판다스
1.판다스 결측값 제거하기(dropna())

aixs : 행(0) or 열(1)how : any(결측값이 하나라도 있으면 해당하는 행 제거), all(전부다 결측값일때 해당행 제거)thresh : 각 행의 결측지가 3개 이상이 되면 삭제subset : 특정컬럼에서만 결측지가 있는 행 삭제
2.판다스 데이터프레임 재구조화 정리
groupby, crosstab, pivottable, melt, 그룹별로 집계를 하는 함수.위와 같이 전체 데이터 프레임이 있는데 우리의 목표는 지역별 장르의 출고량을 비교하는것이다.그래서 데이터 프레임의 구조를 새롭게 해야한다.즉, 우리는 장르와 각지역들간의 출고량
3.판다스 계층적 색인( stack(), unstack() )
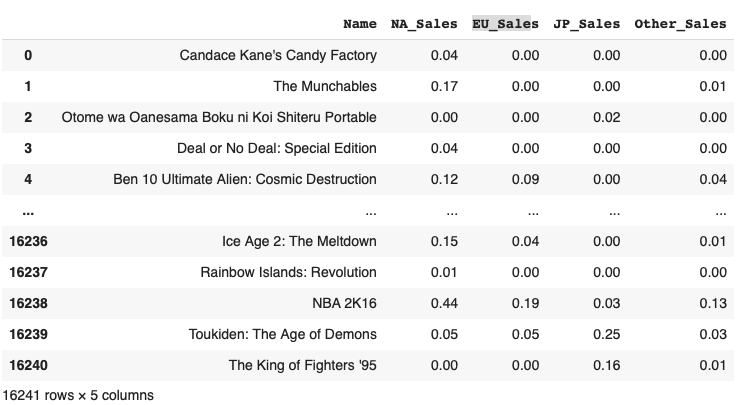
테이블 형식의 데이터들은 우리가 필요한 형태로 다양하게 가공을 할 수 있는데 지난번에는 group by, melt, cross-tab, pivot-table 형태로 변환시키는것을 정리를 했었다.(참고링크 : https://velog.io/@ljs7463/판다스
4.판다스 특정 문자로 검색하는 str.contains()
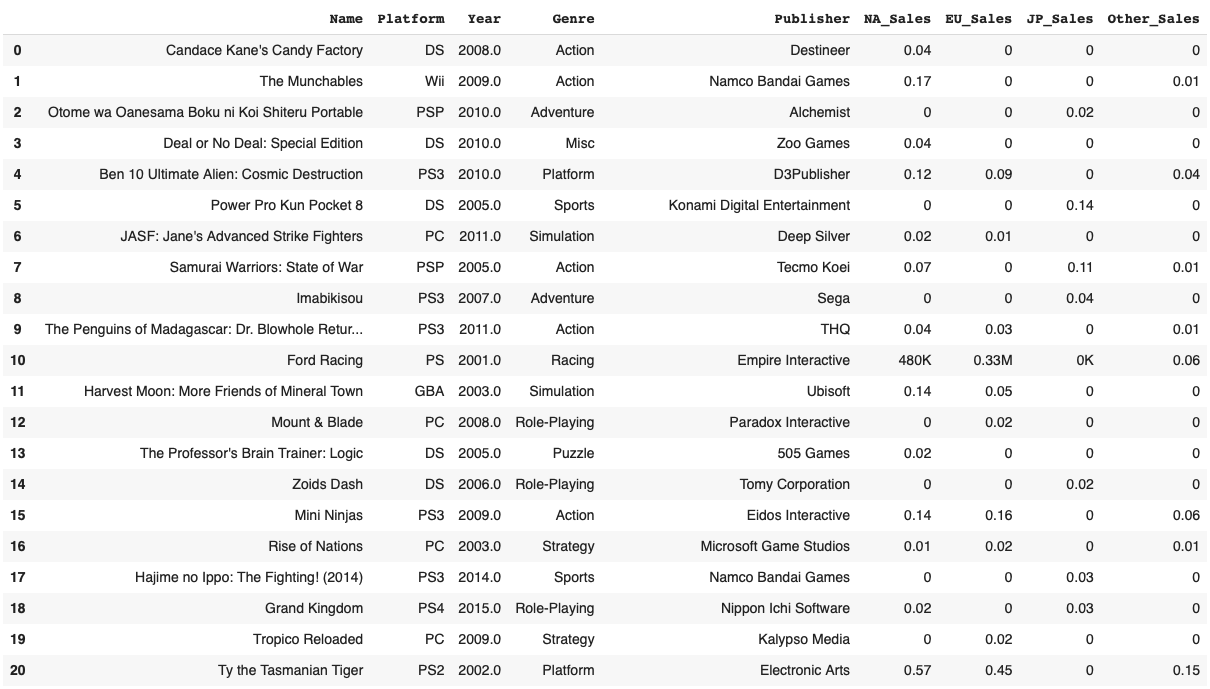
데이터 프레임 내의 특정값(특정문자)를 찾고자 할때 사용할 수 있는 좋은 문법인 str.contains()에 대해 소개한다.위와 같은 데이터가 있다고 가정해보자. 먼저 해당 데이터는 비디오 게임출고량에 대한 데이터 이며, 컬럼은 순서대로 이렇게 이루어져 있다. 제목에
5.판다스 to_datetime(format)

