논문 링크: https://arxiv.org/abs/1609.04802
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
CVPR 2017
Abstract
-
빠르고 깊은 CNN을 사용함으로써 super-resolution task의accuracy와 속도가 향상될 수 있었음
- 그러나, 여전히 upscaling factor를 크게 줬을 때 finer texture detail을 잘 복구할 수 없었다는 문제 존재
- 기존 연구는 super-resolution task에서 MSE 를 최소화하는 방식으로 최적화를 해왔으나, 그에 따른 결과는 high-frequency detail이 부족하며 느끼기에 성능이 좋지 않았음
-
본 논문에서는 SRGAN 제안
- 즉, Super-Resolution task를 위한 Generative Adversarial Network 제안
- 4x upscaling factor에 대해서도 성능 좋았음
-
이에 더불어 perceptual loss function제안
아래 두 loss의 조합으로 이뤄짐- adversarial losss
- uper-resolved image가 photo-realistic image와 비슷하게 될 수 있도록
- content loss
- pixel space similiarity가 아닌 perceptual similarity를 고려할 수 있도록
- adversarial losss
- MOS (mean-opinoin-score)에 있어 SRGAN의 결과가 SOTA
1. Introduction
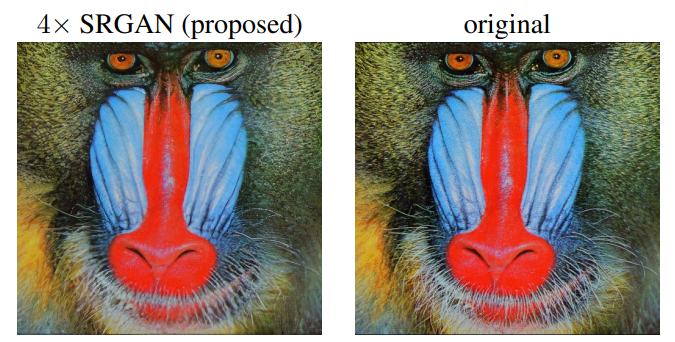
SRGAN으로 SR task를 수행한 결과는 다음과 같다.
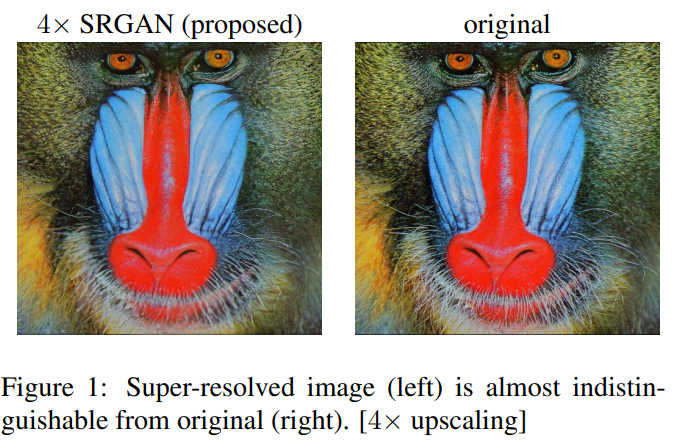
- SR task에서 기존에는 MSE loss를 많이 사용해왔음
- MSE를 최소화하면 PSNR(peak signal-to-noise ratio)을 최대화하는 특징이 있기 때문
- PSNR이란, 특정 영상의 화질에 대한 손실 정보를 평가하는 지표
- 화질 손상이 적을 수록, 즉 화질이 높을 수록 PSNR도 높은 값을 가짐
- 그러나, 보기에 화질이 기대만큼 좋아지지 않았는데 MSE가 낮고, PSNR이 높은 경우도 있음(perceptually different)
- 위 두 평가 지표는 pixel-wise image difference에 기반해 측정을 하기 때문

위 그림들을 보면 알 수 있다시피, PSNR이 높다 해서 보기에도 SR task가 잘 이뤄진 것은 아니라는 걸 알 수 있다. 또, MSE 의 특성 상 보면, 상세 질감 표현이 잘 되지 않았다.
