Computer Networks
1.2 Network Hardware
2 types of transmission technology that are in widespread
broadcast links
- the communication channel is shard by all the machines on the network
- packets sent by any machine are received by all the others
- upon receiving a packet, a machine checks the address field
- if the packet is intended for some other machine, it is just ignored
- some broadcast systems also support transmission to a subset of the machines, multicasting
point to point links
- connect individual pairs of machines
- short message = packets
- one sender and exactly one receiver is called unicasting
1.2.1. Personal Area Networks
- PaNs let devices communicate over the range of a person
- design a short-range wireless network called Bluetooth to connect these components without wires
1.2.2. Local Area Networks
- privately owned network that operates within and nearby a single building like a home
- called enterprise networks
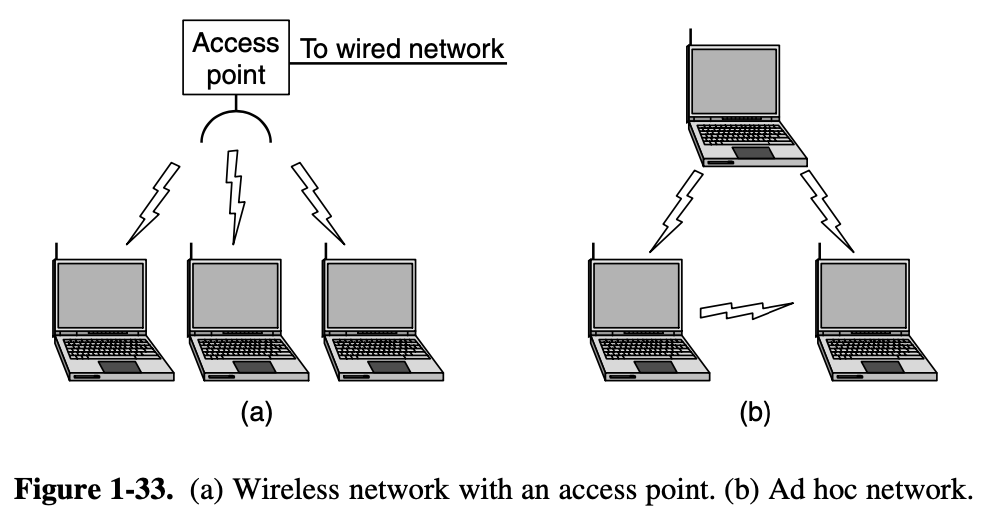
- in most cases, each computer talks to a device in the ceiling
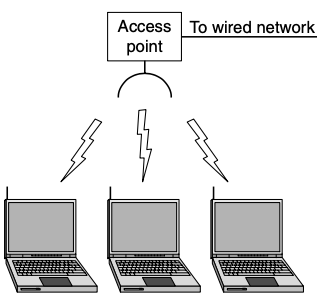
- This device, called an AP (Access Point), wireless router, base station
- standard for wireless LANs called IEEE 802.11 known as WiFi
- Wire LANs use a range of different transmission technologies
- compared to wireless networks, wired LANs exceed them in all dimensions of performance
- just easier to send signals over a wire or through a fiber than through the air
- the topology of many wired LANs is built from point-to-point links
- IEEE 802.3 called Ethernet
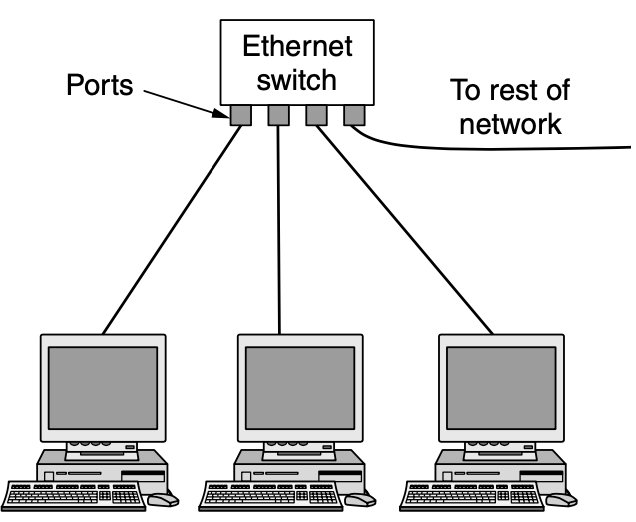
- Each computer speaks the thernet protocol and connects to a box called switch
- Switch has multiple ports, each of whih can connect to one computer
- To build larger LANs, switches can be plugged into each other using thier ports
What happens if you plug them together in a loop?
- job of the protocol to sort out what paths packets should travel to safely reach the intended computer
- also possible to divide one large physical LAN into two smaller logical LANs
- easier to manage the system if engineering and finance logically each had it's own network Virtual LAN , VLAN
classic Ethernet
- at most one machine could successfully transmit at a time
- computers could transmit whenever the cable was idle
- two or more packets collided, each computer just waited a random time and tried later
- wireless and wired broadcast networks can be divided into static, dynamic degisn
static allocation
- devide time into discrete intervals
- use a round-robin algorithm
- wastes channel capacity when a machine has nothing to say during its allocated slot
dynamic allocation
- common channel are either centralized or decentralized
- centralized channel allocation, there are single entry
- ex) base station in cellular networks, which determins who goes next
- decentralized channel allocation,
- each machine must decide for itself whether to transmit
1.2.3. Metropolitan Area Networks
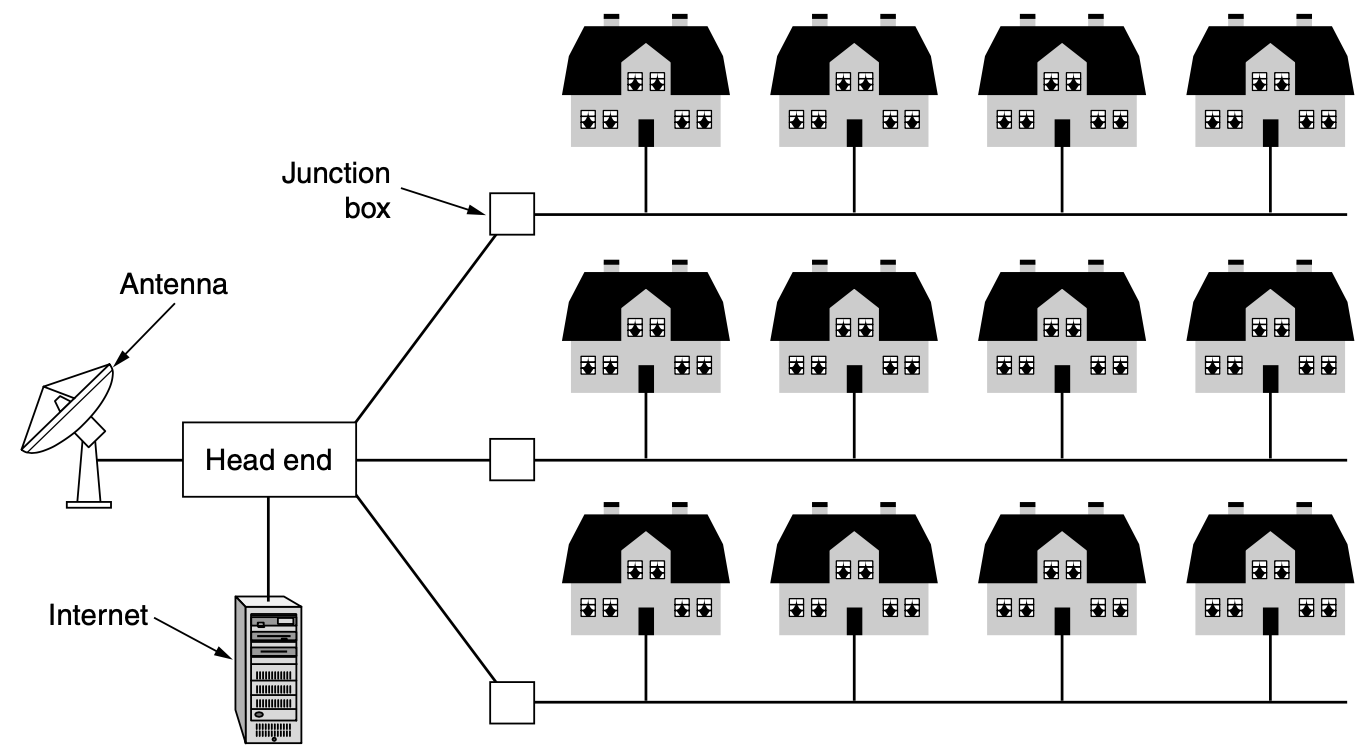
- ex) cable television networks available in many cities
- cable television is not the only MAN
- recent developments int high speed wireless Internet access have resulted in another MAN
1.2.4. Wide Area Networks
- large geographical area (ex) country or continent)
- rest of the network that connects these hosts is then called the communication subnet, just subnet for short
- Transmission lines move bits between machines
- Switching elements, are specialized computers that connect two or more transmission lines
- router : switching computers have been called by various name in the past
1.3. Network Software
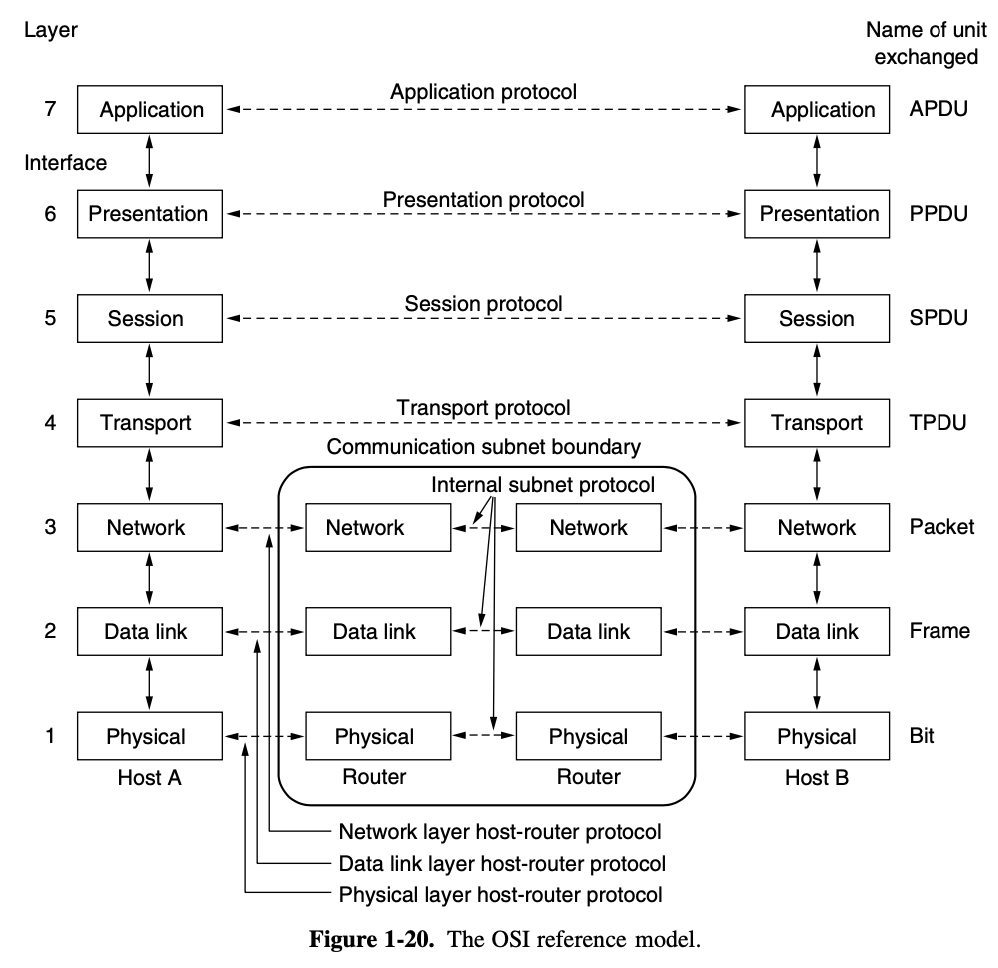
1.3.1. Protocol Hierarchies
- to reduce their design complexity, most networks are organized as a stack of layers or levels
- protocol : agreement between the communicating parties
Architecture of the Internet
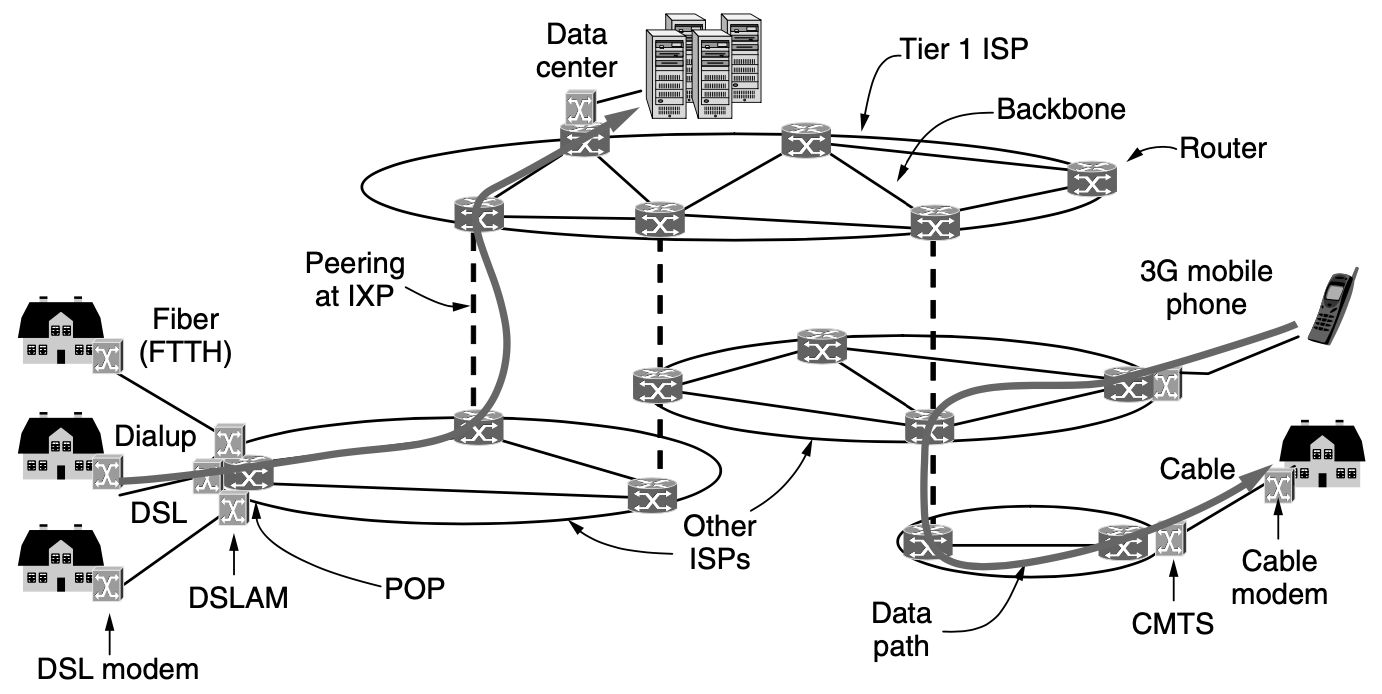
- DSL (Digital Subscriber Line) : reuses the telephone line that connects to your house for digital data transmission
- DSL model : convert digital packet to signal
- DSLAM (Digital Subscriber Line Access Multiplexer) : convert betwwen signals and packets
+) modem = modulator demodulator
- The device at the home and is called cable modem
- cable headend = CMTS (Cable Modem Termination System)
- internet access at much greater than dial-up speeds is called broadband
- name refers to access at much greater than dial-up used for faster networks, rather than any particular speed
- fatser internet access can be provided at rates on the order of 10 to 100 Mbps, called FTTH (Fiber to the Home)
- location at which customer packets enter the ISP network for service the ISP's POP (Point of Presence)
- long-distance transmission lines that interconnect routers at POPs in the different cities that the ISPs serve
- this equipment is called the backbone of the ISP
- ISPs connect their networks to exchange traffic at IXPs (Internet eXchange Points)
- The connected ISPs are said to peer with each other
1.5.2. Third-Generation Mobile Phone Networks
- AMPS (Advanced Mobile Phone System) first generation system
- GSM (Global System for Mobile communications) : become the most widely used mobile phone syestem in the world, 2G system
- UMTS (Universal Mobile Telecommunications Systems), WCDMA (Wideband Code Division Multiple Access) : main 3G system, being rapidly deployed world wide
- scarcity of spectrum that led to the cellular network
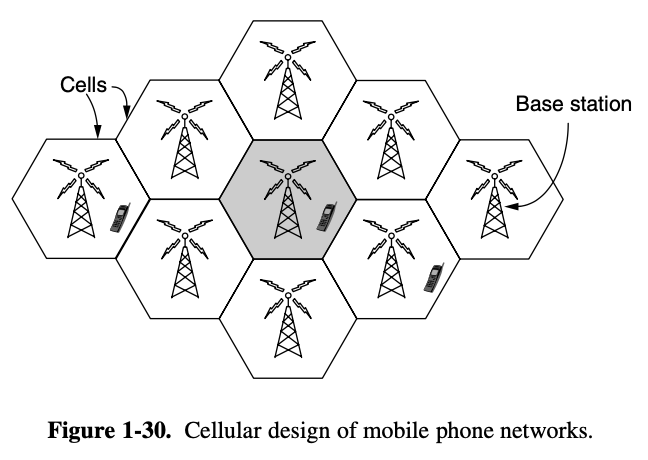
- within a cell, users are assigned channels that do not interfere with each other and do not cause too much interference for adjacent cells
- this allows for good reuse of the spectrum or frequency reuse in te neighboring cells which increase the capacity of the network
- air interface, cellular base station : fancy name for the radio communication protocol, is used over the air between the mobile device
- **RNC (Radio Network Controlller)v : controls how the epectrum is used
- Node B : base station implements the air interface
- core network : rest of mobile phone network carries the traffic for the radio access network
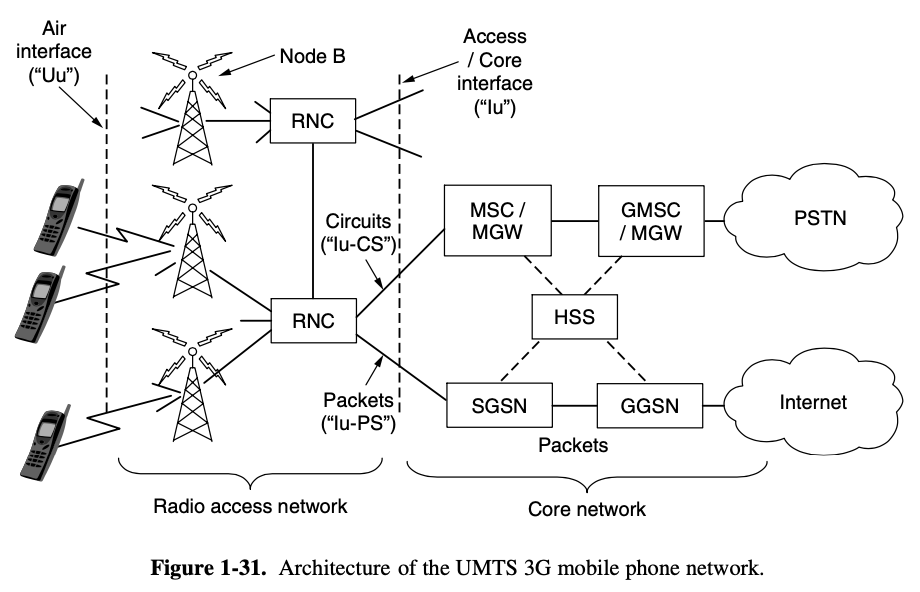
