RV32I Architecture - Block Diagram Design
개요
- 이 글은 RV32I single-cycle processor의 기본 모듈과 Block Diagram 설계 과정을 다룬다.
- 먼저 single-cycle 구조에서 필요한 최소한 state 요소를 정리하고, 이후 설계철학을 바탕으로 구현한 Block diagram을 설명한다
1. Single-cycle 구조에서 State 요소
Single-cycle processor 에서는 하나의 Instruction이 한 Clock 주기 안에 완료 되어야 한다.
Data path 대부분의 연산을 combinational circuit으로 구현하고, **state(상태)를 갖는 요소를 최소한으로 제한하는 것이 구조를 단순하게 만든다.
본 설계는 state를 갖는 PC, Register File, Memory를 sequential logic으로 구현했고,
나머지 연산은 combiantial logic으로 구현했다.
다만, 하나의 clock 내에 연산을 끝내기 위해, Register File과 Memory는 Reading를 combiantional logic으로, 무결성을 위해 Writing을 sequential logic으로 구현했다.
이러한 선택은 제어를 단순하게 만들고 설계 흐름을 명확하게 하지만,
clock 주기가 전체 연산 경로에 의해 제한된다는 trade-off를 가진다.
이는 single-cycle 구조가 가지는 근본적인 한계이기도 하다.
2. CPU 기본 모듈
Instruction cycle
Fetch -> Decode -> Excute -> Memory -> Write_back
크게 6가지 Module으로 위 cycle을 구현한다.
2-1. Program Counter (PC)
-
명령어 갱신 역할. Instruction Memory의 input으로 들어가 명령어를 찾는다.
-
각 명령어를 구분하는 기준이 되는 module이다.
-
따라서
clk에 따라 값을 갱신하고,sequential circuit로 구현한다.
2-2. Instruction Memory
- 명령어들을 저장하는 Memory. 여기 다 쓸 필요는 없으므로, ROM으로 구현한다. 따라서
combinational circuit로 구현한다.
2-3. Register File
- Register들을 저장하는 메모리 장소이다. 총 32개의 레지스터가 존재하며 각 레지스터는 32 bit의 크기를 갖는다.
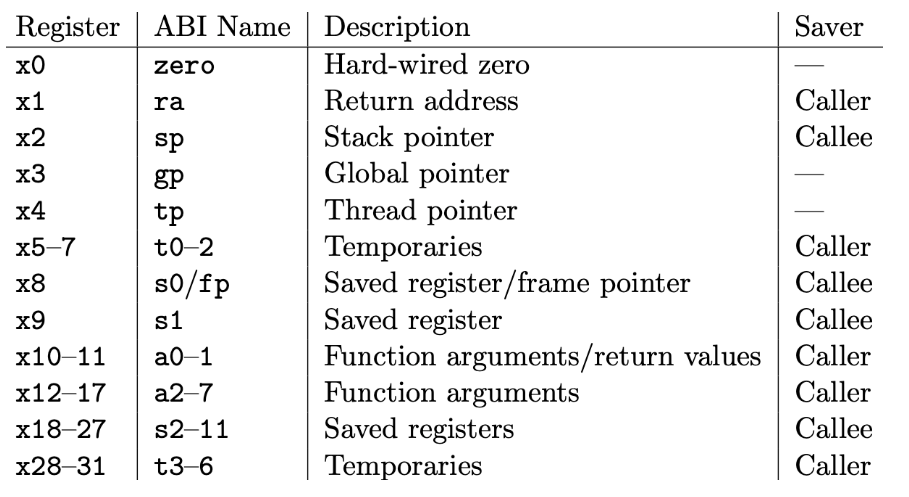 Figure 2. R-type RV32I Register type
Figure 2. R-type RV32I Register type
-
두 개의 source register (
rs1,rs2)를 동시에 읽고, 하나의 destination register (rd) 에 값을 저장하도록 만들었다. -
레지스터에 Writing은
postive clock edge에만 발생하도록해 무결성을 보장했다. -
Reading은 즉각적인 값 전달을 위해
combinational circuit으로 구현한다.
2-4. ALU
- 계산만 하면 되는 module이다. R-type에 존재하는 계산 방식을 모두 가지는
combinational circuit로 구현하면 될 듯하다.
