Towards Total Recall in Industrial Anomaly Detection
CVPR 2022
https://arxiv.org/abs/2106.08265
https://ffighting.net/deep-learning-paper-review/anomaly-detection/patchcore/
[Paper Review] Towards Total Recall in Industrial Anomaly Detection
https://www.youtube.com/watch?v=mEY4qjZcNsw
위 자료들을 참고했다.
Abstract
- nominal(non-defective) image를 사용해 model을 피팅시키기 때문에 발생하는 cold-start 문제를 해결하고자 함
- Cold-start problem이란?
- 추천시스템이 충분한 정보를 갖고 있지 않아 적절히 추천을 하지 못하는 문제
- Cold-start problem이란?
- 제목에서 알 수 있다시피, Industrial Anomaly Detection 환경에서 Recall을 최대화하겠다는 것
PatchCore 요약
- 최대한 nominal patch feature를 대표하는 memory bank를 사용
- Detection&Localization task에서 SOTA이며, inference time에서도 뒤쳐지지 않음
- MVTecAD에서 AUROC 99.6% 달성
- Github주소 : https://github.com/amazon-science/patchcore-inspection
1. Introduction
- Coldstart 문제를 해결하고자 한다. 즉, 적은 양의 nominal data만 보고서도 industiral 환경에서의 anomaly detection 및 localization을 잘 수행해내겠다는 것
가능한 모든 detection를 감지하기 쉬워질 뿐 아니라, cost도 개선할 수 있을 것!
- 보통 out-of-distribution detection 문제로 anomaly detection 문제를 해결하는데, defect가 매우 미세한 차이일 수 있음
모델 적용 예시

위 그림은 MVTec AD 데이터셋에 PatchCore를 적용했을 때 결과다. 주황색 선이 anomaly contour를 의미
-
nominal distribution을 학습함으로써 anomaly detection을 하는 방법으로는 Autoencoding, GAN, Unsupervised adaptation 방법 등등이 존재
-
최근에는 target distribution에 적응하지 않고 ImageNet classification에서의 deep representation을 활용하는 방법이 제안됨
-> 이렇게 했음에도 불구하고, 성능이 좋게 나왔음!- multi scale의 deep feature representation을 활용한 test sample과 nominal sample 간의 feature matching이 키포인트!
- 미세한 defect segmentation은 high-resolution feature 상에서 이뤄지는 반면, structural deviation과 full image-level anomaly detection은 훨씬 추상적인 레벨에서의 feature 상에서 이뤄짐
- 적응적이지 않기 때문에, 더 추상적인 레벨에서의 matching confidence에 있어 한계 존재
- 즉, ImageNet으로부터의 매우 추상적인 feature는 industrial 환경에서의 input에 대한 추상적인 feature와 일치하지 않는다는 것
- 또, 기존의 방법의 testtime에서 사용할 수 있는 nominal context는 추출할 수 있는 high-level feature representation의 수가 적을 경우, 성능이 제한됨
PatchCore의 목표
- 1) test time에 사용할 수 있는 nominal information 최대화
- 2) ImageNet class에 대한 bias 줄이기
- 3) 빠른 inference 속도 유지
특정 패치만 anomaly로 구분될 경우, 바로 abnormal로 구분할 수 있다는 점에서 PatchCore는 locally하게 합쳐진 mid level feature patch들을 활용해 detection 수행
- mid level의 network patch feature를 사용함으로써, high resolution에서의 imageNet class에 대한 bias를 최소화할 수 있음
- 지역적으로 이웃한 feature를 함께 고려함으로써 충분한 spatial context를 보유하는 것 보장 가능
- 큰 메모리 뱅크 방식에서의 결과는 Patchcore가 test time에 가능한 nominal context를 효율적으로 활용할 수 있도록 함
실용성을 위해, PatchCore는 nominal feature bank를 위한 greedy coreset subsampling 제안
-> 추출된 patch level memory bank의 중복성을 줄여주는 주요 요소로서, 실제로 산업 현장에서 잘 사용될 수 있도록 storage memory와 inference time를 줄여줌
- MVTec AD, MTD(Magnetic TIle Defects) 데이터셋에서 SOTA detection score 달성
Overview of PatchCore
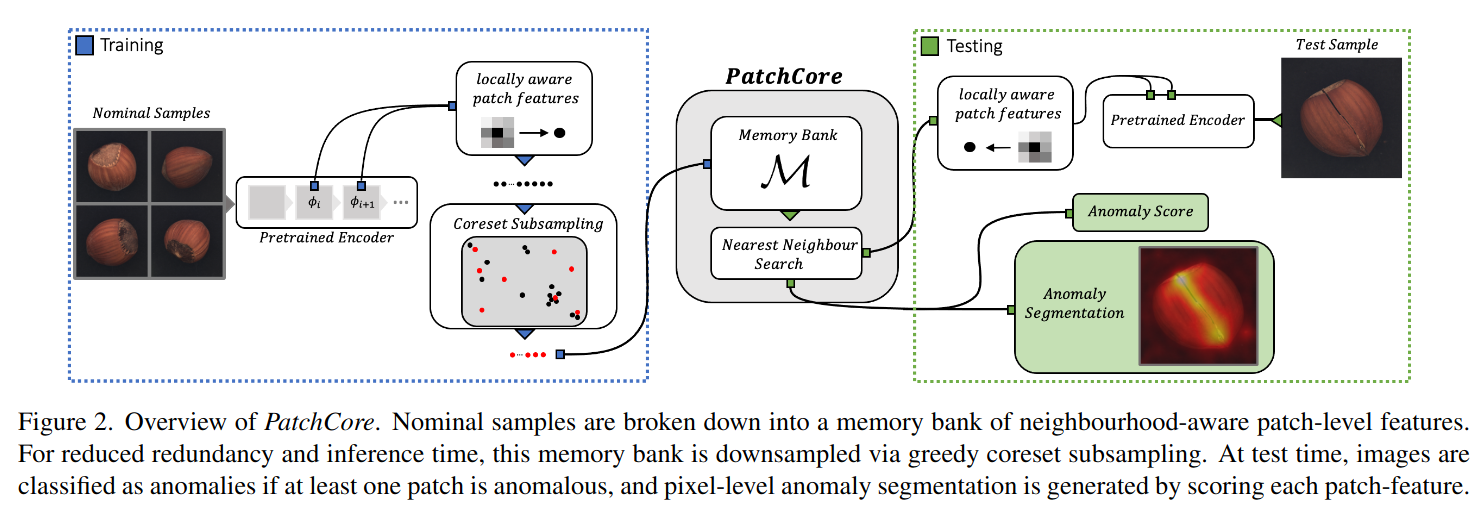
- nominal sample들은 neighbourhood-aware patch-level feature로서 memory bank 안에 포함
- inference time을 줄이기 위해 greedy coreset subsampling을 통해 memory bank를 downsampling
- test time에는 최소 한 패치가 anomalous하다고 판단될 경우, anomaly로 판단됨
- pixel-level anomaly segmentation은 각 patch feature를 scoring함으로써 생성됨
2. Related Works
Industrial Anomaly Detection
지금까지의 SOTA 모델은 특정 데이터로 학습시키는 과정 없이, ImageNet등으로 pretrain된 모델들을 사용했음
- PatchCore에 사용된 요소들은 SPADE와 PaDiM과 유사함!