- there is both packet and circuit switched equipment in the core network
- older mobile phone networks used a circuit-switched core in the style of the traditional phone network to carry voice calls
[legacy]
- MSC (Mobile Switching Center), GMSC (Gate-Mobile Switching Center), MGW (Media Gateway) elements that set up connections over a circuit-switched core network such as PSTN (Public Switched Telephone Network)
[data service]
- **GPRS (General Packet Radio Service)
- newer mobile phone networks carry packet data at rates of multiple Mbps
- to carry all this data, UTMS core network nodes connect directly to packet-switched network
- SGSN (Serving GPRS Support Node), GGSN (Gateway GPRS Support Node) deliver data packets to and from mobiles and interface to external packet networks such as the internet
[handover, handoff]
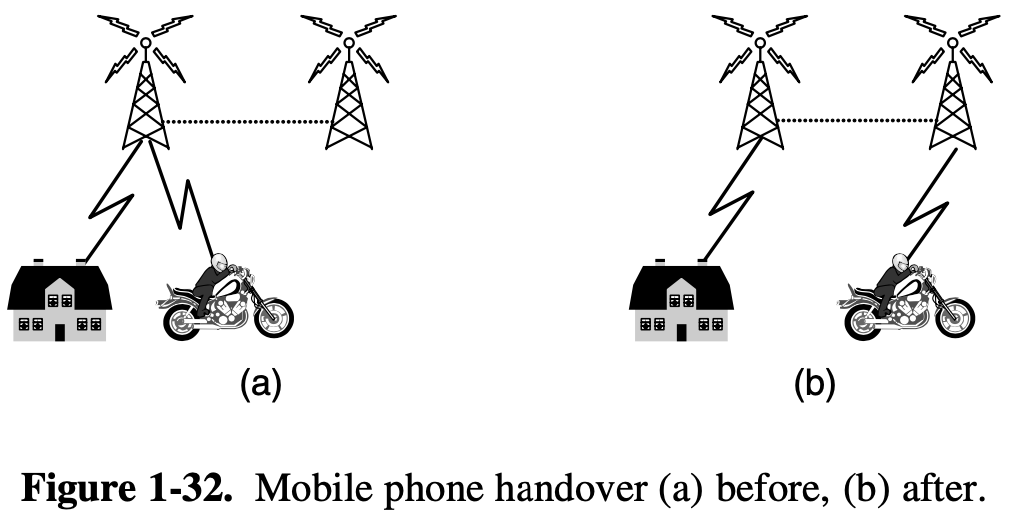
- CDMA is possible to connect to new base station before disconnection from the old base station
- soft handover, hard handover
- hos to find mobile in the first place when there is an incomming call
- Each mobile phone network has HSS (Home Subscriber Server) in the core network
1.5.3. Wireless LANs: 802.11
- ISM (Indutrial Scientific and Medical) bands defined by ITU-R (e.g., 902-928 MHz, 2.4-2.5 GHz, 5.725-5.825 GHz)
- 802.11 networks are made up of clients called APs (access points) = base stations
- 802.11 uses a CSMA (Carrier Sense Multiple Access) scheme that draws on ideas from classic wired Ethernet
- computers wait for a short random interval before transmitting
- wireless transmissions are broadcast, it is easy for nearby computers to receive packets of information that were not intended for them
- 802.11 standard included an encryption scheme known as WEP (Wired Equivalent Privacy), WiFi Protected Access, WPA, WPA2
1.5.4. RFID and Sensor Networks
- RFID (Radio Frequency IDentification)
tag consists of a small microchip with a unique identifier and an antenna that receives radio transmissions - RFID readers installed at tracking points find tags when they come into range and interrogate them for their information
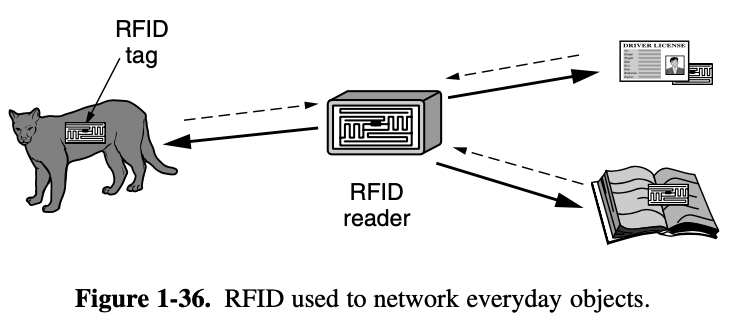
- passive RFID : form of radio waves by RFID readers
- active RFID : electric power source on the tag
- common form of RFID = UHF RFID (Ultra-High Frequency RFID)
- shipping pallets an some driver licenses
- tag communicate at distance of several meters by changing the way they relfect the reader signals
- the reader is able to pick up these reflections
- another popular kind of RFID = HF RFID (High Frequency RFID)
- ex) passport, credit cards, books etc
- short range, meter or less
- other frequencity = LF RFID (Low Frequency RFID)
- developed before HF RFID and used for animal tracking
- tags wait for a short random interval before responding with their identification
- which allows the reader to narrow down individual tags and interrogate them further
- RFID readers to easily track an object
- difficult to secure RFID tags
- weak measures like passwords are used
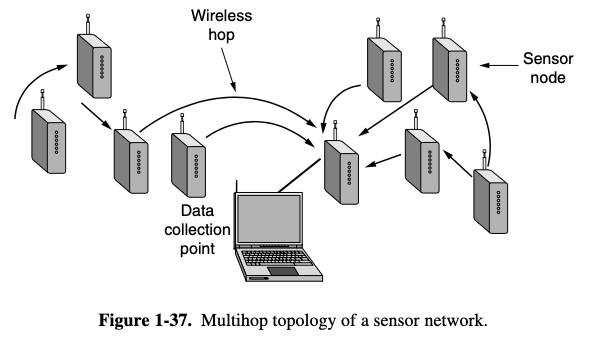
- RFID is sensor network
- deployed to monitor aspects of the physical world
- sensor nodes are small computers
- many nodes are place in the environment that is to be monitored
- nodes communicate carefully to be able to deliver thier sensor information to an external collection point
Physical layer? 왕어려움 안해
3. The data link layer
3.1. Data link layer design issues
- providing a well-defined service interface to the network layer
- dealing with transmission errors
- regulating the flow of data so that slow receivers are not swamped by fast senders
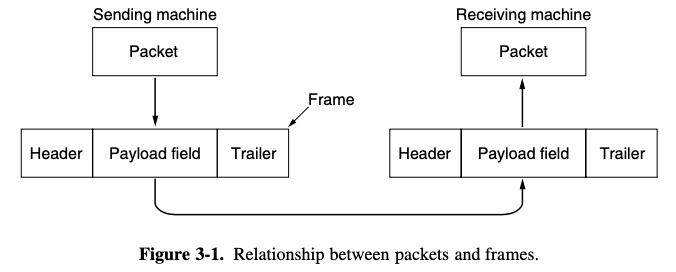
- data link layer takes the packets it gets from the network layer and encapsulates them into frames for transmission
- Each frame contains a frame header, a payload field for holding the packet
3.1.1. Services Provided to the Network Layer
- on the source machine is an entity, call it a process, in the network layer that hands some bits to the data link layer for transmission to the destination
3 reasonable possibilities that we will consider in turn are:
1. Unacknowledged connectionless service
- consists of having the source machine send independent frames to the destination machine without having the destination machine acknowledge them
- if frame is lost due to noise on the line, no attempt is made to detect the loss or recover from it in the data link layer
ex) Ethernet
- No logical connection is established beforehand or released afterward
2. Acknowledge connectionless service
- service is offered, there are still no logical connections used, but each frame sent is individually acknoledged
- sender knows whether a frame has arrived correctly or been lost
- this service is useful over unreliable channels, such as wireless systems, 802.11 (Wifi)
3. Acknowledge connection-oriented service
- the most sophisticated service the datalink layer : provide to the network layer is connection-oriented service
- each frame sent over the connection is numbered
- data link layer gurantees that each frame sent is indeed received
- appropriate over long, unreliable links (ex) stellite channel, long-distnace telephone circuit)
3.1.2. Framing
- the data link layer must use the service provided to it by th phyisical layer
- what the physical layer does is accept a raw bit atream and attempt to deliver it to the destiation
- the bit stream receivved by the data link layer is not guaranteed to be error free
- the usual approach is for the data link layer to break up the bit stream into discrete frames
- compute a short token called a checksum for each frame, and include the checksum in the frame when it is transmitted
find the start of new frames
[1. Byte count]
- use a field in the header to specify the number of bytes in the frame
- count can be garbled by a transmission error
- the frame is bad, it still has no way to telling where the next frame starts
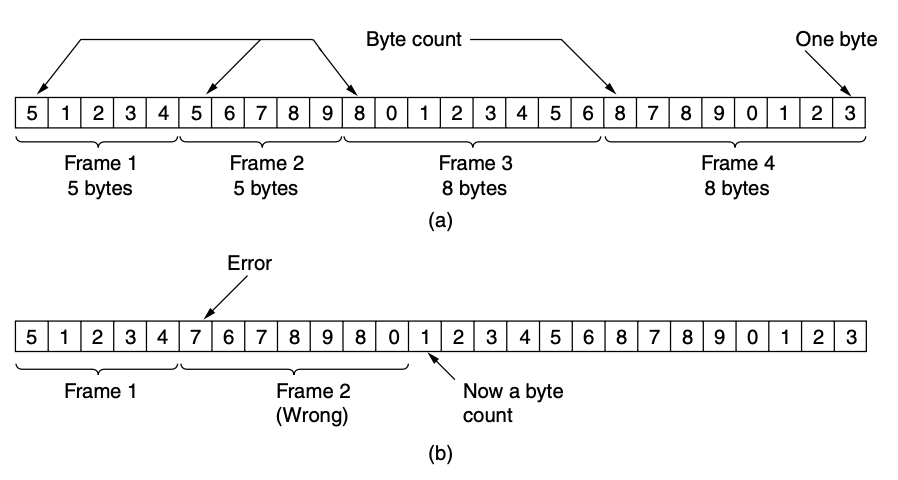
- sending a frame back to the source asking for a retransmission does not help either
- since the destination does not know how many bytes to skip over to get to the start of the retransmission
