PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
ICPR 2020
https://arxiv.org/abs/2011.08785
Abstract
- Patch Distribution Modeling을 위한 새로운 프레임워크 제안
- one-class learning setting으로 anomaly detection&localization 수행 (industrial inspection context)
- PaDiM은 patch embedding을 얻기 위해 pretrained CNN 사용
- normal class에 대한 probabilistic representation을 얻기 위해 multivariate Gaussian distribution 사용
- anomaly를 localizae하는 데 있어 CNN의 다른 semantic level 간 correlation을 활용하는 게 좋다는 것 보여줌
- 데이터셋으로는 MVTec AD, STC 사용
1. Introduction
- 일반적으로, CV에서 Anomaly detection은 anomaly score를 부여하는 것으로 이뤄짐
- Anomaly localization은 각 픽셀마다, 혹은 각 픽셀의 패치마다 anomaly score를 부여해 anomaly map을 output으로 함
Examples of anomaly maps (MVTec AD)

- left: normal image
- middle: abnormal image
- ground truth는 노란색
- right: anomaly heatmap (PaDiM 모델 통해 얻어진 것)
- 노란 색이 detected anomalies, 파란 색이 normality zones
- Anomalous example의 부족, 분포의 다양성 등의 문제로 인해 anomaly detection model들은 대부분 one-class learning setting을 기반으로 함
- training dataset은 normal class로부터의 데이터로만 구성되어있음.
- 기존 연구들에서는 딥러닝을 사용하거나, K-nearest-neighbor algorithm(K-NN)을 사용해 test time에 전체 training dataset을 필요로 했음
- KNN을 사용할 경우, training dataset의 size가 커질 수록 시간 및 공간 복잡도가 선형적으로 증가하는 문제 존재 (scalability issue)
- 위 문제를 완화한 게 본 논문에서 제시한 방법!
- KNN을 사용할 경우, training dataset의 size가 커질 수록 시간 및 공간 복잡도가 선형적으로 증가하는 문제 존재 (scalability issue)
PaDiM 설명
- Patch Distribution Modeling을 위한 모델
- embedding extraction을 위해 pretrained CNN 사용
PaDiM의 두 가지 특성
- 1) 각 patch position은 multivariate Gaussian distribution으로 구해짐
- 2) PaDiM은 pretrained CNN에서의 다른 두 semantic level의 correlation을 중요하게 봄
- 본 접근 방법으로 anomaly localization&detection task에 있어 MVTec AD와 ShanghaiTechCampus(STC) 데이터셋에 대해 SOTA 달성
- training 데이터셋 사이즈에 상관 없이 test time에 낮은 시간 및 공간복잡도 달성
2. Related Work
Anomaly detection & localization method는 reconstruction based와 embedding similarity-based method의 두 가지 방향으로 나눌 수 있음
Reconstruction-based methods
- AE(Autoencoder)
- VAE(Variational autoencoder)
- GAN(Generative adversarial network)
위 모델들은 normal training image만을 reconstruct하도록 훈련됨
-
