예를 들어, 아기용 기저귀와 맥주의 판매량이 늘어난 데이터가 있다고 하자.
이것들은 서로 특별한 연관관계가 없어보인다.
사실, 퇴근한 남편이 기저귀를 사면서 맥주를 산 것이다.
우리가 사장이라면 기저귀랑 맥주를 정반대에 둬야 편의점 전체를 둘러볼 것이다.
이러한 알고리즘을 어프라이어리 알고리즘이라고 한다.
예를 들어, 스타워즈 영화를 본 사람은, 비슷한 계열의 가오갤을 볼 확률이 높다.
이런 분석을 하기 위해 세 단계를 거치게된다.
-
support
100명 중 10명이 가오갤을 봤다면, support는 0.1이 된다. -
confidence
스타워즈를 본 사람이 100명 중 40명, 40명중 가오갤을 본 사람은 7명
confidence=7/40가 된다. -
lift
100명 중 가오갤을 보라고 하면, 10명이 되지만 40명 중 보라고 하면 7명이된다.
즉, lift = 17.5% / 10% = 1.75가 된다.
빈도>척도>연관을 통해 데이터에 관한 발생빈도를 기반으로 각 데이터간의 연관 관계를 밝히기 위한 수학적 접근 알고리즘이다.
1. 라이브러리 가져오기
어프라이어리 라이브러리를 가져오기 위해선 설치가 필수이다.
!pip install apyori
2. 데이터 전처리

데이터 셋은 순서대로 무엇을 샀는지 나열되어있다.
그러므로 첫 부분은 열, 제목 이런것이 아니다.
dataset=pd.read_csv('Market_Basket_Optimisation.csv',header=None)
그래서 header=None 없다고 표시해줘야한다.
그리고 리스트안에, 리스트로 만들기 위해서 먼저 리스트를 만들어주고,
각 행의 수 만큼 리스트에 추가시켜주기로한다.
str은 문자열이기때문에 str을 붙여주도록하자.
3. 모델 훈련