- this method is rarely used by itself
[2. Flag bytes with byte stuffing]
- resynchronization after an error by having each frame start and end with special delimiter
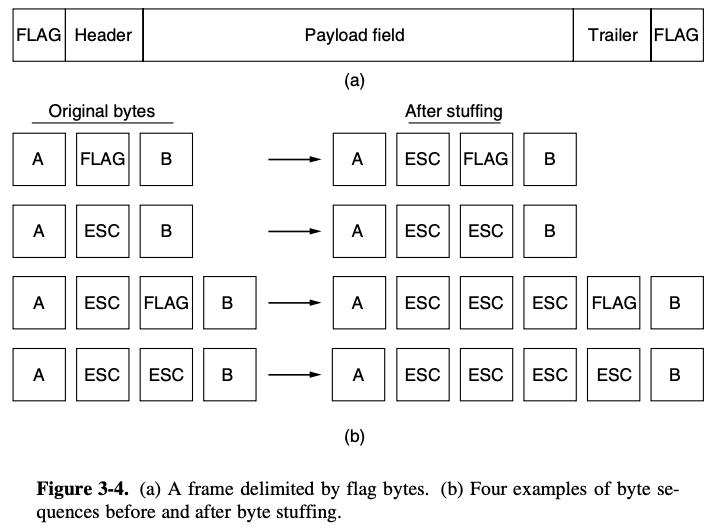
- the same byte, called a flag byte, is used as both the starting and ending delimiter
- the problem will be happend when the flag byte occurs in the data
- have to sender's data link layer insert a special escape byte (ESC) just before each "accidental" flag byte in the data
byte stuffing: the data link layer on the receiving end removes the escape bytes before giving the data to the network layer
[3. Flag bits with bit stuffing]
- disadvantage of byte stuffing (tied to use of 8-bit)
- framing can be also be done at the bit level
- HDLC (High-level Data Link control) protocol
- Each frame begins and ends with a special bit pattern (0x7E)
- this pattern is flag byte
- when ever the sender's data link layer encounters five consecutive 1s in the data, it automatically stuffs a 0 bit into the outgoing bit stream
ex) USB
- when the receiver sees five consecutive incoming 1 bits followed by a 0 bit it automatically destufss the 0 bit
ex) flag pattern : 01111110
this flag is tranmitted as 011111010 but stored in the receiver's memory as 01111110
- with bit stuffing the boundary between two frames can be unambiguously recognized by the flag pattern
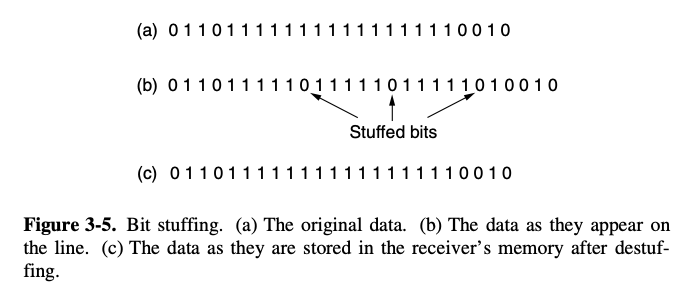
- with both bit and byte stuffing, a side effect is that the length of a frame now depends on the contents of the data is carries
- 100byte might be carried but with bit/byte stuffing the frame will become roughly 200 bytes long
[4. Physical layer coding violations]
- use a shortcut from the physical layer
coding violations: use some reserved signals to indicate the start and end of frames- they are reserved signals it is easy to find the start and end of frames and there is not need to stuff the data
- many data link protocol use a combination of these methods for safety
- common pattern used 802.11 called a preamble
- allow the receiver to prepare for an incoming packet
- followed by a length field in the header that is used to locate the end of the frame
3.1.3. Error control
- usual way to ensure reliable delivery is to provide the sender with some feedback about what is happening at the other end of the line
- receiver to send back sepcial control frames bearin gpositive or negative acknowledgements about the incoming frames
- hardware troubles may cause a frame to vanish completely
- the receive will not react at all, since it has no reason to react
- if the acknowledgement frame is lost, the sender will not know how to preceed
- timer is solution
- when the sender tranmit a frame it generally also starts a timer
- if either the frame or the acknowlegement is lost
- the timer will go off, alerting the sender to a potential problem
- the obvious solution is to just transmit the frame again
- when fames may be transmitted multiple times there is a danger that the receiver will accept the same frame two or more pening
- it is generally necessary to assign sequence numbers to outgoing frames, so that the receiver can distinguish retransmission from originals
whole issue of managing the timers and sequence numbers
3.1.4. Flow Control
- systematically wants to transmit frames faster than the receiver can accept them
[1. feedback-based flow control]
- the receiver sends back information to the sender giving it permission to send more data
- more common these days
- various schemes are known, but most of them use the same basic principle
- well-defined rules about when a sender may transmit the next frame
- these rules often prohibit frames from being sent until the receiver has granted permissions
[2. rate-based flow control]
- built-in mechanism that limits the rate at which senders may transmit data, without using feedback from the receiver
3.2. Error detection and correction
- redundant information to the data that is send
- including enough redundant information to enable the receiver to deduce what the transmitted data must have been
=> error-correcting code = FEC (Forward Error Correction)
- noisy channels : retransmissions are just as likely to be in error as the first transmission
- include only enough redundancy to allow the receiver to deduce that an error has occured and have it request a retransmission
=> error-detecting code
-
highly reliable, such as fiber
-
to avoid undetected errors the code must be strong enough to handle the expected errors
3.2.1. Error-Correcting Codes
- Hamming codes
- Binary convolutional codes
- Reed-Solomon codes
- Low-Density Parity Check codes
- A frame consists of m data bits and r redundant bits
block code: r check bits are computed solely as a function of the m data bitssystematic code: m data bits are sent directly along with the check bitslinear code: r check bits are computed as a linear function of the m data bits
- Let's assume total length of a block be n (n = m + r)
- we will describe this as an
(n, m)code
- An n bit unit containing data and check bits is referred to as an n-bit code word
- code rate : (# of message bits / # of transmission bits)
ex) 10001001, 10110001 (3 bit differ)
- how many bits differ : XOR the 2 codewords, count the 1 bits
Hamming distance
- number of bit positions in which 2 codewords differ
- 2 codewords are a hamming distance d apart
- it will require d single-bit errors to convert one into the other
- error-detecting and error-correcting properties of a block code depend on its Hamming distance
- to reliably detect d errors, you need a distance d + 1 code
- receiver sees an illegal codeword, it can tell that a tramsmission error has occured
- to correct d errors, you need a distance 2d + 1 code
- legal codewords are so far apart that even with d changes the original codeword is still closer than any other codeword
ex) valid codeword : 00, 11 (2 hamming distance)
00 : 2 bit error / correct
01 : 1 bit error / not know 00 or 11
10 : 1 bit error / not know 00 or 11
11 : 2 bit error / correct
ex) valid codeword : 000, 111 (3 hamming distance)
no error : 000 (correct)
1 bit error : 001, 010, 100 (error / assume 0 (correct))