anomaly map은 latent space로부터 생성된 visual attention map으로 대체 가능
-
reconstruction based method들은 직관적이며, 해석하기 편하다는 장점이 있지만 종종 anomalous image들에 대해서도 reconstruction을 잘해낸다는 문제 존재
Embedding similarity-based methods
- 전체 이미지 혹은 패치에 대한 의미있는 feature vector를 추출하기 위해 딥러닝 사용
- Anomaly detection 분야에 있어서는 잘 작동하지만, 특정 이미지 내에서 high anomaly score를 갖는 anomalous한 부분이 어딘지 해석해내기 어렵다는 단점 존재
- normality를 나타내는 reference vector와 test image의 embedding vecotr 사이의 distance가 anomaly score가 됨
- SPADE에서 해당 방안 채택
- 앞서 언급됐듯, KNN alogirhtm 쓰기 때문에 시간/공간복잡도에 대한 문제 발생 (inference complexity 증가)
PaDiM
- anomaly localization 위해 patch embedding 생성
- normal class는 Gaussian distribution의 집합으로 묘사됨
- 이때, Gaussian distribution은 pretrained CNN에서의 semantic level 간 correlation도 나타냄
- pretrained 네트워크 구조로 ResNet, Wide-ResNet, EfficientNet 사용
- 이때, Gaussian distribution은 pretrained CNN에서의 semantic level 간 correlation도 나타냄
- train set 규모에 상관 없이 시간 복잡도 작음
3. Patch Distribution Modeling
A. Embedding extraction
- PaDiM에서의 patch embedding 과정은 SPADE에서의 과정과 유사함
Patch Embedding process
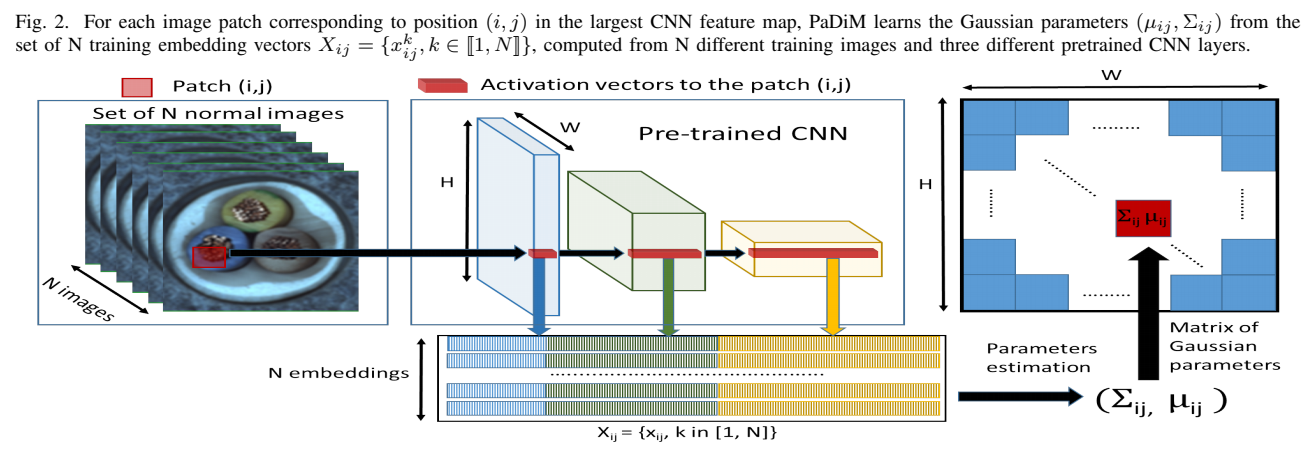
i,j번쨰 패치가 맨 왼쪽 이미지에서의 빨간 박스에 해당하는 부분이라 할 때, featuremap 상에서 해당 위치에 대응하는 부분들이 가운데 이미지에서의 빨간 벡터 형태로 나타나 있음.
- PaDiM은 N개의 normaml image(training image) 집합 상에서의 i,j번째 인덱스의 패치들 각각에 해당하는 CNN 3개 layer부터로의 embedding들에서 Gaussian parameter들을 학습함
-
pretrained CNN에서의 activation map에서 embedding vector를 추출해냄으로써 다른 semantic level과 resolution 상에서의 정보를 가져올 수 있음
-
이미지는 상의 그리드로 나눠질 수 있는데, 이떄 는 embedding을 만드는 데 사용되는 가장 큰 activation map에서의 해상도여야 함
-
이때, 생성된 patch embedding vecotr는 중복되는 정보를 가질 수 있기에, size를 줄이는 것에 대한 필요성에 대한 연구도 진행함 (5.Results 부분 참고)
- PCA(Principal Component Analysis)를 사용해 랜덤하게 몇 개의 차원을 선택하는 게 효율적인 방안이라는 것을 알아냄
- 몇 개의 차원만을 선택함으로써 training/test phase 모두에서 모델 complexity 감소시킴
-
test image에서의 patch embedding vecotr들은 anomaly map을 생성하는 데 사용됨
B. Learning of the normality
training dataset(normal image들) 상에서fig2에 묘사된 과정으로부터 얻어진 는 multivariate Gaussian Distribution 으로부터 생성되었다고 가정할 수 있음
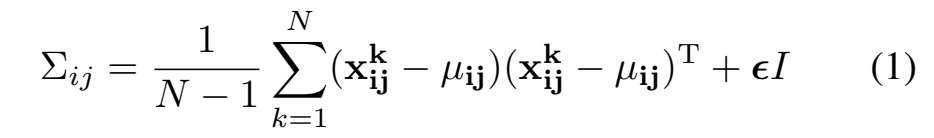
regularisation term 는 sample matrix 가 full rank며, invertible하도록 함
