1. KNN
가장 간단한 분류 알고리즘.
비슷한 특성을 가진 데이터는 비슷한 범주에 속한다고 가정하고 시작한다.
모양이 달라도 색상이 같으면 같다고 가정
1.1 KNN Model Training
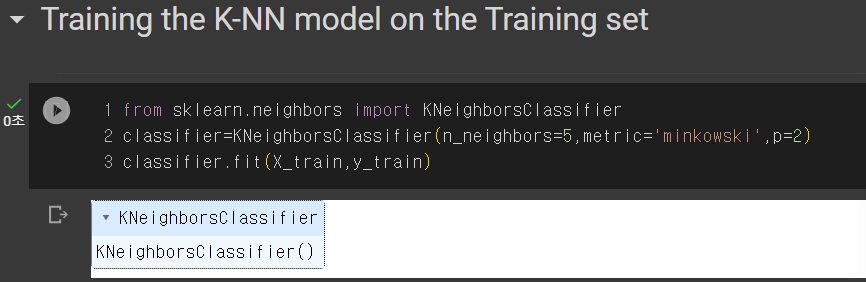
from sklearn.neighbors import KNeighborsClassifier
라이브러리 가져와야 한다.
classifier=KNeighborsClassifier(n_neighbors=5,metric='minkowski',p=2)
이웃의 수는 5개, 유클리드 계산법 p=2 모두 디폴트값이다.
1.2 시각화
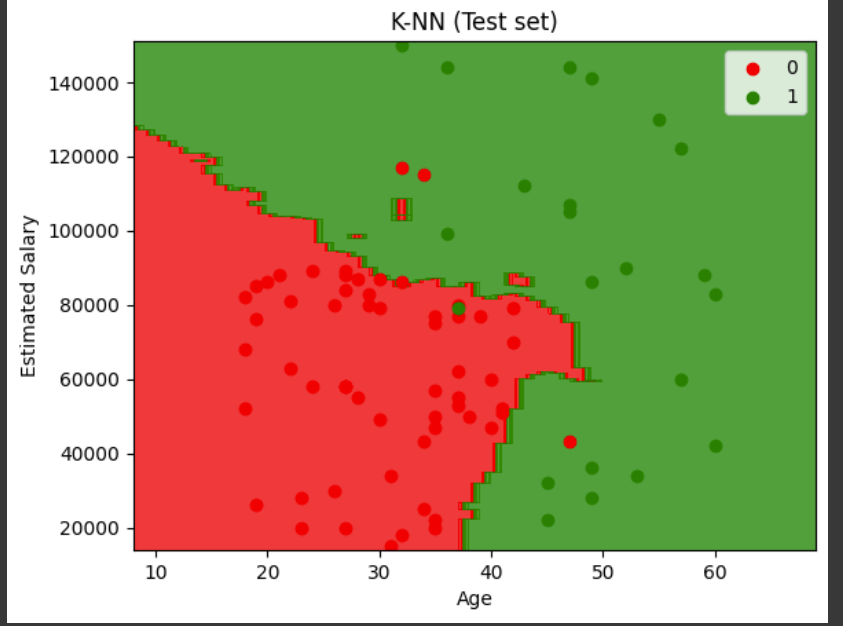
로지스틱 회귀와는 다르게 선형이 아님을 기억하자.
2. 서포트 벡터 머신 (SVM)
두 개의 데이터를 분리하는 방법으로, 데이터들과 거리가 가장 먼 초평면을 선택하여 분리하는 방법
데이터를 분리하기 위한 직선이 필요한데, 데이터의 변동이나 노이즈를 해결하기 위해 margin을 사용한다.
이런 마진을 최대로 만드는 직선을 계산하여 데이터를 분류하는 방법
주어진 샘플을 완벽하게 분류할 수 없는 경우, 오분류 에러를 허용한다
크게 설정하면 에러는 작아지지만, 마진도 작아진다
2.1 SVM model Training
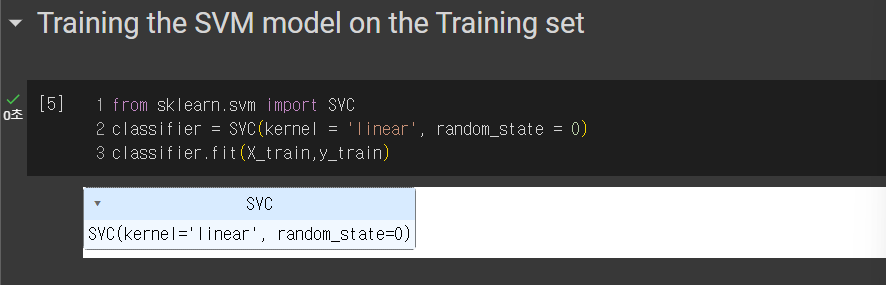
kernel은 우리가 정해줘야하는데, RBF, Linear 등등 다양하지만
여기서는 Linear을 선택한다.
그리고 예측결과가 0.91 정도 나왔고 Knn보다 낮은 것을 알 수 있다.
2.2 시각화
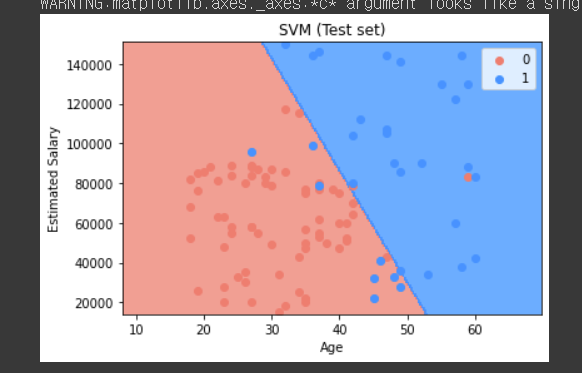
선형이라서 더 낮은 것임!
비선형이었으면 어떻게될지 궁금하다.
3. 커널 서포트 벡터 머신 (SVM)
커널은 rbf 방사형으로 교체만 해주면 끝!
예측 결과 0.93으로 더 높아진다.