2bit error : 011, 101, 110 (error / assume 1 (wrong))
3 bit error : 111 (no error / assume 1 (wrong))
So
2 hamming distance
- error detection : 1 bit error
- error correction : impossible
3 hamming distance
- error detection : 1-2 bit error
- error correction : 1 bit error
in summary
d hamming distance
- minimum hamming distance for error detection : d + 1
- minimum hamming distance for error correcton : 2d + 1
Hamming code
- the bit s of the codeword are numbered consecutively, starting with bit 1 at the left end, bit 2 to its immediate right and so on
- The bit that are powers of 2 are check bits
- the rest are filled up with the m data bits
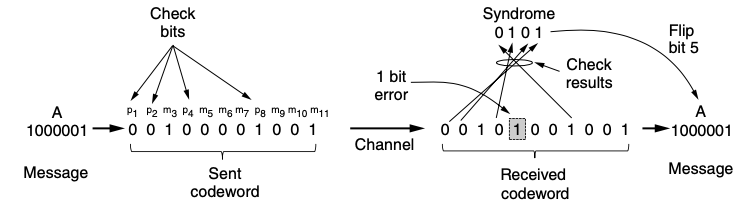
- when the codeword arrives, the receiver redoes the check bit computations including the values of the received bits
parity check
- error detection but no error correction
- reserve one special bit + the rest carry a message
reserve one speical bit
- number of 1's (
even(0)orodd (1))
- do parity check not all the bits, do some part of bits
ex) do the hamming code
initial message

fill up the rest message
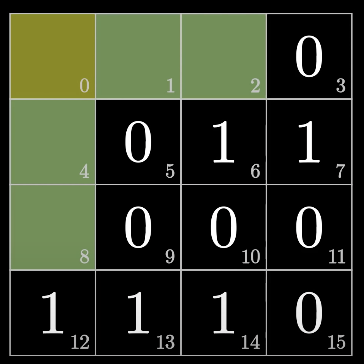
fill up the first bit (even)
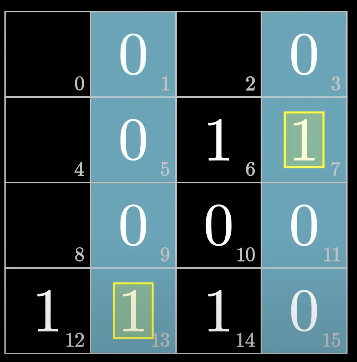
fill up the second bit (odd)
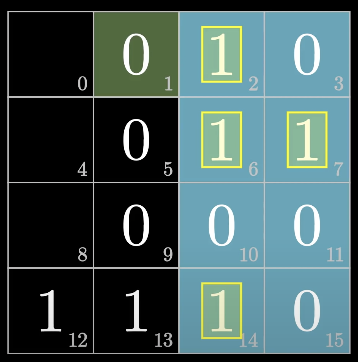
fill up the fourth bit (odd)
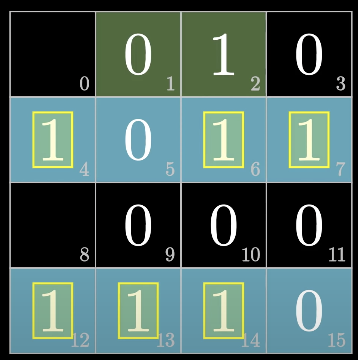
fill up the eighth bit (odd)
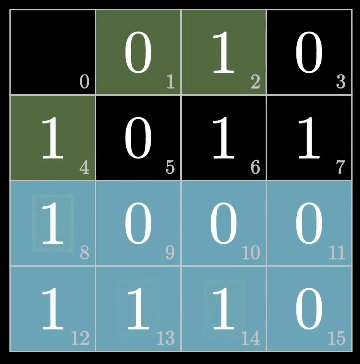
fill up the 0th bit (even)

- if the check results are not all zero, an error has been detected
- the set of check results forms the error syndrome, is used to pinpoint and correct the error
- hamming distances are valuable for understanding block codes, and hamming codes are used in error-correcting memory
- most networks used stronger codes, the second code we will loock at is a convolutional code
convolutional code
- this code is the only one we will cover that is not a block code
- encoder processes a sequence of input bits and generates a sequence of output bits
- the output depends on the current and previous input bits
- encoder has memory
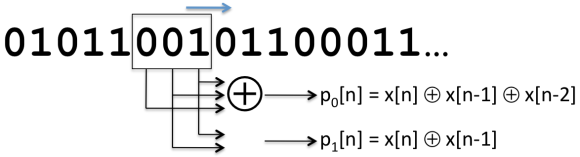
- widely used in deployed networks, in 802.11
Reed-Solomon code
- linear block codes
- based on the fact that every n degree polynomial is uniquely deterined by n+1 points
ex) ax + b is determined by 2 points
- extra points on the same line are redundant, helpful for error correction
ex) CD, DVD, Barcode
- Reed-Solomon codes are often used in combination with other codes, such as convolutional code
LDPC (Low-Density Parity Check)
+) Don't need to know everything in here (ㅎㅎ)
- linear block codes
- each output bit is formed from only a fraction of the input bits
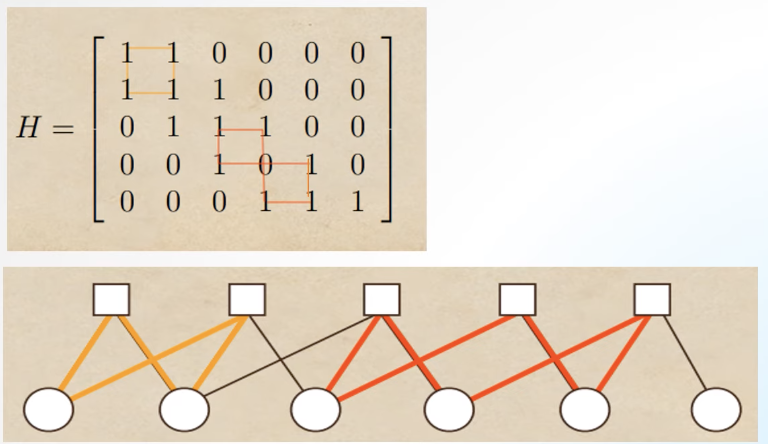
- this leads to a matrix representation of the code that has a low density of 1s
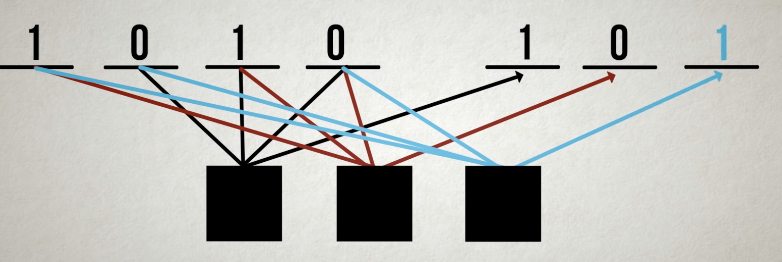
+) definition
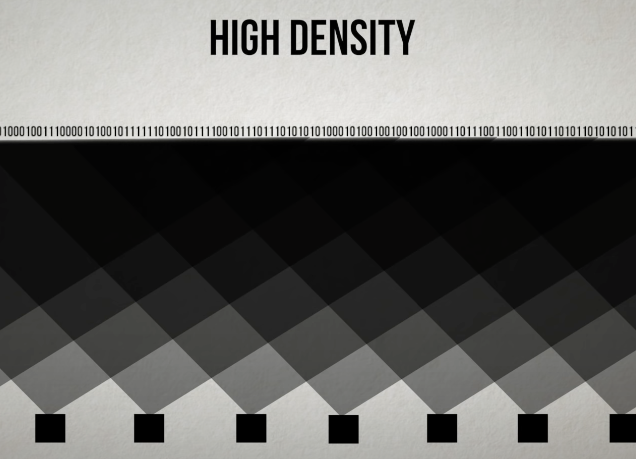
Density: maesursity amount of overlapped, how message bit is connect to the parity check bithigh density: each bits connected to many parity check bits
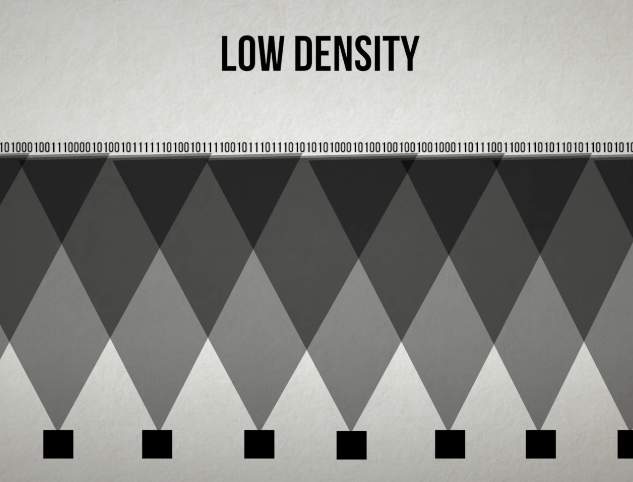
low density: each bits connected to few parity check bits
3.2.2. Error-Detecting Codes
- widely used on wireless links
- over fiber or high-quality copper, the error rate is much lower
- parity
- checksum
- cyclic redundancy check
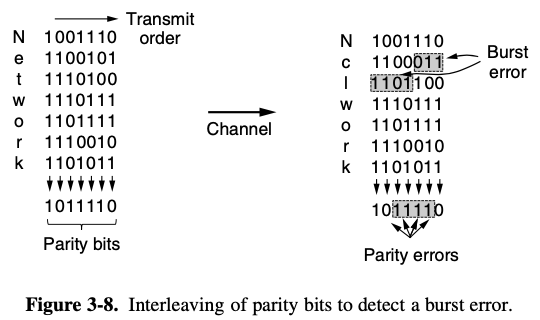
Parity
- i already explain about parity above so skip the description except image
Checksum
- closely related to groups of parity bits
- a group of parity bits is one example of a checksum
- checksum is usually placed at the end of the message
- divide bits on k blocks and sum of that
ex) 10011001, 11100010, 00100100, 10000100
10011001
11100010
00100100
+ 10000100
--------------
1000100011
00100011
+ 10
--------------
00100101
1's complement
=> 11011010CRC (Cyclic Redundancy Check)
= polynomial code
- treating bit strings as representations of polynomials with coefficients of 0 and 1 only
- find the length of the divisor L
- append L-1 bits to the original message
- perform binary division operation
- remainder of the division = CRC
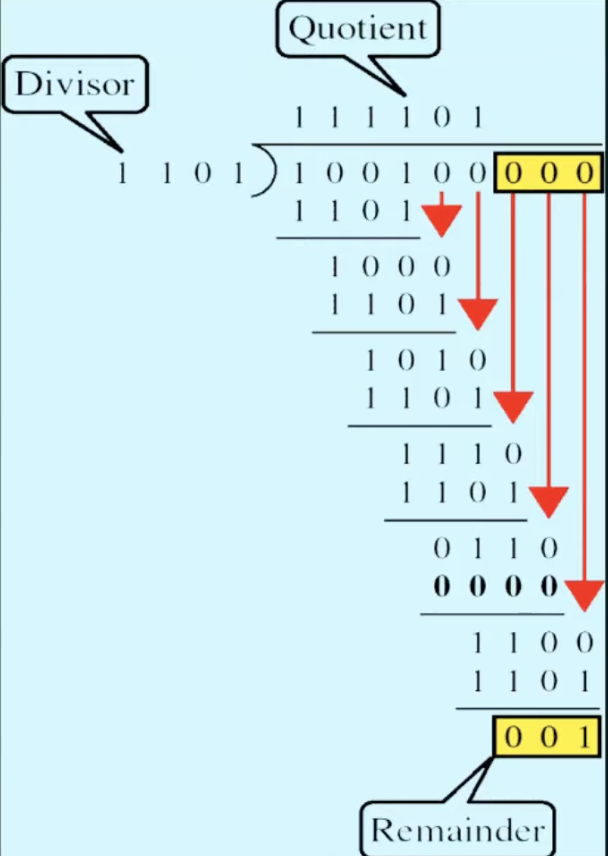
- results :
100100001
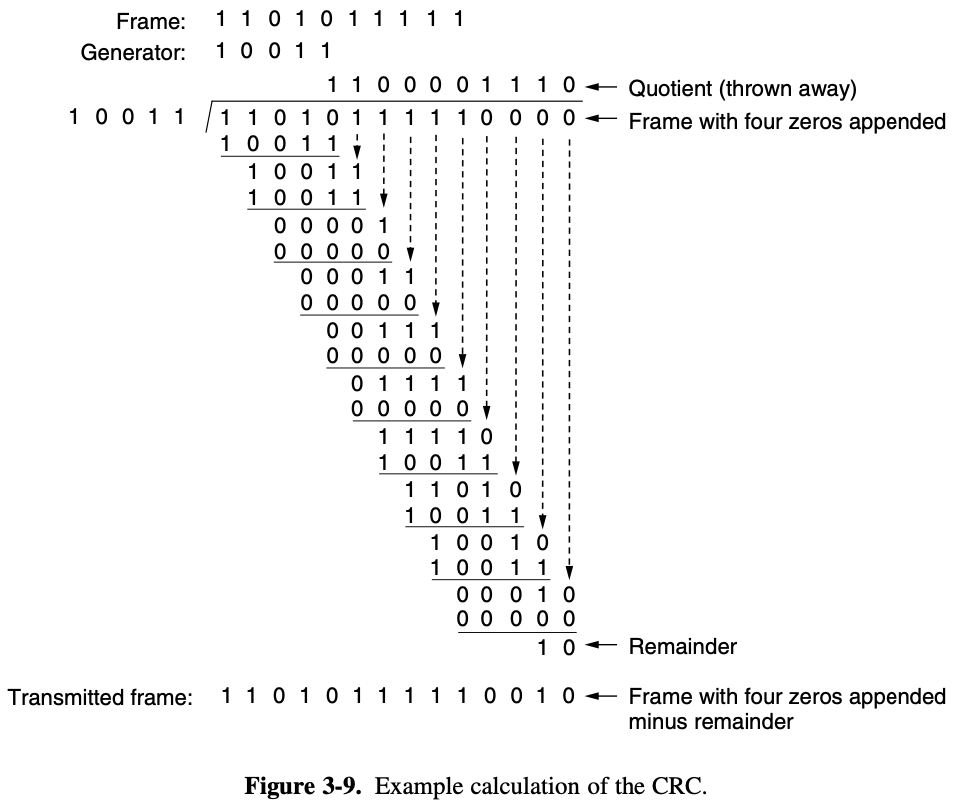
3.3. Elementary data link protocols
- The physical layer process and some of the data link layer process that communicate by passing messages back and forth
- The physical layer process and some of the data link layer process run on dedicate hardware called a NIC (Network Interface Card)
- th rest of the link layer process and the network layer process run on the main CPU as part of the operating system, with the software for the link layer proess often taking the form of a device driver
자세한 설명은 생략한다 (무슨 코드 설명임)
3.4. Sliding window protocols
- in most practical situation, there is a need to transmit data in both directions
- each link is then comprised of a "forward" channel (for data) and a "reverse" channel (for acknowledge)
- use same link for data in both directions
piggy backing
- The acknowledgement is attached to the outgoing data frame
- the technique of temporarily delaying outgoing acknowlegements so that they can be hooked onto the next outgoing data frame
- better use of the available channel bandwidth
- but how long data link layer wait for a packet onto piggyback the acknowledgement?
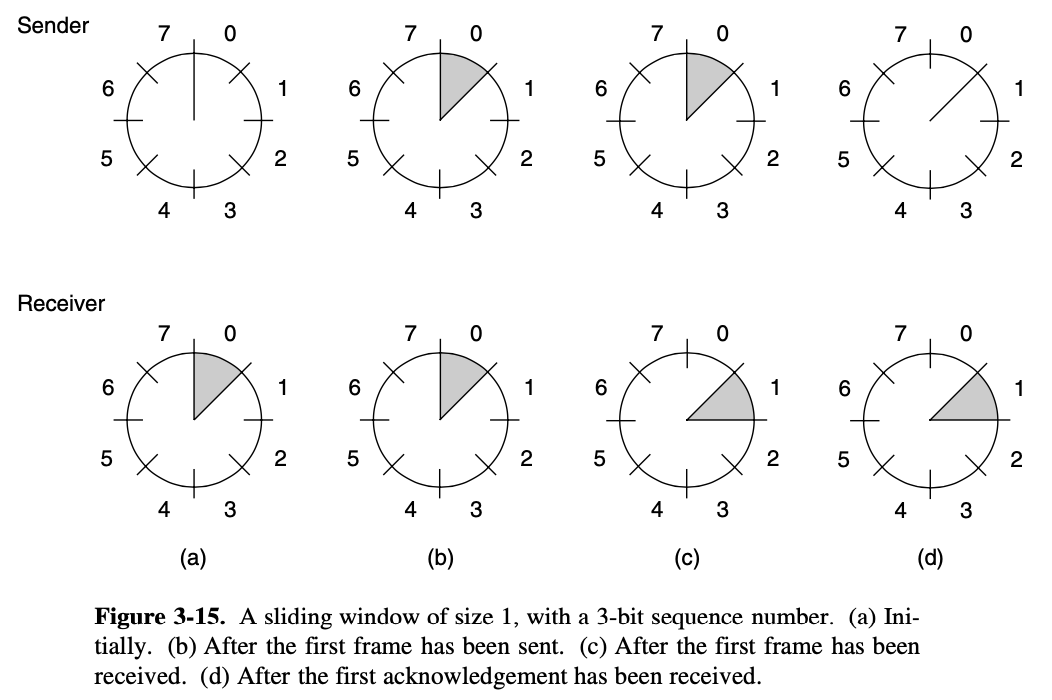
Sliding window
- bidirectional protocols
- any instant of time, the sender maintains a set of sequence numbers corresponding to frames it is permitted to send
- definitely not dropped the requirement that the protocol must deliver packets to the destination network layer in the same order
3.4.2. A Protocol Using Go-Back-N
- until now we didn't discuss about transmission time
- long transit time, high bandwidth, short frame length is disastrous in terms of efficiency
- problem described here can be viewed as a consequence of the rule
- requiring a sender to wait for an acknowledgement before sendig another frame
go-back-N
- the data link layer refuses to accept any frame except the next one it must give to the network layer
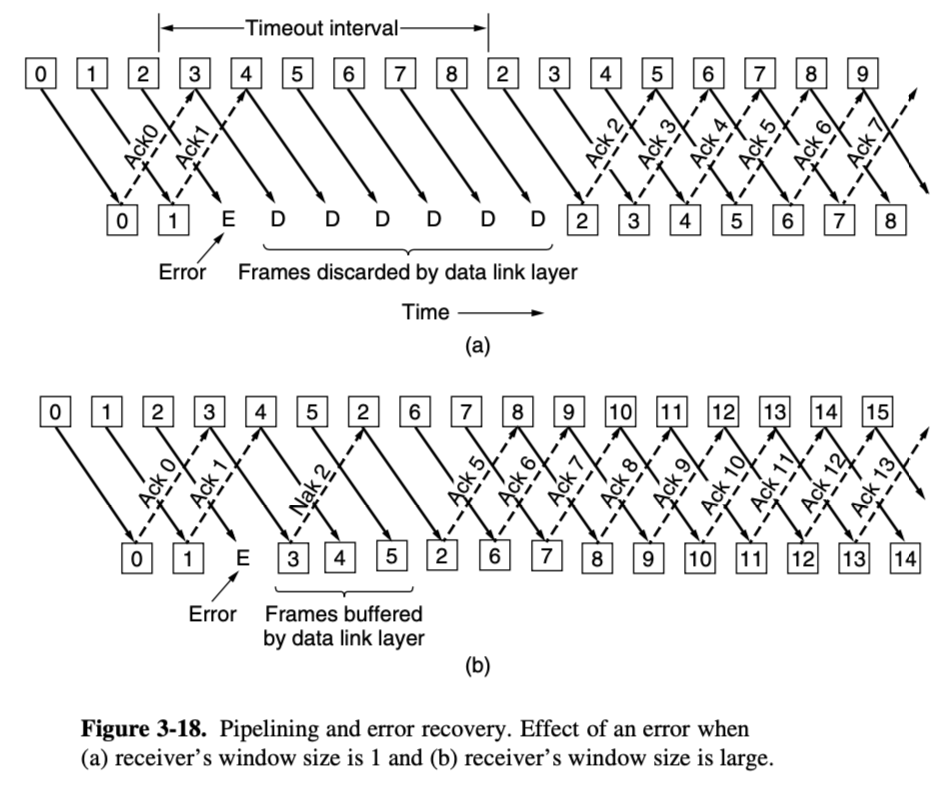