- patch embedding이 다른 semantic level에서의 정보를 포함하기 때문에 그로부터 생성되는 또한 다른 레벨에서의 정보를 포함한다 볼 수 있음
- Results 파트에 더 자세한 내용 있음
C. Inference : computation of the anomaly map
- patch 에 대한 anomaly score를 부여하기 위해 Mahalanobis distance 사용
- test patch embedding 와 학습된 distribution 사이의 distance로 해석될 수 있음
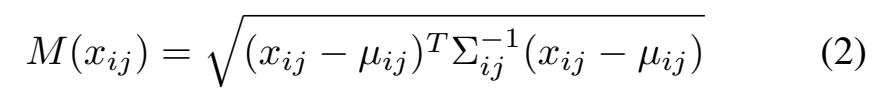
- test patch embedding 와 학습된 distribution 사이의 distance로 해석될 수 있음
- Mahalanobis distance matrix 는 anomaly map을 형성할 수 있음
- 해당 맵에서 M distance가 anomalous score를 나타내는 것
- M distance의 최대값이 해당 이미지에 대한 최종 anomaly score가 됨
4. Experiments
A. Datasets and metrics
Metrics
localization performance를 측정하기 위해 두 개의 독립적인 metric에 대한 threshold 지정
- AUROC(Area Under the Receiver Operating Characteristic curve)
- true positive rate는 anomalous로 잘 분류된 pixel들의 비율. 즉 abnormal인데 abnormal로 잘 분류된 경우
- AUROC는 large anomaly에 대해 편향을 갖기 때문에(비정상 샘플이 많은 경우, 높은 수치가 나옴), PRO-score(per-region-overlap score)도 사용함
- PRO-score는 크고 작은 anomaly들이 잘 localize되었는가를 나타내는 척도
Datasets
MVTec AD
- one-class learning setting 및 산업 면에서의 anomaly localization task testing을 위해 설계됨
- 15개의 class가 있으며(10개의 object class, 5개의 texture class), class 당 약 240장 정도씩의 이미지 존재
- 원본 이미지는 700x700~1024x1024 사이의 해상도를 가짐
- object class는 중앙에 잘 위치된, 방향도 거의 같게 되어있음
- random rotation(-10,+10), random crop(256x256 -> 224x224) 등을 적용한 데이터셋인 Rd-MVTec AD 데이터셋도 존재
STC (Shanghai Tech Campus Dataset)
- 정적 감시카메라 상황 가정
- 13개의 scene에 대한 총 274515개의 training frame, 총 42883개의 testing frame 존재
- 원본 해상도는 856 x 480
- training video는 normal sequence로 이뤄져있으며, test video는 싸우는 사람들이 있거나, 보행자가 있어야 할 곳에 차가 있는 등의 예시로 이뤄져있음
B. Experimental setups
-
PaDiM은 서로 다른 백본으로 학습을 시켰는데, 모두 ImageNet으로부터 pretrain된 것 사용 (ResNet18, Wide ResNet-50-2, EfficientNet-B5)
-
ResNet인 경우,
- patch embedding vecotr는 맨 처음 세 개 layer로부터 추출됨
-
EfficientNet-B5인 경우,
- patch embedding vecotr는 layers 7(level 2), 20(level4), 26(level5)로부터 추출됨
- patch embedding vecotr는 layers 7(level 2), 20(level4), 26(level5)로부터 추출됨
-
random dimensionality reduction(Rd)도 적용함. 백본 및 Rd 적용 여부에 따라 모델 이름 다르게 설정
-
1번 식에서의 값으로는 0.01 사용
-
앞서 언급되었듯이, SPADE의 방법론 사용.