- MSE loss가 아닌 perceptual loss를 최적화하는 ResNet기반의 SRGAN 제안
- VGG network를 통해 얻은 high feature map을 사용한 새로운 perceptual loss정의
- 이때, discriminator를 사용해 HR reference image와 최대한 유사하도록 결과 이미지가 생성되도록 함
1.1. Related work
1.1.1 Image super-resolution
- Single Image Super-Resolution(SISR)에만 초점 맞출 것
- 여러 이미지로부터 HR 이미지를 복원해내는 것은 고려 x
Prediction based methods
- linear, bicubic, Lanczos 등 filtering approach의 경우, 매우 빠르지만 texture정보를 스무스하게 만드는 문제 발생
- edge-preservation에 초점 맞춰짐
Self-dictionary / Self-similarity
- training data에 의존한다는 특징 존재
- low/high resolution image를 패밍해 그 정보에 의존하는 것
- multi-scale dictionary, neighborhood embedding approach등 존재
CNN-based SR algorithm
- 좋은 성능을 보임!
- 본 논문의 접근 방식
1.1.2 Design of convolutional neural networks
- batch normalization, residual block, skip connection 등 참고
1.1.3 Loss function
- MSE를 최소하는 것의 단점
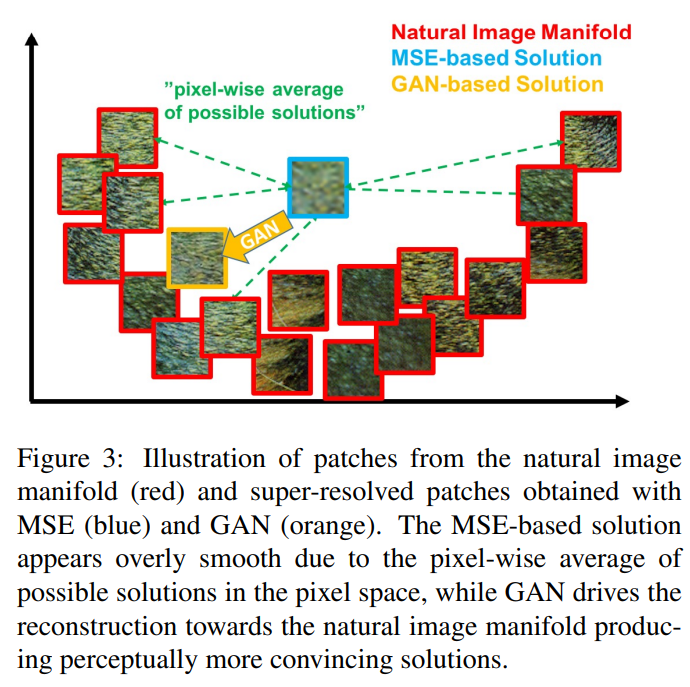
MSE의 특성 상 픽셀 정보를 과하게 smooth하는 문제가 있음. GAN의 경우, natural image manifold와 유사하도록 이미지를 생성해냄
