AI/ML/Decision Tree
의사결정나무
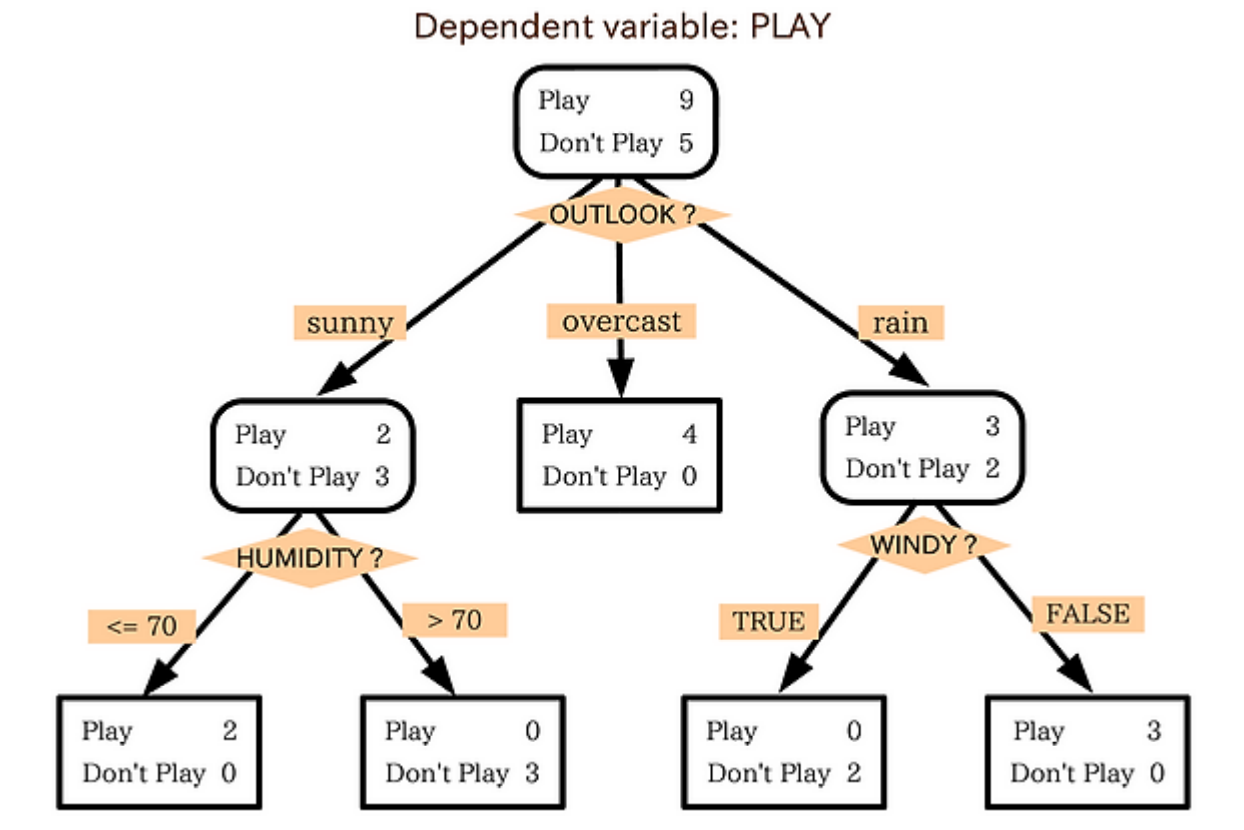
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/ 이곳에서 더 자세히 알 수 있다. 각 변수들을 이곳저곳에 돌려 배치하면서 가장 명확한 트리를 찾는다.
의사결정나무는 회귀, 분류 모두 해결 가능하다는 특징을 가진다.
맨 위를 root node, 맨 밑을 leaf node라고 한다.
아웃라이어들의 영향을 많이 받아 불안정하고, 과적합이 쉽게 발생한다.