SPADE
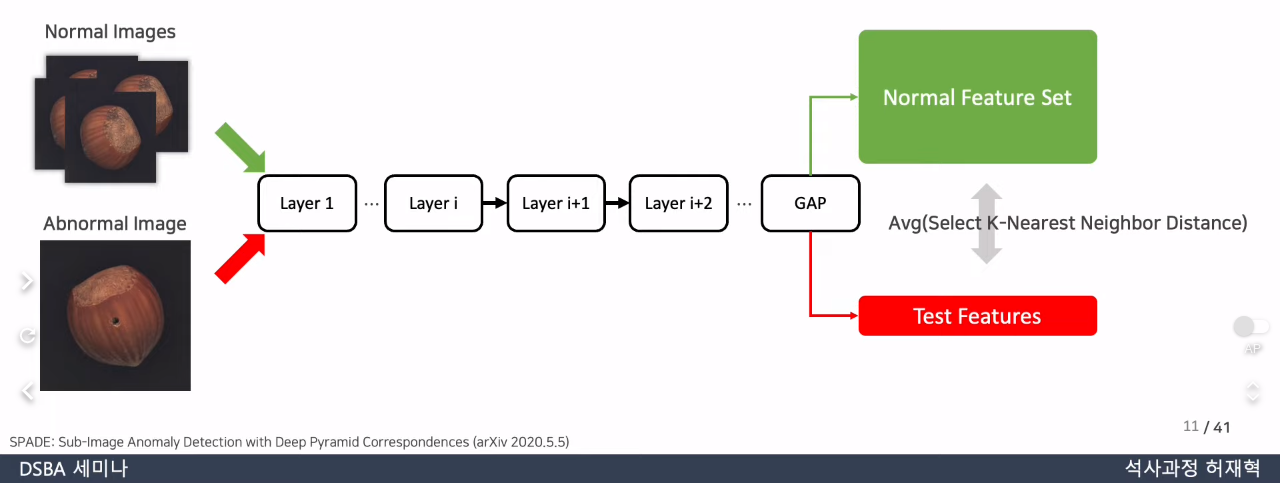
- pretrained backbone으로부터 추출된 nominal feature의 memory bank 사용
- 이때, image level anomaly detection과 pixel level anomaly detection 각각에 대해 분리된 접근 방식 사용
- 다양한 feature 계층으로 구성된 memory bank 활용해 kNN기반의 미세한 anomaly segmentation과 image level anomaly detection 수행
- PatchCore도 memory bank를 사용하지만, nominal context 정보가 많아지고 inductive bias 정보가 통합됨에따라 neighborhood-aware patch-level feature가 더 높은 성능을 얻는 데 도움이 된다는 점 활용
- 높은 성능을 유지하면서 inference cost를 줄이가 위해 memory bank는 coreset-subsample됨
- memory bank feature space를 근사화하는 것이 목적이기 때문에, PatchCore에서는 greedy coreset mechanism을 적용
- 높은 성능을 유지하면서 inference cost를 줄이가 위해 memory bank는 coreset-subsample됨
PaDiM
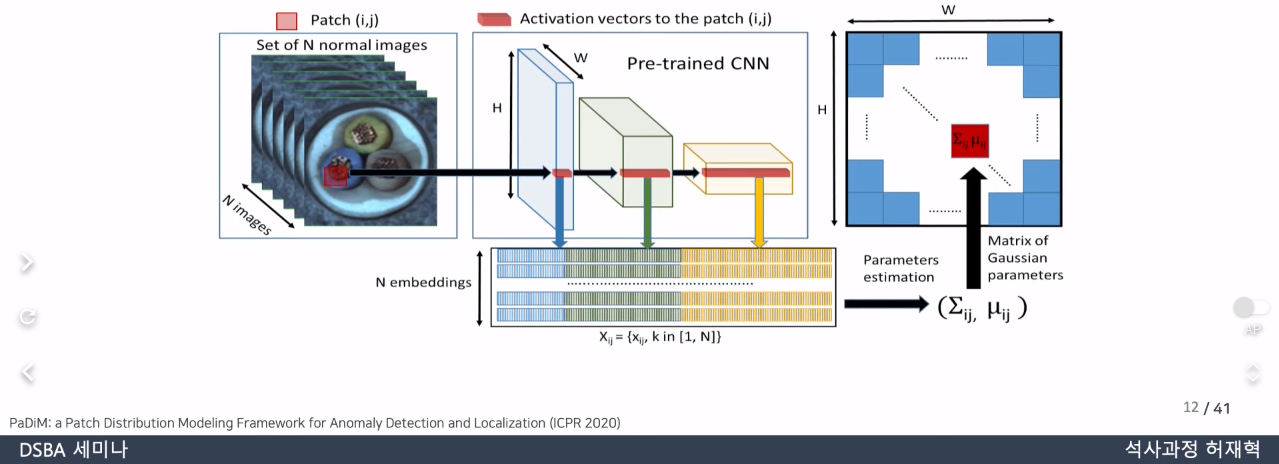
https://velog.io/@ljwljy51/PaDiM
참고!
-
locally constrained bag of features 접근 방식 사용
-
SPADE와 달리, image level anomaly detection과 pixel level anomaly segmentation 모두에서 patch-level 접근 방법 사용
- patch level Mahalanobis distance를 평가하기 위해 patch-level feature distribution(mean, covariance) 예측
-
PatchCore도 detection sensitivity를 높이기 위해 patch level approach 사용
-
PatchCore에서는 inference time에 "모든 패치" 정보에 접근할 수 있는 효율적인 patch feature memory bank를 사용
- PatchCore는 더 많은 nominal context를 고려함으로써 PaDiM보다 image alignment에 대한 의존성이 낮아짐!
- PaDiM은 "대응되는 각 패치"마다만 Mahalanobis distance를 측정함으로써 patch level anomaly detection 수행
-
PatchCore는 PaDiM과 달리, input image가 training과 testing에서 같은 사이즈를 가질 필요가 없음
-
PatchCore는 locally-aware patch-feature score로 locally spatial variance를 계산함으로써 ImageNet class에 대한 bias를 줄임
3. Method
다음과 같은 요소로 구성됨
- local patch feature들이 memory bank로 합쳐지는 것
- 효율성을 높이기 위한 coreset-reduction 방법
- detection과 localization을 하는 전체 알고리즘
3.1. Locally aware patch features
자세한 notation은 논문을 참고하자.

-
Memory bank 사용
- training 과정에서 생성된 중간 레벨즈음의 feature representation으로 구성된 patch level feature들로 이뤄짐
- ImageNet에 대한 bias 줄임!
- training 과정에서 생성된 중간 레벨즈음의 feature representation으로 구성된 patch level feature들로 이뤄짐
-
위와 같이 될 경우, 즉 local neighbourhood의 정보를 포함하지 않더라도 각 patch representation은 local spatial variance의 영향을 덜 받고 anomaly를 판단할 수 있다고 가정
- receptive field 때문! 그러나 실제로는 patch representation을 그대로 사용할 경우 주변의 정보를 충분히 못 담는다.