- MVTec AD 이미지는 256x256으로 resize한 다음 224x224로 center crop 적용
- STC 이미지에 대해서는 256x256으로 resize만 적용
- 이미지나 localization map울 resize할 때는 bicubic interpolation 사용
- Anomaly map에는 의 값을 갖는 Gaussian filter 적용
-
reconstruction-based baseline을 위해 자체적으로 VAE 구현
- encoder로는 ResNet18 사용, 8x8의 convolutional latent variable 사용
- MVTec AD class로부터의 10000개 이미지로부터 학습됨
- (-2,+2) rotation
- 292x292 resize
- 282x282 random crop
- 마지막에 256x256 center crop 적용
- Adam optimizer를 사용해 100 epoch동안 학습시켰으며, 초기 learning rate는 0.001로 지정, batch size로는 32 사용
5. Results
A. Ablative studies
- semantic level 간 correlation의 영향
- dimensionality reduction을 통해 방법론을 간단히 할 수 있는 방안
위 두 가지에 초점을 두어 연구 진행
Inter-layer correlation
- PaDiM은 Gaussian modeling과 Mahalanobis distance를 혼합해 썼다는 점에서는 이전 연구들과 비슷하지만, CNN에서의 서로 다른 semantic level 간 corelation을 사용했다는 점에서 차이점 존재
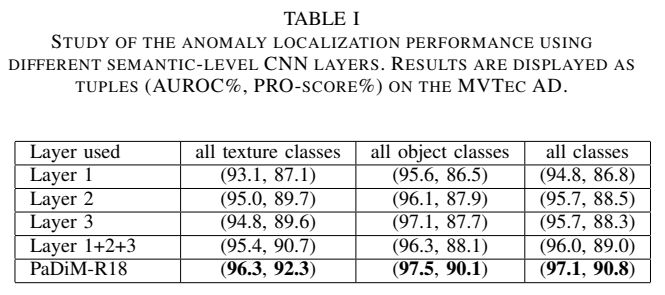
- 각각 레이어 하나씩만을 사용했을 때, 레이어 3개를 사용하되 correlation을 고려하지 않았을때, PaDiM의 방법을 썼을 때(3개 layer로부터 patch embedding 추출, correlation 고려)의 결과를 보여줌
- PaDiM의 결과가 가장 좋으므로, 서로 다른 semantic level 간 correlation을 고려하는 것의 영향 증명 가능
Dimensionality reduction
- PaDiM은 448 차원의 각 patch embedding vecotr 집합으로부터 multivariate Gaussian distribution을 예측함
- embedding vector size를 줄이면 본 모델의 computational cost 및 memory complexity를 줄일 수 있을것이라는 가정
