랜덤 포레스트 개요
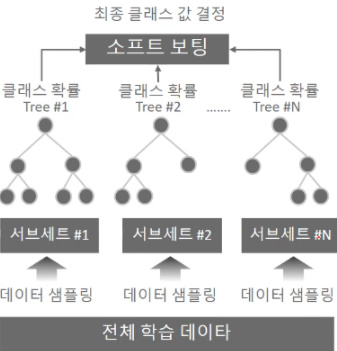
- 랜덤 포레스트는 결정 트리 기반의 알고리즘으로, 결정트리의 장점인 쉽고 직관적인 것을 그대로 가지고 왔습니다. 랜덤 포레스트는 여러 개의 결정 트리 분류기(classifier)가 전체 데이터에서 배깅(bagging)방식으로 각자의 데이터를 샘플링(sampling)해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅(voting)을 통해 예측결정을 하게 된다.
(이미지 출처: https://velog.io/@kjpark4321/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%99%84%EB%B2%BD%EA%B0%80%EC%9D%B4%EB%93%9C-%EB%B6%84%EB%A5%98-3)
- 랜덤 포레스트에서 개별 트리가 학습하는 데이터 세트는 일부가 중첩되게 샘플링(sampling)된 데이터 세트이다. 이렇게 여러 개의 데이터 세트를 중첩되게 분리하는 것을 부트스트래핑(bootstrapping)분할 방식이라 부른다. 그래서 배깅을 "bootstrap aggregating"의 줄임말입니다.

위의 그림은 Original Dataset에서 n_estimators = 3이라는 하이퍼 파라미터를 지정해주어 3개의 결정트리를 기반으로 학습하는 모습이다.
이렇듯 중첩이 된 개별 데이터 세트에 각 결정트리 분류기(classifier)를 적용하는 것이 랜덤 포레스트 이다.
랜덤 포레스트 실습
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from category_encoders import OrdinalEncoder
# 파이프라인 생성및 적용
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy = 'mean'),
RandomForestClassifier(n_estimators = 500, max_depth = 18,
min_samples_split =6, min_samples_leaf =4,
class_weight ='balanced' ,n_jobs=-1,
random_state=2, oob_score=True)
)
pipe.fit(X_train, y_train)
print('학습세트 정확도', pipe.score(X_train, y_train))
print('검정세트 정확도', pipe.score(X_val, y_val))>>> 학습세트 정확도 0.8821872312664947
>>>검정세트 정확도 0.8120033210769778위는 하나의 예시데이터로 랜덤포레스트를 실습해 본 코드입니다.
pipe라인으로 인코딩과 simpleimputer를 넣어두었으며 랜덤포레스트의 파라미터값을 임의로 조정을 해 주었습니다.
그리고 pipe를 X_train과 y_train으로 학습시킨 후
검증세트와 비교해본 결과 약간의 오버피팅이 있는것을 확인 할 수 있습니다.
이때는 랜덤포레스트의 하이퍼파라미터 값을 조정하여 오버피팅이 일어나지 않는 최적의 하이퍼파라미터값을 찾아서 넣어주어야 합니다. 이렇게 최적의 하이퍼파라미터 값을 찾아 오버피팅과 과소적합이 일어나지 않는 모델이 좋은 모델이라고 할 수 있습니다.
그리고 정확도(accuracy)가 아닌 f1-score로 확인해 볼 수 있습니다.
from sklearn.metrics import f1_score
y_val_pred = pipe.predict(X_val)
f1 = f1_score(y_val, y_val_pred)
print(f1)
>>>0.6313096068853221이렇게 f1_score를 불러와서 검증세트의 f1-score를 확인할 수 있으며 추가로 test데이터의 f1_score와 비교를 해본 후 모델을 다시 학습시키고, 하이퍼파라미터를 조정할지, 아니면 모델그대로를 사용할지 정하면 된다.
마지막 과정을 아래 코드로 간단하게 남기면 이렇다.
# 테스트셋의 label예측값
y_predict = pipe.predict(X_test)
# submission파일 불러오기
submission =pd.read_csv('/content/submission.csv')
# 예측값으로 제출파일 데이터 변경해 주기
submission['label의 컬럼명'] = y_predict
# 제출 파일 저장
submission.to_csv('submission.csv',index = False) #index제외 이런식으로 해서 나온 csv파일을 각종대회(데이콘, 캐글)등에 제출하면 된다.
랜덤 포레스트 하이퍼 파라미터 튜닝
트리 기반의 앙상블 알고리즘의 단점은 하이퍼파라미터가 너무 많다는 점이다...
그로 인해 튜닝을 위해서 많은 시간이 걸리게 된다.
만약 이렇게 많은 시간을 소비했을때 예측 성능이 크게 향상이 된다면 그 수고를 덜 만큼의 충분한 시도가
될 수 있지만 튜닝 후 예측성능이 크게 향상되는 경우가 많지 않아서 아쉬움을 가지고 있다.
| 이름 | 내용 |
|---|---|
| n_estimators | 랜덤 포레스트에서 결정 트리의 개수를 지정한다. 디폴트는 10개이며 많이 설정할 수록 좋은 성능을 기대할 수 있지만, 계속 증가시킨다고 무조건 향상되는것은 아니다 , 또한 증가에 따른 학습 수행시간 역시 오래걸리게 됨을 감안해야한다.(적을경우 과소적합) |
| max_features | 결정트리에 사용되는 max_features와 같은것이다. 현재 모델에서는 디폴트 값이 'auto'이다. 즉, 'sqrt'와 같다.(피쳐가 16개라면 4개 참조/ 줄일 수록 다양한 트리 생성) |
| max_depth | 노드의 깊이이다. 너무깊어지게 되면 과적합이 일어난다. |
| class_weight | 불균형(imbalanced)클래스인 경우 사용 |
| min_samples_leaf | 결정트리와 같다(과적합일 경우 높이면 된다 |
이후 이러한 복잡한 파라미터들을 최적의 파라미터로 찾고 교차검증 까지 해주는 방법들에 대해 정리해서 다루어 보겠다.