-
각 patch level feature representation마다 local neighbourhood 정보를 포함하도록 하면 receptive field를 늘릴 수 있고, feature map의 공간적 해상도나 활용성을 잃지 않으면서 조그만 공간적 변화에 대해 강건해질 것!
-
주변의 패치정보를 포함할 수 있도록 다음과 같이 패치를 구성할 수 있음
-
주변 패치 계산식
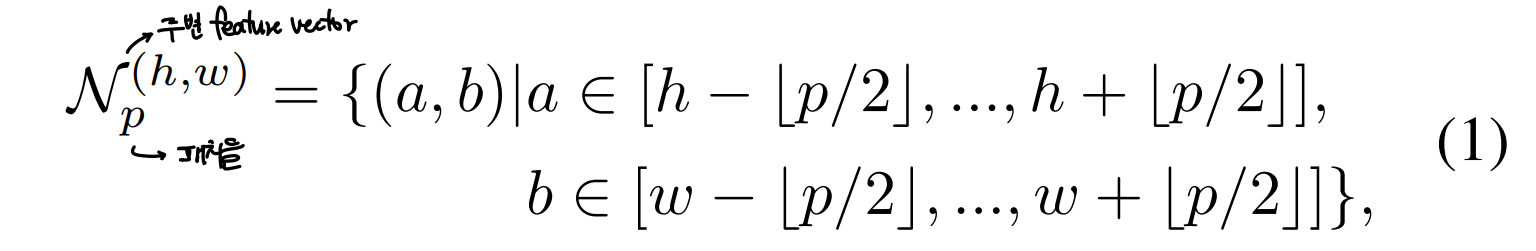
-
에서의 locally aware feature 계산식
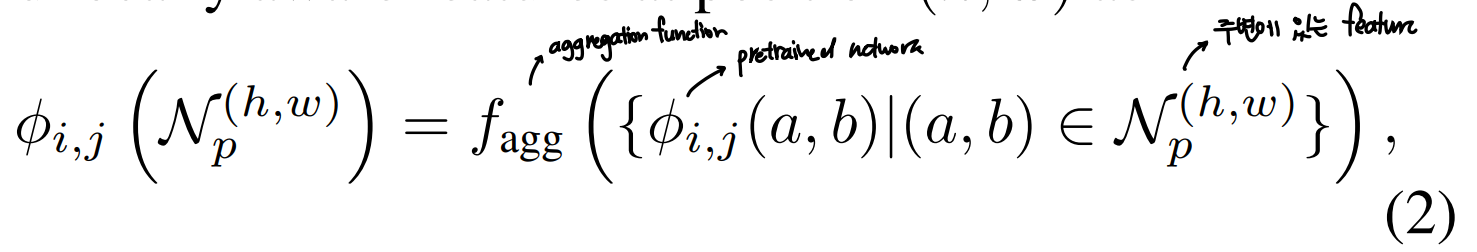
-
여기서 는 주변의 feature vector 정보를 합쳐주는 function
- PatchCore에서는 adaptive avarage pooling 사용
- 각 feature map에 대한 local smoothing의 효과가 있음
- 쌍 각각에 대해 해당 위치에 대응되는 하나의 차원의 single represenation이 결과로 나옴
- 그로 인해 feature map resolution을 유지할 수 있는 것
- locally aware patch feature collection 수식
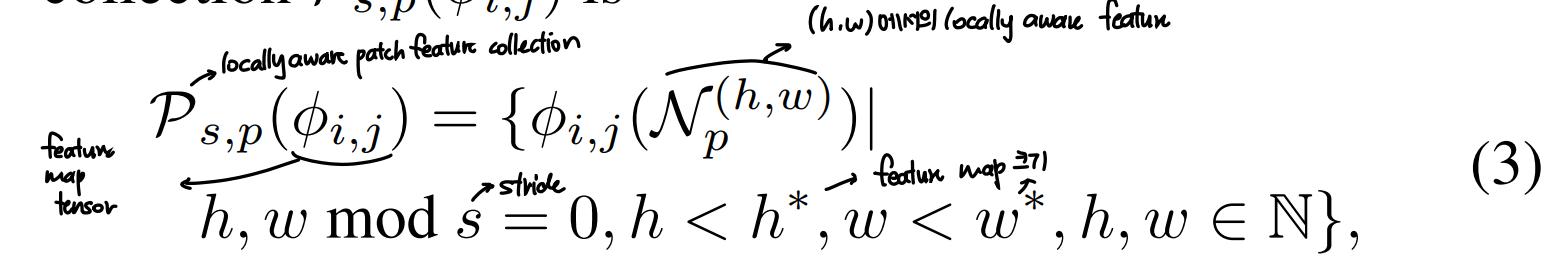
- 이때, 여러 hierarchy의 feature를 활용하는 것이 성능을 높이는 데 도움이 되는 것을 확인함
- 사용된 feature의 공간적 해상도와 generality를 유지하기 위해 PatchCore는 중간의 두 feature hierarchy j, j+1만을 사용함
- 우선, j+1 계층에서의 locally aware featrue 를 계산하고, 계산된 feature의 각 요소를 대응되는, 사용된 patch feature의 lowest hierarchy level의 feature(여기서는 j번째 계층의 locally aware patch feature)와 합쳐주는 방식으로 계산됨
- bilinear하게 j+1번째 계층의 patch feature를 rescaling해줌으로써 j번째 계층의 patch feature 와 합쳐주는 것
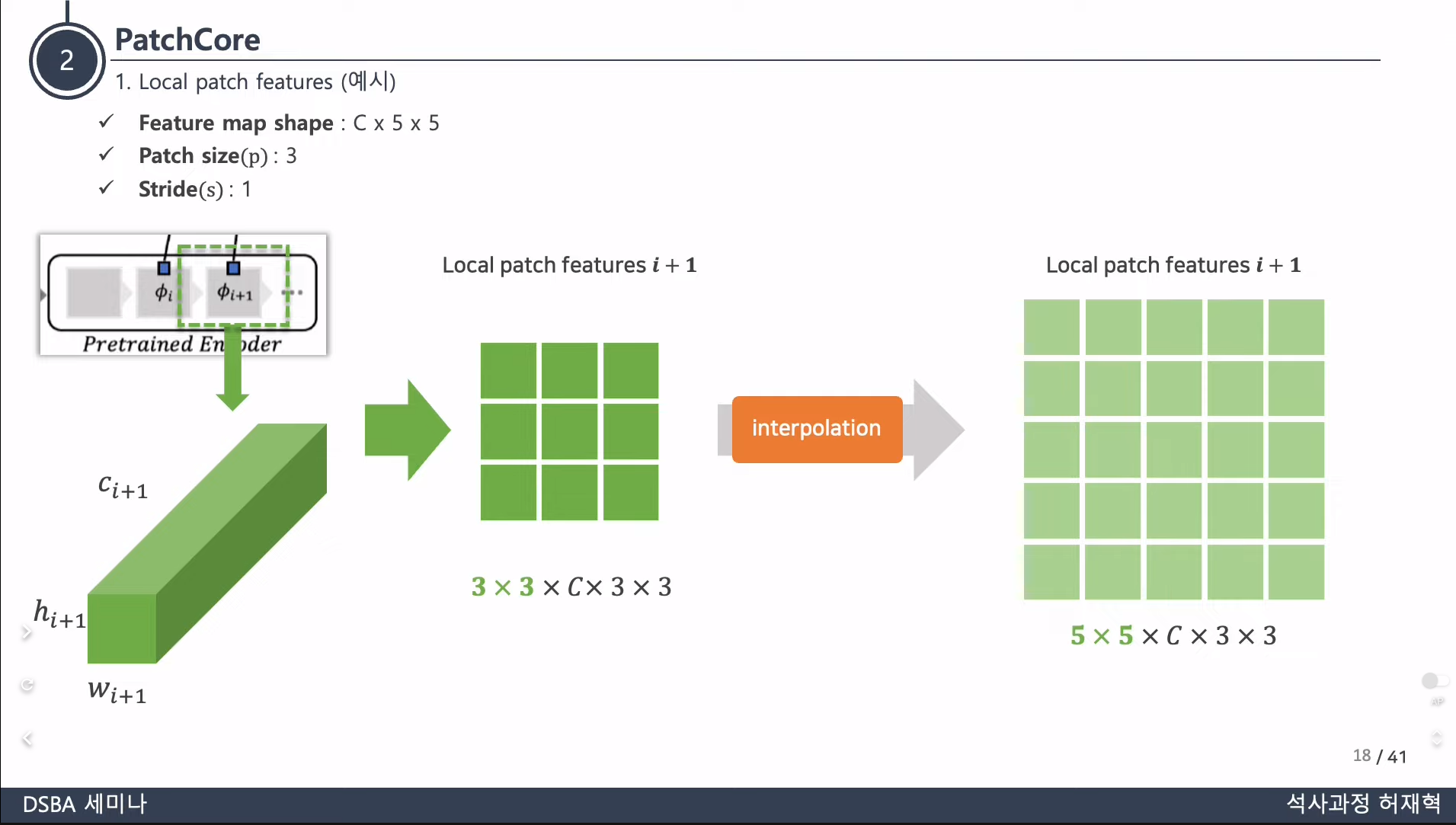
- 우선, j+1 계층에서의 locally aware featrue 를 계산하고, 계산된 feature의 각 요소를 대응되는, 사용된 patch feature의 lowest hierarchy level의 feature(여기서는 j번째 계층의 locally aware patch feature)와 합쳐주는 방식으로 계산됨
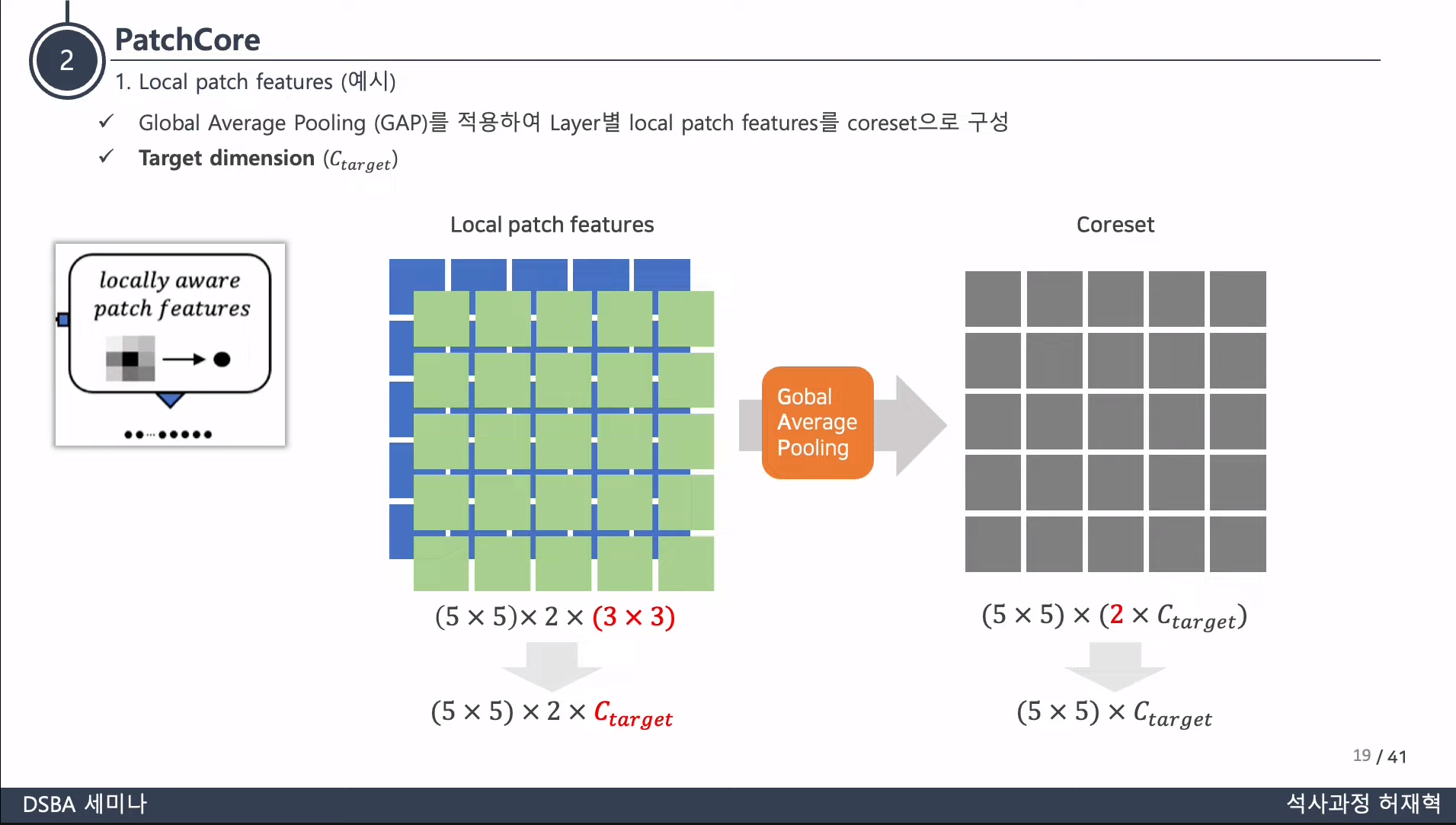
- 최종적으로, nominal training sample은 다음과 같이 나옴

3.2. Coreset-reduced patch-feature memory bank
-
