데이터 셋을 분리하는 이유
우리가 관심을 가지고 있는것은 모델 학습에 사용했던 훈련(train)데이터를 잘 맞추는 모델이 아니라, 학습에 사용하지 않은 테스트(test)데이터를 얼마나 잘 맞추는지 이다.
train데이터는 우리가 학습을 할때 사용할 데이터 이며,
test데이터는 우리가 학습한 모델의 성능을 테스트하는 데이터 이다.
고등학교 3학년 학생을 예로 들어보자.
수능을 잘치는것이 목표이다 즉, 우리는 모의고사라는 학습을 통해 모델을 만들어주고 수능(test데이터)을 통해서 모의고사를 풀면서 만든 모델의 성능을 확인하는 것이다.
따라서 우리는 모의고사(train) 데이터를 통해 모델을 업그레이드 시켜야한다.
이때 중요한 분리 개념이 하나더 생긴다.
우리는 수능을 단 한번밖에 치지 못한다. 따라서 수능을 쳐서 모델이 만족이 되지 않을 수 있다.
그래서 우리는 validation데이터 즉, 검증데이터가 필요하다.
3월, 6월, 9월 모평을 치고 10월에 현재까지 본 모의고사를 통해 만들어진 모델을 검증하기위해 혼자서 모의수능을 연습한다고 보면된다.
모의수능을 봤는데 만족이 되지않는다면 다시 연습을 통해서 실력을(모델을)업그레이드 해서 또 모의수능을 보면서 만족해졌을때 수능을 마지막으로 딱 한번 보는것이다!!
사진으로 쉽게 요약해 보겠다.
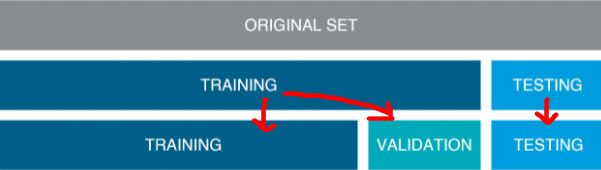
(사진출처: https://modern-manual.tistory.com/19)
1 단계 : training과 test데이터로 분리한다.
2 단계 : training데이터를 training과 validation으로 분리한다.
3 단계 : training데이터로 모델을 만들고 validation데이터로 검증한다. 만족시 해당모델을 train과 validation데이터를 합쳐서 학습을 시킨후 test데이터를 넣어 확인한다.
검증데이터가 필요한 이유
우리가 train을 한번학습으로 완전하게 모델을 학습시키기 어렵기때문에 다르게 튜닝된 여러 모델들을 학습한 후 어떤모델이 잘 학습되었는지 검증셋으로 검증하고 모델을 선택하는 과정이 필요하다. 이렇게 훈련/검증세트로 좋은 모델을 만들어 낸 후 최종적으로 테스트세트에는 단 한번의 예측테스트를 진행한다. 결과가 마음에 들지 않아도 또 수정하게되면 테스트 세트에 과적합되어 일반화의 성능이 떨어지게 된다.
요약하면, 훈련데이터는 모델을 Fit하는데 사용하며, 검증데이터트 예측 모델을 선택하기 위해 모델의 예측오류를 측정할 때 사용한다. 테스터데이터는 일반화 오류를 평가하기 위해 마지막에 단 한번만 사용해야한다. 이때 테스트 데이터는 한번도 공개된적 없는 데이터 이어야한다.