자료형으로 표현된 날짜를 to_datetime을 사용하면 datetime형으로 변경할 수 있다.다음과 같은 데이터 프레임이 있다고 가정해보자. 모든 값을 object형태로 되어있고 우리는 이를 datetime으로 바꿔야한다. 이렇게 to_datetime으로 바꿀 수 있
6.특정문자가 포함되거나 일치하는 데이터(행)추출하기
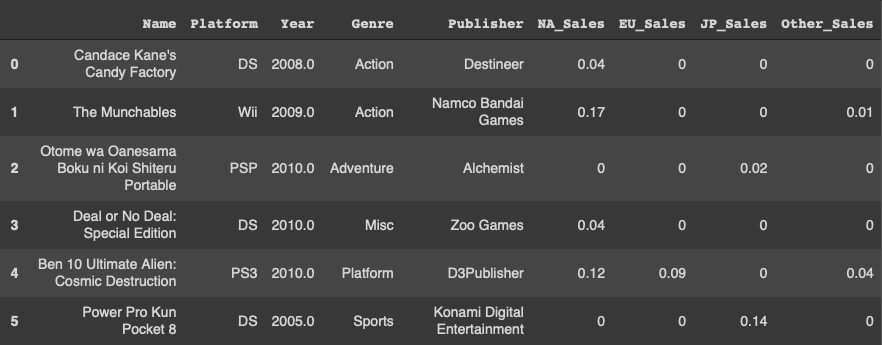
일을 하면서 특정한 값에 대해서 매핑을 하기위해 DB속의 데이터를 가져와서 매핑 컬럼을 추가해줄일이 있었다. 이때 원하는 조건의 값을 찾아서 해당하는 조건이 담긴 행에 매핑테이블을 붙여주었는데 이때 애용하게된 방법을 공유하고자 한다.(예시 데이터는 사내 데이터와는 무관
7.특정 컬럼에 중복값 이 있는 행 제거하기
여러가지 데이터를 개인 혹은 회사의 컨벤션(convention)에 맞게 여러 테이블을 합칠때가 있는데 이때 테이블 간의 연결을 통해 깊이(depth)가 깊어질 때 특정컬럼값의 중복값이 생기게 되는데 목적에 따라 이 중복값을 제외하고 싶을 때가 있다. 그럴때 우리가 잘알
8.특정 문자열이 포함되지 않는 데이터(열)찾기, 추출하기
지난번에 특정 문자열이 포함된 데이터(열)을 추출하는 것을 다루어 봤는데 이번에는 포함되지 않는 데이터(열)를 추출하는것을 정리해 보려고 합니다.( 특정문자열이 포함되는 데이터(열) 추출 : https://velog.io/@ljs7463/특정문자가-포함되거나-
9.판다스 각각의 로우(row) 백분율 구하는 방법(The method Compute row percentages in pandas DataFrame)
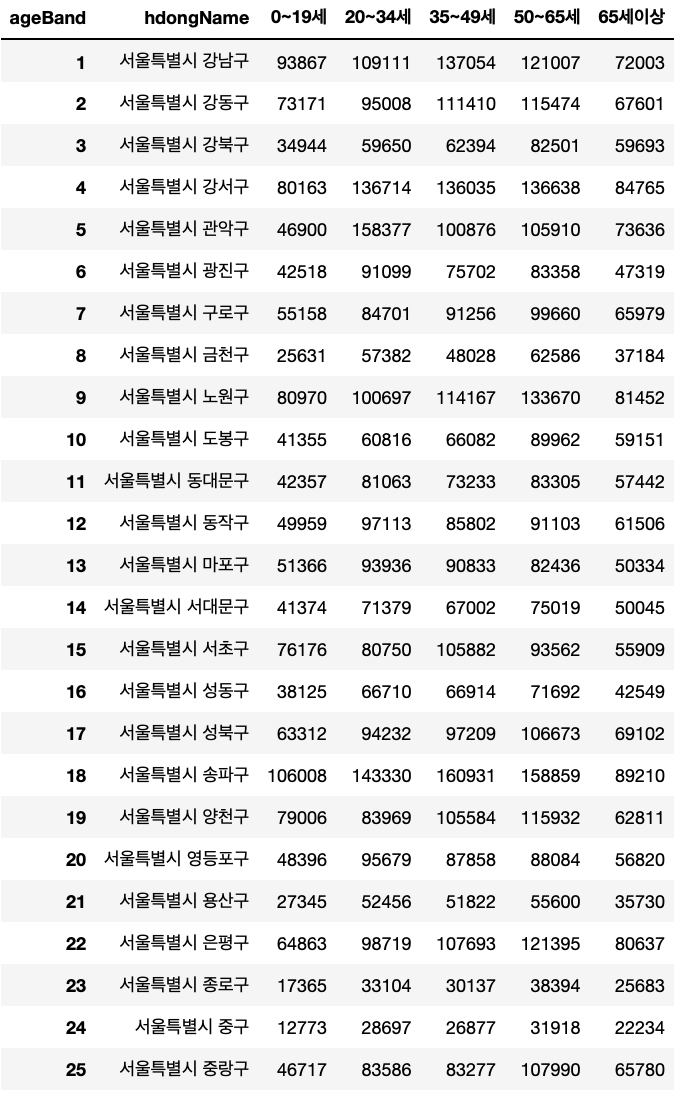