Training data 의 수가 증가함에 따라, 메모리 뱅크 은 매우 커지고, 새로운 test data에 대해 평가하기 위한 inference time과 그때 사용되는 storage 크기가 매우 커짐
- SPADE에서는 anomaly segmentation을할 때 low, high level feature를 모두 사용하기 때문에 이에 대한 문제가 존재했음
- pixel level anomaly detection을 할 때 computational limination때문에 SPADE에서는 feature map의 pre-selection stage를 사용
- 이때, image level anomaly detection 매커니즘에 의해 (full image, deep feature representation에 의존)작동하기 때문에, 해상도가 낮을 뿐더러, ImageNet에 편향된 representation을 사용하는 문제 존재
- pixel level anomaly detection을 할 때 computational limination때문에 SPADE에서는 feature map의 pre-selection stage를 사용
- SPADE에서는 anomaly segmentation을할 때 low, high level feature를 모두 사용하기 때문에 이에 대한 문제가 존재했음
-
위 문제를 해결하기 위해 PatchCore에서는 M이 large image size와 count를 찾을 수 있도록 함
- 그렇게 함으로써 detection과 localization 모두에서 성능이 좋은 patch based comparison이 효과적으로 이뤄질 수 있도록 함
- 이때 M에 속한 featrue들은 nominal featre coverage가 좋다는 가정이 전제되어있음
- 다양한 크기로 하는 Random subsampling의 경우, 중요한 정보를 잃을 수 있는 문제 존재
- 그러므로, 본 논문에서는 Coreset subsampling mechanism을 제안함
- 해당 방법을 통해 inference time은 줄이면서 성능은 유지할 수 있었음
- 그렇게 함으로써 detection과 localization 모두에서 성능이 좋은 patch based comparison이 효과적으로 이뤄질 수 있도록 함
-
PatchCore는 nearest neighbour computation을 사용하기 때문에 본 논문에서는 minmax facility location coreset selection 사용
-
M-coreset 는 거의 원본 메모리 뱅크 M을 근사함

-
coreset selection time을 줄이기 위해 iterative greedy approximation 사용
- 메모리뱅크 M의 요소 각각의 차원을 줄이기 위해 Johnson-Lindenstrauss theorem 사용
- 랜덤하게 linear projection 수행.
