약 10일간 머신러닝을 공부 한것같다.
하면서 제일 손이 많이 가고 귀찮았던 부분이면서 해결 방법을 찾고있었던 스케일링과 다양한 학습들을 한번에 해주는 방법을 공부하게 되었다.
그것이 바로 사이킷런의 파이프라인이다.
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
enc = OneHotEncoder()
imp_mean = SimpleImputer()
scaler = StandardScaler()
model_lr = LogisticRegression(n_jobs=-1)
X_train_encoded = enc.fit_transform(X_train)
X_train_imputed = imp_mean.fit_transform(X_train_encoded)
X_train_scaled = scaler.fit_transform(X_train_imputed)
model_lr.fit(X_train_scaled, y_train)
X_val_encoded = enc.transform(X_val)
X_val_imputed = imp_mean.transform(X_val_encoded)
X_val_scaled = scaler.transform(X_val_imputed)
# score method: Return the mean accuracy on the given test data and labels
print('검증세트 정확도', model_lr.score(X_val_scaled, y_val))
X_test_encoded = enc.transform(X_test)
X_test_imputed = imp_mean.transform(X_test_encoded)
X_test_scaled = scaler.transform(X_test_imputed)
y_pred = model_lr.predict(X_test_scaled)
>>> 검증세트 정확도 0.~~~~이런 흐름으로 일일이 모델을 학습시켜주었었다.
정말 귀찮으면서도 번거로운 작업이 아닐수 없다.
하지만 이것을 한번에 해결해주는 것이 파이프라인이다.
파이프라인을 통해서 똑같은 작업을 해보겠다.
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
StandardScaler(),
LogisticRegression(n_jobs=-1)
)
pipe.fit(X_train, y_train)
print('검증세트 정확도', pipe.score(X_val, y_val))
y_pred = pipe.predict(X_test)
>>> 검증세트 정확도 0.~~~~끝이다. 다음과같이 pipeline에 학습하고자 하는것을 한번에 집어놓고 pipe를통해 한번에 학습을 적용할 수 있다.
또한 추가적으로 named_steps라는 속성을 통해서 파이프라인의 각 스텝에 접근이 가능하다.
pipe.named_steps
이런식으로 출력이 된다.
이를 활용하여 유사 딕셔너리 형태로 파이프라인 내 과정에 접근이 가능하도록 한다.
import matplotlib.pyplot as plt
model_lr = pipe.named_steps['logisticregression']
enc = pipe.named_steps['onehotencoder']
encoded_columns = enc.transform(X_val).columns
coefficients = pd.Series(model_lr.coef_[0], encoded_columns)
plt.figure(figsize=(10,30))
coefficients.sort_values().plot.barh();다음과 같은 코드를 통해 plot을 찍을 수 있는데 결과는 아래와 같다.
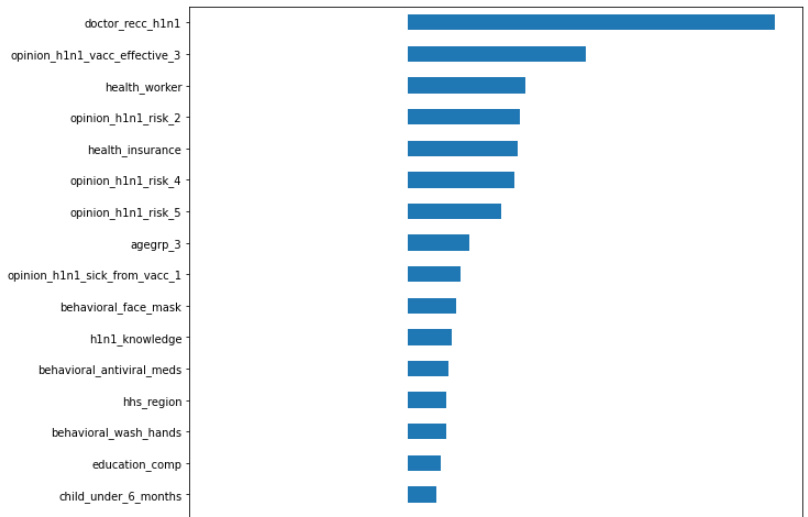
이런식으로 접근할 수 있는 방법이 있으므로 알아두길 바란다.

문제를해결하는도구로서의"데이터"