Decision Tree
결정트리 모델이란 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 (Tree)기반의 분류 규칙을 만드는것으로 이 모양이 나무를 닮아 Tree모델이다.
- 구조
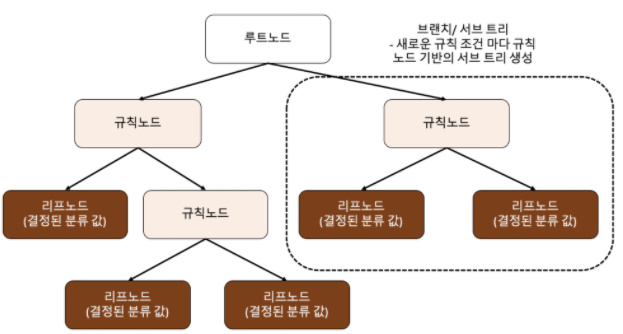
(출처 :파이썬 머신러닝 완벽가이드)
- 구조 설명
- 루트노드(root) : 트리가 시작된 곳(뿌리)
- 규칙노드 : 규칙조건이 되는 곳
- 리프노드 : 결정된 클래스 값
- 서브트리 : 새로운 규칙 조건마다 생성
이 모델은 어떤 기준으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘 의 성능을 크게 좌우한다.
하지만 규칙이 많다는 것은 좀 더 예측을 위한 학습이 잘된다고 말할 수 있음과 동시에 복잡하다는 의미이며 이는 과적합 으로 이어질 수 있다.
즉, 트리의 깊이(depth)가 깊어질 수록 예측성능이 저하될 가능성이 높기 때문에 적절한 값을 찾아야한다.
가장 적은 노드로 높은 예측을 가지려면 균일하게 나누어야한다(분류시 최대한 많은 데이터가 포함되어야한다).
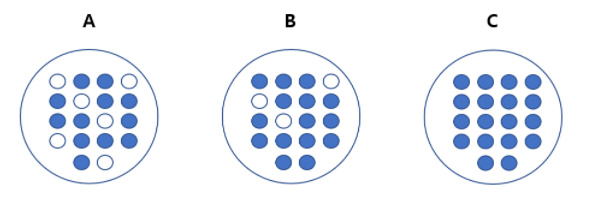
(출처 :파이썬 머신러닝 완벽가이드)
A가 가장 균일도가 낮고,
C가 가장 균일도가 높다.
이러한 데이터셋의 균일도는 데이터를 구분하는 데 있어서 필요한 정보의 양에 영향을 미친다.
-
A의 경우 상대적으로 혼잡도가 높고 균일도가 낮기 때문에 같은 조건에서 데이터를 판단하는데 있어서 더 많은 정보가 필요하다.
-
즉, 더 많은 규칙이 필요하고 그만큼의 새로운 노드들을 거쳐야 한다는 의미이다.
-
또한 노드는 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙조건을 만듭니다. 즉, 첫번째 뿌리 노드가 가장 균일도가 높게 쪼갤 수 있는 조건입니다.
이러한 정보의 균일도를 측정하는 방법으로는 엔트로피를 이용한 정보이득( Information Gain)지수와 지니계수가 있다.
-
정보이득(Information Gain)은 엔트로피라는 개념을 기반으로 한다. 엔트로피란 주어진 데이터 집합의 혼잡도를 의미하는데, 서로 다른 값들이 섞여 있으면 엔트로피가 높고, 같은 값으로 섞여있으면 엔트로피가 낮다. 여기서 정보이득지수는 1 - (엔트로피 지수) 를 의미합니다.결정트리는 방금 언급한 정보 이득 지수로 분할을 한다.
-
지니계수는 낮을 수록 데이터의 균일도가 높고, 지니계수가 높으면 균일도가 낮음을 의미한다.
지금 배우고 있는 DecisionTreeClassifier는 지니 계수를 이용하여 데이터 세트를 분리하는것이 default이면 이는 엔트로피로 바꿔서 설정할 수 있다. -
불순도(impurity)라는 개념이 있는데 이것은 여러 범주가 섞여 있는 정도를 이야기 한다. 예를들어 (45%,55%)인 샘플은 불순도가 높은 것이며 (80%,20%)인 샘플이 있다면 상대적으로 위의 상태보다 불순도가 낮은것이다.
즉, 불순도가 낮다 = 지니계수가 낮다 = 엔트로피가 낮다 = 균일도가 높다
(주의할 점은 클래스가 섞여있다고(불순도가0이아니라고)나쁜 것은 아니다.)
요약하면 균일도가 높다는 것은 같은 데이터가 많이 섞여있다는 것이며, 이는 정보이득지수가 높다는 것인데, 정보이득지수는 1 - (엔트로피) 이다. 엔트로피는 낮을수록 데이터가 균일하며, 지니계수 역시 0이 가장 평등하고 1로 갈수록 불평등해 지니계수가 낮을 수록 윤일도가 높다.
결정트리 모델의 특징
장점
- 정보의 균일도라는 룰을 기반으로 하고 있어서 알고리즘이 쉽고 직관적이다.
- 정보의 균일도만 신경쓰면 되므로 특별한 경우를 제외하고는 각 피처의 스케일링과 정규화 같은 전처리 작업이 필요없다.
- 선형회귀 모델과 달리 특성들간의 상관관계가 많아도 트리모델은 영향을 받지않는다.