- frame 2 is damaged or lost
- the sender, unaware of this problem, continues to send frames until the timer for frame 2 expires
- then it backs up to frame 2 and start over with it, sending 2,3,4 etc
selective repeat
- when the sender times out, only the oldest unacknowledged frame is retransmitted
- is often combined with having the receiver send a negative acknowledgement when it detects an error
- NAKs simulate retransmission before the corresponding timer expires and thus improve performance
- if NAK should get lost, eventually the sender will time out for frame 2 and send it of its own accord, quite a while later
cummulative acknowledgement
- when an aknowlegement comes in for frame n (n-1, n-2 so on) are also automatically acknowledged
4. The medium access control sublayer
4.1. The channel allocation problem
- how to allocate a single braodcast channel among competing users
4.1.1. Static Channel Allocation
ex) telephone trunk
-
if there are N users, the bandwidth is divided into N equal-sized portions
-
-
however, when the number of senders is large and varying or the traffic is bursty, FDM (Frequency Division Multiplexing) presents some problems
4.1.2. Assumption for Dynamic Channel Allocation
- independent traffic
- single channel
- observable collisions
- continuous or slotted time
- carrier sense or no carrier sense
4.2. Multiple access protocol
4.2.1. ALOHA
Pure ALOHA
- let users transmit whenever they have data to be sent
- if the frame was destroyed, the sender just waits a random amount of time and sends it again
- the waiting time must be random or the same frames will dollide over and over, lockstep
- systems in which multiple users share a common channel in a way that can lead to conflict are known as contention system
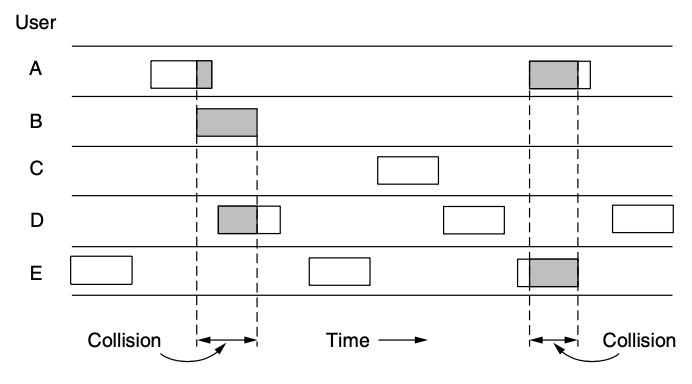
- whenever two frames try to occupy the channel at the same time, there will be collision and both wil be garbled
Slotted ALOHA
- divide time into discrete interval called slots
- each interval corresponding to one frame
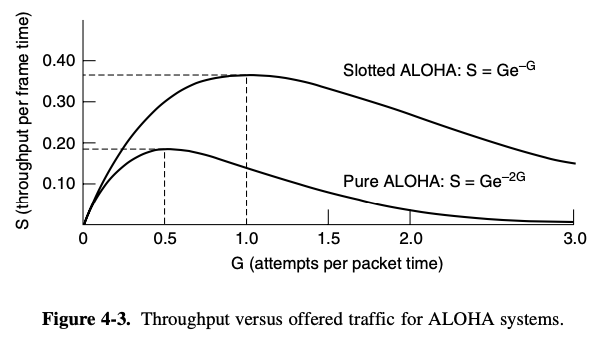
- it is required to wait for the beginning of the next slot
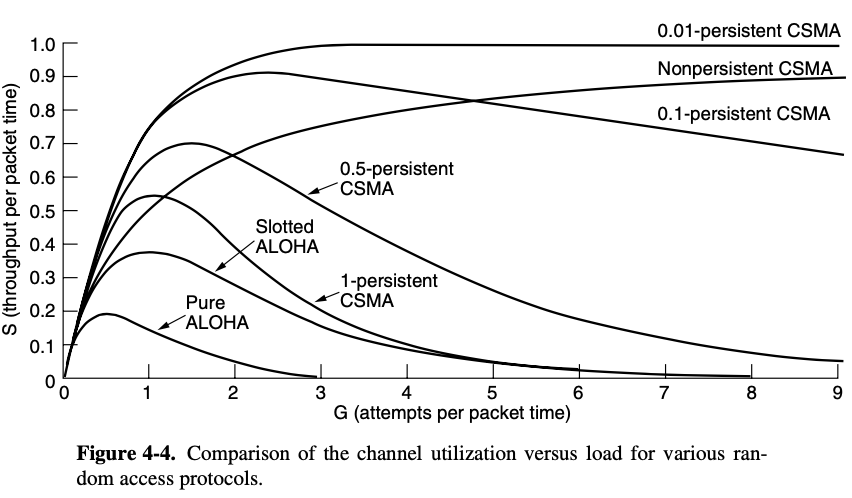
4.2.2. Carrier Sense Multiple Access Protocols
- improving performance than ALOHA
Persistent and Nonpersistent CSMA
- 1-persistent CSMA (Carrier Sense Multiple Access)
- simplest CSMA schema
- station transmits with a probability of 1 when it finds the channel idle
- when a station has data to send, it first listens to the channel to see if anyone else is transmitting at that moment
- if the chennel is idle, the stations sends its data
- if a collision occurs, the station waits a random amount of time and starts all over again
nonpersistent CSMA
- less greedy than in the previous one
- if the channel is already in use, the station does not continually sense it for the purpose of seizing it immediately upon detecting the end of the previous transmission
- instead it waits a random period of time and then repeats the algorithm
p-persistent CSMA
- when a station becomes ready to send, it sense the channel
- if it is idle, it transmits with a probability p
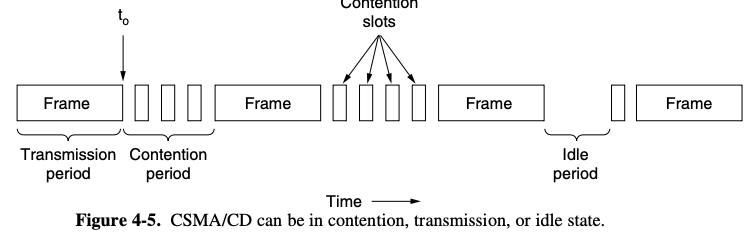
- important to realize that collision detection is an analog process
- worth devoting some time to looking as CSMA/CD in detail
CSMA with Collision Detection (CSMA/CD)
- basis of the classic Ethernet LAN (data-link : switch, hub)
- if a station detects a collision, it aborts its transmission, waits a random period of time and then tries again
4.2.3. Collision-Free Protocols
A Bit-Map Protocol
- basic bit-map method : each contention period consists of exactly N slots
- the essence of the bit-map protocol is that it lets every station transmit a frame in turn in a predefined order
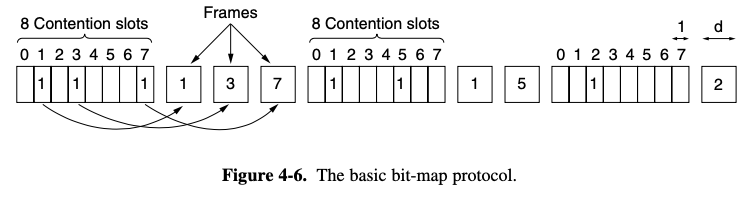
- if station 0 has frame to send, it transmit a 1 bit during the slot 0
- no other station is allowed to transmit during this slot
- regardless of what station 0 does, station 1 gets the opportunity to transmit a 1 bit during slot 1
- the desire to transmit is braodcast before the actual transmission are called reservation protocol
token passing
- small message called token from one station to the next in the same predefined order
- the token represents permission to send
token ring protocol
- network is used to define the order in which stations send
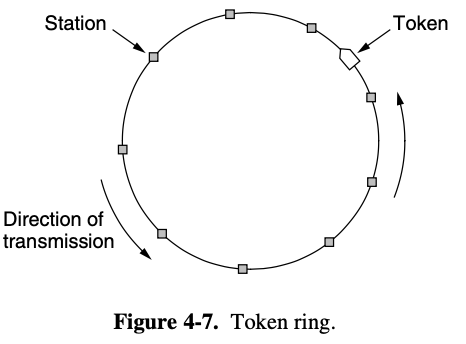
- this protocol is called token buse
- the performace of token passing is similar to that of the bit-map protocol
- after sending a frame each station must wait for all N stations
- Token rings have cropped up as MAC protocols with some consistency
- a much faster token ring called FDDI (Fiber Distributed Data Interface)
- standarize the mix of metropolitan area rings in use by ISPs RPR (resilient Packet Ring)
Binary Countdown
- a problem with the bit-map protocol and token passing, is that the overhead is 1 bit per station
- we can do better than by using binary station addresses
- to avoid conflicts, an arbitration rule must be applied
- a station sees that a high-order bit position that is 0 in its address has been overwritten with 1, it give up
ex) if stations 0010, 0100, 1001, 1010
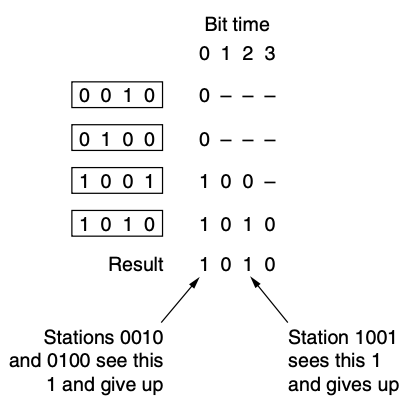
- binary countdown is an example of a simple, elegant and efficient protocol that is waiting to be rediscovered
- hopefully it will find a new home some day
4.2.4. Limited-Contention Protocol
- used contention and collision-free protocols, arriving at a new protocol that used contention at low load to provice low delay
- but used a collison-free technique at high load to provide good channel efficiency
- the trick is how to assign stations to slots
- what we need is a way to assign stations to slots dynamically
the adpative tree walk protocol
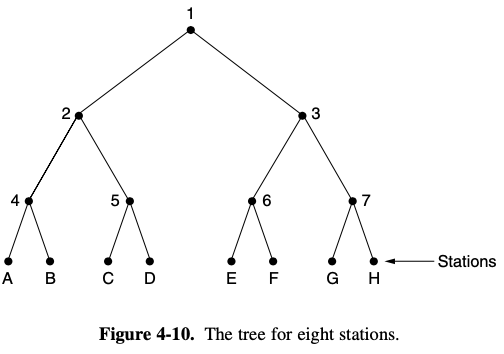
- 그중 노드 0에서 성공적인 전송이 이루어지면 첫 번째 경쟁 슬롯 0에서 모든 스테이션들의 채널 점유가 시도가 허락된다.
- 모든 스테이션 중 하나의 전송이 성공하면 노드상에 문제가 없는 것이고 만약 충돌이 일어나면 트리구조에서 노드 1 밑으로 내려가는 스테이션들 즉 왼쪽 우선순위에 의해 경쟁이 일어난다.
- 노드 1에서만 경쟁이 일어나지 않고 2에서도 동시에 경쟁이 일어난다면 결국 충돌이 일어날 확률은 슬롯 0과 같아지게 된다.
- 이는 어느 스테이션에서 문제가 발생했는지 오류 검출이 어려워지며 노드 활용의 효율성도 낮아지는 결과를 가져온다.
- 이러한 문제를 해결하기 위한 방법으로 ATW Protocol을 사용하게 되었다.