- 랜덤하게 linear projection 수행.
- 메모리뱅크 M의 요소 각각의 차원을 줄이기 위해 Johnson-Lindenstrauss theorem 사용
-
Memorybank reduction algorithm

- 는 원본 메모리 뱅크에서 subsampling된 percentage를 의미
Random Selection과 비교한 Greedy coreset subsampling의 예시
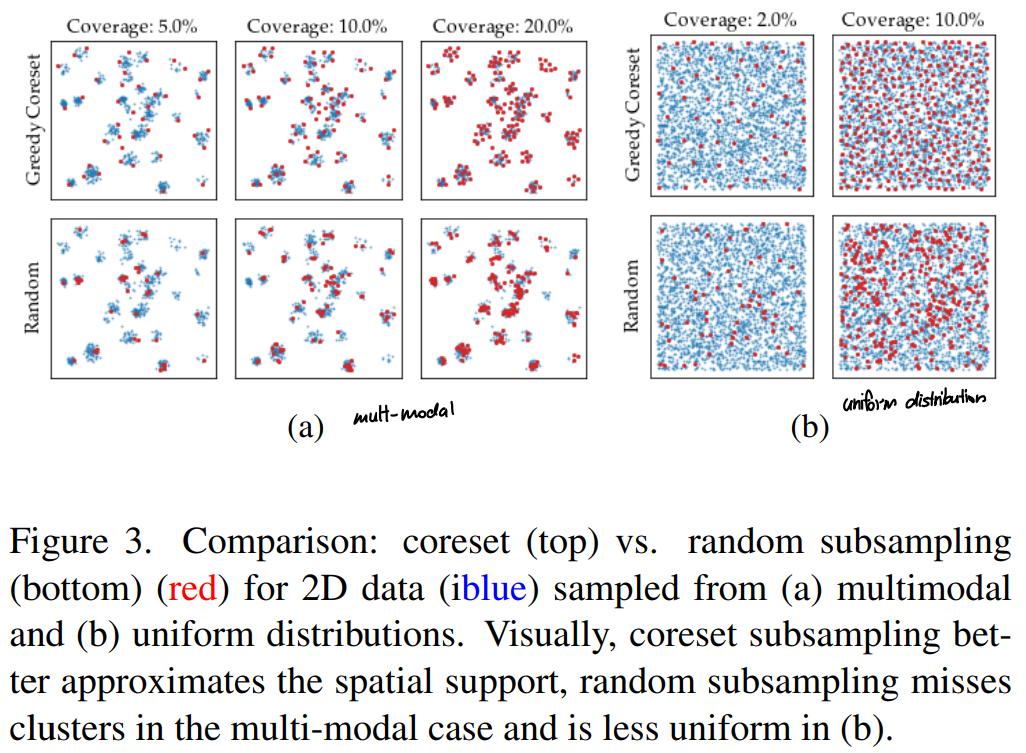
- 파란 점이 원본 데이터, 빨간 점이 subsampling된 데이터고 가정할 때, 아래 줄이 Random selection, 윗 줄이 Coreset 방식에 의한 subsampling 결과이다.
- Random Selection의 경우, Coreset과 달리 multimodal에서 일부 cluster에 대해 sampling하지 못하고, 덜 uniform하게 subsampling하는 것을 알 수 있다.
