K-평균 클러스터링이란?
머신러닝 비지도 학습에 속하고, 데이터를 K개의 군집으로 묶는 알고리즘이다.
이 알고리즘은 가깝게 위치하는 데이터를 비슷한 특성을 지닌 데이터로 여기고 같은 군집으로 군집화한다.
KNN과 다른 점은 KNN은 지도학습이다!
이해하기에 좋은 사진인 것 같다.
분류
분류 classification은 지도학습 방법에 속하여 정답이 주어졌을 때, 정답을 기반으로 데이터를 나누는 방법이다.
머신러닝에서 모델을 학습시킬 때, 정답을 제거하고 모델이 예측한 정답과 실제 정답을 비교하여 모델의 성능을 판단.
군집화
비지도학습 방법이고, 정답이 주어지지 않았을 때, 주어진 데이터를 묶는 방법을 의미한다.
정해진 정답이 없어서 정답을 예측한다기보다는 이렇게 군집화가 될 수 있구나 정도만 파악이 가능하다.
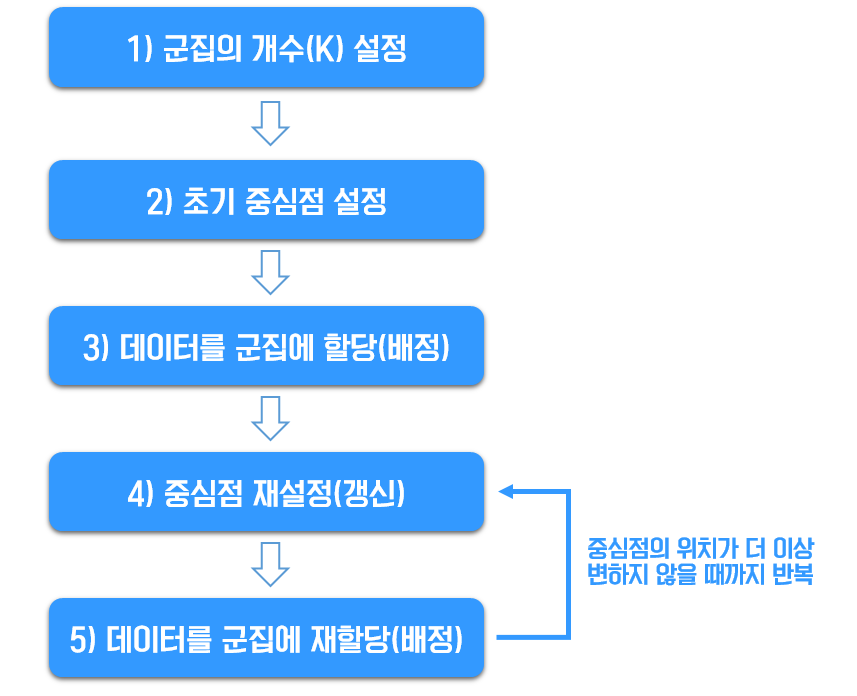
- 군집의 개수 (K) 정하기
- 초기 중싱점 설정하기
- 데이터를 군집에 배정하기
- 중심점 재설정하기
- 데이터를 군집에 재배정하기
중심점의 이동이 없을 때까지, 4와 5를 반복!
