인코딩을 하는이유
우리는 머신러닝의 모델을 만들때 데이터를 인코딩 하게된다.
컴퓨터는 우리와 달리 텍스트를 인식하지못하여 이해를 할 수 있는 숫자의 형태로 만들어줘야한다.
그래서 Categorical한 데이터를 숫자로 바꾸어 주는것을 우리는 인코딩이라고 부른다.
인코딩하는 방법
1. One-hot-encoding
OneHotEncoding은 category_encoders라이브러리를 사용하면 범주형 데이터만 원핫 인코딩을 수행할 수 있다.
# 라이브러리 불러오기
from category_encoders import OneHotEncoder
# 원핫 인코딩
encoder = OneHotEncoder(use_cat_names = True)
X_train = encoder.fit_transform(X_train)
X_test = encoder.transform(X_test)여기서 알아두어야 할 점이 몇가지 있다.
먼저 use_cat_names =True를 해주면 이전에 있는 컬럼 names를 같이 가져갈 수 있다. 이해를 돕기위해 아래 사진으로 설명하겠다.
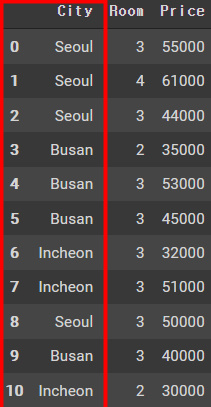
기존에 다음과 같은 City라는 컬럼에 Seoul과 Busan, Incheon이 있다고 가정하자.
이를 위의 원 핫 인코딩을 사용하면 자동으로 범주형 데이터만 인코딩이 진행되고 다음과 같은 모습으로 나타난다.

여기보면 컬럼내임 그대로 남아있고 뒤에 값들이 나타난다 여기서 use_cat_names = True를 사용해주었기 때문에 컬럼명이 그대로 붙은것을 확인할 수 있다.
두번째로, X_train 을 fit_transform을 시켜주었기 때문에 이미 모델이 만들어진것이다. 따라서 X_test를 인코딩할때는 fit을 쓰지않고 transform만 사용하여 기존 모델과 같이 변환을 시켜주면 된다.
2. get_dummies(판다스)
두번째는 판다스의 get_dummies를 이용하는 방법이다.
# pd.get_dummies()
pd.get_dummies(df, prefix = ['City'])위와 같은 데이터를 만들기 위해서 get_dummies를 사용해본 코드이다.
prefix는 점두사 라고 생각하면 된다. 즉 값의 앖에 City를 붙여준다.
이를 출력하면 다음과 같다.
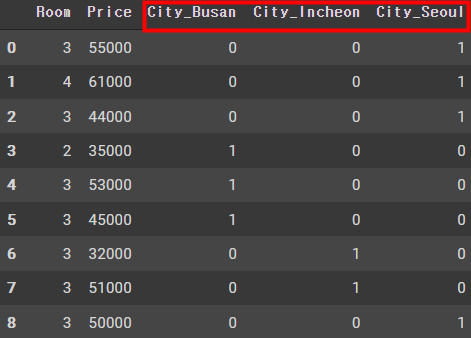
One-hot-encoding과 get_dummies()의 차이
그래서 둘 중에 뭐를 쓰라는건데??
여기에 대한 답을 적어보겠다.
원핫 인코더의 좋은점은 Ordinal변수도 모두 범주형으로 인식하여 처리한다는 점이다.
get_dummies는 Ordinal데이터를 숫자로 인식하기때문에 그대로 둔다.
이 두개의 방법 test데이터에 새로운 값이 들어오면 에러가 걸리게 된다.
따라서 결론은, Ordinal도 한번에 바꾸려면 원핫인코딩 쓰고 아니면 편한거 쓰면될것같다.