가지가 너무 길어지면 각 leaf node에 데이터가 부족해져서 신뢰하기가 좀 그렇다.
Model ensemble
여러 모델을 짬뽕하여 예측하는 방법이다.
- Boosting
- Bagging
등이 있다.
여기서 의사결정나무의 단점을 보완하기 위해 Boosting기법을 사용한다. weak learner들을 합쳐 strong learner를 만드는 기법이다. 적당히 피팅된 의사결정나무(의사결정나무가 아니어도 됨) 여러개를 섞어 예측한다.
분류문제의 경우 과반으로 예측을 하면되고, 회귀문제의 경우 평균/가중평균을 낸다.
Tree-Based Ensemble Model들을 살펴보자
Boosting
AdaBoosting(Adaptive Boosting)
Boosting기법의 업그레이드이다.
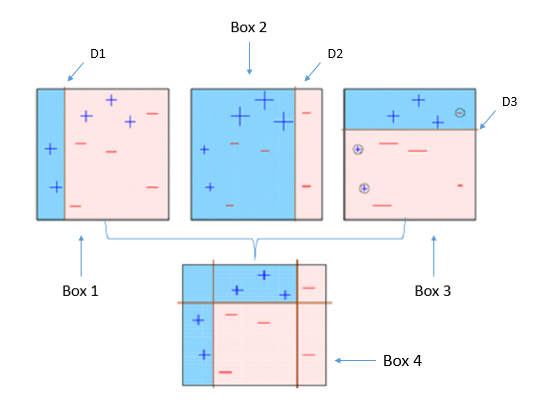
https://towardsdatascience.com/understanding-adaboost-2f94f22d5bfe
- 데이터 학습
- 틀린 부분에 가중치를 두고 재 학습 반복
- 그 과정에있는 모델들을 모두 사용하여 결정
위 사진의 경우 분류문제의 경우고 회귀문제의 경우 회귀를 많이해서 평균을 낸다.
근데 가중치를 곱하다 보면 모델의 Acurracy가 점점 떨어져 쓰레기가 될 수 있다.
어떻게 가중치를 줘야 하나? 여기서 Gradient decent가 들어온다. 가중치를 이리저리 조정해가면서 선정한다. 그렇게 Gradient Boosting 기법이 등장한다.
Gradient Boosting을 사용해서 의사결정나무를 막 만들다보니 성능에 대한 아쉬움이 있었다. 의사결정 나무 자체가 만들기 오래걸리는 모델인데 Sequential로 만들다보니 너무 느리다. 그래서 등장한게 XG Boost이다.
XG Boost
병렬 처리 기법으로 Gradient Boosting의 성능을 끌어올렸다. Sequential하게 모델을 만드는 부분은 그대로 두되, 의사결정나무 자체를 만드는 과정에서 병렬 처리 기법을 사용하였다.
XG Boost는 Hyper-Parameter가 꽤 많아서 최적의 설정값을 찾기가 까다롭다고 한다.
번외로 MS의 LightGBM, EBM이라는 것도 있다.
Bagging
Bootstrap Aggregating의 줄임말이다.
Random Forest
가장 유명한 예는 Random Forest이다. Boosting과 같이 의사결정나무를 여러개 만들어서 합치는건 같으나 Boosting처럼 모델이 Sequential하게 만들어지지 않고 독립적으로 만들어진다.
학습 데이터를 랜덤하게 뽑아서 모델을 만들기 때문이다. 병렬로 모델을 만들 수 있다. 그래서 성능이 좋지만 Boosting류가 성능이 일반적으로 좋다.
번외
n차원 테이블로 표현되는 정형데이터들은 머신러닝을, 이미지와 영상같은 데이터들은 딥러닝을 활용하는 경우가 많다.
근데 정형데이터를 위한 인공신경망, 즉 딥러닝 모델인 TabNet이라는게 있다고..
