파이썬 가상환경과 패키지
파이썬에서 표준 라이브러리의 일부로 제공되지 않는 패키지를 사용할 때가 많다. 프로젝트별로 상황에 따라 라이브러리의 특정 버전이 필요 할 때가 있다.
이러한 문제의 해결 방법이 바로 가상환경(Virtual Environment)이다.
패키지는 모듈(기능묶음)을 모아 놓은 것. 패키지의 묶음은 라이브러리
패키지 사용
Requests 라이브러리
requests는 파이썬으로 HTTP 호출하는 프로그램을 작성할 때 가장 많이 사용되는 라이브러리
requests 라이브러리는 매우 직관적인 API를 제공
어떤 방식(method)의 HTTP 요청을 하느냐에 따라서 해당하는 이름의 함수를 사용
- GET 방식: requests.get()
- POST 방식: requests.post()
- PUT 방식: requests.put()
- DELETE 방식: requests.delete()
requests 기본 코드
import requests # requests 라이브러리 설치 필요
r = requests.get('API주소입력')
rjson = r.json()서울시 미세먼지 API 활용
import requests # requests 라이브러리 설치 필요
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
gus = rjson['RealtimeCityAir']['row']
for gu in gus:
gu_name = gu['MSRSTE_NM']
gu_mise = gu['IDEX_MVL']
if(gu_mise > 100) :
print(gu_name, gu_mise)종로구 117.0
성동구 119.0
동대문구 114.0
구로구 119.0
영등포구 107.0
동작구 139.0
금천구 122.0
양천구 109.0
강남구 139.0
서초구 119.0
BeautifulSoup4 라이브러리
BeautifulSoup은 HTML 문서를 분석 할 수 있는 라이브러리
이를 이용하여 HTML 태그에 쉽게 접근 하고 데이터를 추출할 수 있다.
BeautifulSoup4을 이용하여 웹스크래핑(크롤링)
BeautifulSoup4 크롤링 기본 코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://웹주소입력',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')태그 쉽게 가져오는 방법. 개발자 도구 이용하여 원하는 부분 선택한다.
mongoDB(robo3T)
mongoDB는 No-SQL 형태로 딕셔너리{} 형태로 데이터를 저장
파이썬에서 mongoDB 조작하려면 pymongo 패키지를 설치해야 한다.
mongoDB 데이터베이스는 robo3T로 확인.
pymongo 기본 코드
from pymongo import MongoClient