4.2.5. Wireless LAN Protocols
- A system of laptop computers that communicate by radio can be regarded as a wireless LAN
- an office building with access points (APs) strategically placed around the building
important difference between wireless LANs and wired LANs
- wireless LAN may not be able to transmit frames to or receive frames from all other stations
- limited radio range of the stations
- A naive approach to using a wireless LAN might be to try CSMA
- just listen for other transmission and only transmit if no one else is doing so
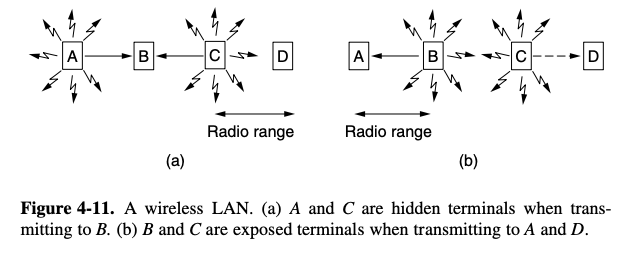
[first consider : A, C transmit to B]
- if A send and then C immediately sense the medium, it will not hear A because A is out of range
- C will falsely conclude that it can transmit to B
- if C dose start transmitting, it will interfere at B, wiping out the frame from A
- the problem of collision from happening because it competitor for the medium
- because the competitor is too far away is called the hidden terminal problem
[second consider : B transmitting to A, at the same time that C want to transmit to D]
- if C sense the medium , it will hear a transmission and falsely conclude that it may not send to D
- In fact, such a transmission would cause bad reception only in to zone between B, C, where neither of the intended receivers is located
- exposed terminal problem
- the difficulty is that
before starting a transmission, a station really want to know whether there is radion activity around the receiver
MACA (Multiple Access With Collision Avoidance)
- ealry influential protocol
[basic idea]
- sender to stimulate the receiver into outputting a short frame,
- so stations nearby can detect this transmission
- avoid transmitting for the duration of the upcoming data frame
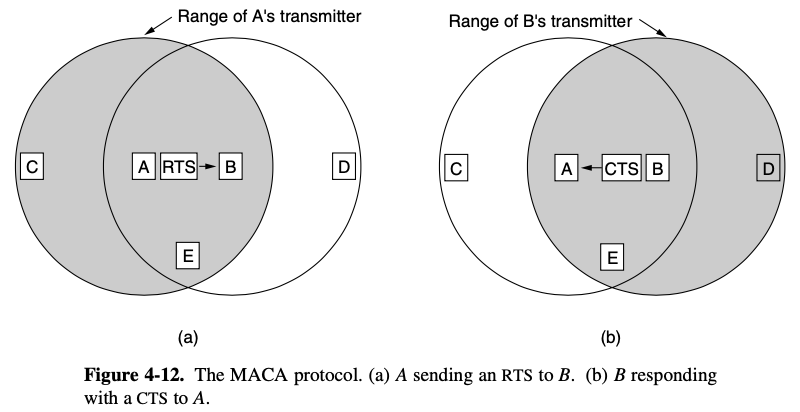
- A starts by sending an RTS (Request To Send) frame to B
- B replies with a CTS (Clear To Send) frame
- receipt of the CTS frame, A begins transmission
- C is Within range of A but not within range of B
- it hears the RTS from A but not the CTS from B
- D is within range of B but not A
- it does not hear the RTS but does hear the CTS
- hearing CTS tips it off that it is close to a station that is about to receive a frame
- so it defers sending anything until that frame is expected to be finished
- E hears both control message and like D, must be silent until the data frame is complete
- Despite these precautions, collisions can stil occur
- in the event of a collision, an unsuccessful transmitter waits a random amount of time and tries again later
4.3. Ethernet
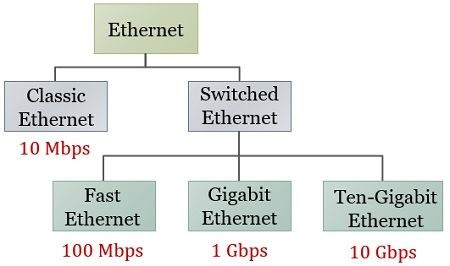
[2 kind of Ethernet exist]
classic Ethernet
- solves the multiple access problem using the techniques
- original form and ran at rates from 3 to 10 Mbps
switched Ethernet
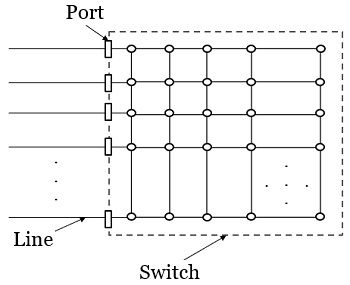
- devices called switches are used to connect different computers
- Ethernet has become and runs at 100, 1000, 10000 Mbps
only switched Ethernet is used nowadays
4.3.1. Classic Ethernet Physical Layer
- snaked around the building as a single long cable to which all the computers were attached
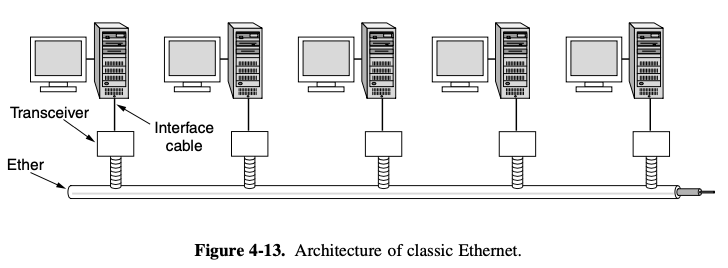
- to allow larger networks, multiple cables can be connected by
repeaters - physical layer device that receive, amplifies, and retransmit signals in both directions
4.3.2. Classic Ethernet MAC Sublayer Protocol
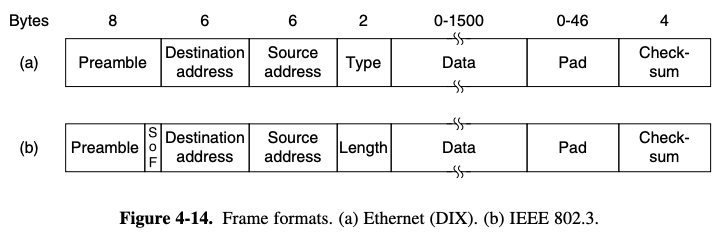
multicasting: sending to a group of stations, more selectivebraodcasting: 1 bits is reserved, accepted by all stations on the network
CSMA/CD with Binary Exponential Backoff
- use 1-presistent CSMA/CD algorithm
- binary exponential backoff : chosen to dynamically adapt (0 and 2^i -1 (i = collision number)) to the number of stations trying to send
- after 10 collision have been reached, the randomization interval is frozen at a maximum of 1023 slots
- average wait after a collision would be hundereds of slot times, introducing significant delay
4.3.4. Switched Ethernet
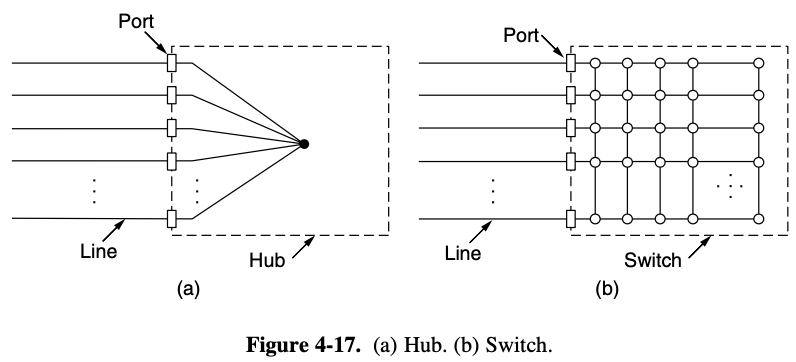
hubsdo not increase capacity because they are logically equivalent to the single long cable of classic Ethernet- As more and more stations are added, each station gets a decreasing share of the fixed capacity
- the heart of
switchsystem is a switch containing a high-speed backplane that connects all of the prots
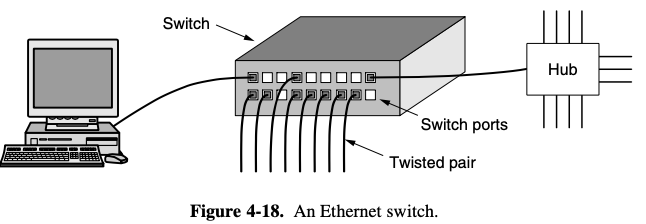
- when a switch port receives an Ethernet frame from a station
- the switch checks the Ethernet addresses to see which port the frame is destined for
- switch knows the frame's destination port
what happens if more than one of the stations or ports wants to send a frame at the same time?
- in a hub, all stations are in the same collision domain
- the must use CSMA/CD algorithm to schedule their transmissions
- in a switch, each port is its own independent collision domain
- cable is a full duplex (station, port can send a frame at the same time)
- collision are now impossible and CSMA/CD is not needed
[Switch improves performance]
- no collisions
- multiple frames can be sent simultaneously
[Change in the ports]
- have security benefis
- most LAN interfaces have a promiscuous mode
- all frames are given to each computer, not just those addressed to it
- with a hub, every computer that is attached can see the traffic sent between all of the other computers
- Spies and hackers will love it
- with a switch, traffic is forwarded only to the ports where it is destined
- the restriction provides better isolation so that traffic will not easily escape and fall into the wrong hands
4.4. Wireless LANS
4.4.1. The 802.11 Architecture and Protocol Stack
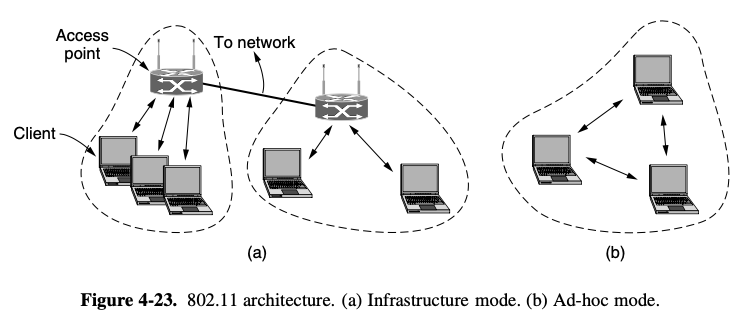
[2 mode]
- AP (Access Point)
- each client is associated with an AP (Access Point), is in turn connected to the other network
- the client sends and receives its packets via the AP
- serveral access points may be connected together, typically by a wired network called a distribution system
- ad hoc neetwork
- collection of computers that are associated so that they can directly send frames to each other
- no access point, not very popular
802.11 관련 설명이 정말 길게 나오지만 나는 알고 싶지도, 정리하고 싶지도 않음
4.4.5. Services
association service
- used by mobile station to connect themselves to APs
- it is used just after a station moves within radio range of the AP
- upon arrival, the station learns the identity and capabilities of the AP
- either from beacon frames or by directly asking the AP
reassociation service
- let a station change its preferred AP
- facility is useful for mobile stations moving from one AP to another AP
-in the same extended 802.11 LAN, like a handover in the cellular network
- stations must also authenticate before they can send frames via the AP
- but authentication is handled in different ways depending on the choice of security scheme
WPA2
- The recommended scheme, called WPA2 (Wifi Protected Access 2)
- with WPA2, the AP can talk to an authentication server that has a username and password database to determine if the station is allowed to access the network
WEP (Wired Equivalent Privacy)
- the schema that was used before WPA
- authentication with a preshared key happens before association
- software to crack WEP passwords is now freely available
- wireless is a broadcast signal
- for information sent over a wireless LAN to be kept confidential, it must be encrypted
- the encryption algorithm for WPA2 is based on AES (Advanced Encryption Standard)
- To handle traffic with different priorities, there is a QOS traffic scheduling service
- transit power control : gives stations the information they need to meet regulatory limits on transmit power that vary from region to region
- dynamic frequency selection : give stations the information they need to avoid transmitting on frequencies in 5-GHz band
4.5. Braodband wireless
- IEEE 802.16, WiMAX (Worldwide Interoperability for Microwave Access)
4.5.1. Comparison of 802.16 with 802.11 and 3G
-
WiMax
= 802.11 (wirelessly connecting devices to the internet) + 3G
= 4G -
802.16 was designed to carry IP packets over the air and to connect to an IP-based wired network with a minimum of fuss
-
The packets may carry peer-to-peer traffic, VoIP calls, or streaming media to support a range of applications
- WiMAX is more like 3G
- WiMAX base stations are more powerful than 802.11 AP
- To handle weaker signals over larger distances
- 4G = LTE (Long Term Evolution)
3G cellular network: based on CDMA and suppor voice and data4G cellular network: based on OFDM with MIMO (target data, with voice as just one application)
4.5.2. The 802.16 Architecture and Protocol Stack
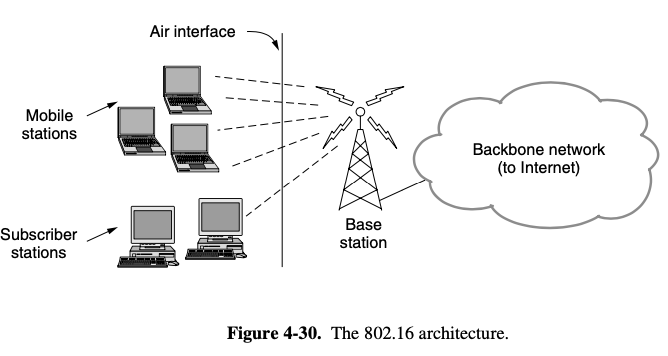
- base stations connect directly to the provider's backbone network
- base stations communicate with stations over the wireless air interface