다음과 같은 차원 축소 알고리즘들을 적용해보았음
- PCA(Principal Component Analysis)
- embedding vecotr size를 100 혹은 200으로 줄이는 데 사용
- training 이전, random feature selection(Rd) 적용
- 10개의 다른 모델들을 훈련시켜 average score 사용
- 랜덤성에도 불구하고, 서로다른 seed 상에서 average AUROC에 대한 SEM(standard error mean)이 항상 ~을 유지하는 것 확인
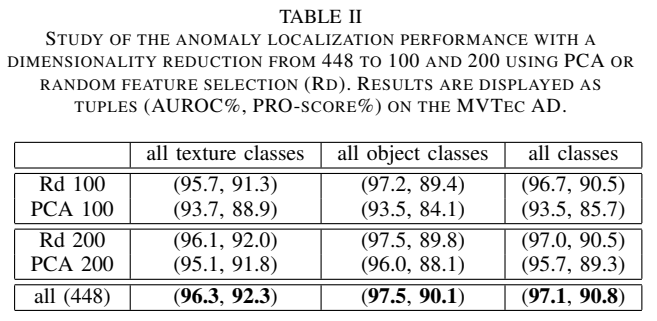
- 위 표와 같이, 차원 수가 같다는 가정 하에 PCA보다 Rd를 적용했을 때의 성능이 더 좋은 것을 알 수 있음
- PCA는 가장 높은 분산값을 갖는 축을 선택하는데, 그 축이 anomaly 한 것과 normal class를 분류해내는 데 도움이 되지 않을 수도 있어 그럴 것으로 보임
B. Comparison with the state-of-the-art
아래 표는 MVTec AD dataset에 대한 AUROC와 PRO-score를 보여줌
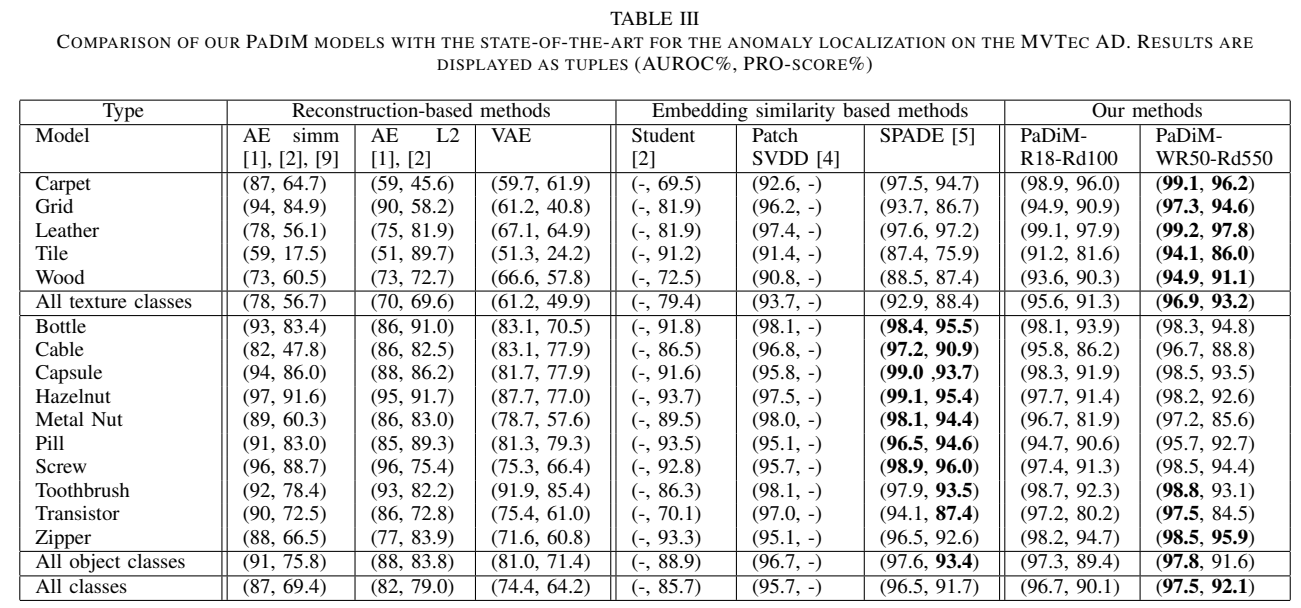
Localization
- 비교할 떄 공정성을 위해, SPADE에서의 backbone인 Wide ResNet-50-2 기준으로 비교 진행
- 더 작은 size의 backbone을 갖고 있는 모델들도 있기에, ResNet18 기준으로도 비교 진행
- WR50에 대해서는 embedding size를 550으로, R18에 대해서는 embedding size를 100으로 줄여 적용(Rd)
- PaDiM-WR50-Rd550이 모든 다른 method에 비해 가장 성능이 잘 나오는 것을 확인
- 좀 더 가벼운 모델로는 PaDiM-R18-Rd100이 성능이 잘 나옴
- PaDiM-WR50-Rd550이 object 간 성능 gap이 가장 적음
- 또한, PaDiM 모델은 특히 texture class에서 성능이 좋은 것을 알 수 있음
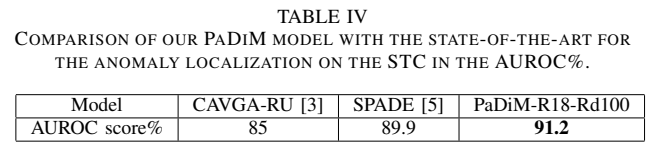
위 표는 STC 데이터셋에 대한 AUROC를 비교한 결과
Detection
본 모델에서, 이미지 당 anomaly score는 모델로부터 생성된 anomaly map으로부터 maximum score를 추출함으로써 채택됨

C. Anomaly localization on a non-aligned dataset
-
Rd-MVTec AD 데이터셋 상에서 테스팅