2-5. Data Memory
- 무결성을 위해
clk에 따라 값의 입력과 출력이 결정되게 구현한다. 즉sequence circuit. - DRAM의 역할을 할 예정이며, memory address가 총 32 bit이니 이에 맞춰 용량을 구현할 예정이다.
2-6. Control Unit
- Instruction type과 그들의 종류에 따라 module의 작동을 세부적으로 control 할 module이다. 비트단위 signal을 보내 각 module을 통제한다.
combinational circuit으로 구현한다.
3. 설계 철학
Computer Organization Design 에서 설계 철학을 강조한다. 따라서 나만의 설계철학을 바탕으로 구현했다.
1. ISA 중심 설계
-
RISC-V ISA의 각 명령어 타입 (R, I, S, B, J ,U)를 하나씩 이해하며 필요한 데이터 경로와 모듈을 점진적으로 추가하는 (Bottom up) 방식을 채택
(ISA 내용 : https://velog.io/@liquetxnx22/1.-%EC%9D%B4%EB%A1%A0-RV32I-ISA-%EC%A0%95%EB%A6%AC) -
R-type 명령어는 memory access와 branch를 포함하지 않기 때문에, 가장 단순한 data path를 가진다. 이 data path를 바탕으로 Instruction type의 경로를 확장해 나간다.
-
이유 : 직접 설계해보며 하드웨어 설계 감각 증진
2. Simplicity favors regularity
-
예외적인 전용 경로 추가보다, 기존 경로 재사용을 늘리고, 규칙적인 구조 유지를 우선함
-
예시 :
-
AUIPC 명령어는 Branch adder가 아닌 ALU에서 PC + IMM으로 처리
-
PC 선택을 PC MUX로 통합 등
-
-
이유 : 구조가 규칙적이면 제어가 단순해지고 확장이 쉬워진다.
3. 명확한 역할 분리
-
각 module은 역할을 명확히 분리한다.
-
예시 :
- Control unit은 Opcode 기반의 정적 제어만 생성.
(각 Instruction type에 따른 signal만 생성)
- Control unit은 Opcode 기반의 정적 제어만 생성.
-
이유 : 각 모듈을 명확히 나누어 유지 보수성을 높이고 가독성을 높인다.
3-1 추상화된 모듈
