AI/개요
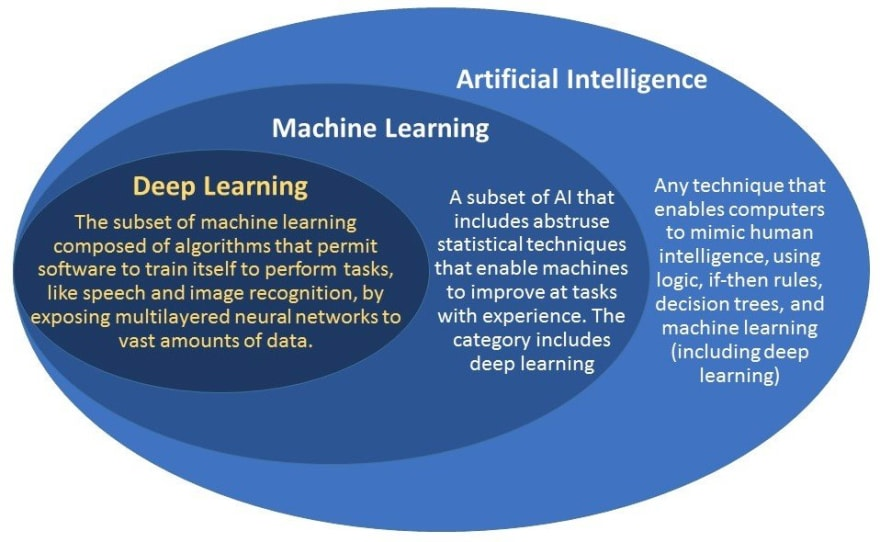
인공지능 (AI)
지각, 추론, 행동, 적응할 수 있는 프로그램
머신러닝 (Machine learning)
데이터가 늘어날수록 성능이 향상되는 알고리즘
정의
A field of AI that gives computers the ability to learn from data, without being explicitly programmed - Arthur Samuel, 1959
A computer program is said to learn from experience E with repect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E. - Tom M. Mitchell, 1997
프로그램이 데이터를 학습하고 성능이 향상된다는 점이 중요한 것 같다.
종류
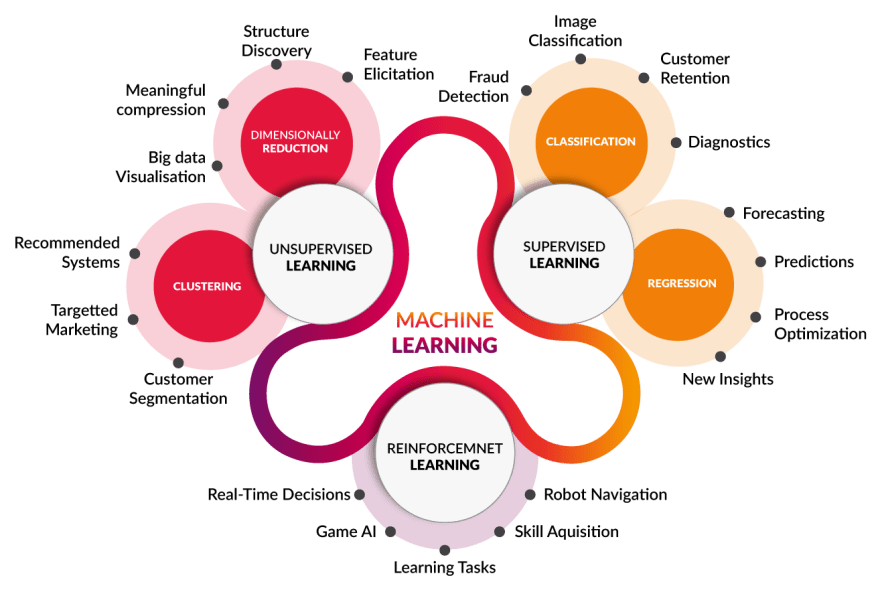
지도학습(교사학습) / 비지도학습 / 강화학습
지도학습
데이터와 함께 정답이 제공된다.
데이터에 적합한 함수를 근사하는 과정이라고 볼 수 있다.
-
REGRESSSION(회귀)모델은 정답이 연속적인 값(Numerical)일 경우 (온도, 가격 등)
-
CLASSIFICATION(분류)은 정답이 불연속적인, 범주형 값(Categorical)일 경우(강아지 품종 등)
-
대표적인 알고리즘: Linear/Logistic regression, Decision Tree, Bayesian Classification, Neural Network, Hidden Markov Model (HMM) 등
비지도학습
정답이 제공되지 않고 데이터의 성향을 분석함.
CLUSTERING(군집화)는 비슷한 것들 끼리 묶는것,
DIMENSIONALLY REDUCTION(차원축소)은 데이터의 차원을 날리는 것이다. 차원은 2차원데이터에서 column같은 의미이다.
ex) 고객군 분류, 장바구니 분석(Association Rule), 추천 시스템 등
강화학습
연속적인 단계마다 상태(State)를 인식하고 각 상태에 대해 결정한 행동(Action)들의 집합에 대해 환경으로부터 받는 보상(Reward)을 학습하여 전체 행동에 대한 보상을 최대화하는 행동 선택 정책(Policy)을 찾는 알고리즘.
시행착오(Sequential decision making)를 통한 학습을 한다.