1. 라이브러리 가져오기
2. 데이터 전처리
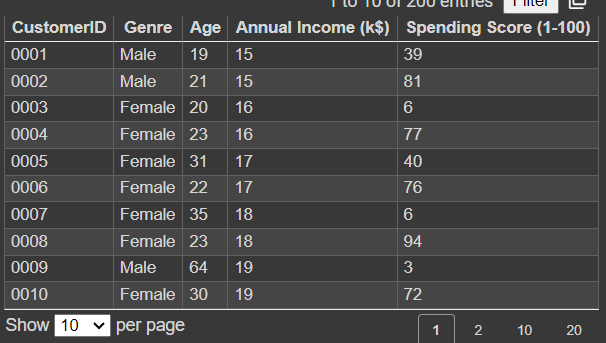
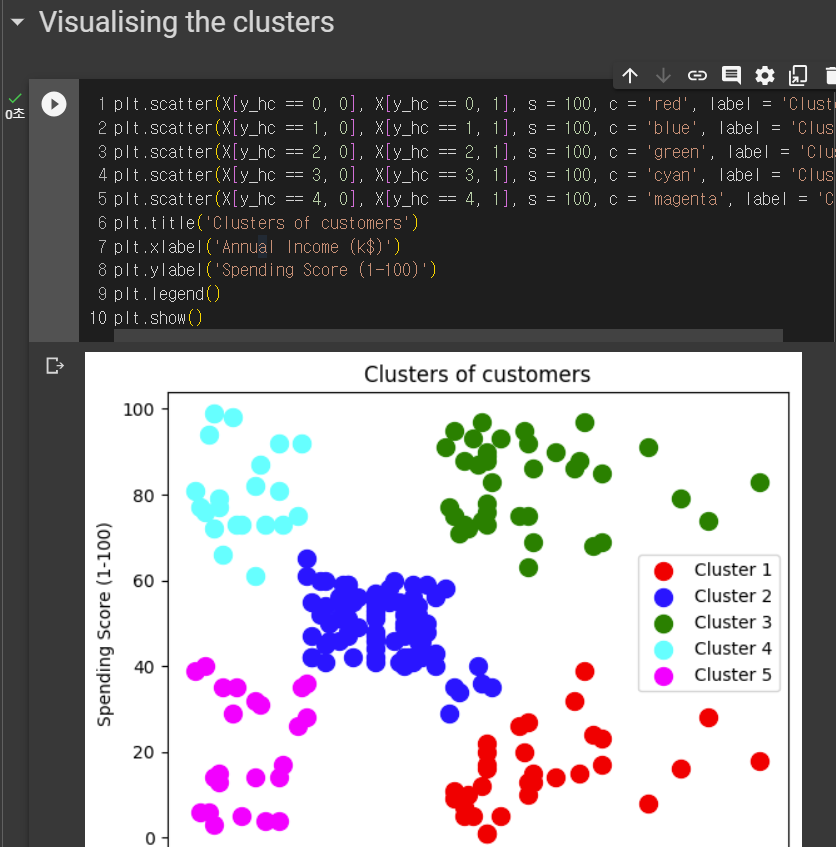
데이터를 보면 우리가 알고 싶은 것은 소득과 소비의 관계라서 3열과 4열을 가져와야한다.

여기에서 X만 필요하기때문에 X에 대해서 3열과 4열을 뽑아준다.
3. 엘보우방법으로 최적의 K찾기

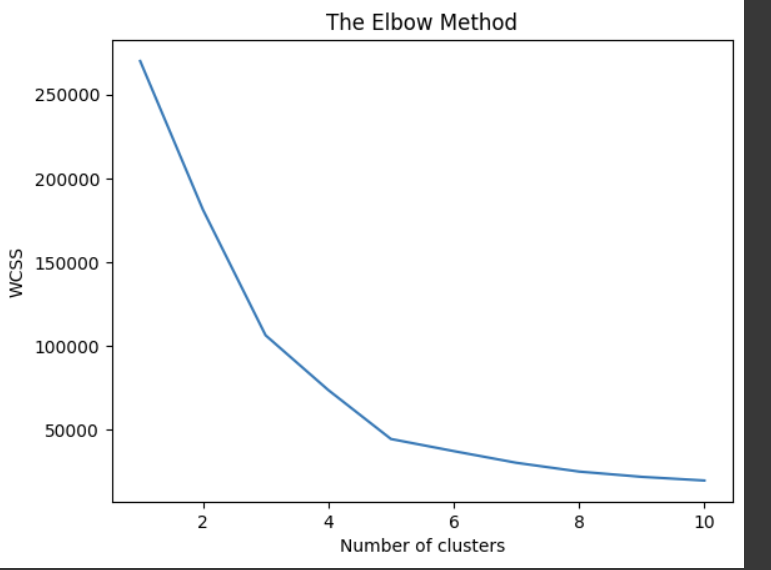
여기서 보면 5부터 완만해지는 것을 알 수 있다.
K는 5로 정하고 이제 코드를 살펴보자.
from sklearn.cluster import KMeans
KMeans 라이브러리 가져오기
wcss=[]
이것은 점과의 제곱인데, 이것이 작아야 좋음
10번의 배열을 돌릴 떄, 값을 저장하기 위해 생성!
for i in range(1,11):
kmeans=KMeans(nclusters=i,init='k-means++', random_state=42)
kmeans.fit(X)
wcss.append(kmeans.inertia)
init는 무작위 초기화함정을 피하기 위해 kmeans++를 사용한다.
그리고 클러스터 내 제곱합을 wcss에 추가한다.
4. 모델 훈련

kmeans = KMeans(n_clusters = 5, init = 'k-means++', random_state = 42)
kmeans를 이제 5로 고정!