3.3. Anomaly Detection with PatchCore
-
nominal patch feature로 이뤄진 memory bank M에서 test image에 대한 image level anomaly score를 예측
- test patch들에 대한 distance score들 중 최대값을 anomaly score로 가짐
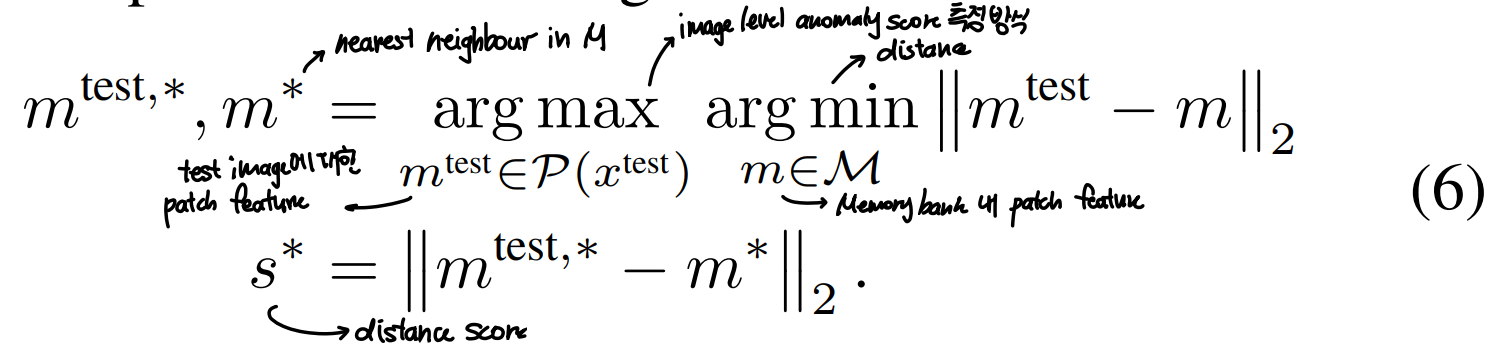
- test patch들에 대한 distance score들 중 최대값을 anomaly score로 가짐
-
s를 얻기 위해 메모리 뱅크 내 주변 nominal patch feature와의 거리에 따라 s*을 scaling해줌
- 만약 anomaly candidate 과 가장 가까운 memory bank feature가 neighbouring sample들과 멀리 있으면, 그 sample은 rare한 nominal sample이므로, anomaly score를 증가시키겠다는 것
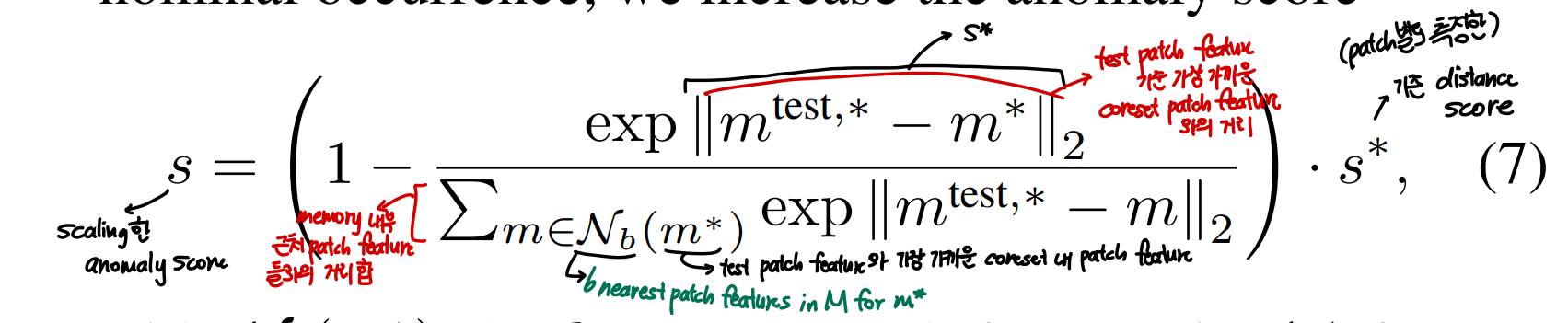
- 만약 anomaly candidate 과 가장 가까운 memory bank feature가 neighbouring sample들과 멀리 있으면, 그 sample은 rare한 nominal sample이므로, anomaly score를 증가시키겠다는 것
이 식 notation이 너무 헷갈린다.
위처럼 re-weighting했을 때가 단순히 patch distance들 상에서 maximum값을 취했을 때보다 더 강건하게 작동했다고 한다.
- segmentation map의 경우, 같은 방식으로 진행해주되, 계산된 patch anomaly score들을 각자 대응되는 위치에 따라 realigning해줌으로써 계산될 수 있음
- 이 과정을 위해 지금까지 네트워크의 중간 hierarchy feature를 사용해왔는데, 원본 이미지 해상도에 맞추기 위해 그 결과를 bi-linear interpolation을 통해 upscale해줌
- 추가적으로, 결과를 의 가우시안 커널로 smoothing해줬으나, 이 파라미터를 따로 optimize하지는 않음
4. Experiments
4.1. Experimental Details
Datasets
MVTec AD
- 전체 5354장의 이미지로 이뤄져있으며, 1725장은 test set에 해당
- 15개의 sub dataset으로 구성됨
- training data는 normal로만, test data는 normal, abnormal이미지 모두로 이뤄져있음
- 다양한 defect type, anomaly ground truth mask로 이뤄져있음
- 256x256으로 resize한 뒤 224x224로 center crop적용
- data augmentation은 적용하지 않음.
- class-retaining augmentation에 대한 사전 지식이 있어야 하기 때문
MTD(Magnetic Tile Defects)
- 925개의 결함 없는 이미지, 392장의 다양한 밝기와 이미지 사이즈를 갖는 anomalous magnetic tile image로 구성
- 20%의 normal image를 testing에 사용했으며, 나머지는 cold-start training을 위해 사용됨
mSTC(Mini Shanghai Tech Campus)
- STC dataset의 subsample된 버전
- non-industrial image, anomaly localization, cold start 문제에 대한 평가를 위해 사용
- 다섯 번째 scene의 training ,test frame만 사용
- 12개의 다른 scene에 대한 pedestrian video로 구성되어있음
- normal은 일반 보행자, abnormal은 싸우거나 자전거를 타는 등의 보행자
- cold start 문제에 대한 평가를 하기 위해 mSTC protocol을 따르되, anomaly supervision을 따로 하지는 않고 256x256 사이즈로 resize진행
- 12개의 다른 scene에 대한 pedestrian video로 구성되어있음
Evaluation Metrics
- Image-level anomaly detection의 경우, 생성된 anomaly score를 통해 AUROC(are under the receiver-operator curve)로 측정
- MVTec에 대해서는 class average AUROC 사용
- Segmentation 성능 측정을 위해서는 pixel-wise AUROC와 PRO metric 사용
- PRO score의 경우, MVTec AD 데이터셋에서 다양한 anomaly size가 있을 때 연결된 anomaly 요소를 복구해냈을 때를 더 중요하게 고려함
4.2. Anomaly Detection on MVTec AD
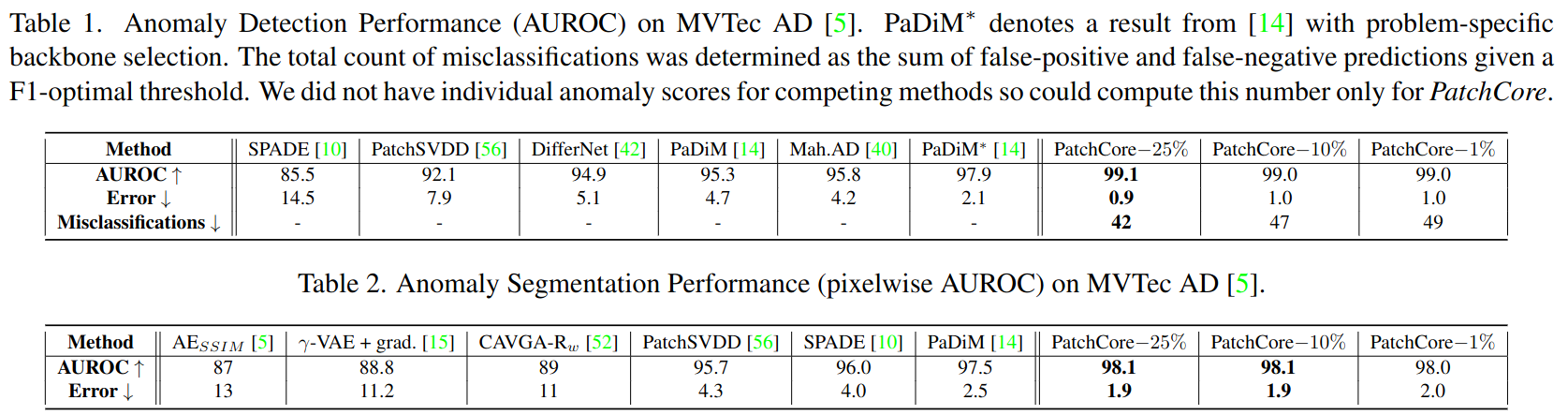
위 표는 MVTec 데이터셋에서의 image level, pixel wise anomaly detection 결과를 나타낸다. PatchCore의 경우, 다양한 레벨의 memory bank subsampling 비율 별 결과를 보여준다.