가장 추상화된 top module을 설계한다. 크게 Data가 흐르는 Data Path와 그 Data의 흐름을 제어하는 Control Path로 나눈다.
Data path는 명령어가 각 값들을 계산하는 과정을 모두 나타낸다.
Control path는 Control Unit으로 구현하며, 명령어의 Opcode, funct7, funct3의 정보를 받고 명령어의 계산 과정을 제어할 신호를 보낸다.
이후 각 Instruction type에 따라 data path를 설계하고 그에 맞는 필요한 control signal을 만든다.
4. Block Diagram Design
완성본
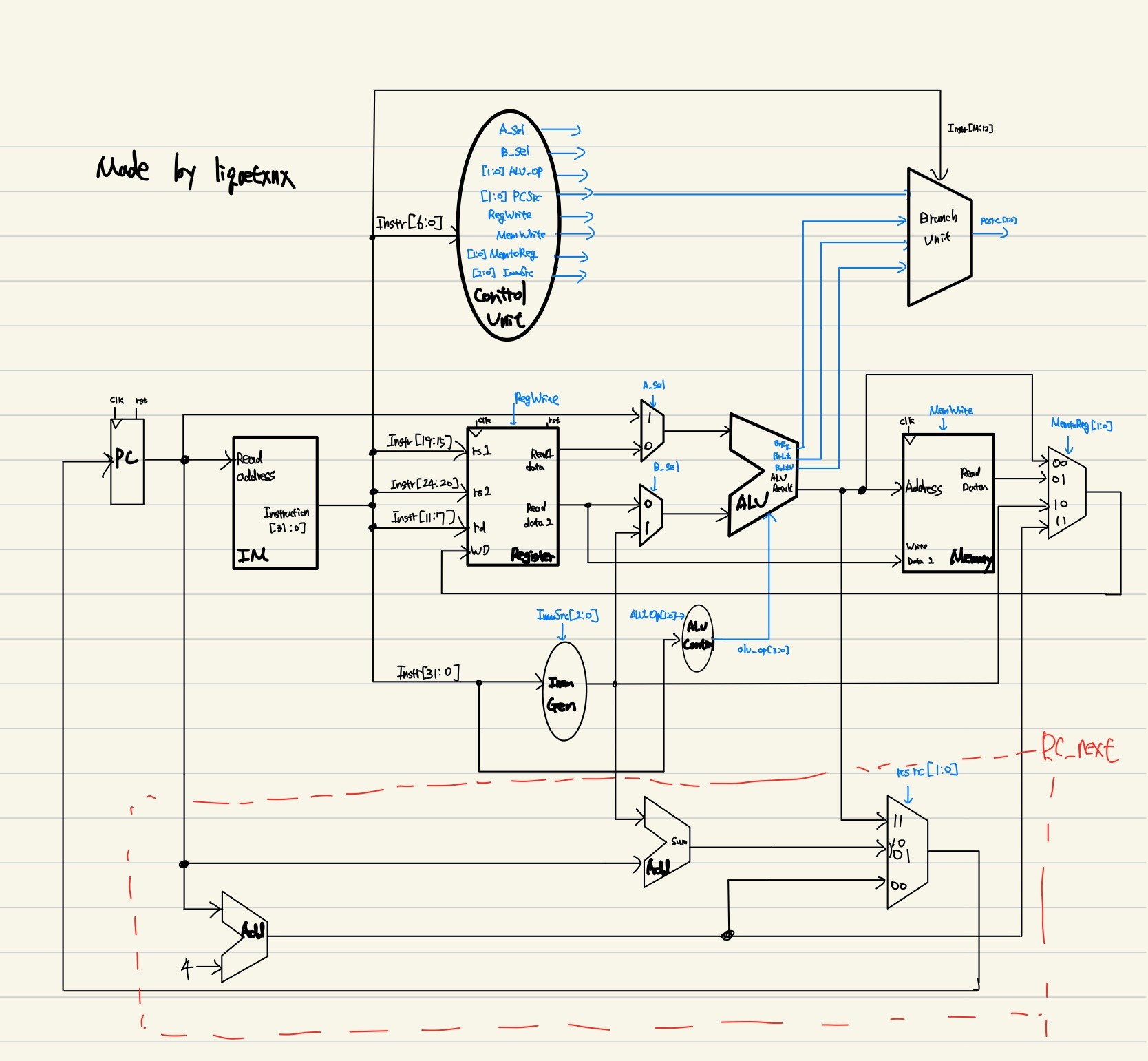 Figure 3. Single cycle processor RV32I Block Diagaram
Figure 3. Single cycle processor RV32I Block Diagaram
-
Control signal 들은 가독성을 위해 파란색으로 표시했다.
-
더불어 Diagram의 복잡도를 낮추기 위해, signal의 선은 input과 output만 표시했다.
-
Instruction Memory와 Data Memory를 분리한 Haravard 구조를 택했다.
-
설계 철학에 따라 각 module을 명확히 추상화 했다. Module 중 몇개만 간략히 보겠다.
-
Control Unit : Opcode에 따른 Instr type 별 signal을 결정. 총 8개의 signal로 연산 통제.
-
Branch Unit : B-type 연산을 위한 MUX로 후에 자세히 설명
-
PC : 주소값 갱신만을 담당하며 주소값 계산은 PC_next에서 진행
-
Data Path
크게 다음과 같이 나눌 수 있다.
1. PC
2. PC_Next
3. IM
4. Reg_file
5. ALU
6. ImmGen
7. ALU_Control
8. Memory
9. Branch_Unit
10. Mux
PC and PC_Next
-
PC는 레지스터의 역할만을 부여 받아 명령어 주소 값 갱신만 담당한다.
-
이외에 PC 값 갱신은 PC_Next에서 이루어진다.
분리 이유
-> PC모듈의 역할 (PC 값 갱신)의 역할을 명확히 하고 모듈의 복잡도를 낮추기 위해.
-> 또한 이후 pipe line 구현시 효율성을 높이기 위해.
PC_Next 는 만들 생각이 없었지만, 효율적이고 간단한 코드 작성을 위해 필요성을 깨닫고 만들었다.