이제 y_kmeans로 훈련을 시킨다.
5. 시각화
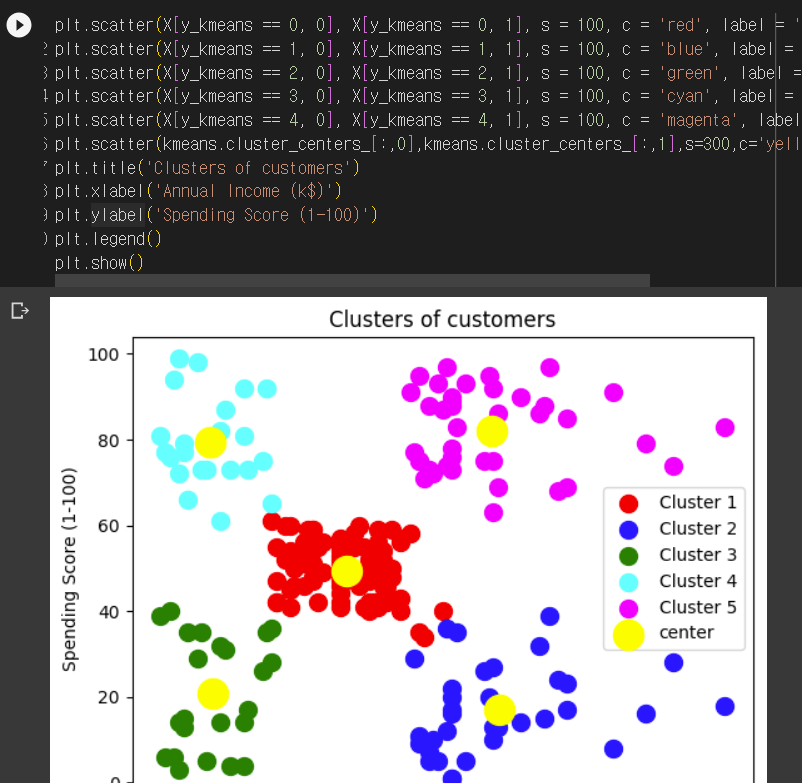
plt.scatter(kmeans.clustercenters[:,0],kmeans.clustercenters[:,1],s=300,c='yellow',label='center')
각 군집의 가운데에 점이 생기게 해줌!
계층적 클러스터링
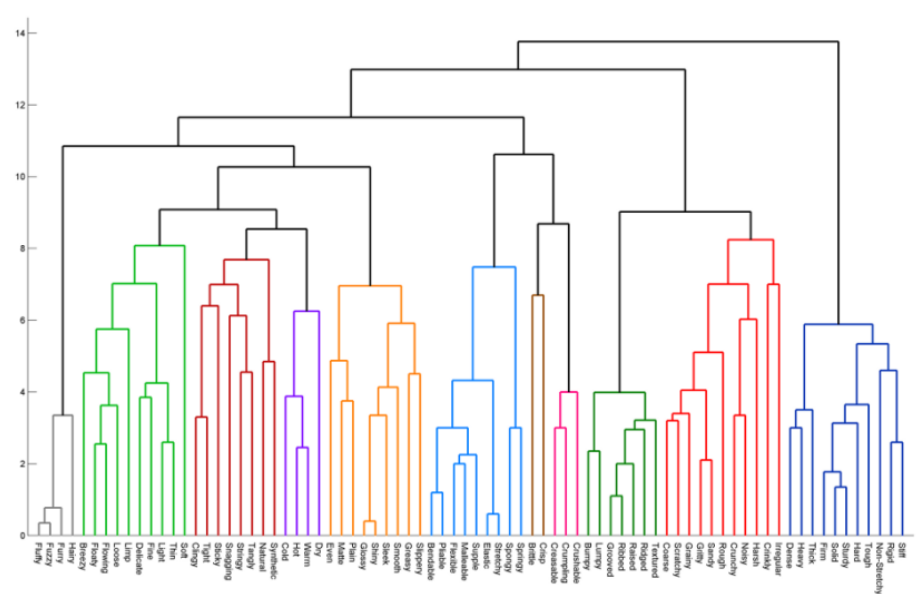
개별 개체들을 순차적, 계층적으로 유사한 개체를 그룹과 통합하여 군집화를 수행한다.
K평균군집화와 달리, 사전에 군집수를 정하지 않아도 된다.
위 사진은 덴드로그램이다. 트리형태!
