NLP에서 bag of words 모델을 사용한다.
우리 데이터는 레스토랑의 좋고 나쁨을 1,0으로 나타내는 데이터이다.
그렇게 훈련시키기 위해선 문장에서 필요없는 부분은 지우고 어간도 없애야한다.
and a the 아런 것들은 지운다.
좋았다 좋다로 고쳐주고 not은 없애면 안된다.
이렇게 수정된 문장들은 나이브베이즈 분류기로 훈련시키면 된다.
1. 라이브러리 가져오기
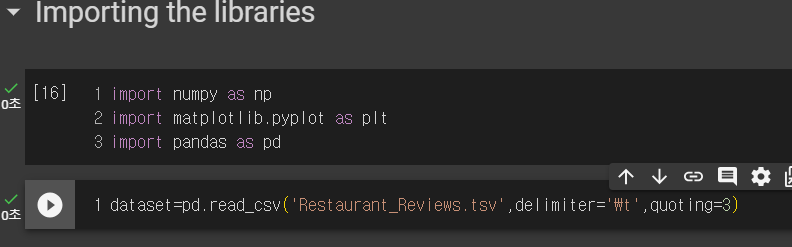
dataset=pd.read_csv('Restaurant_Reviews.tsv',delimiter='\t',quoting=3)
csv 파일이 아닌 tsv 파일이다.
delimiter는 tsv파일을 쓴다고 명시했다.
quoting=3은 띄움표""를 무시하는 역할이다.
2. 문장 Cleaning
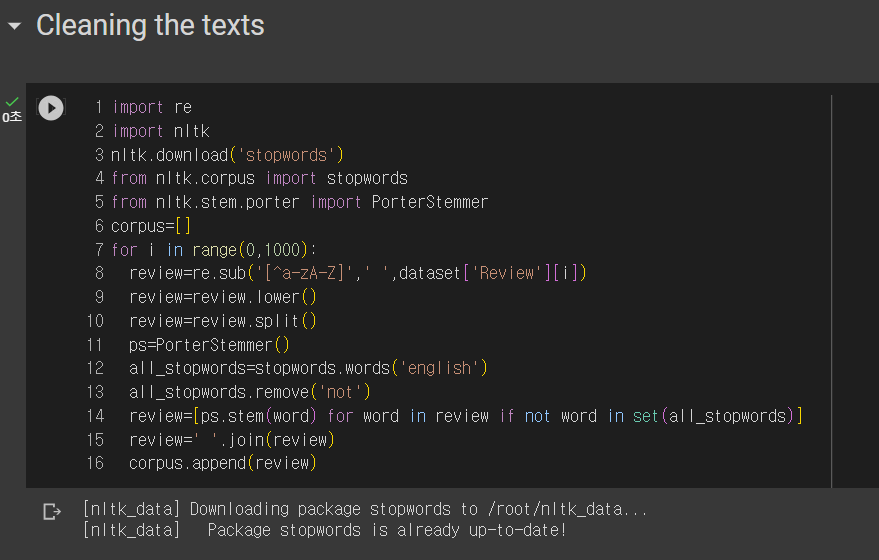
import nltk
nltk.download('stopwords')
제외어를 다운로드하여 나중에 필요없는 단어를 제외할때 사용된다.
from nltk.stem.porter import PorterStemmer
어간을 추출할 때 사용되는 라이브러리이다.
review=re.sub('[^a-zA-Z]',' ',dataset['Review'][i])
^ not 문자가 아니라면?
공백으로 사용한다
dataset의 Review열의 i번째에서
review=review.lower()
review=review.split()
후기들을 소문자로 바꿔주고 분리시켜준다.
all_stopwords=stopwords.words('english')
all_stopwords.remove('not')
제외어에서 not은 포함시켜주지 않는다.
review=[ps.stem(word) for word in review if not word in set(all_stopwords)]
review=' '.join(review)
corpus.append(review)
제외어가 아닌 것들을 review 로 재설정하고 그것을 만들어둔 리스트에 넣어준다.
3. Bag of Words 모델 생성

from sklearn.feature_extraction.text import CountVectorizer
라이브러리 가져오기
cv=CountVectorizer(max_features=1500)
모델 생성
4. Train,Test set 구분

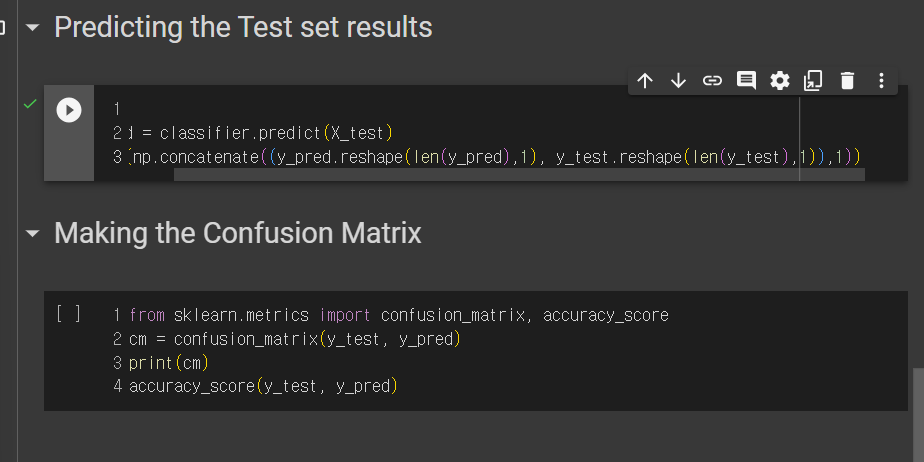
5. Naive Bayes 모델 훈련
6. Test 예측 및 행렬