Groupby
그룹별로 집계를 하는 함수.
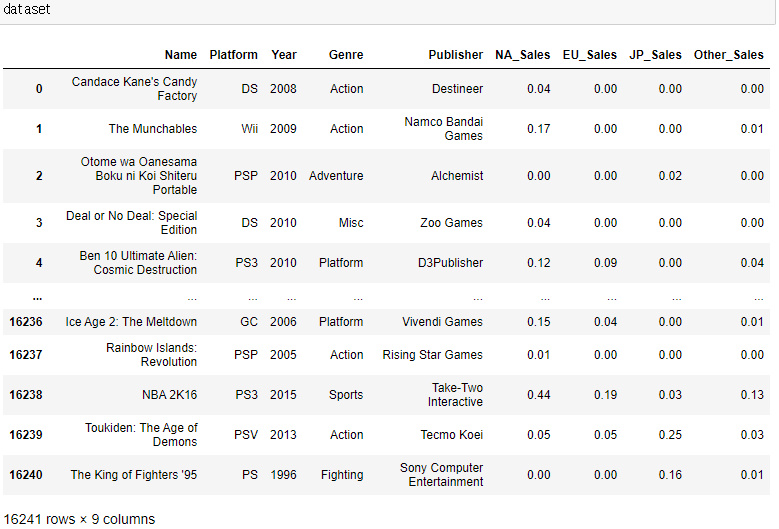
위와 같이 전체 데이터 프레임이 있는데 우리의 목표는 지역별 장르의 출고량을 비교하는것이다.
그래서 데이터 프레임의 구조를 새롭게 해야한다.
즉, 우리는 장르와 각지역들간의 출고량확인을 위한 새로운 데이트 프레임이 필요하다.
이때 그룹별로(각 지역별) 집계를 하는 함수인 groupby를 사용할 수 있다.
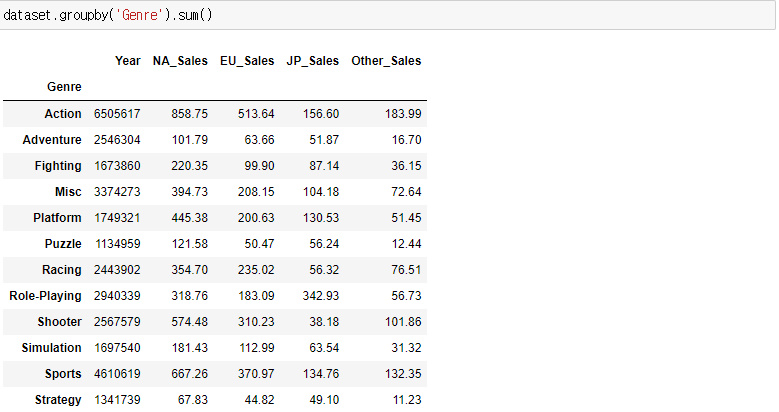
먼저 장르(Genre)에 따른 출고량의 합을 알아보기위해 위와 같이 만들어준 모습이다.
groupby는 그룹별 집계이기 때문에 groupby를 묶어준 후에 sum,mean등의 하고자하는 계산을 무조건 넣어주어야한다.
또한 연산을 하는 것이므로 따로 지정을 해주지 않는다면 데이터 셋 내의 모든 numerical컬럼들이 표에 나타난다.
우리가 필요한 것은 각 지역별 장르의 출고량의 비교이므로 년도(Year)는 필요없다.
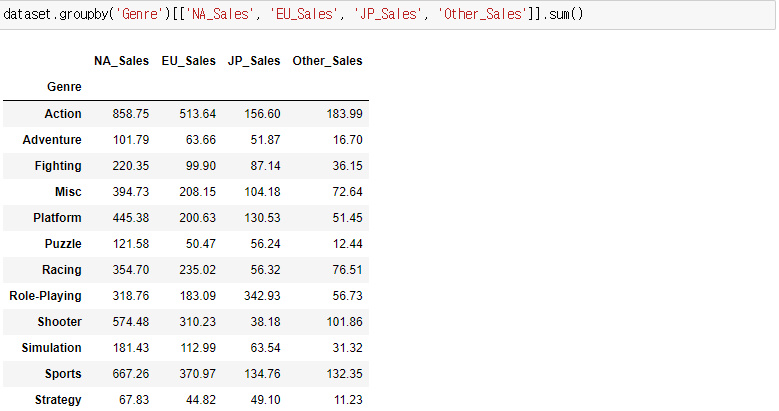
이렇게 groupby는 ()를 사용하고 연산을 할 컬럼은 [ ] 를 통하여 넣어주면된다.
melt함수
(melt함수가 너무좋아서 멜며들었습니다ㅎㅎ)
melt함수는 지정하는 컬럼을 각 행으로 보낸다고 생각하면 된다..
melt가 사전적 정의로는 '녹다'라는 그림으로 많이 쓰인다.
컬럼을 각 행으로 녹여낸다라고 생각하면 될 것 같다.
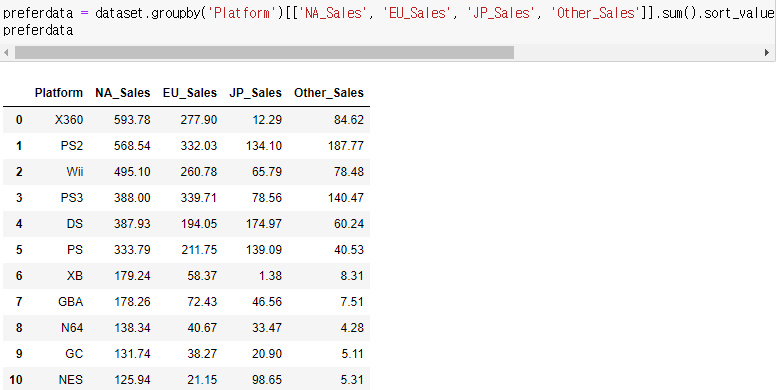
위와 같은 데이터 프레임이 있다고 생각해 보자
하지만 위의 데이터로는 어떠한것도 얻기 힘들어 보인다.