subscriber station: a fixed locatio (ex) broadband internet access for homes)mobile station: receive service while they are moving (ex) WiMAX)
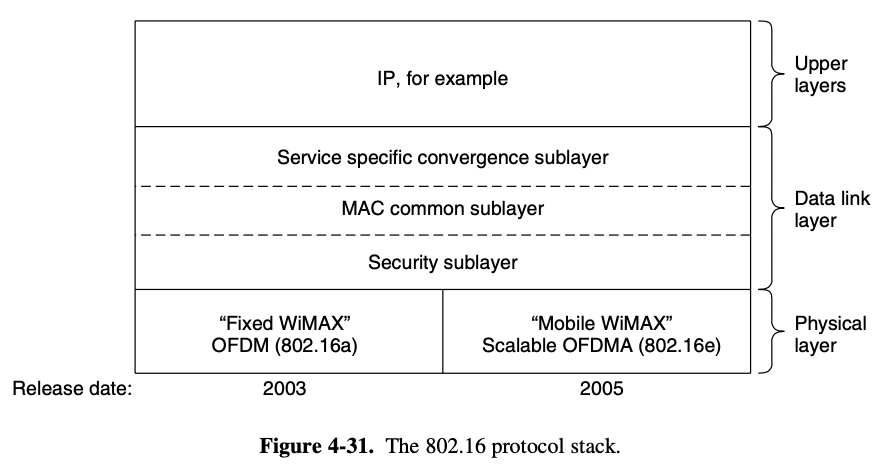
여기도 마찬가지로 802.16 에 대해 최선을 다해 설명하고 있지만, 듣고 싶지 않음
4.6. Bluetooth
- Bluetooth protocols let these devices find and connect to eah other an act called pairing, and securely transfer data
4.6.1. Bluetooth Architecture
- piconet : consists of a master node and up to seven active slave nodes with in a distance of 10 meters
- multiple piconets can exist in the same room
- can event be connected via a bridge node that takes part in multiple pinconets
- interconnected connection of pinconets : scatternet
- 7 active slave nodes in pinconet can be up to 255 parked nodes in the net
- devices that master has switched to a low power state to reduce the drain on their batteries
- in parked state, a device cannot do anything except respond to an activation or beacon signal from the master
- 2 intermediate power state : hold & sniff
- the reason for the master/slave design : the designer intended to facilitate the implementation of complete Bluetooth chips for under $5
- slaves : fairly dumb, basically just doing whatever the master tell them do
- pinconet is a centralized TDM system : master controlling the clock and determining which device gets to communicate in which time slot
4.6.2. Bluetooth Applications
- Bluetooth SIG specifies particular applications to be supported and provides different protocol stacks for each one
- 25 applications, which are called profiles
- very large amount of complexity
profiles
- 6 of profiles : for different uses of audio and video
- other profiles : for streaming stero-quality audio and video (ex) portable music player to headphone)
- hume interface device profile : connecting keyboards and mice to computers
- other profiles : let a mobile phone or other computer receive images from a camera or send images to a printer
- for more interest is a profile to use a mobile phone as a remote control for a (Bluetooth-enabled) TV
- still other profiles (ㅋㅋㅋ) : enable networking (ad hoc network or remotely access another network, via access point)
- we will skip the rest of the profiles
4.6.3. The Bluetooth Protocol Stack
- many protocols grouped loosely into the layer
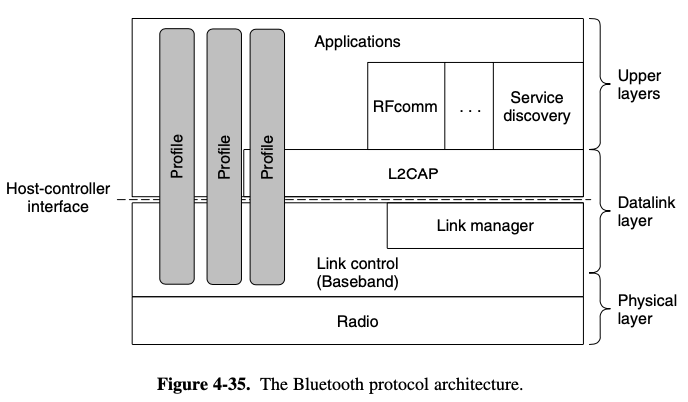
bottom layer
- physical radio layer > radio transmission and modulation
link control
- analogous to the MAC sublayer, includes elements of the physical layer,
- how the master controls time slot and how these slots are grouped into frames
- 2 protocols that use the link control protocol
- the link manager handles the establishment of logical channels between devices
ex) power management, pairing, encryption etc - it lies below the host controller interface line
L2CAP (Logical Link Control Adaptation Protocol)
- link protocol above the line
- frames variable-length messages and provides reliability if needed
- many protocols use L2CAP
- the service discovery protocol is used to locate services within the network
RFcomm (Radio Frequency communication)
- emulates the standard serial port found on PCs for connecting the keyboard, mouse and modem among other devices
top layer
- applications are located
- profiles are represented by vertical boxes
- they each define a slice of the protocol stack for a particular purpose
4.6.4. The Bluetooth Radio Layer
- radio layer moves the bits from master to slave (vice versa)
- low-power system with a range of 10 meters operating
- the band is divided into 79 channels of 1 MHz each
- To coesist with other networks using the ISM band
adaptive frequency hopping
- bluetooth to adapt its hop sequence to exclude channels on which there are other RF signals
4.6.5. The Bluetooth Link Layers
- closest thing Bluetooth has to a MAC sublayer
- it turns the raw bit stream into frames, defines some key formats
secure simple pairing
- enables users to confirm the both devices are displaying th same passkey
- or to observe the passkey on one device and enter it into the second device
- once pairing is complete, the link manager protocol sets up the links
2 main kind of links exist to carry user data
- SCO (Synchronous Connection Oriented) link
- real-time data (ex) telephone connections)
- fixed slot in each direction
- ACL (Asynchronous ConnectionLess) link
- used for packet-switched data (available irregular intervals)
- frames can be lost and may have to retransmitted
the data sent over ACL links com from the L2CAP layer
L2CAP layer
- accept packets of up to 64KB from the upper layers and breaks them into frame for transmission
- handles the multiplexing and demultiplexing of multiple packet sources
- handles error control and retransmission
- enforce quality of service requirements between multiple links
4.7. RFID (Radio Frequency IDentification)
4.7.1. EPC Gen 2 Arcihtecture
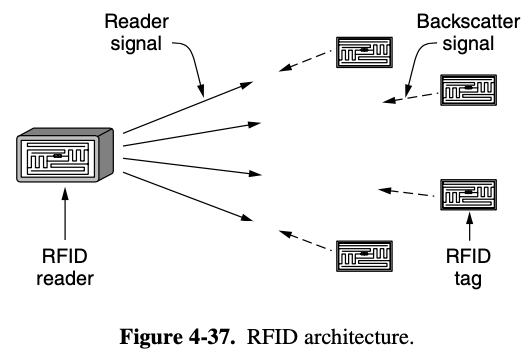
- tags & readers
- RFID tags are small, inexpensive devices
- have unique 69-bit EPC identifier and a small amount of memory that can to read and written by the RFID reader
- memory might be used to record the location history of an item
- the tags look like stickers that can be placed on
- most of the sticker is taken up by an antenna that is printed onto it
- a tiny dot in the middle is the FRID intergrated circuit
- the RFID tags can be integrated into an object
- no battery and must gather power from the radio transmission of a nearby RFID reader to run
- the readers are the intelligence in the system
- analogous to base stations and access points in cellular and WiFi networks
- Readers are much more powerful than tags
- they have thier own power source, often have multiple antennas
- incharge of when tags send and receive messages
- main job of the reader is to inventory the tags in the neighborhood
- discover the identifers of the nearby tags
4.7.2. EPC Gen 2 Physical Layer
- reader is always transmitting a signal (regardless of whether it is the reader or tag that is communicating)
- for the tags to send bits to the reader
- the reader transmit a fixed carrier signal that carries no bits
- tag harvest this signal to get the power they need to run
- to send data, a tag changes whether it is reflecting the signal from the reader
- backscatter
backscatter
- sender and receiver never both transmit at the same time
- low-energy way for the tag to create a weak signal of its own, that shows up at the reader
- for the reader to decode the incoming signal
- it must filter out the outgoing signal that it is transmitting
- tag that runs on very little power and costs only a few cents to make
- to send data to the tags
- the reader uses 2 amplitude levels
- bits are determined to be either 0 or 1
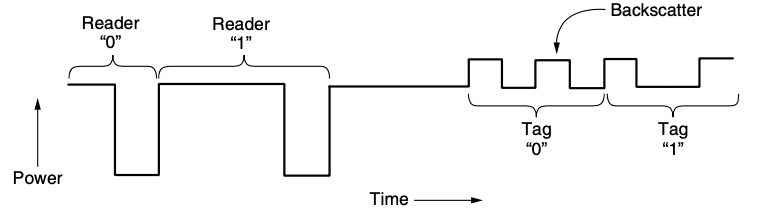
- tag responses consist of the tag alternating its backscatter state at fixed intervals to create a series of pulses in the signal
- 1s have fewer transitions than 0s
4.7.3. EPC Gen 2 Tag Identification Layer
- reader needs to receive a message from each tag that gives the identifier for the tag
- the reader might broadcast a query to ask all tags to send their identifiers
- tags that replied right away would then collide
- in which the tags cannot hear each other's transmissions
Gen 2 RFID
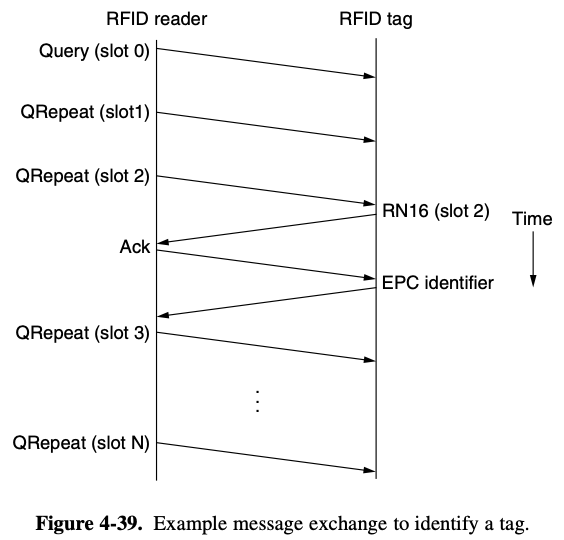
- reader send a query message to start the process
- each Qrepeat message advances to the next slot
- reader also tells the tags the range of slot over which to randomize transmission
- using a range is necessary because the reader synchronizes tags when it starts the process
- tag pick a random slot in which to reply
- tag replies in slot
- tags do not send their identifier when they first reply
- instead a tag send a short 16 bit random number in an RN16 message
- if there is no collisions, the reader receives this message and send an ACK message of its own
- at this stage the tag has acquired the slot and send its EPC identifier
+) Why send identification later?
- EPC identifier are long
- collision on these messages would be expensive
- identifier has been successfully transmitted
- tag temporarily stops responding to new Query messages so that all the remaining tags can be identified
key problem
- reader to adjust the number of slots to avoid collisions
- performance suffers
- if the reader sees too many slots with collisions
- it can send a QAdjust message to decrease or increase the range of slots over which the tags are responding
4.8. Data link layer switching
- connect multiple LANs
bridge
- operate data link layer
- examine the data link layer addresses to forward frames
4.8.1. Use of Bridges
- buy bridge, plug the LAN cables into the bridges and have everything work perfectly
2 algorithms are used
1. a backward learning algorithm : stop traffic being sent where it is not needed