IM (Instruction Memory)
-
PC에서 받은 주소 값으로 저장되어 있는 명령어 비트를 출력한다.
-
RISC-V default인 Little-endian으로 구현한다.
-
편리성을 위해 명령어 집합은 외부 파일에서 로드한다.
Reg_File
- x0은 하드웨어에서 clk 발생시 0으로 항상 업데이트해 고정한다.
- x2는 스택 pointer로 이후 c-code 를 돌리기 위해 일정한 값으로 갱신해준다.
ALU and Branch Unit
-
Branch를 위한 계산은 Arthimetric calculation이 필요하다. 이는 ALU의 역할임으로 Branch를 나타내는 Flag을 ALU에서 계산해 Branch unit으로 보낸 후 결정한다,
-
Branch 계산 방법은 다음 링크에서 확인할 수 있다.
https://velog.io/@liquetxnx22/RV32I-%EB%B9%84%EA%B5%90%EA%B8%B0
ImmGen
-
각 명령어 type에 맞게 Immediate 값을 계산한다.
-
한편 입력값으로 모든 명령어 크기인 Instr[31:0] 을 받는다. 계산에는 opcode 부분인 [6:0] 이 필요 없지만, 이 정도 비트수가 늘어나서 효율이 떨어진다고 볼 순 없다.
-
또한 Branch를 결정하는 명령어 type을 Imm에서 구분하여 구현하는 방법이 있어서 후에 pipe line 구현시 사용할까 싶어 일단 남겨놨다.
ALU_Control
- 설계철학에 따라 ALU의 연산 종류를 결정하는 ALU_Control 모듈을 분리했다. 이로써 Control unit은 opcode만을 받아, 명령어 type을 결정하는 명확한 역할을 가지게 된다.
Memory
- 1- word addressing로 구현함으로 endian을 신경쓰지 않는다.
- 1-word addressing임으로 memory address를 받으면 2 bit shift하여 사용한다. (mem_addr >>2)
Control Unit
총 8개의 Signal 사용
1. A_Sel,
2. B_Sel,
3. [1:0] ALU_Op,
4. [1:0] PCSrc,
5. RegWrite,
6. MemWrite,
7. [1:0] MemtoReg,
8. [2:0] ImmSrc
1, 2. A_Sel and B_Sel
-
A_Sel은 U-type 연산을 위해 PC 값과 Register value 중 ALU input을 결정하는 signal.
-
B_Sel은 IMM 값과 Regster value 중 ALU 연산에 필요한 값을 결정하는 signal.
3. [1:0] ALU_Op
-
설계철학에 따라 ALU의 연산 종류를 결정하는 ALU_Control 모듈을 분리했다. 이로써 Control unit은 opcode만을 받아, 명령어 type을 결정하는 명확한 역할을 가지게 된다.
-
ALU_Control module을 제어하는
signal이다. -
총 2비트이며, 비트마다 다음과 같다
00: ADD 고정 : 주소값 계산 (lw, sw 등에 사용)01: SUB 고정 : Branch 계산 목적10: R-type11: I-type
4. [1:0] PcSrc
-
PC 값 갱신을 결정할
Signal이다. -
총 2비트이며, 비트마다 다음과 같다
00: PC+4로 갱신 (일반적인 상황)01: branch 주소로 갱신 (B-type 전용)10: jump 주소로 갱신 (J-type 전용)11: jump 주소로 갱신 (I-type jump, JALR 전용)
5. RegWrite
-
Register File에 값을 입력하도록 결정하는
Signal. -
이
Signal이 켜졌을 경우,WD를 rd가 나타내는 reg 주소에 저장한다.
6. MemWrite
-
Register File에 값을 입력하도록 결정하는
Signal. -
이
Signal이 켜졌을 경우,rs2_output을 memory 주소에 저장한다.
7. [1:0] MemtoReg
-
WD값 갱신을 위한 MUX의select Signal이다. -
총 2비트이며, 비트마다 다음과 같다
00: ALU output (R, I-type etc.)01: Data Memory value (lw)10: ImmGen value (U-type)11: PC + 4 (JALR)
8. [2:0] ImmSrc
-
Immsign extention을 위한Signal -
총 3비트이며, 비트마다 다음과 같다
000: I-type001: S-type010: B-type011: J-type100: U-type- Others : Not used