모델 검증
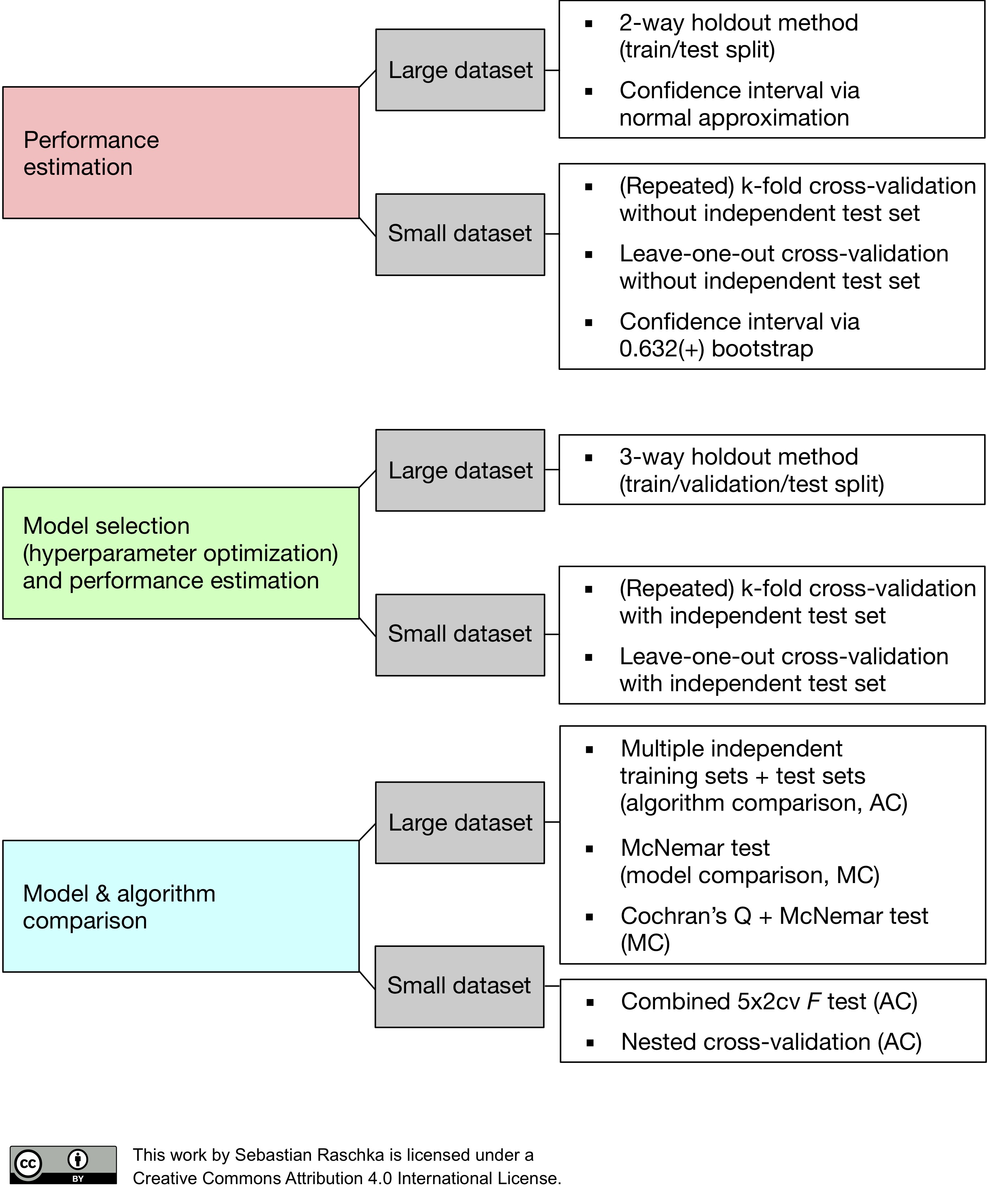
모델을 개발할때 어떤 모델을 쓸지 모델선택(Model selection)을 수행해야한다. 이때 하이퍼파라미터(hyperparameter)역시 튜닝하게 되는데 검증세트로 진행해야한다. 위의 사진처럼 상대적으로 데이터가 적을경우 K-fold교차검증(k-fold cross-validation)을 진행할 수 있다. 물론 이방법을 사용할때도 테스트 데이터는 분리되어 있어야한다.
from sklearn.model_selection import train_test_split
# train-test분리
X_train, X_test, y_train, y_test = train_test_split(df['feature'],df['target'])
# train-validation분리
X2_train, X2_val, y2_train, y_val = train_test_split(X_train, y_train)파라미터
- test_size = 테스트 셋 구성의 비율을 나타냅니다. train_size의 옵션과 반대 관계에 있는 옵션 값이며, 주로 test_size를 지정해 줍니다. default값은 0.25이다.
- shuffle : split을 해주기 이전에 섞을것인가 의 여부이다. 보통은 default값으로 나둔다. default = True
- stratify : classification을 다룰때에는 매우 중요한 옵션값이다. sratify 값을 target으로 지정해주면 각각의 class비율(ratio)을 train/validation에 유지해 준다. (한쪽에 쏠려 분배되는것을 방지해 준다.)
- random_state: 세트를 섞을때 해당 int값을 보고 섞으며, 하이퍼 파라미터를 튜닝시 이 값을 고정해두고 튜닝해야 매번 데이터셋이 변경되는 것을 방지할 수 있다.
(출처 : https://teddylee777.github.io/scikit-learn/train-test-split)
