📈 앤스컴 콰르텟
기술통계에서는 많은 대표값들이 존재한다. 하지만, 이 대표값으로만 의미를 뽑아내려다 보면 전체적인 그림을 보지 못할 수 있습니다. 이를 설명하는데 대표적인 것이 앤스컴 콰르텟 입니다.
앤스컴 콰르텟이란 통계학자가 발견한 네 개의 데이터셋을 뜻한다.
실제로 코렙으로 만들어 보았다.
# 데이터 불러오기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = sns.load_dataset('anscombe')
data1 = df[df['dataset']=='I']
data2 = df[df['dataset']=='II']
data3 = df[df['dataset']=='III']
data4 = df[df['dataset']=='IV']
print(data1.describe())
print(data2.describe())
print(data3.describe())
print(data4.describe())>>> 출력
x y
count 11.000000 11.000000
mean 9.000000 7.500909
std 3.316625 2.031568
min 4.000000 4.260000
25% 6.500000 6.315000
50% 9.000000 7.580000
75% 11.500000 8.570000
max 14.000000 10.840000
x y
count 11.000000 11.000000
mean 9.000000 7.500909
std 3.316625 2.031657
min 4.000000 3.100000
25% 6.500000 6.695000
50% 9.000000 8.140000
75% 11.500000 8.950000
max 14.000000 9.260000
x y
count 11.000000 11.000000
mean 9.000000 7.500000
std 3.316625 2.030424
min 4.000000 5.390000
25% 6.500000 6.250000
50% 9.000000 7.110000
75% 11.500000 7.980000
max 14.000000 12.740000
x y
count 11.000000 11.000000
mean 9.000000 7.500909
std 3.316625 2.030579
min 8.000000 5.250000
25% 8.000000 6.170000
50% 8.000000 7.040000
75% 8.000000 8.190000
max 19.000000 12.500000출력된 정보를 보았을때는 4개의 데이터 셋이 모두 비슷해보인데 하지만 이를 regplot으로 시각화 해보겠다.
# 시간이 없어 지저분하지만 하나하나 만들었다.
fig, ax =plt.subplots(2,2,figsize =(12,6))
sns.regplot(
data=data1,
x='x',
y='y',
ax = ax[0,0]
)
sns.regplot(
data=data2,
x='x',
y='y',
ax = ax[0,1]
)
sns.regplot(
data=data3,
x='x',
y='y',
ax = ax[1,0]
)
sns.regplot(
data=data4,
x='x',
y='y',
ax = ax[1,1]
)
plt.show()
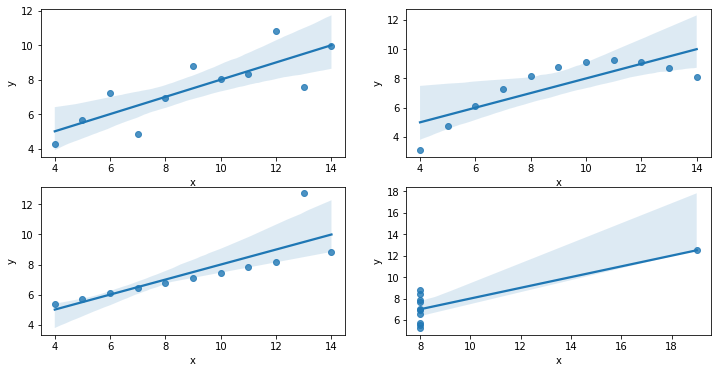
출력 결과는 위의 그림과 같다.
보는것처럼 4개가 전부 다르다는것을 알 수 있다. 충격적인 결과이다.
이를 보고 대표값에 맹신하여 과도한 집착은 오히려 함정에 빠질 수 있다는 교훈을 남겨주었다.

문제를해결하는도구로서의"데이터"