데이터 프레임 내의 특정값(특정문자)를 찾고자 할때 사용할 수 있는 좋은 문법인 str.contains()에 대해 소개한다.
위와 같은 데이터가 있다고 가정해보자. 먼저 해당 데이터는 비디오 게임출고량에 대한 데이터 이며, 컬럼은 순서대로
"Name: 게임의 이름",
"Platform: 게임이 지원되는 플랫폼",
"Year: 출시년도",
"Genre: 게임 장르",
"Publisher: 출판 회사",
"NA_Sales: 북미 출고량",
"EU_Sales: 유럽 출고량",
"JP_Sales: 일본 출고량",
"Other_Sales: 기타지역 출고량"이렇게 이루어져 있다.
제목에 적은것 처럼 판다스에서 데이터프레임내의 특정 문자를 검색해서 찾는 방법인 str.contains()에 대해서 예시를 만들어보았다.
Boss : Ds(Platform)에 지원되는 게임의 목록을 뽑아줄 수 있겠어??
우리는 다음과 같은 미션을 상사에게 받았다고 가정해보자. 먼저 나에게 가장 익숙한 문법은 dataset[dataset['Platform']=='DS'] 이러한 방법을 사용하여 뽑았을 것이다. 하지만 이번에는 str.contains()를 통해서 뽑아보려고 한다.
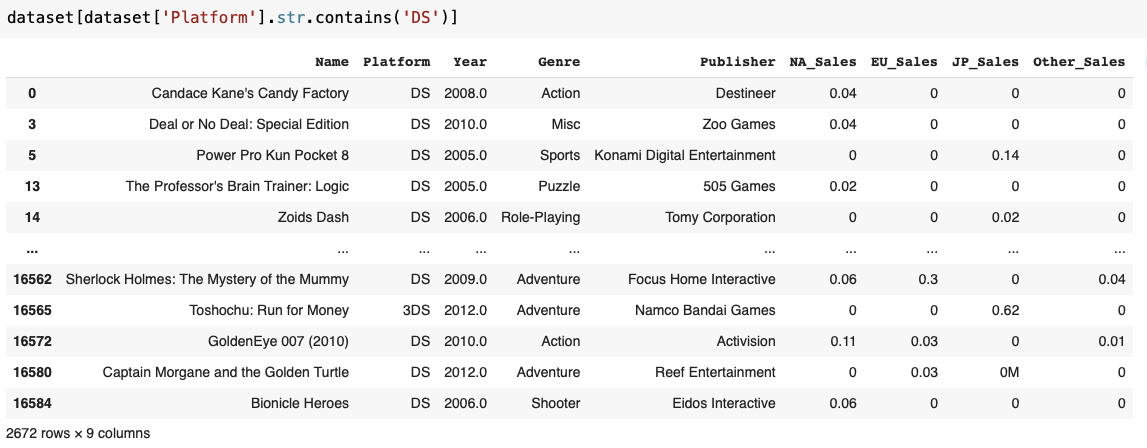
이렇게 str.contains()를 활용해서도 뽑을 수 있다.
그러면 질문이 있을것이다. dataset[dataset['Platform']=='DS'] 이렇게 뽑으면 되는데 왜 저방법을 쓸까!?
복잡하게 데이터 프레임을 재구성 하는 과정에서는 분명히 이 방법이 도움이 될것이다. 기억해두자!!
큰 이유는 없지만 분명 도움될것이다.... 이게 이유다 ㅎㅎ..
그리고 또 str.contatins()에는 파라미터를 던져줄 수 있다.
대소문자를 구분없게 만들어주는 파라미터

소문자/ 대문자 구분이 되지 않기 때문에 파라미터 중에 case = False 를 사용하게 되면 대,소문자 구분이 사라진다.

nan값이 있을때 파라미터
기본적으로 str.contains() nan값이 있을때 검색이 안된다... 따라서 이때 파라미터를 사용하여 방지 할 수 있다.
na = True 파라미터를 넣어준다면 검색이 가능할 것이다.