판다스로 작업을 하다보면 각각의 데이터(행, row) 마다 백분율을 구하게 되는 경우가 있다. 이해를 돕기 위해 아래의 예시를 먼저 보자."서울시의 시군구와 연령별 인구 수" 에 대한 테이블이 있다.이때 우리는 해당 데이터를 봤을때 어떤 시군구에 어떤 연령층이 많은지
10.구글코렙, 쥬피터노트북 한글 폰트 적용하는 방법
데이터 분석을 하다보면 시각화를 통해 데이터를 요약하고 인사이트를 얻는 시도를 하게 된다. 하지만 시각화 작업시 한글폰트가 적용되지 않아서 깨지는 경우가 발생하는데 이때 구글코렙과 쥬피터노트북 각각 해결하는 방법을 간단하게 정리해 보았습니다.구글코렙쥬피터 노트북이렇게
11.[판다스] 날짜 범위를 출력 하는 date_range
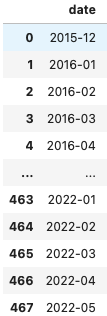
시계열 데이터를 다루다 보면 특정시점에서 특정시점까지의 날짜를 원하는 간격으로 필요한 경우가 생긴다. 이를 도와주는 date_range라는 함수가 있고, 매우 편하다.위의 코드를 통해 시작하는 날짜(startDate)에서 끝나는 날짜(endDate) 까지 원하는 간격(
12.판다스 inplace = True를 사용하지 말아야 하는 이유
판다스를 사용하다 보면 우리는 1\. fillna()를 통해 결측값을 채우기도 하고, 2\. dropna()를 통해 결측값을 지우기도 하며, 3\. replace()를 통해 값을 변경하기도 합니다.이 과정에서 데이터분석가들은 두가지 유형으로 나누어집니다.inplace
13.판다스 데이터프레임 name속성 제거

판다스를 다루다 보면 pivot_table과 같이 데이터프레임을 변형하는 여러가지 메서드를 사용하는 상황이 생긴다. 이때 다음과 같은 형태의 데이터 프레임을 마주치는 경우가 있을것이다.예시데이터의 경우 경기도의 주택종류별 갯수에 해당하는 데이터입니다.해당 데이터 프레임