AI/ML/Linear Regression
선형 회귀
회귀분석 중 가장 기본적인 형태. 선형 상관 관계(ax + b)를 찾는다.
기울기 a를 가중치, b를 보정치 혹은 편향이라고 부른다.
독립변수(x)가 한개일경우 단순 회귀분석, 여러개일 경우 다중 회귀분석이라고 한다. 여기서 선형회귀를 사용하면 선이 면이 되겠지?(ax+by+cz+...+C) 이것이 선형 결합(Linear Combination)이다. 직선식을 여러개 합친 것이라고 생각하자.
a, b, c 등의 파라미터들을 정할 때 그 값에 대한 평가를 해야한다. 그럴 때 비용 함수를 사용한다.
비용 함수(cost function)
cost 대신 loss, error, objective(목적 함수는 문제를 해결하기 위해 값을 줄이거나 늘려야하는 함수를 말한다. 여기선 cost함수를 최소화시켜야 한다.)가 쓰이기도 한다.
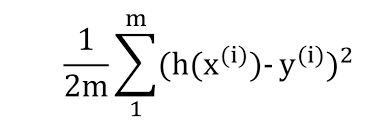
Mean Squared Error Function(MSE)라는 가장 흔한 비용함수이다. 보통 비용 함수는 J로 표시한다.
오차를 제곱하여 평균을 내어주면 된다. 앞에 1/2를 곱하는 것도 있고 안 곱하는 것도 있는 것 같다.
변종으로 Mean Absolute Error Func(MAE)라는 것도 있다고 한다. 제곱이 들어간 MSE는
MAE보다 아웃라이어에 민감하게 변한다.
또 Mean Absolute Percentage Error(MAPE)라고 절대오차가 아닌 상대오차에 절댓값을 씌워 평균을 낸 것도 있다.
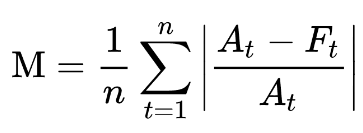
MSE에 루트를 씌운 RMSE라는 것도 있다.
경사 하강법(Gradient Decent Algorithm)
그럼 목적함수를 어떻게 해결할까?
비용 함수는 어찌됬건 대부분의 점에서 미분가능한 그래프를 만들 것이다. 사람은 그래프를 대충 그려보고 최솟값을 구할 수 있겠지만 컴퓨터는 그래프를 그리려면 무한개의 점을 찍어야한다. 그래서 미분 후 최소값을 찾는 방식으로 최솟값을 찾는다.

랜덤한 지점을 미분 후 쭉 내려가는 방식으로 J' = 0의 해를 찾아 해결한다. (미분 방정식을 직접 풀어서 사용할 수도 있다.)
근데 위와 같은 방식을 사용했다가 잘못해서 Local Minima들로 빠져서 Global Minimum을 놓친다면?
빠져나오는 방식이 몇개 있다고 하는데 보통 Global Minimum과 비슷한 값으로 떨어진다고 한다.
보폭을 나타내는 알파(learning rate, step size)는 수동으로 설정하는 상수다. 너무 작으면 속도가 느려지고, 너무 크면 왔다갔다해서 정확도가 떨어질 수 있다. 일반적으로 0.01 ~ 0.001 사이에서 잡는다. 이와 같이 사람이 결정하는 변수를 Hyper-parameter라고 한다. 이를 조절하는 것을 Model Tuning이라고 한다.
번외로 AutoML이라는 것이 있는데, 이는 데이터 전처리, 모델 선택, 하이퍼 파라미터 최적화(HPO)를 알아서 해주는 것이다.
scikit-learn
파이썬으로 traditional ML 알고리즘들을 구현한 오픈 소스 라이브러리.
장점
- 타 라이브러리들과 호환성이 좋음 (Numpy, Pandas 등)
- 통일된 인터페이스
사용법
1. 데이터 불러오기
sklearn.datasets.load_[DATA]() 함수를 통해 데이터를 불러온다.
데이터의 형식은 numpy.array형식으로 주면 된다.
유명한 데이터는 내장되어있다. 예를 들면
var = sklearn.datasets.load_iris() 이렇게 불러올 수 있다.
x를 불러오려면
var.data
y를 불러오려면
var.target 이렇게
2. 데이터 쪼개기
x_train, x_test, y_train, y_test = sklearn.model_selection.train_test_split(x, y, test_size)test_size를 0.3으로 설정하면 0.7을 학습 데이터, 나머지를 테스트 데이터로 사용한다. validation data는 이 함수에서는 없다.
3. 모델 객체 생성
model = sklearn.linear_model.~~~()Hyperparameter가 있는 모델들은 argument로 넣어주면 된다.
이렇게 모델을 생성하고
model.fit(train_x, train_y)학습을 시켜주면 된다.
이제 예측을 하고 Cost function을 돌려보자.
pred_y = model.predict(test_x)
sklearn.metrics.mean_squared_error(pred_y, test_y)mean_squared_error 외에도 성능지표로 accuracy_score(분류문제만), precision_score, recall_score, r2_score 등등 많다.
데이터 정제
numerical -> min-max algorithm or standardization
categorical -> one-hot encoding
Standardization
표준화이다. 고등학교 때 하던 (x-표준편차)/평균 이다.
One-Hot Encoding
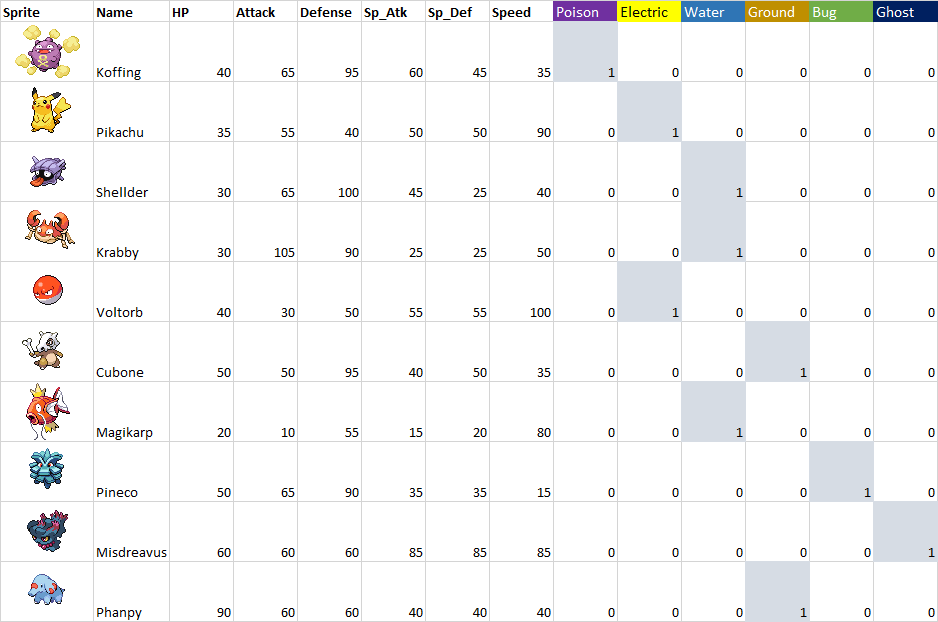
categorical column과 numerical column을 명확히 구분짓기 위해 categorical column은 정수가 아닌 벡터로 변환해서 사용한다.
Linear 기반 모델들은 무조건 해줘야 하는 작업.
Tree 계열 모델들은 굳이 해줄 필요가 없다고 한다.
