앙상블(Ensemble)
- 앙상블(Ensembl)이란 한 종류의 데이터로 여러 머신러닝 학습모델(week base learner,기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법을 말한다.
- 이론적으로 기본모델 몇가지 조건을 충족하는 여러 종류의 모델을 사용할 수 있다.
- 예를 들어 앙상블 기법중 하나인 랜덤포레스트는 결정트리를 기본모델로 사용하는 앙상블 방법이라고 할 수 있다.
앙상블 학습(Ensemble Learning)
- 앙상블 학습을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로서 더 정확한 최종예측을 도출 하는 기법이다.
- 에디슨이 전구를 발명할때 수천번의 실수를 겪었다고 한다. 하지만 여러명의 에디슨과 같은 과학자들이 함께 구성되어 다양한 의견을 수렴하고 결정하듯이 앙상블의 학습목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기 보다 신뢰성 높은 예측값을 얻는것이다.
앙상블 학습 유형
앙상블 학습의 유형은 전통적으로 보팅(voting), 배깅(Bagging), 부스팅(Boosting)의 세 가지로 나눌 수 있으며, 이외에도 스태깅을 포함한 다양한 앙상블의 방법들이 있다. 먼저, 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 경정하는 방식이다. 보팅과 배깅의 차이 점은 보팅의 경우 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합하는것이다.(예를 들어 Linear Regression, Support Vector Machin, Decision Tree이런식으로) 하지만 배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘을 기반으로 구성되어 있지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행하는 것이다. 배깅의 대표적인 방식이 랜덤 포레스트이다.
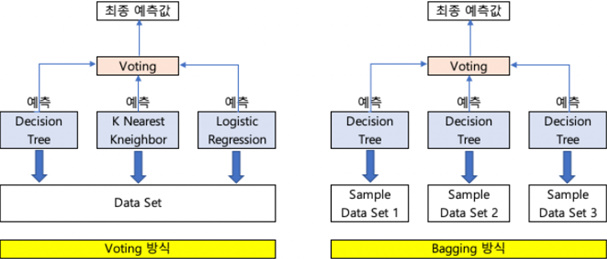
(사진출처:https://eunsour.tistory.com/58)
왼쪽이 보팅(voting) 분류기를 도식화 한것이며 3가지의 ML알고리즘을 통해 같은 데이터 세트를 학습하고 예측한 결과를 voting(투표)를 통해 최종 예측결과를 선정하는 방식이다.
오른쪽은 배깅(bagging)분류를 도식화 한 것이다. 단일 ML알고리즘으로 여러 분류기가 학습으로 개별 예측을하는데, 학습하는 데이터 세트가 보팅과 다른 방식이다. 부트스트래핑(Bootstrapping)분할 방식으로 샘플을 추출하게 되는데 이것은 각 classifer에게 데이터를 샘플링 해서 추출하는 방식이다. 이렇게 개별 분류기가 부트스트래핑 방식으로 샘플링된 데이터를 학습하여 개별적인 예측을 하고 보팅을(투표)를 통해 최종 예측결과를 선정하는데 이것이 배깅 앙상블 방식이다.
이때 교차검증의 경우 데이터 세트의 중첩을 허용하지 않지만 배깅방식은 중첩을 허용한다. 이렇게 중첩을 허용하면서 sample을 추출하는것을 '복원추출' 이라고 부른다. 따라서 10000개의 데이터를 10개의 분류기가 배깅으로 나누더라도 각 1000개의 데이터는 중복되지 않는다.
부트스트랩 샘플링 사진
 원본 데이터에서 샘플링을 하는데 복원추출을 한다는 것이다. 복원추출은 샘플을 뽑아 값을 기록한 후 제자리에 돌려놓는 것이다. 이렇게 샘플링을 특정한 수 만큼 반복하면 하나의 부트스트랩세트가 완성이 된다. 복원추출의 방식이기 때문에 부트스트랩세트에는 같은 샘플이 반복될 수 있다.
원본 데이터에서 샘플링을 하는데 복원추출을 한다는 것이다. 복원추출은 샘플을 뽑아 값을 기록한 후 제자리에 돌려놓는 것이다. 이렇게 샘플링을 특정한 수 만큼 반복하면 하나의 부트스트랩세트가 완성이 된다. 복원추출의 방식이기 때문에 부트스트랩세트에는 같은 샘플이 반복될 수 있다.
- 부트스트랩세트의 크기가 n이라 할 때 한 번의 추출과정에서 어떤 한 샘플이 추출 되지 않을 확률은 다음과 같습니다.
n회 복원추출을 진행했을 때 그 샘플이 추출되지 않았을 확률은 다음과 같습니다.
n을 무한히 크게 했을 때 이 식은 다음과 같습니다.
참고:
즉, 데이터가 충분히 크다고 가정했을 때 한 부트스트랩세트는 표본의 63.2%에 해당하는 샘플을 가진다 여기서 추출되지 않는 36.8%의 샘플이 Out-Of-Bag샘플이며 이것을 사용해 모델을 검증할 수 있다.
부스팅
은 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린데이터에 대해서는 올바르게 예측할 수 있도록 다음분류기에 가중치(weight)를 부여하면서 학습과 예측을 진행하는것이다. 이러한 방법은 예측 성능이 뛰어난 앙상블 학습을 주도하고 있다.
스태킹
은 여러 가지 다른 모델의 예측 결과값을 다시 학습데이터로 만들어 다른모델로 다시 학습시켜 결과를 예측하는 방식이다.
중간요약
여기까지 요약하면, 앙상블 방법에는 보팅과 배깅, 부스팅이 있는데 보팅은 Dataset에서 각각의 다른 분류기(classifier)에 넣어 투표를 통해 최종 결과를 결정하는 방식이며, 배깅은 Dataset을 부트스트래핑 분할방식으로 복원추출을 하여 sample을 나누고 이를 같은 모델의 여러 분류기에 넣어 투표를 통해 최종결과를 결정하는 방식이다.이때, sample은 중첩을 허용한다, 부스팅은 여러개의 분류기가 순차적으로 학습을 하되 먼저 학습한 분류기가 예측이 틀린다면 올바르게 예측할 수 있게 하기위해 다음 분류기에 가중치를 부여하면서 학습과 예측을 하는 방법이다. 마지막으로 스태킹은 여러가지 모델의 예측결과값을 다시학습데이터로 만들어 다른 모델로 재학습 시켜 결과를 예측하는 것이다.
보팅유형 - 하드보팅(Gard voting)과 소프트 보팅(Soft voting)
보팅을 하는 방법에는 두 가지가 있다.하나는 하드보팅 다른하나는 소프트 보팅이라고 하는데,
- 하드보팅은 다수결의 원칙과 비슷하다고 볼 수 있다. 예측한 결과값들중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정한다.
- 소프트보팅은 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 확률이 가장 높은 레이블 값을 최종 결과값으로 선정하는 방식이다.
(일반적으로 소프트 보팅이 예측 성능이 더 좋아 많이 사용한다.)
