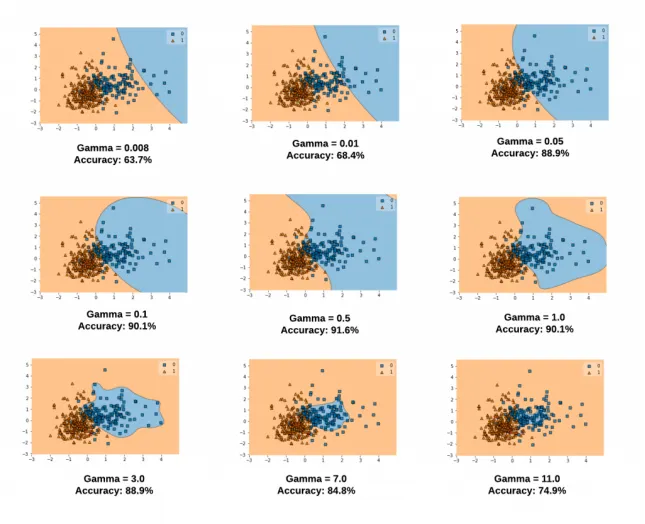
gamma
두 샘플 사이의 거리에 얼마나 민감하게 반응할지 결정한다.
값이 커질수록 거리 변화에 민감하게 반응하고, Overfitting 가능성이 높아진다.
C
Margin과 Hinge Loss 중 어떤 것을 더 중요하게 볼 것인지 결정한다.
값이 크면 Hinge Loss를 더 고려하며, 학습 데이터에 Overfitting될 수 있다. 값이 작으면 Margin을 더 고려하며, Underfitting 가능성이 있다.