- 비선형 모델에서 또한 depth를 조절(하이퍼파라미터를 수정하여)함으로서 모델을 학습할 수 있다.
- 수치형, 범주형 데이터 모두가능하다.
- 회귀와 분류 모두 가능하다.
단점 - 새로운 sample이 들어오면 속수무책이다.
- 학습정확도를 높이기 위해서는 더 복잡하게 만들어야 하는데 그러다 보면 과적합(Overfitting)에 걸리기 매우 쉽다.
따라서 결정트리 모델은 사전에 크기를 제한하는것이(일반화) 성능 튜닝에 도움이 된다.
결정트리의 파라미터
| 파라미터명 | 설명 |
|---|---|
| min_samples_split | 샘플이 최소한 몇개 이상이어야 split(하위(잎)노드로 분리)할것인가/클수록 과적합방지, 작을수록 정확하게 분리되어 과적합 |
| min_samples_leaf | (잎) 노드가 되려면 가지고 있어야 할 최소 샘플의 수/ 클수록 과대적합방지, 작을수록 과적합/ min_samples_split을 만족해도 min_sample_leaf을 만족하지 않으면 leaf노드가 되지 못한다. |
| max_depth | 얼마나 깊게 트리를 만들것인가/None이면 최대한 깊게(불순도가 0이 될때까지)/클수록 과적합,작을수록 과적합방지 |
| max_leaf_nodes | 최대 몇개 잎 노드가 만들어 질때 까지 split(하위(잎)노드로 분리)할것인가 |
| max_feature | 최적의 분할을 위해 고려할 최대 피처개수 |
결정트리 학습 알고리즘
- 결정트리를 학습하는 것은 노드를 어떻게 분할하는가에 대한 문제이다.
- 노드 분할 방법에 따라 다른모양의 트리구조가 만들어지게 된다.
- 결정트리의 비용함수를 정의하고 그것을 최소화 하도록 분할하는것이 트리모델의 학습알고리즘이다.
- 트리학습에 자주 쓰이는 비용함수는 지니불순도와 엔트로피 이다.
결정트리 구현
파이프라인을 사용해서 간단하게 구현해보았다. 데이터에 맞게 수정해서 사용면된다.
from sklearn.tree import DecisionTreeClassifier
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(),
DecisionTreeClassifier(random_state=42, criterion='entropy')
)
pipe.fit(X_train, y_train)
print('훈련 정확도: ', pipe.score(X_train, y_train))
print('검증 정확도: ', pipe.score(X_val, y_val))
>>>훈련 정확도: 0.9908667674880646
>>>검증 정확도: 0.7572055509429486결정트리 평가지표
결정트리를 평가하는 지표는 f1 score를 통해 이루어집니다.
f1-score에 대한 자세한 내용은 주말에 다루어 보겠다.
그렇다면 평가를 하기 위한 코드를 먼저 본다.
from sklearn.metrics import f1_score
predict = pipe.predict(X_val)
f1=f1_score(y_val, predict)
print("F1 score: {}" .format(f1))sklearn의 metrics에서 f1-score를 가져온후 score를 측정하게 되면 답이 나온다.
내가 쓴 모델에서는 0.54676...이 나왔다.
이전에 훈련정확도와 검증정확도는 높게 나왔지만 f1-score가 낮게 나온것으로 봐 다른모델을 사용을 해서 향상시키던가 아니면 전처리와 하이퍼파라미터를 수정하여 올려야 할것같다.
특성중요도 시각화
선형모델에서는 특성과 타겟의 관계를 확인하기 위해 회귀계수(coefficeients)를 확인했다. 하지만 결정트리에서는 대신 특성중요도를 확인할 수 있다. 회귀계수와 달리 특성중요도는 항상 양수값을 가진다. 이 값을 통해 특성이 얼마나 일찍 그리고 자주 분기에 사용되는지를 결정한다.
import matplotlib.pyplot as plt
model_dt = pipe.named_steps['decisiontreeclassifier']
importances = pd.Series(model_dt.feature_importances_, encoded_columns)
plt.figure(figsize=(10,30))
importances.sort_values().plot.barh();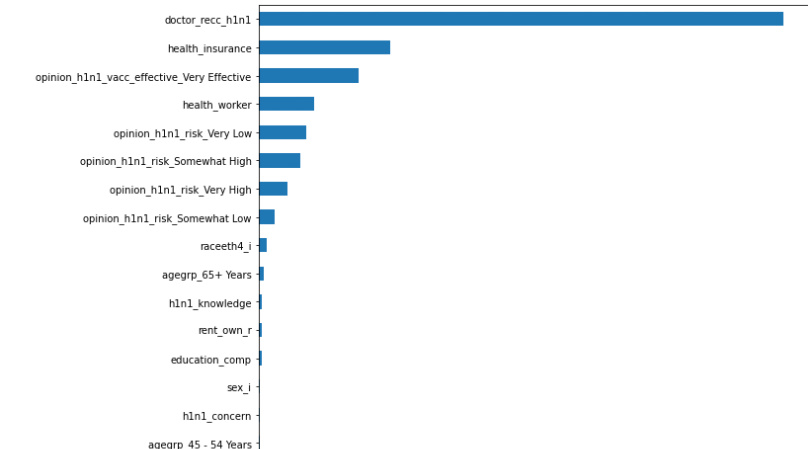
이런식으로 결과가 출력이 된다. 이것을 통해 어떤 특성이 결정트리에서 중요한지 알 수 있다.
