NLP
1.[NLP] Tokenization과 Embedding

Tokenization Token은 특정 문서에서 연속된 문자들을 의미 있는 인스턴스다. Tokenization은 언어 입력을 토큰과 같은 작은 단위로 나누는 과정이다. Tokenization Level 단어 수준 일반적으로 공백, 구두점을 기준으로 분리하며, 각 단어
2.[NLP] Language Model
LM은 가장 자연스러운 단어 시퀀스를 찾아내는 모델이다. 퇴근 후 공항에 택시를 타고 갔는데, 답승 시간에 늦어서 결국 비행기를 () 앞에 순차적으로 나열된 단어들을 살펴보았을 대 ()에 들어갈 만한 그럴듯한 (likeliness) 단어는? 앞의 단어들의 hist
3.[NLP] RNN
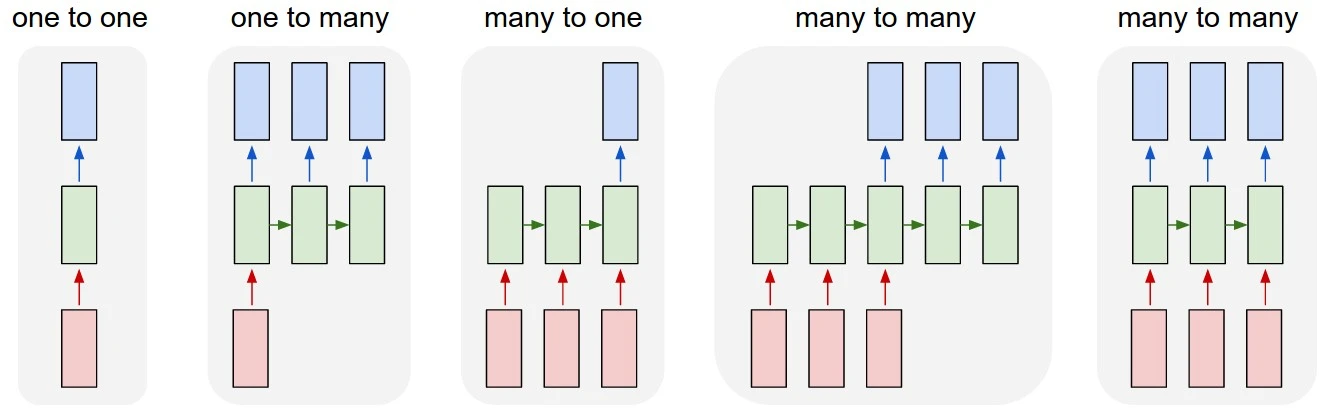
문장의 단어를 순차적으로 처리한다. 글을 읽고 맥락을 파악하는 행위는 한 단어, 한 단어 순차적으로 보고 이해하는 것과 같다. 앞선 단어의 기록을 hidden state를 통해 기억하고 있고, 이를 현재의 예측에 활용한다. long-term dependency를 개선하
4.[NLP] GRU와 LSTM
Sigmoid와 요소 단위 곱을 게이트로 사용하여 얼마나 많은 정보가 통과할지 제어한다.$$f=\\sigma\\left(\\mathbf{w}{hh}h{t-1}+\\mathbf{w}\_{xh}x_t\\right)$$Reset Gate $r_t$와 Update Gate $
5.[NLP] Seq2Seq
Encoder-Decoder Model의 등장 배경 Machine Translation, QA, Speech Recognition, Image Captioning 같은 문제에서는 입력과 출력 길이가 다를 수 있다. 일반 RNN은 이러한 입력과 출력의 길이가 서로 다르거