1.2. Contribution
-
SRResNet 제안
- 16 block deep ResNet
- 4x upscaling SR에서 SOTA 달성
- 평가지표로 PSNR과 SSIM사용
-
SRGAN 제안
- 새로운 perceptual loss통해 최적화됨
- VGG network로부터의 feature map을 통해 loss 계산
- pixel-space 변화에 대해 더 강건함
-
세 가지 benchmark 데이터셋으로부터 MOS(mean opinion score) test를 통해 4x SR task에서 SRGAN이 SOTA인 것을 증명
2. Method
- 학습 시 low resolution image는 Gaussian filter를 적용함으로써 얻어냄
- downsampling factor :
- Original High Resolution image(), Super resolved image size(): x x
- Low Resolution image() size: x x
Generative function optimization
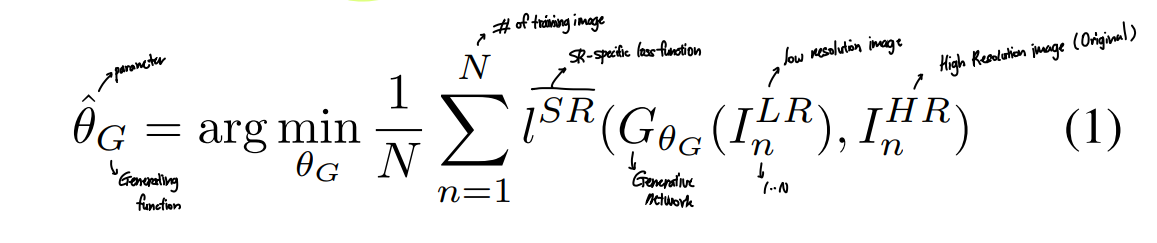
2.1. Adversarial network architecture
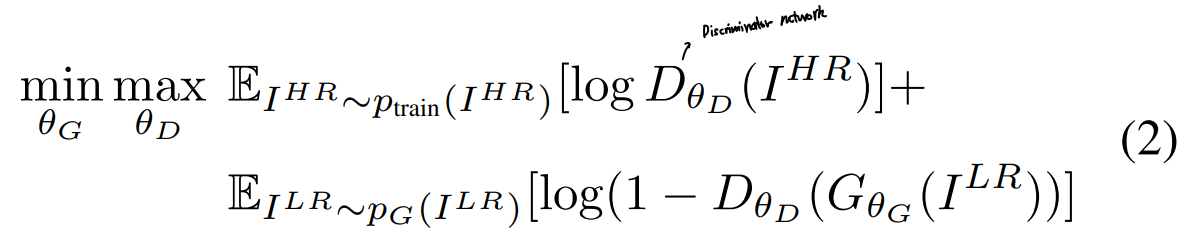
- 는 super-resolved image를 real image와 구분해낼 수 있도록, 는 super-resolved image가 최대한 real image와 비슷해질 수 있도록 학습됨
- 궁극적으로 Discriminator는 Generator로부터 생성된 이미지를 real image와 구분할 수 없게 될 것
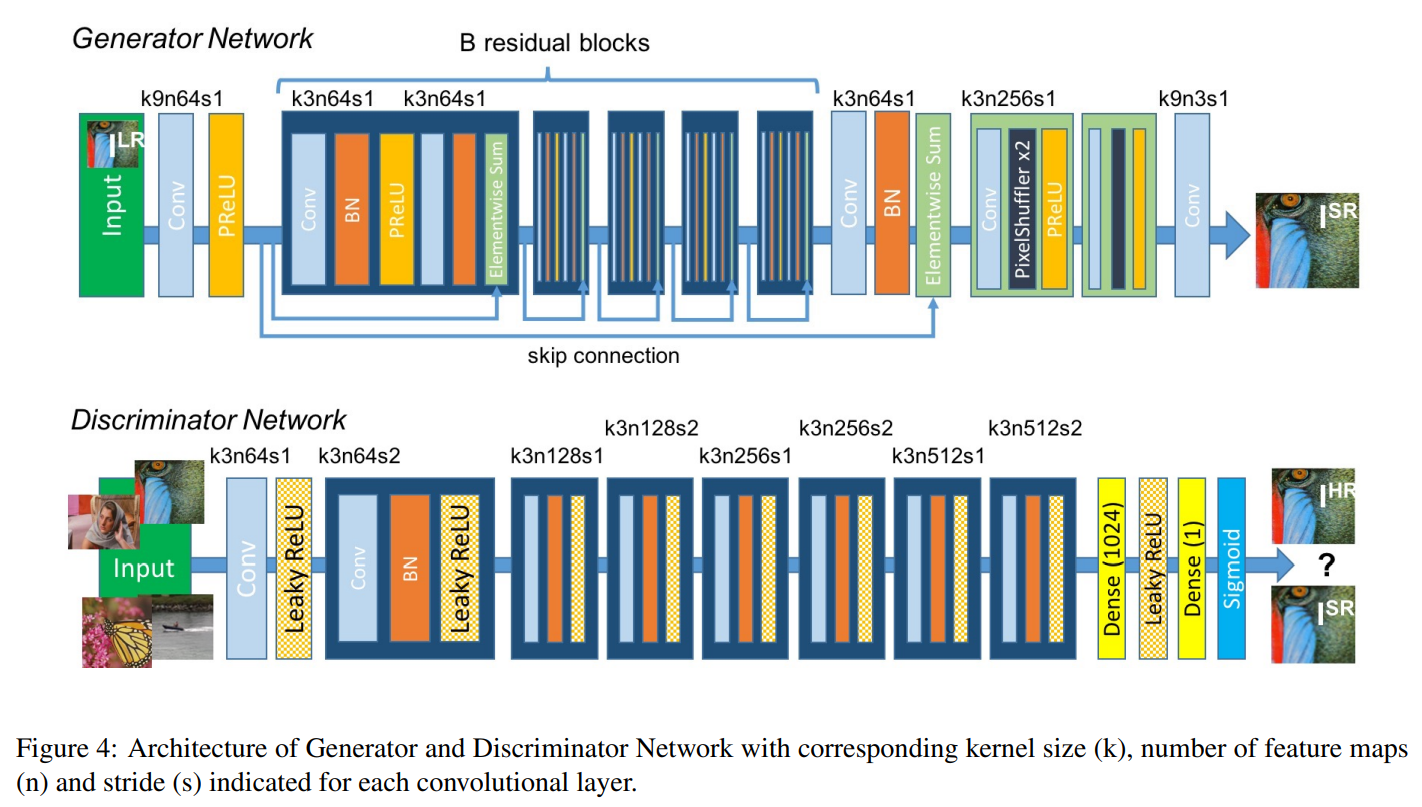
-
위 그림에서 각 convolution layer 당 k는 커널 사이즈, n은 feature map수, s는 stride를 의미.