rules=apriori(transactions=transactions, min_support=0.003,min_confidence=0.2,min_lift=3,min_length=2,max_length=2)
훈련을 하기 전, 어떤 정도로 훈련을 시킬지 규칙을 정해야한다.
transactions=transactions
이것은 어떤 업무일지 받는 인자인데, 우리는 전에 만든 2중 리스트를 사용한다.
min_support=0.003
이것은 지지도인데, 두개의 상품을 포함하는 거래 내역의 수 / 전체 수 이다.
한 마디로, 상품 2개에 대해 일주일의 거래내역에 이 상품이 최소 몇 번이나 나타났는지를 구해야한다.
하루에 3번, 일주일이므로 3*7/7501=0.003이 된다.
min_lift=3
최소 향상도는 3을 선택하자.
min,max_length
1+1을 위해 최소2, 최대2를 선택하고 2+1일 경우에는 각각 3이된다.
4. 시각화
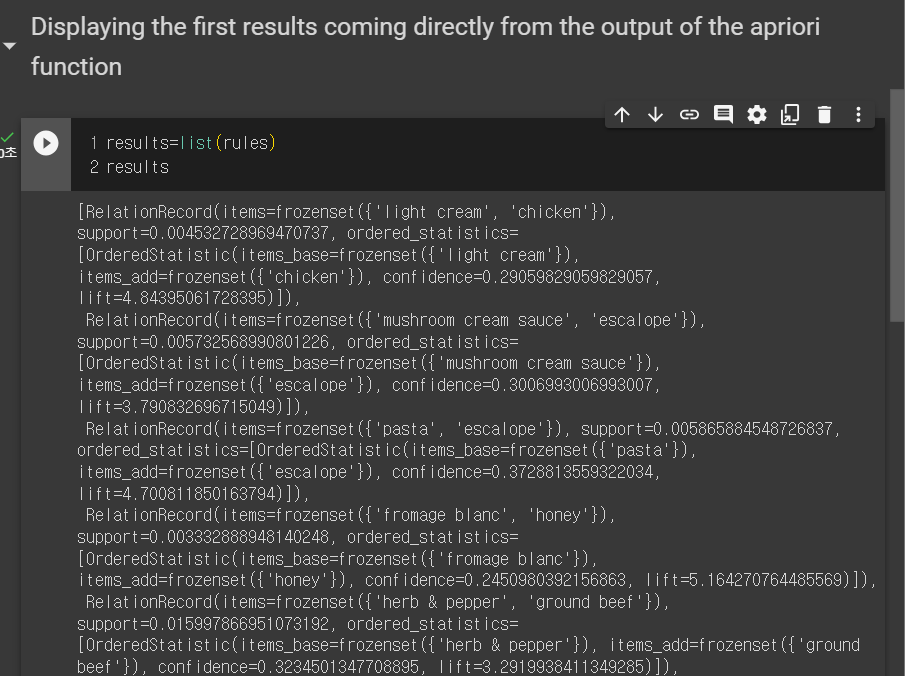
여기서 보면, 좌변과 우변이 되게 중요한데, 만약 라이트크림을 사면, 치킨을 살확률이 높고, 그에 대한 신뢰도도 있다.
우리가 정한 규칙에 맞게 나열되어있다.
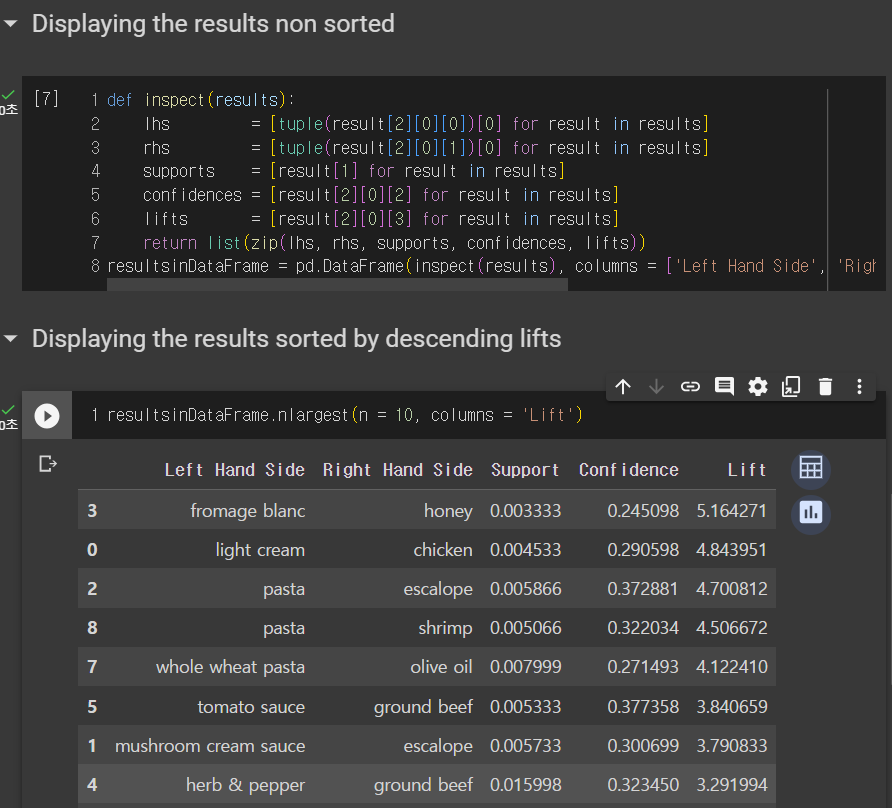
이클렛은 어프라이오리 모델의 단순한 버전으로, 이걸 산 사람은 x를 산다라는 추천 시스템 같은거다.
모든 조합을 검토하고 어떤 것에 집중해야 하는지 알려준다.
또한, 지지도 support만 있다.
1+1 행사에서 어떤 가장 연관성이 높은 상품들이여야 잘 팔릴까?
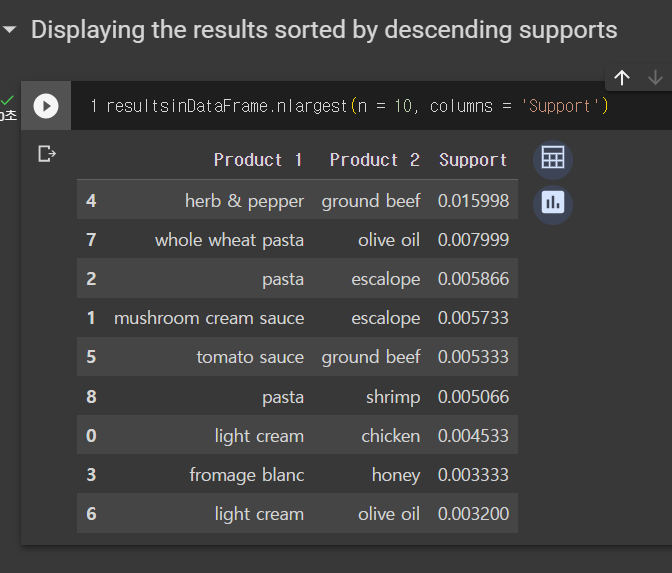
지지도가 중요

이렇게 유용한 정보를 공유해주셔서 감사합니다.