따라서, 나는 플렛폼과 지역에 따라서 출고량이 어떻게 형성되는지 알아보고 싶다 그러면 어떻게 melt를 활용해야할까
platform을 기준으로 각지역을 녹여보자!
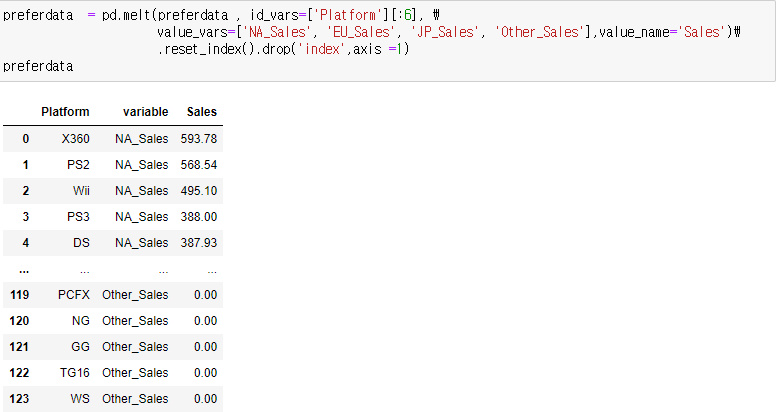
melt함수를 사용하여 파라미터로 id_vars와 value_vars를 지정해주어 위와 같이 만들 수 있다.
id_vars는 기준되는 컬럼이다 즉, 플렛별로 지역에따른 출고량을 확인하고 싶으므로 플렛이 기준이 된다.
value_vars는 이제 컬럼을 각각의 행으로 만들어주는것이다.
위의 데이터 프레임에서 보듯 variable이라는 컬럼명으로 지역들이 만들어진것이 보인다.
컬럼은 var_name을 쓰게되면 우리가 각행으로 끌고온 지역의 이름을 바꿀수 있고, value_name하면 데이터 프레임에서 값이 되었던 출고량의 컬럼명이 바뀌게 된다.
Crosstab
크로스탭은 집계데이터를 표로 만들어 놓은것을 말한다
그리고 크로스탭은 피벗테이블의 한 종류라고 볼 수 있다.
먼저 사용법으로는
pd.crosstab(index = , columns = , values = , aggfunc = ) 이렇게 구성되어 있다
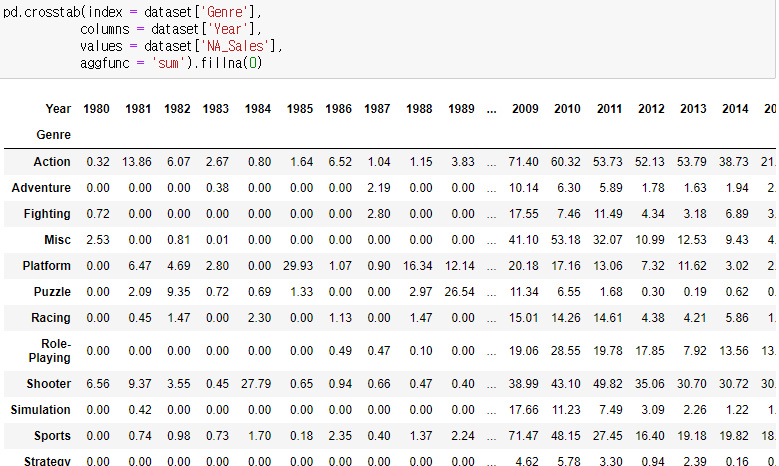
위 처럼 각각에 값을 넣어주면 다음과 같은 crosstab이 나오게 된다.
Pivot_table
피벗테이블은 통계표라고 생각하면된다.
데이터를 요약, 분산, 탐색을 할 수 있으며 여러가지 데이터들끼리의 통계적인 비교가 가능하다.
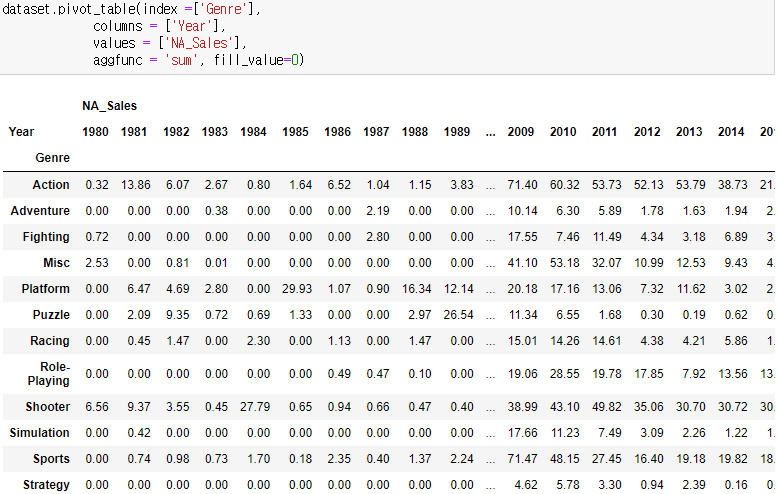
피벗테이블과 크로스텝의 차이는 피벗테이블의 경우 이미 DataFrame일 것으로 예상한다는 점이 다르다.