-
의 구조로는 개의 residual block 사용
- activation function으로는 Parametric ReLU 사용
-
실제 HR 이미지와 생성된 SR 이미지를 구분하기 위해 discriminator network를 학습
- activation function으로 LeakyReLU 사용(=0.2)
- maxpooling사용하지 않음
- strided convolution 사용
- (2) 식을 통해 최적화됨
- VGGnet과 비슷한 CNN 구조 사용
- 최종적으로 나오는 512개의 feature map 뒤에 두 개의 dense layer와 sigmoid activation function을 통해 classification
2.2. Perceptual loss function
- content loss와 adversarial loss의 weighted sum으로 정의
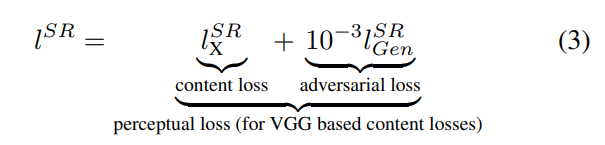
2.2.1 Content loss
Pixel-wise MSE loss
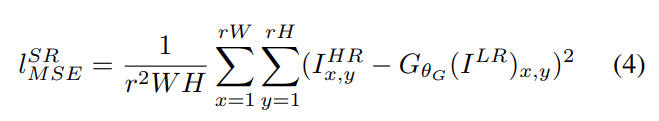
-
high frequency content를 잘 못 살려내 보기에 만족하지 못한 결과가 나오는 문제 발생
- 과하게 텍스쳐를 스무딩함
-
Perceptual similarity를 높이기 위해 VGG loss 제안
- ReLU activation function을 사용한 pretrained 19 layer VGG 네트워크를 사용
- 해당 레이어를 통과한 feature representation 간 euclidean distance를 VGG loss로 정의
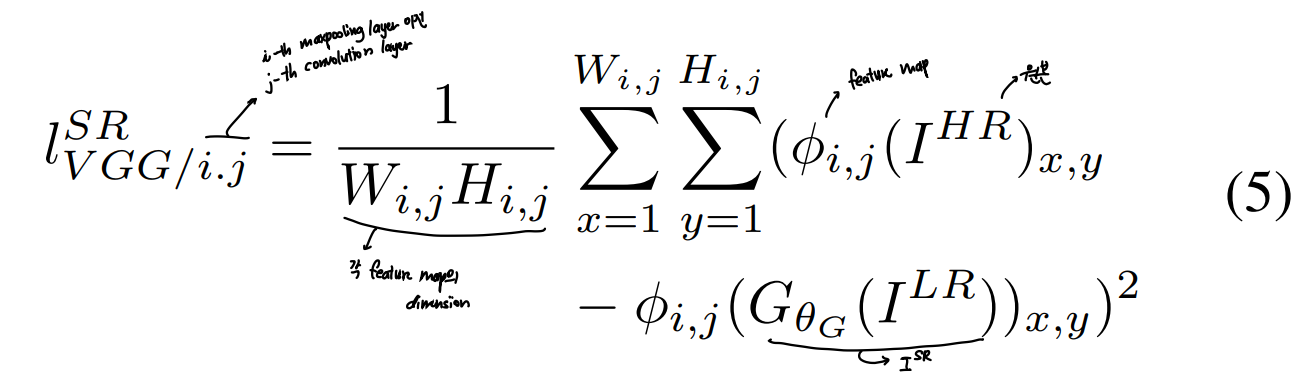
2.2.2 Adversarial loss
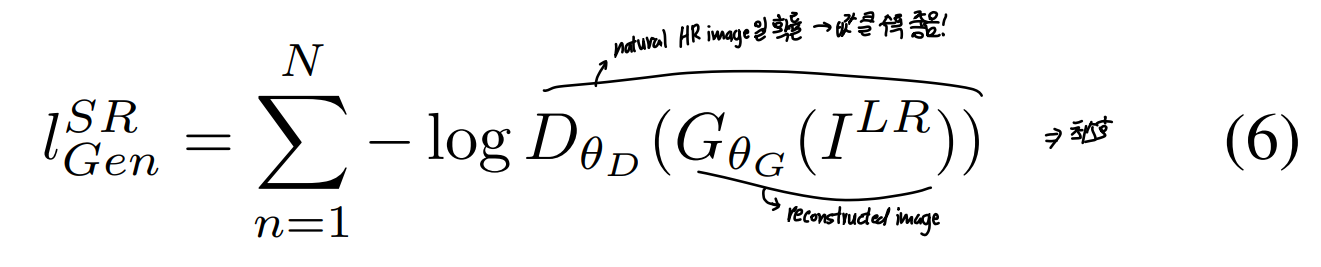
- 해당 loss를 사용함으로써 real image와 생성된 이미지가 유사해질 수 있도록 함
- 모든 training sample들에 대한 discriminator probability를 통해 계산됨
3. Experiments
3.1. Data and similarity measures
- benchmark dataset Set5, Set14, BSD100 사용