client = MongoClient('localhost', 27017) # mongoDB는 27017 포트로 돌아갑니다.
db = client.데이터베이스 이름pymongo 사용법
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})3주차 끝
지니뮤직의 1~50위 곡을 스크래핑
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
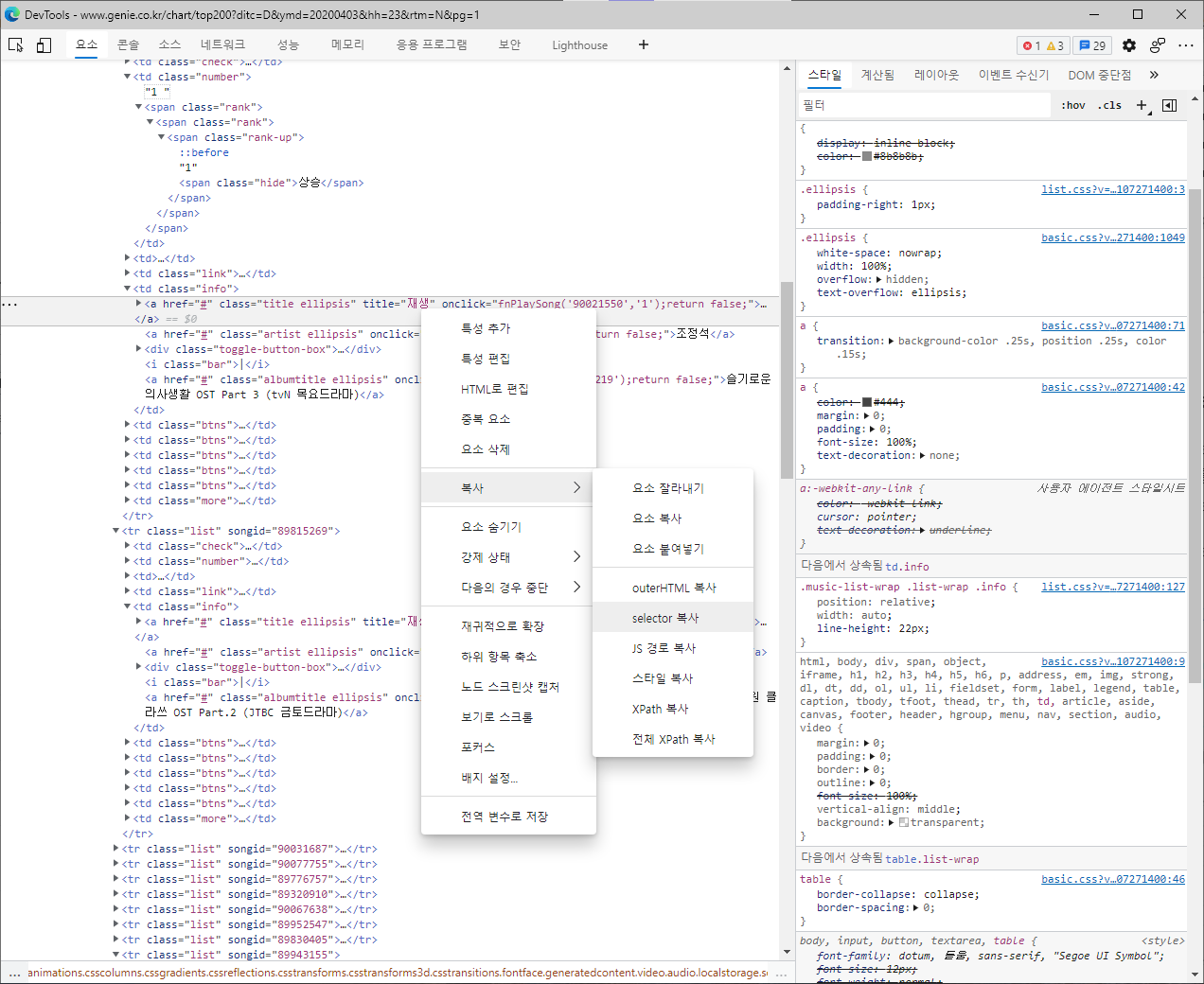
elements = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for element in elements:
number = element.select_one('td.number').text[0:2].strip()
title = element.select_one('td.info > a.title.ellipsis').text.strip()
artist = element.select_one(' td.info > a.artist.ellipsis').text.strip()
print(number, title, artist)1 아로하 조정석
2 시작 가호 (Gaho)
3 처음처럼 엠씨더맥스 (M.C the MAX)
4 이제 나만 믿어요 임영웅
5 아무노래 지코 (ZICO)
...
49 Paris In The Rain Lauv
50 주저하는 연인들을 위해 잔나비
.strip()은 공백 제거
- 지니뮤직의 1~50위 곡을 스크래핑 하면서
number = element.select_one('td.number').text[0:2].strip() 나오기 위한 과정
(정답보고 알음)
number = element.select_one('td.number').text.strip()의 결과값
1
1상승
2
2상승
3
유지숫자 1,2,3만 나오게 하기 위해 enter 키로 나뉘어 있어
number = element.select_one('td.number').text.strip().split('/n')으로 문자열 나누기 출력(파이썬의 enter 키는 '\n' 이다). '/n' 잘못 입력
이 상태에서 [0], .pop(0) 등 삽질을 하였다. 현재 상태는 리스트 전체를 하나로 인식
['1\n \n \n1상승']
['2\n \n \n2상승']
['3\n \n \n유지']number = element.select_one('td.number').text.strip().split('\n')
['1', ' ', ' ', '1상승']
['2', ' ', ' ', '2상승']
['3', ' ', ' ', '유지']number = element.select_one('td.number').text.strip().split('\n')[0]
이렇게 하여도 정상적으로 나온다. (.text[0:2] 방법이 가장 간단)
#이전숫자
9
10
11
#다음숫자