알파고가 좋은 예다.
알고리즘 - Monte Carlo Methods, Markov Decision Processes, Q-learning, Deep Q-learning, Dynamic Programming 등
ex) 로봇 제어, 공정 최적화 등
학습이란?
예측과 정답 사이 오차를 줄여가는 과정
Capaciity
모델의 복잡성을 뜻함. 다항함수로 치면 차수를 생각할 수 있다. 인공신경망의 경우 layer의 개수를 들 수 있따.
근사를 과하게 해서 Capacity가 올라가면 오버피팅이 발생할 수 있다. 그 반대는 언더피팅이 발생한다. (데이터의 경향성을 무시한 채 학습데이터에 대한 오차만 줄이는 방향으로 모델이 발전하면 오버피팅됨)
feature
데이터들에서 현상의 원인이 되는 독립변수, 결과가 되는 종속변수가 있는데 여기서 독립변수들을 feature라고 한다. 종속변수들은 회귀모델에서는 label, target 등으로 불리며 분류모델에서는 label 로 부른다
generalization
일반화. 학습데이터가 아닌 새 데이터가 투입되었을 때도 오차가 적게나오도록 하는 것이다.
generalization error 라고 하면 새 데이터를 마주칠 시 오차를 말한다.
데이터 나누기(교차 검증)
가지고 있는 데이터를 전부 모델의 학습용으로 써버리면, 테스트를 할 수 없게된다.
그래서 세 가지 용도로 데이터를 나누어 사용한다.
- Training Data
- Validation Data
- Test Data
Validation Data와 Test Data가 나한테는 비슷하게 느껴지는데(Validation Data를 사용하지 않는 경우도 있다고 한다.), 전자는 유효한 모델을 걸러낼 때 사용하고 후자는 걸러진 모델들의 성능을 평가할 때 사용하는 것 같다.
세 가지 데이터간 비율은 데이터의 총량이 적을수록 6:2:2, 7:3 정도로 설정하고 엄청 많은 경우는 99:0.5:0.5 정도로 극단적으로 잡는다고 한다.
K-Fold Cross Validation
Test Data를 제외한 나머지 데이터들로 여러 모델을 학습, 비교하는 방법이다. 데이터를 K등분내고 한 조각을 Validation Data로, 나머지 k-1조각을 Training Data로 활용하여 각 모델별 점수를 매기고 비교한다.
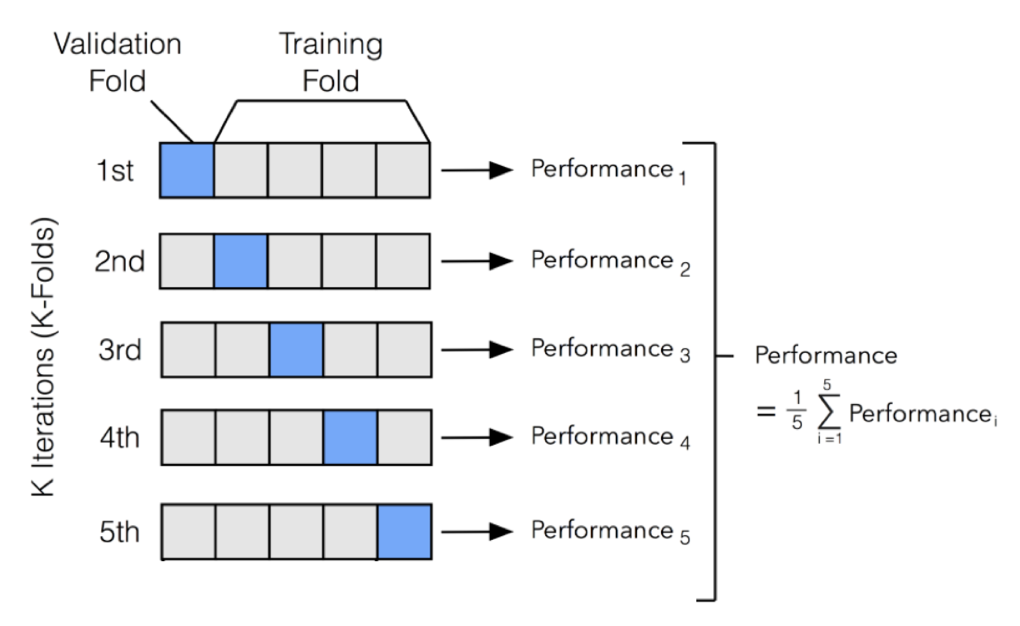
k번 돌고 평균을 낸다.
점수를 바탕으로 모델을 결정한 다음 등분을 내지 않은 전체 데이터를 대상으로 학습 후 따로 떼어뒀던 Test Data로 테스트 후 점수를 확인한다.
Stratified
분류 문제에서 분류(class)가 몇개 없을 때 표본들에서 분포가 편향되는 것을 방지해주는 것이다. k = 10이면 10토막 모두 비슷한 분포를 맞춰준다는 것이다.
데이터 불균형에 관한 글
https://3months.tistory.com/414?category=756964
https://www.tensorflow.org/tutorials/structured_data/imbalanced_data?hl=ko#oversample_the_minority_class
딥러닝 (Deep Learning)
머신러닝 중 신경망을 통해 데이터를 학습하는 알고리즘