HC를 수행하려면 모든 개체들 간 거리가 이미 계산되어 있어야한다.
1. 라이브러리 가져오기
2. 데이터 전처리
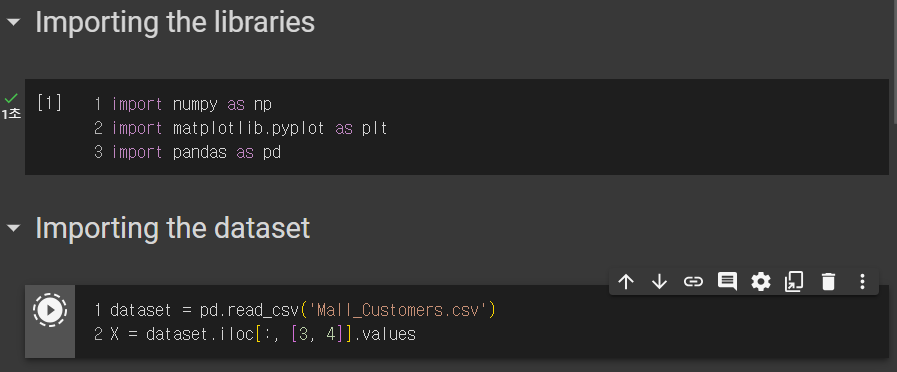
이전과 동일하다.
3. 최적의 개수 찾기
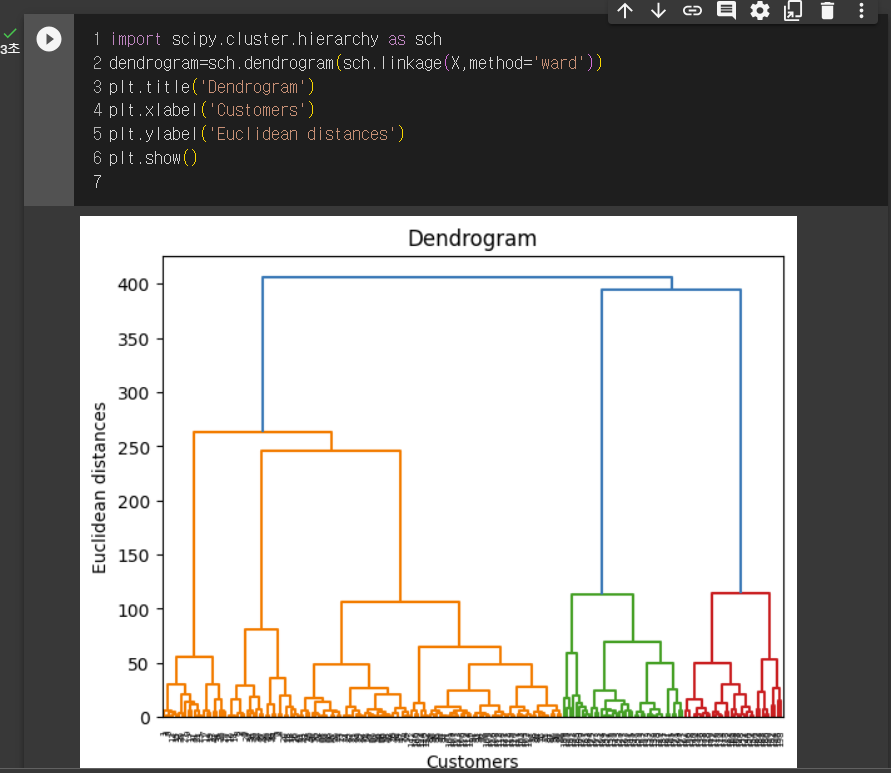
dendrogram=sch.dendrogram(sch.linkage(X,method='ward'))
ward는 클러스터내 편차를 줄여주는 방법이다.
import scipy.cluster.hierarchy as sch
라이브러리 가져오기
4. 모델 훈련
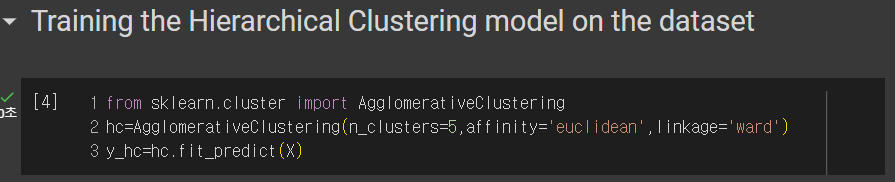
5. 시각화