Encoder-Decoder Model의 등장 배경
Machine Translation, QA, Speech Recognition, Image Captioning 같은 문제에서는 입력과 출력 길이가 다를 수 있다. 일반 RNN은 이러한 입력과 출력의 길이가 서로 다르거나 aligned되지 않은 경우를 처리할 수 없다.
Seq2Seq
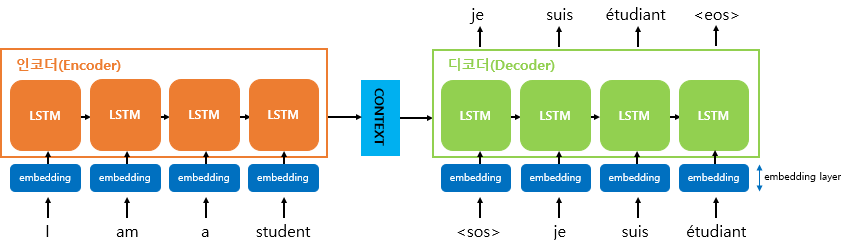
하나의 RNN (Encoder)를 사용하여 입력 시퀀스를 한 단어씩 읽고, 고정된 차원의 벡터 표현인 Context Vector를 얻는다. 그리고 다른 RNN (Decoder)를 사용하여, 그 벡터로부터 출력 시퀀스를 생성한다.
인코더는 각 입력 시퀀스를 대응되는 Context Vector로 변환하고, 디코더는 이 과정을 역으로 수행하여 이전 출력을 현재 입력으로 사용하고, 매 시점마다 벡터를 출력 단어로 변환한다. 즉, 이전 단계 출력에 기반하여 다음 단어를 예측하는 Conditioned LM이다.
✏️ Conditional LM?
일반적인 LM과 유사하지만, 추가적인 맥락 에 조건화된다.예를 들어, 텍스트 요약에서 는 긴 문서, 는 요약본을 의미하고, 기계 번역에서 는 영어 문장을 는 한국어 문장을 의미한다. 이는 디코더가 타겟 시퀀스 의 다음 단어를 예측하기 때문이다. 다음 단어는 지금까지의 타겟 시퀀스의 원본 시퀀스 에 기반해 예측된다.
✏️ 일반적으로
<SOS>(Start of Sequence)와<EOS>(End of Sequence) 토큰을 포함한다.
Machine Translation, Text summarization, Conversational Modeling, QA, Image Captioning에 사용된다.
한계
- 인코더와 디코더 모두 시점이 멀어질수록 초반 정보가 잊혀진다. 즉, Context Vector에 첫 단어보다 마지막 단어의 정보가 많이 담겨 있다.
- 입력 시퀀스가 길어지면 너무 많은 단어가 하나의 Context Vector로 압축되어 정보가 손실된다.
