이진형태>> yes,no 이런 데이터들이 엄청나게 많다고 생각하자.
그런 점들이 한 그래프에서 무수히 많다.
이것들 중 한 선으로 두 개의 파트로 나눈다고 생각해보자
대부분 0,1 로 잘 갈릴 것이다.
하지만 예외로 안갈리는 것들이 있을 수도있다.
그런것들은 선이 아닌 곡선으로 하면 오류가 하나도 없을 수 있지만 그것은 너무 Train_set에 맞춰져있기 때문에 실제 Test_set에서는 효과가 없을 수 있다.
이번 섹션에서는 선형으로된 것만 생각해보자
1. 라이브러리 가져오기
2. 데이터 전처리
3. Train, Test set 나누기
4. 피쳐 스케일링
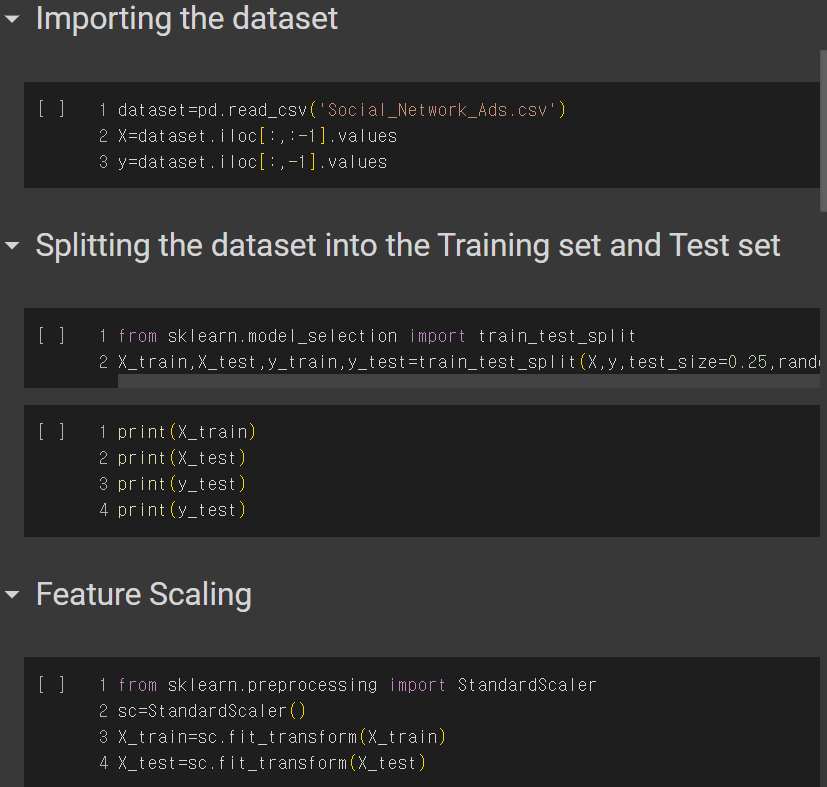
이전과 전부 동일한 방식이다.
5. 로지스틱 회귀 모델 생성 및 훈련
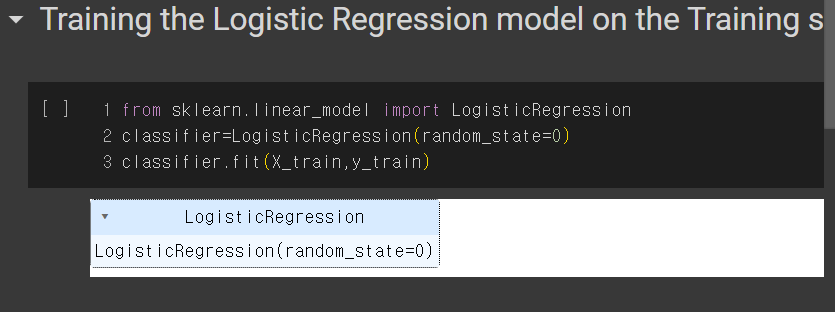
from sklearn.linear_model import LogisticRegression
선형 모델이다. 그리고 LogisticRegression 라이브러리를 가져온다,
classifier=LogisticRegression(random_state=0)
로지스틱 모델 생성
classifier.fit(X_train,y_train)
Train 셋으로 훈련
6. 미래 예측
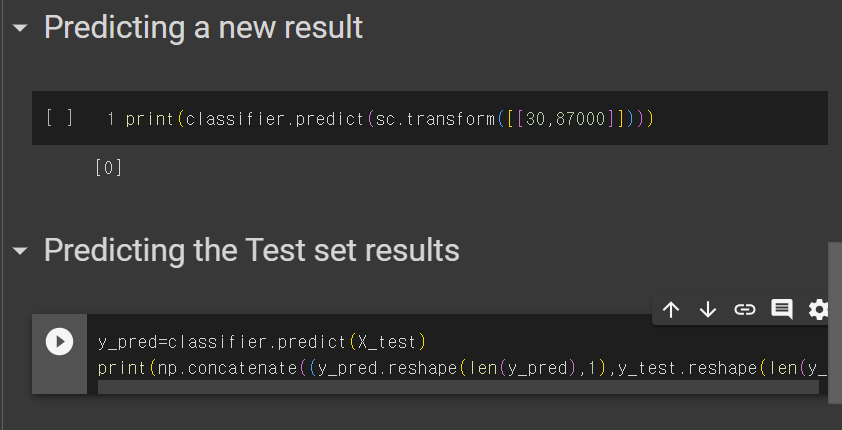
y_pred=classifier.predict(X_test)
가공된 X_test 셋으로 y값을 예측한다.