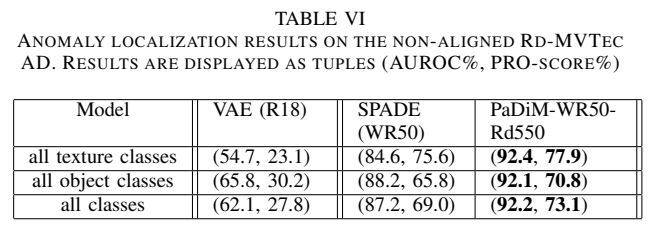
기존 MVTec 데이터셋에서의 결과와 비교를 통해 본 논문에서의 method를 사용했을 때 non-aligned image에 대해 더 강건하다는 것을 알 수 있음
D. Scalability gain
Time complexity
- PaDiM에서는 전체 training dataset을 사용해 Gaussian parameter들을 예측하기 때문에 dataset size에 따라 training time이 선형적으로 증가함
- 그러나, pretrained CNN을 사용하기 때문에 따로 deeplearning training을 필요로 하지 않음
- 그렇기 때문에 상대적으로 작은 크기의 MVTec AD 데이터셋 상에서 훈련하고 테스팅하기 쉬운 것.
자세한 사항은 논문을 참고하자!
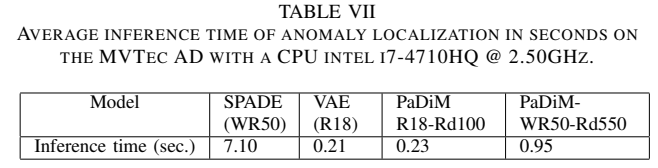
위 표는 MVTec 데이터셋 기준으로 여러 방법들에 대해 inference time을 측정한 것이다.
Memory Complexity
- SPADE와 Patch SVDD가 training dataset size에 따라 memory complexity가 영향받는 것과 달리, 본 논문에서 제시한 모델은 training datasetsize가 아닌 image resolution에 의해서만 영향을 받는다.
- PaDiM은 pretrained CNN과 각 패치와 관련된 Gaussian parameter들만 메모리에 저장함
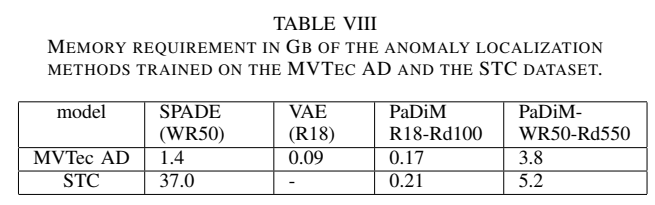
위 표는 각 모델 당 요구되는 memory를 나타냄
- inference time requirements, resource limit 혹은 예상 성능에 따라 유저가 backbone, 혹은 embedding size 등을 임의로 선택해 PaDiM을 쉽게 적용할 수 있다는 점도 본 모델의 장점!
6. Conclusion
- one-class learning 가정 상에서 distribution modeling을 기반으로 하는 anomaly detection 및 localization을 위한 프레임워크인 PaDiM 제안
- MVTec 및 STC 데이터셋에서 SOTA 달성
- evaluation protocol을 Non-aligned dataset에 대해서도 확장
- 기존 방법들에 비해, PaDiM이 realistic data에서도 강건하게 작동하는 것을 보여줌
- 메모리를 상대적으로 적게 사용할 뿐 아니라, 다양한 visual industrial control 상황에서 적용하기 쉬움