- 4x scale factor에 대해 진행
- 비교를 위해 4-pixel wide로 border를 crop한 이미지에 대해 PSNR과 SSIM score 계산
3.2. Training details and parameters
- ImageNet database로부터의 35만개 이미지 사용
- 4배 downsampling, bicubic kernel 사용해 LR이미지 얻어냄
- 각 training image의 미니배치마다 랜덤하게 16개의 96x96 sub image를 크롭해 HR이미지로서 사용
- LR이미지의 경우, 범위 [0,1], HR 이미지의 경우 범위 [-1,1]로 normalize
- MSE loss는 [-1,1]사이의 값을 가짐
- VGG loss를 구하기 위해 사용되는 VGG featrue map 또한 mse loss와 scale 맞추기 위해 로 rescale해줌
- 즉, (5)번 식에 0.006을 곱해주면 됨
- Optimizer로는 Adam 사용,
- SRResNet의 경우, 백만번의 update동안 learning rate로 의 값 사용
- 실제 GAN을 학습시킬 때 generator를 초기화하기 위해 MSE기반으로 학습된 SRResNet 네트워크 사용
- local optima 피하기 위함
- SRGAN 학습 시 10만번의 update동안 의 learning rate로, 이후 10만번의 update 동안에는 의 learning rate로 학습시킴
- 이때 generator와 discriminator는 k=1로, 즉 번갈아가면서 학습됨
- generator는 16개의 동일한 residual block으로 이뤄져있음
- test 시에는 input에만 의존되도록 하기 위해 batch normalization update하지 않음
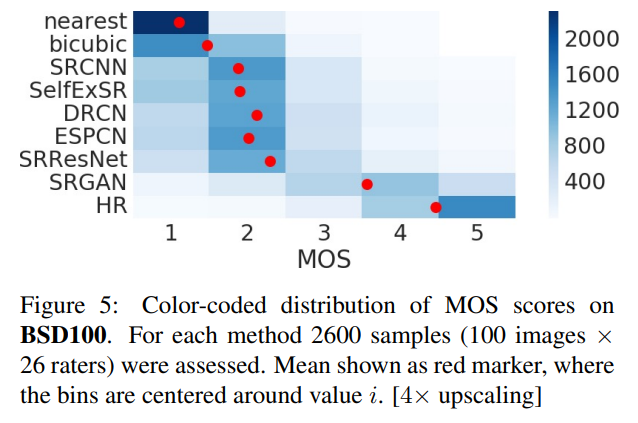
3.3. Mean opinion score(MOS) testing
- 실제로 "보기에" 잘 reconstruction되었는지 판단하기 위함
- 실제 사람들에게 rating하도록 함
- 자세한 건 논문 참고
3.4. Investigation of content loss
