테이블 형식의 데이터들은 우리가 필요한 형태로 다양하게 가공을 할 수 있는데 지난번에는 group by, melt, cross-tab, pivot-table 형태로 변환시키는것을 정리를 했었다.
(참고링크 : https://velog.io/@ljs7463/판다스-데이터프레임-재구조화-정리)
이번에는 계층적 색인으로 재형성하는것을 정리해보고자한다.
주요 키워드
- stack : 데이터의 칼럼을 로우로 피벗시킨다.
- unstack : 로우를 칼럼으로 피벗시킨다.
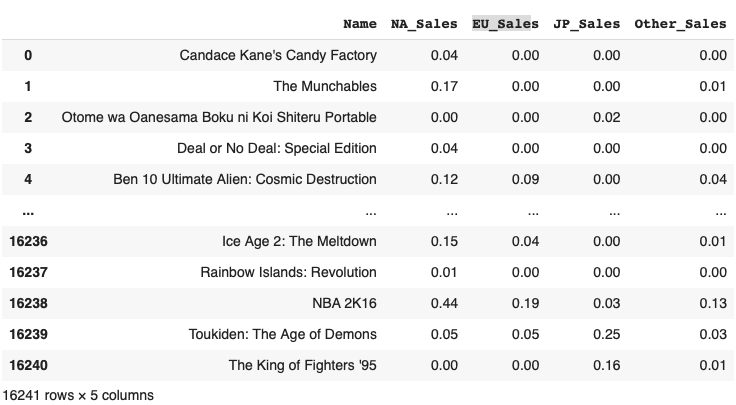
# 데이터 및 컬럼 설명
- 비디오게임 판매량 데이터
Name : 비디오 게임 이름
NA_Sales : 북미 지역 출고량
EU_Sales : 유럽 지역 출고량
JP_Sales : 일본 지역 출고량
Other_Sales : 기타 지역 출고량위와 같은 데이터가 있다고 가정해보자.
1. stack()
해당데이터가 df로 저장되어있을 때 df.stack() 을 사용하면 다음과 같은 형태를 보인다.

위에 보이는 것 처럼 데이터의 컬럼이 로우로 피벗이 된 형태이다.
만약에 df.unstack()을 하게 되면 어떤 형태를 뛸까??
2. unstack()
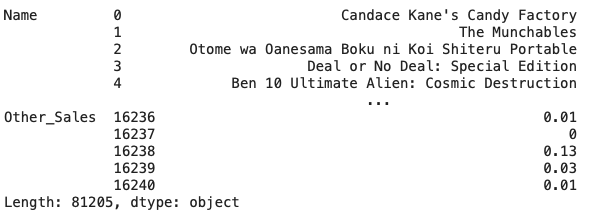
Name에 있는 제목이 먼저 출력이 되는것을 볼 수 있다. 즉, 로우를 컬럼으로 피벗시킨것이다.
이렇게 우리는 필요에따라 변형을 시킬 수 있는 두가지 추가적인 방법을 알게되었다.
(ps. sql만 너무 하다보니 판다스에서 까먹은 부분도 생기고 쿼리문과 충돌하다보니 정리를 위해 오늘 포스팅을 하게되었다.)

문제를해결하는도구로서의"데이터"