위 표는 PRO Metric 결과를 나타낸다.
- Coreset memory subsampling을 통해 효율성을 높일 수 있기에, subsampling ratio를 1%로 지정할 경우 더 높은 해상도의 이미지를 사용할 수 있다. (현재 기준은 224이나, 280/320 등으로 확장 가능)
- sampling ratio를 낮게 설정할 경우, 기본 해상도의 이미지 입력을 사용해 inference time을 유지하면서 다음 표와 같이 앙상블을 적용할 수 도 있음
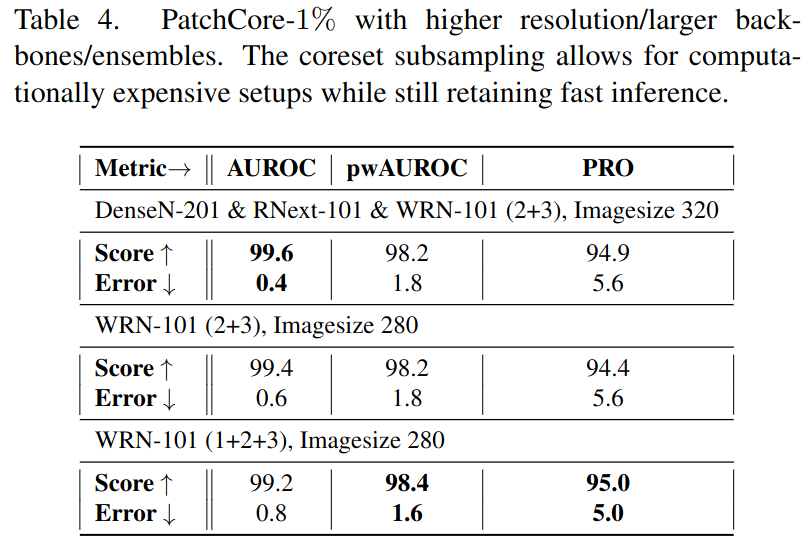
- sampling ratio를 낮게 설정할 경우, 기본 해상도의 이미지 입력을 사용해 inference time을 유지하면서 다음 표와 같이 앙상블을 적용할 수 도 있음
4.3. Inference Time
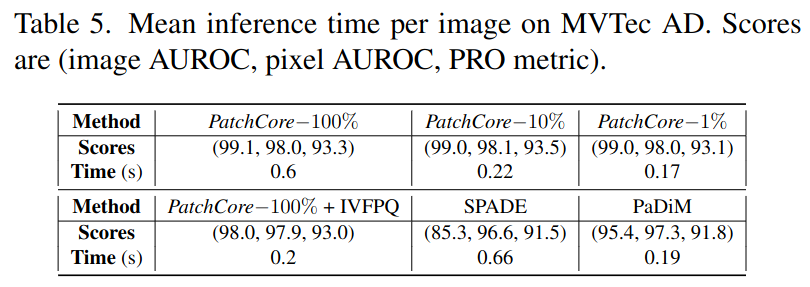
- WideResNet50을 사용했을 때의 기준
- backbone으로의 forward path time도 포함한 것
- Coreset sampling을 통해 성능은 유지하면서 inference time 줄일 수 있음
4.4. Ablation Study
- locally aware patch feature와 coreset reduction method에 대한 ablation 결과를 보여줌
4.4.1 Locally aware patch-features and hierarchies
- 다양한 neighbourhood size에 대한 anomaly detection 성능을 평가함으로써 locally aware patch feature에 대한 중요성 입증
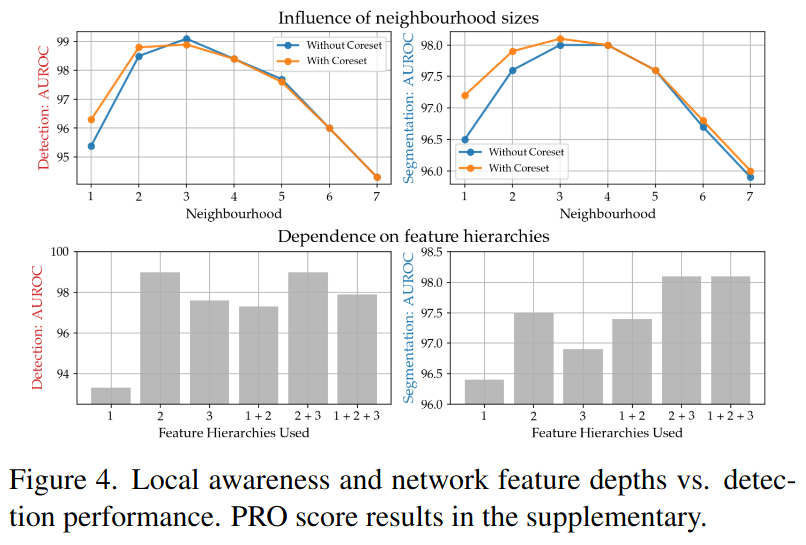
위 표에서 윗 부분의 표들이 Detection과 Segmentation 각각에 대한 최적 neighbourhood 값을 보여줌
밑 부분은 highly localized prediction들과 더 global한 context와 ImageNet class bias가 부여됐을 때 각각의 성능을 보여줌- neighbourhood 값으로 3을, 2, 3 layer(더 깊은 레이어를 사용)를 Feature hierarchy로 사용했을 때 더 global한 정보를 얻을 수 있기에 성능이 좋은 것을 확인 가능
- global한 context를 얻을 수 있는 대신, 더 깊은 layer를 사용할 경우, resolution이 손실되며 ImageNet class bias가 더 많아짐
- 기본값으로 2+3 layer 사용
- neighbourhood 값으로 3을, 2, 3 layer(더 깊은 레이어를 사용)를 Feature hierarchy로 사용했을 때 더 global한 정보를 얻을 수 있기에 성능이 좋은 것을 확인 가능
4.4.2 Importance of Coreset subsampling
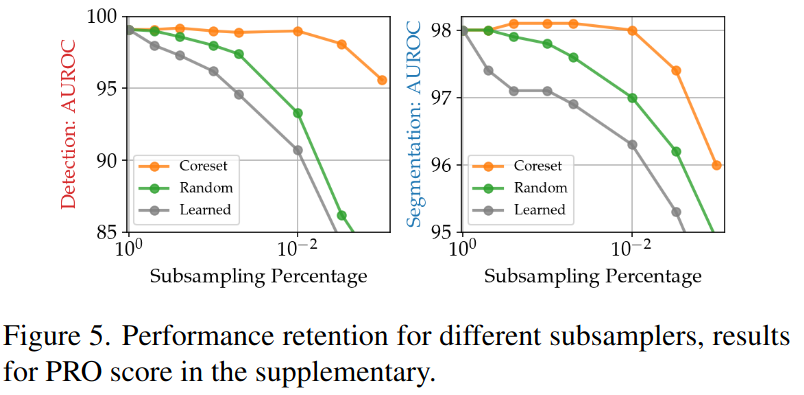
위 그림은 subsampling 방법 각각에 대한 성능을 보여줌. Coreset Subsampling이 가장 성능이 좋음!