- GAN based-network에서 perceptual loss로 각기 다른 content loss를 사용했을 때의 결과를 확인해봄
- (3) 식 참고
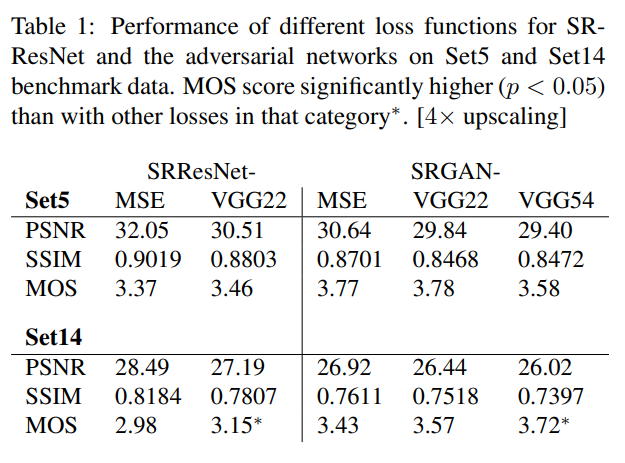
- SRGAN-MSE
- content loss로 mse 사용
- SRGAN-VGG22
- 사용(lower-level feature 사용)
- SRGAN-VGG54
- 사용(high level feature 사용)
- 이미지의 content에 초점맞출 수 있도록 함
- 해당 설정을 SRGAN에서 사용
- 사용(high level feature 사용)

표의 결과와 같이 SRGAN-VGG54의 세팅으로 했을 때 보기에 가장 SR이 잘 된 것을 알 수 있다.
3.5. Performance of the final networks
- SRResNet과 SRGAN의 성능 비교 수행
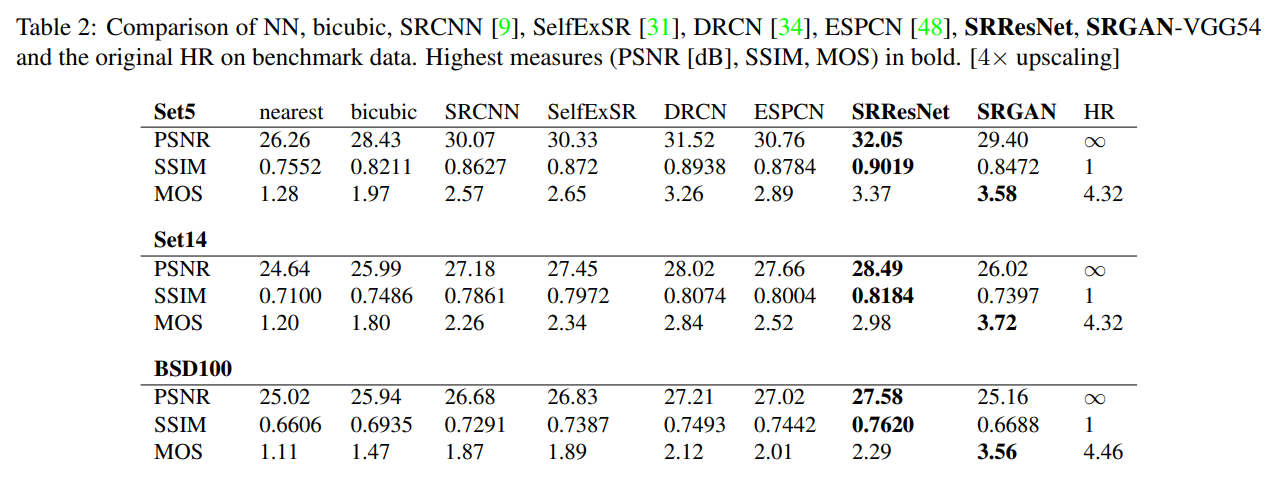
- PSNR과 SSIM을 고려했을 때, SRResNet이 SOTA
- MOS score 기준으로는 SRGAN이 SOTA
4. Discussion and future work
- 본 연구의 주 목표는 SR이미지의 "perceptual quality"를 높이는 것
- 해당 모델은 비디오의 SR 등 실시간 처리는 불가능
- SRResNet에서 더 깊은 구조로 네트워크를 구성한다면, (B>16) 성능이 더 좋아질 것
- 시간과 성능 간 trade off 존재
- SRGAN의 경우, high-frequency artifact로 인해 더 깊은 네트워크를 구성하더라도 학습시키기 어렵다는 점 발견
- 실험 결과들을 통해, content를 고려할 때 깊은 층의 network layer를 사용하는 것이 pixel space에서 벗어나 higher abstraction feature를 나타내기 좋다는 것 확인
- content 자체에 온전히 집중할 수 있도록 함
- adversarial loss는 texture detail에 초점을 맞출 수 있도록
- Application에 따라 loss를 조정하면 좋을 것
- medical application이나 surveilance의 경우, 사소한 디테일부분들보다 spatial content에 대한 정보 유지하도록 하는 등..
