개요
RNN (Recurrent Neural Network)은 임의 길이의 순차 입력을 받아 각 단계에서 동일한 가중치를 적용하고 출력을 생성한다.
Sequence Modeling with RNN
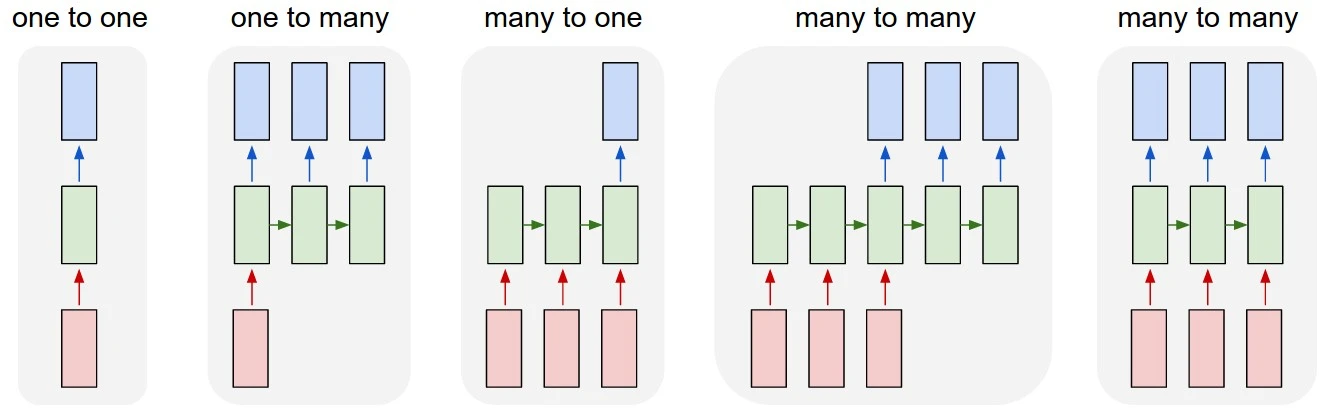
- one to one: Vanilla NN (ex. image classification)
- one to many: Image Captioning (이미지 → 단어 시퀀스)
- many to one: Sentiment Analysis (단어 시퀀스 → 감정 클래스)
- many to many (left): Machine Translation (단어 시퀀스 → 단어 시퀀스)
- many to many (right): PoS Tagging, NER, Video Classification on Frame Level
Vanilla RNN
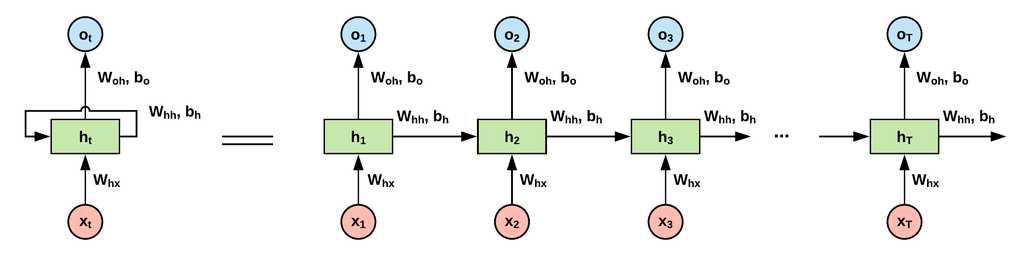
Feed Forward NN은 입력과 출력이 단방향으로만 연결되어, 순차적 맥락을 담아낼 수 없다. 시퀀스를 다루기 위해서는 정보가 시간에 걸쳐 유지될 수 있는 Loop 구조가 필요하다.
동작 원리
Input vector: , Output vector:
는 방금 입력된 뿐만 아니라 과거의 모든 입력에 영향을 받는다.
각 시점 에서, output 는 current input 와 내부 hidden state 로부터 계산된다. hidden state 는 다음 시점 로 전달된다. 매 시점마다 Input을 읽고, hidden state를 갱신하며, output을 생성한다.