-
Greedy coreset selection
-
Random subsampling
-
subsampling target percentage 에 대응되는 basis proxy set에 대한 학습
-
proxy 를 sampling함
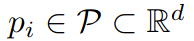
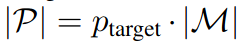
-
아래와 같은 basis reconstruction objective를 minimize
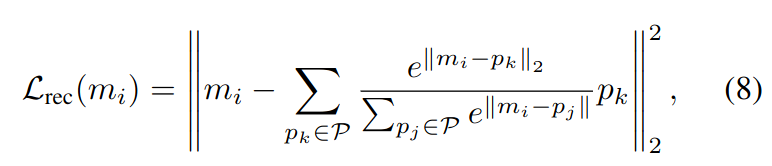
-
-
memory bank data 을 가장 잘 묘사하는 proxy 을 찾기 위함
-
subsampling을 안했을 때와 했을 때의 성능이 비슷함
-
memory bank size 을 줄일수록, 즉 stride를 크게 해서 resolution을 작게 가져갈 수록 성능이 하락하는 것을 확인
4.5. Low-shot Anomaly Detection
- nominal data가 적을 때의 성능에 대해서도 연구함
- 아래 그림은 같은 backbone(WideResNet50) 하에서 적은 sample로 학습되었을때의 성능을 나타냄
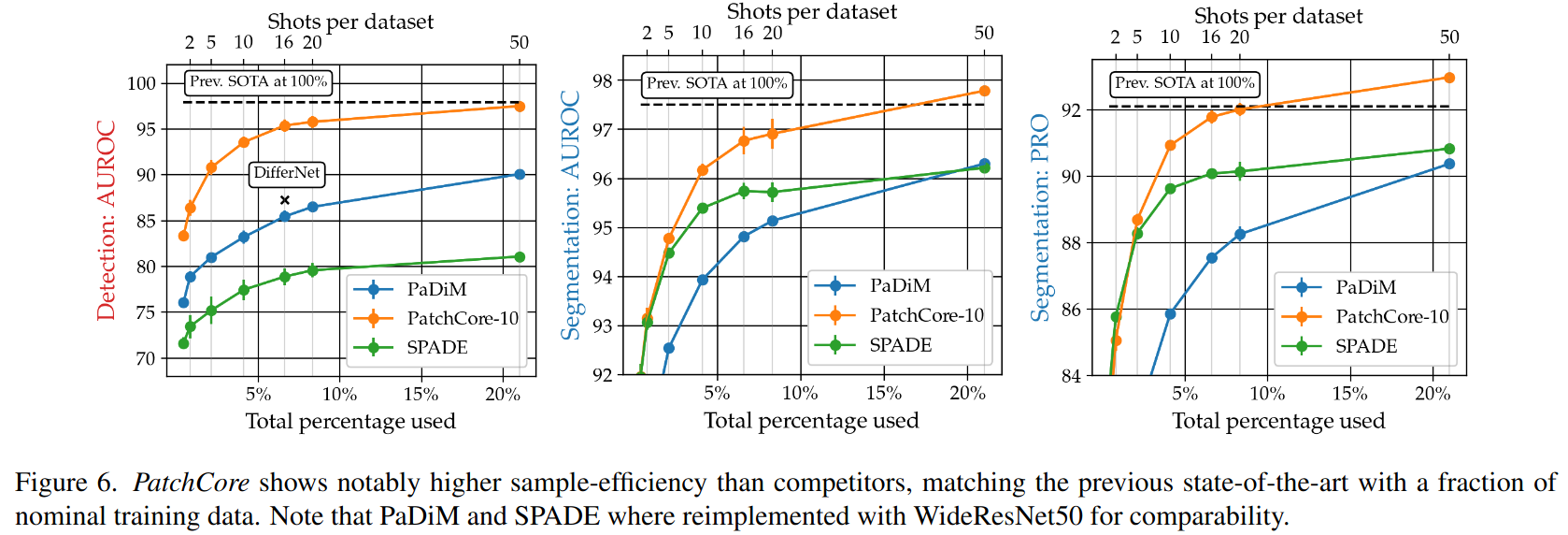
- 1/5의 데이터만 사용하고도 SOTA와 견주는 성능 달성!
4.6. Evaluation on other benchmarks
- STC, MTD dataset에서도 평가 진행
- mSTC에 대해서는 unsupervised anomaly localization 성능 평가 (256x256 사이즈로 resize 후 진행)
- detection context가 ImageNet에서의 natural image와 훨씬 가깝기 때문에 더 깊은 네트워크의 featuremap 사용 (level 3, 4). 이외의 hyperparameter tuning은 거치지 않음
- mSTC에 대해서는 unsupervised anomaly localization 성능 평가 (256x256 사이즈로 resize 후 진행)
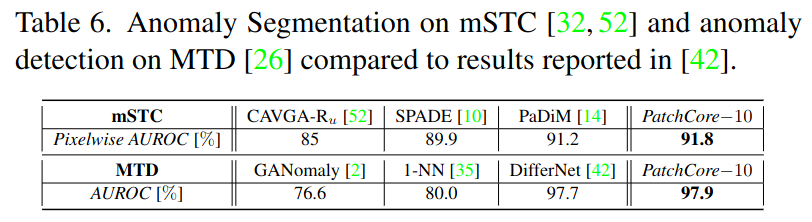
위 표는 mSTC 데이터셋에서의 Anomaly Segmentation 결과를 보여준다. 보면, PatchCore를 썼을 떄 SOTA인 것을 알 수 있다. 즉, 위 결과는 PatchCore의 해당 데이터셋 도메인에서의 transferability를 보여준다.
밑열은 MTD dataset에 대한 결과
- MTD dataset의 경우, 입력의 크기가 다양하다. 즉, spatially rigid approach 방식의 PaDiM은 MTD dataset에서 잘 작동하지 않으나, PatchCore는 이미지 사이즈의 변동과 상관 없이 잘 작동한다.
5. Conclusion
- Cold start anomaly detection을 위한 알고리즘 PatchCore 제안
- train 시에는 normal image만 사용
- test time에 nominal context를 최대한 활용하면서 locally aware한, Image pretrained network로부터 얻은 nominal patch level feature representation을 담는 memory bank 활용
- coreset subsampling을 통해 runtime을 줄임
- 이 논문이 나왔을 때 기준으로 MVTec AD 데이터셋에 대해 SOTA 달성!
Broader Impact
- 본 논문은 industrial anomaly detection에 초점을 맞춤
- societal application이 가능할지는 의문
Limitations
- industiral anomaly detection에 대해 중점을 두었기에, 또 다른 domain, 즉 일반화하기 위해 적용하기는 어려울 것으로 보임
- future work로 보류!