- pixel space의 변화에 강건하도록 SR task를 수행하는 게 앞으로의 관건일 것
5. Conclusion
- SRResNet 제안
- 당시 benchmark 데이터셋에서 PSNR이나 MSE에서 SOTA
- PSNR의 한계 지적
- SRGAN 제안
- Perceptual loss 제안 (content loss 초점)
- MOS testing 시행
A.1 Performance vs. network depth
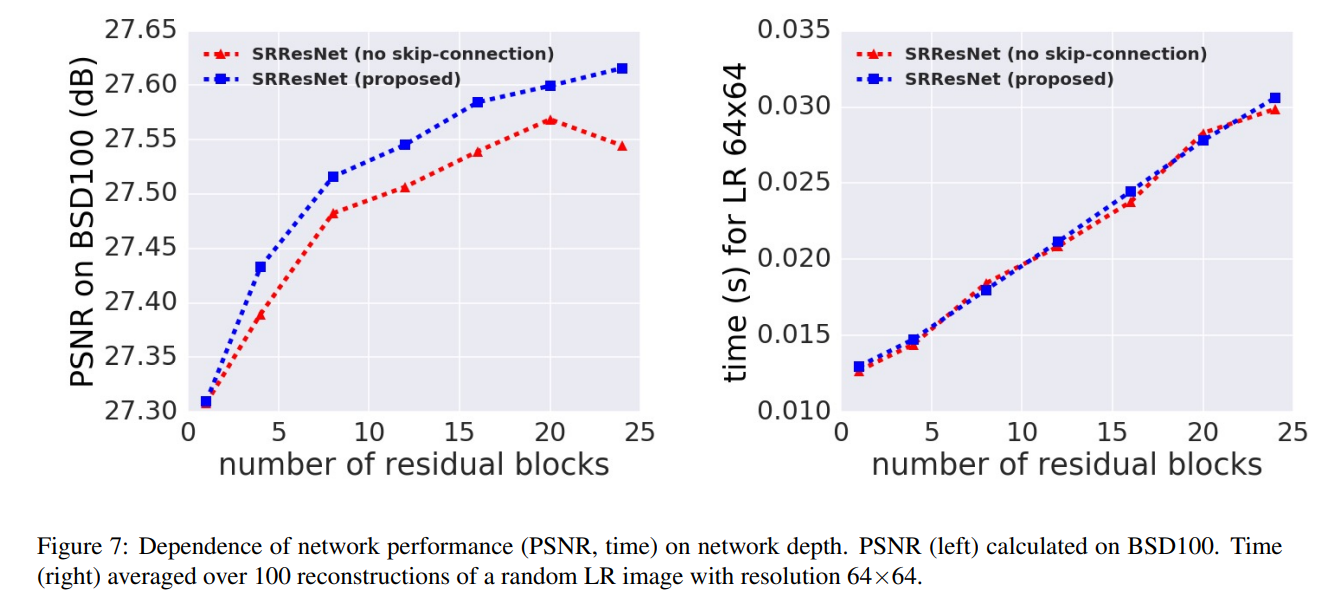
다른 추가 실험 결과는 논문을 참고