정보는 내부적으로 한 시점에서 다음 시점으로 전달된다. 결과적으로 는 네트워크 전체로 전파된다.
의 계산
매 시점마다 내부 hidden state 를 계산한다. 가중치 로 파라미터화된 Activation Function 가 이전 hidden state 과 input vector 에 적용된다. 매 시점마다 동일한 함수와 가중치가 사용되어 가변 길이 입력을 처리할 수 있다.
RNN은 매 시점마다 동일한 가중치를 반복 사용하기 때문에, 한 시점에서 Gradient가 감소하면 매 시점마다 반복해서 감소한다. 따라서 Activation Function으로 Gradient vanishing 문제가 덜한 를 사용한다.
Input과 Output
매 시점마다 두 Input 을 사용하여 hidden state 를 계산한다. 일반적으로 초기 hidden state 는 0으로 설정한다.
output 는 hidden state 에 가중치를 곱해 계산하며, 분류 문제에서는 softmax를 사용하여 를 결정한다.
동일한 세 가지 가중치 행렬 (, , )이 네트워크 전체에서 반복적으로 사용된다.
이점과 한계
이점
- 가변 길이 입력을 처리할 수 있다.
- 입력 텍스트가 길어져도 모델의 크기가 증가하지 않는다.
- 매 시점마다 동일한 가중치가 적용된다.
한게
- Long-Term Dependency Problem
- Gradient Vanishing/Exploding
RNN의 종류
Simple RNN
하나의 hidden RNN Layer로 구성된다. 모델의 메모리 부분을 유지하고, Feed Forward Dense Layer가 이어진다.
Stacked RNN
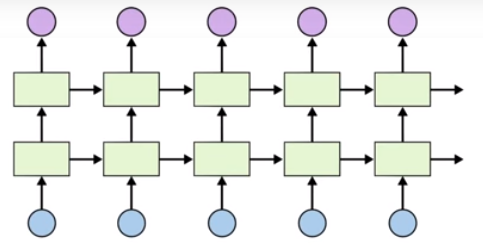
여러 RNN Layer가 차례대로 쌓여 있고, 각 레이어는 고유의 Memory unit을 가진다. 한 RNN Layer의 출력 시퀀스가 다음 RNN Layer의 입력으로 들어간다.
더 깊은 네트워크일수록 문맥이나 시계열 정보를 더 잘 포착할 수 있다.
Bidirectional RNN
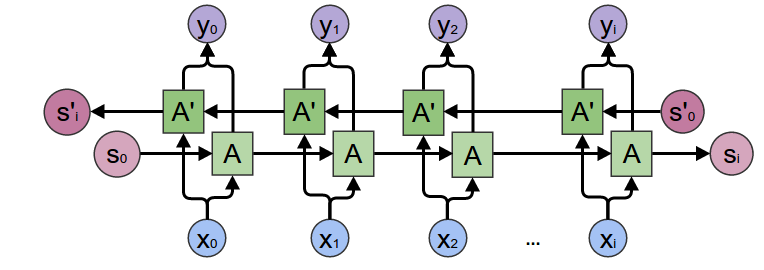
두 RNN을 결합한 구조로, 하나는 시간 순서대로 입력을 처리하고 다른 하나는 시간 역순으로 입력을 처리한다. 이 구조는 네트워크가 시퀀스에 대한 앞뒤 정보를 동시에 활용할 수 있게 한다. 즉, 현재 라벨을 예측할 때 미래와 과거의 정보를 모두 사용할 수 있다. 두 RNN의 출력이 결합되어 최종 출력으로 사용된다.
예시: RNN LM을 사용한 텍스트 생성
학습된 RNN LM을 사용하여 시작 단어로부터 텍스트를 생성한다. 이 단어를 사용하여 출력 확률 분포를 샘플링하여 다음 단어를 예측한다. 샘플링된 output은 다음 단계의 입력이 된다. 원하는 시점까지 각 시점에서 다음 단어를 반복적으로 생성한다.