2. a spanning tree algorithm : to break loops
4.8.2. Learning Bridge
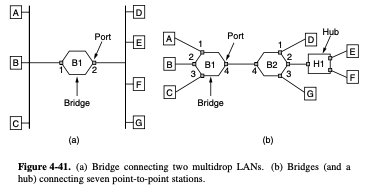
- left hand side : classic Ethernets
- rgiht hand side : point-to-point cables
- if there is more than one station, as in a classic Ethernet, hub, or a half-duplex link, the CSMA/CD protocol is u sed to send frames
- Each bridge operates in promiscuous mode
- it accepts every frame transmitted by the stations attached to each of its ports
- the bridge must decided whether to forward or discard each frame
- this decision is made by using the destination address
- A simple way to implement this scheme is to have a big hash table inside the bridge
- table can list each possible destination and which output port it belongs on
backward learning
- when the bridges are first plugged in, all the hash tables are empty
- As time goes on, the bridge learn where destinations are
- Periodically, a process in the bridge scan the hash table and purges all entries more than a few minutes old
- if the port for the destination address is the same as the source port, discard the frame
- if the port for the destination address and the source port are different, forward the frame on to the destination port
- if the destination port is unknown, use flooding and send the frame on all ports except the source port
cut-through switching / wormhole routing
-
as each frame arrives, usually implemented with special-purpose VLSI chips
-
the chip do the lookup and update the table entry
-
bridge only look at the MAC addresses to decide how to forward frames
-
it is possible to start forwarding as soon as the destination header field has come in
-
this design reduces the latency of passing through the bridge
-
as well as the number of frames that the bridge must be able to buffer
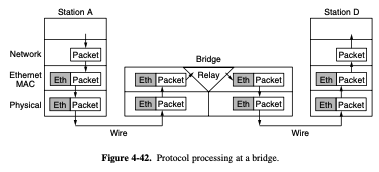
- relay at a given layer can rewrite the headers for that layer
4.8.3. Spanning Tree Bridges
- to increase reliability, redundant links ca be used between bridges
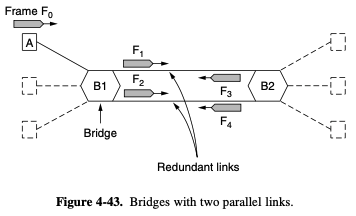
- there are 2 links in parallel between a pair of bridges
- the network will not be partitioned into 2 sets of computers that cannot talk to each other
- however this redundancy introduces some additional problems, it create loops in the topology
- some potential connections between bridges are ignored in the interest of construction a fictitious loop-free topology that is a subset of the actual topology
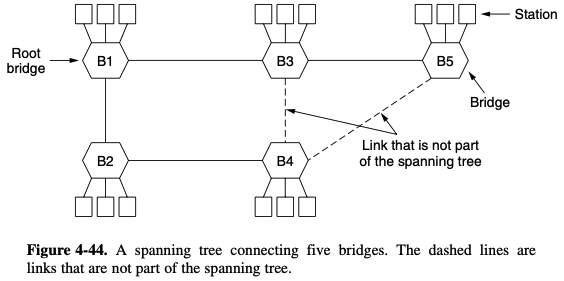
- to build the spanning tree, the bridges run a distributed algorithm
- each brdige periodically broadcasts a configuration message out all of its ports to its neighbors and processes the message it receives from other bridges
Spanning Tree algorithm 은 나중에 배우세요
4.8.4. Repeaters, Hubs, Bridges, Switches, Routers and Gateways
Physical Link Layer
Repeaters
- analog devices that work with signals on the cables to which they are connected
- do not understand frames, packets, or headers
- understand the symbols that encode bits as volts
- classic ethernet was designed to allow 4 repeaters
hubs
- a number of input lines that it join electrically
- arriving on any of the lines are sent out on all the others
- do not amplify the incomming signals
Data link layer
bridge
- intended to be able to join different kinds of LANs
- 2 or more LANs like a hub, a modern bridge has multiple ports, usually enough for 4 to 48 input lines of a certain type
- each port is isolated to be its own collision domain
- when a frame arrives, the bridge extracts the destination address from the frame header and looks it up in a table to see where to send the frame
- For ethernet this address is the 48 bit destination address (MAC)
switches
- modern bridges by another name
- bridge were developed when classic Ethernet was in use
- so they tend to join relatively few LANs and thus have relatively few ports
- mordern installations all use point-to-point links
4.8.5. Virtual LANs
- network administrators like to group users on LANs to relect the organizational structure rather than physical layout of the building
+) broadcast storm
- entire LAN capacity is occupied by these frames
- all the machines on all the interconnected LANs are cripples just processing and discarding all the frames being broadcast
VLAN (Virtual LAN)
- IEEE 802
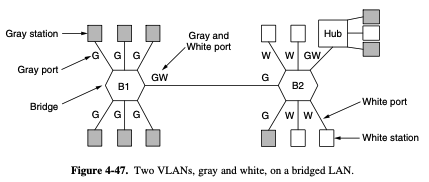
+) Often the VLANs are informally named by colors
- to make the VLANs function correctly, configuration tables have to be set up in the bridges
- these tables tell which VLANs are accessible via which ports
The IEEE 802.1Q standard 읽어보시길
5. The Network Layer
5.1. Network Layer Design Issues
5.1.1. Store-and-Forward Packet Switching
- major components of the network are the ISP's equipment (router connected by transmission lines)
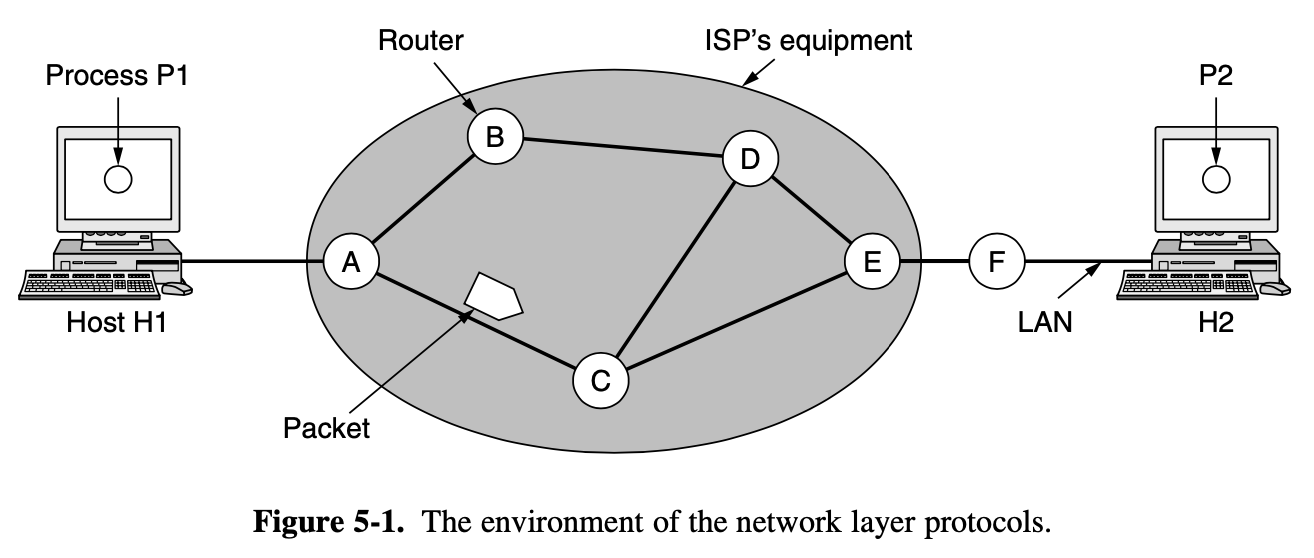
- A host with a packet to send transmit it to the nearest router, either on its own LAN or over a point-to-point link to the ISP
- The packet is stored there until it has fully arrived and the link has finished its processing by verifying the checksum > stop
- Then it is forwarded to the next router along the path until it reaches the destination host, where it is delivered > forward
5.1.2. Services Provided to the Transport Layer
- The services should be independent of the router technology
- The transport layer should be shielded from the number, type and topology of the routers present
- The network addresses made available to the transport layer should use a uniform numbering plan, even across LANs ans WANs
5.1.3. Implementation of Connectionles Service
- packets are injected into the network individually and routed independently of each other
- The packets are frequently called datagrams
- The network called a datagram network
- If connection-oriented service is used
- a path from the source router all the way to the destination router must be established before any data packets can be sent
- This connection is called a VC (Virtual Circuit)
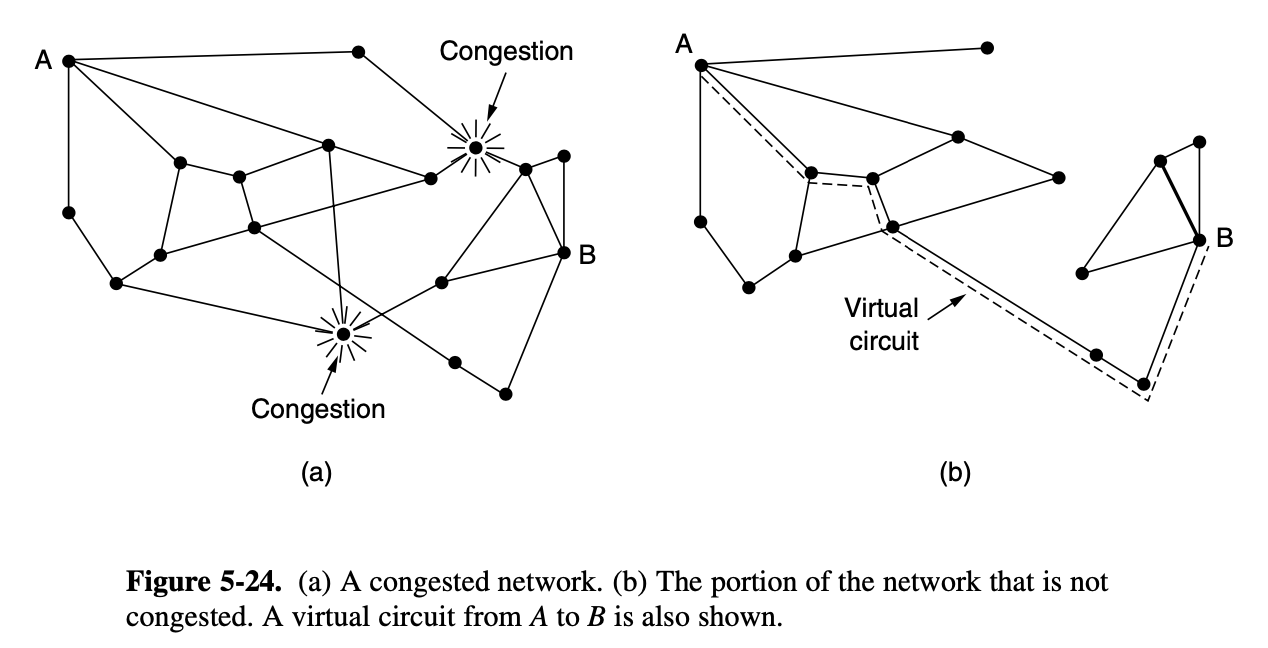
Virtual Circuit network
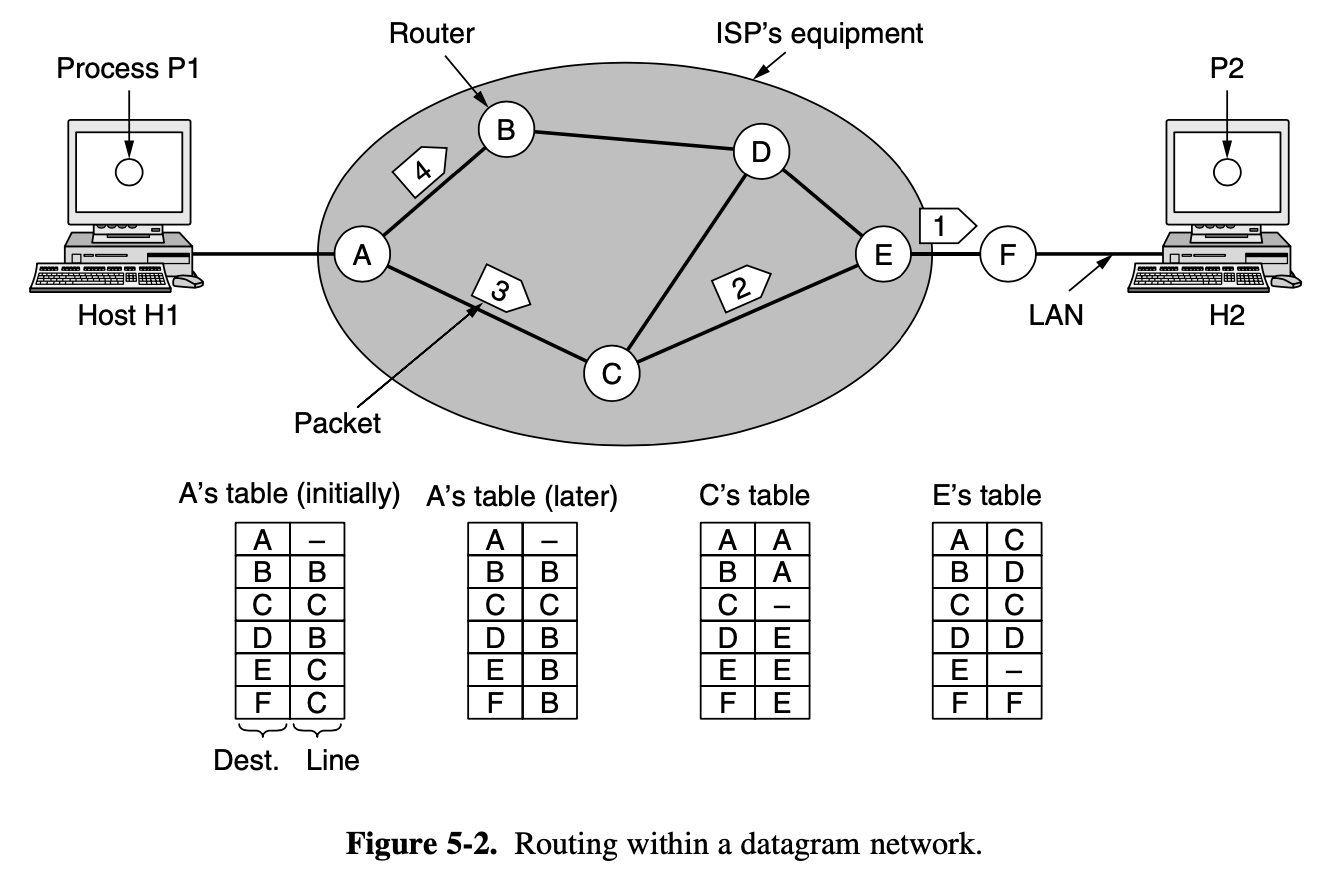
Let us assume) the message is 4 times longer than the maximum packet size
- the network layer haas to break it into 4 packets 1,2,3,4
- send each of them in turn to router A using some point to point protocol, PPP
- At this point the ISP takes over
- Every router has an internal table telling it where to send packets for each of the possible destinations
- Each table entry is a pair consisting of a destination and th outgoing line to use for that destination
- At A, packets 1, 2, 3 are stored briefly, having arrived on the incoming link and had their checksums verfieid (stop-and-forward)
- The each packet is forwarded according to A's table, onto the outgoing link to C within a new frame
- Packet 1 is then forwarded to E and then to F
- When it get to F, it is sent wighin a frame over the LAN to H2
- Packets 2 and 3 follow the same route
- However someting different happend to packet 4
- When it gets to A it is sent to router B, even though it is also destined for F
- For some reason, A decided to send packet 4 via a different route than that of the first 3 packets
- Perhaps it has learned for a traffic jam somewhere along the ACE path and updated its routing table, as shown under the label "later"
- The algorithm that manages the tables and makes the routing decisions is called the routing algorithm
- IP (Internet Protocol), which is the basis for the entire Internet, is the dominant example of a connectionless network service
- Each packet carries a destination IP address that routers use to individually forward each packet
- The address are 32 bits in IPv4 packets and 128 bits in IPv6 packet
5.1.4. Implementation of Connection-Oriented Service
- For connection-oriented service, we need a virtual-circuit network
- The idea behind virtual circuits is to avoid having to choose a new route for every packet sent
- When a connection is established, a route from the source machine to the destination machine is chosen as part of the connection setup and stored in tables inside the router
- That route is used for all traffic flowing over the connection
- When the connection is released, the virtual circuit is also terminated
- each packet carries an identifier telling which virtual circuit it belongs to
[An example]
- host H1 has established connection 1 with host H2
- This connection is remembered as the first entry in each of the routing tables
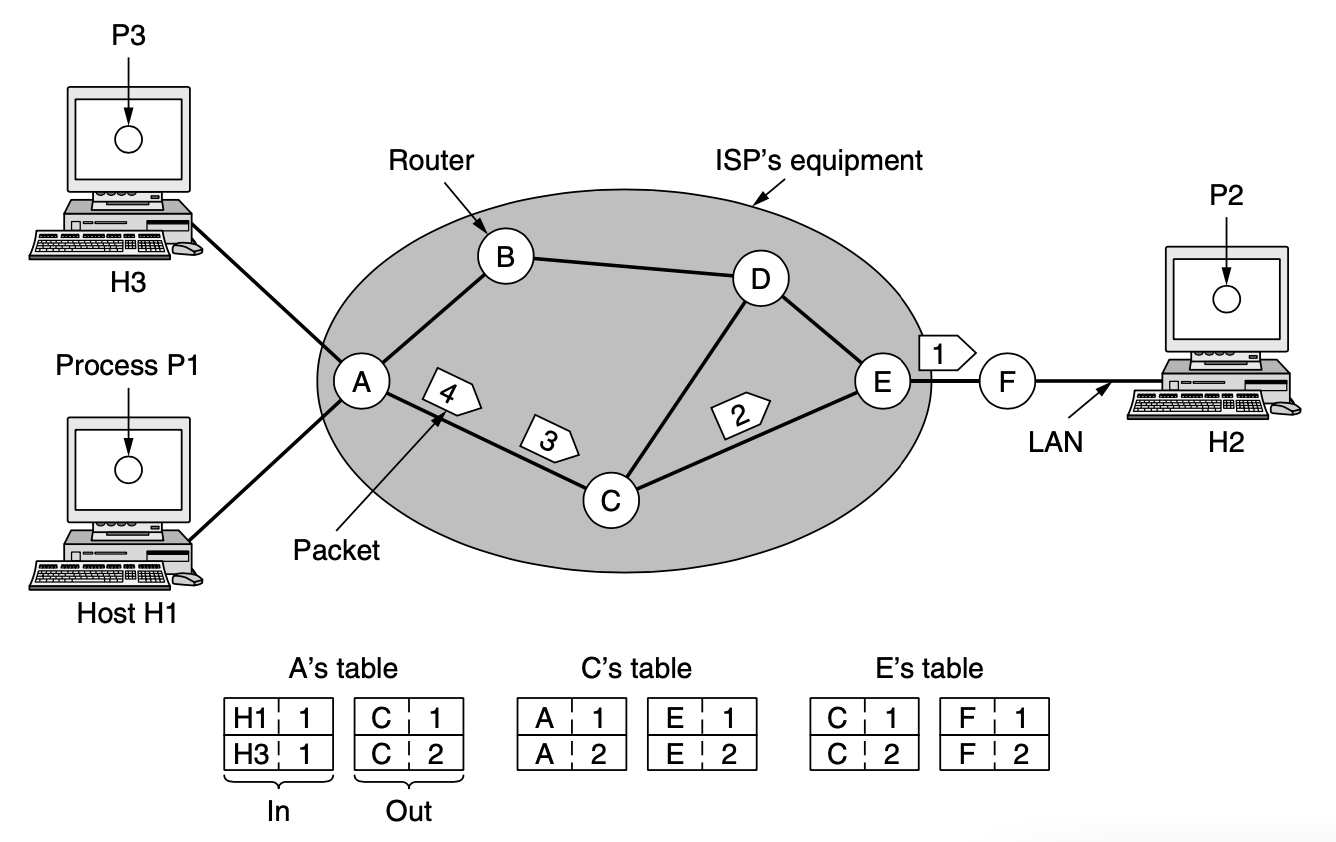
[NEW!] Now let us consider what happends if H3 also wants to establish a connection to H2
- It choose connection identifier 1
- because it is initiating the connection and this is its only connection
- tell the network to establish the virtual circuit
- this leads to the second row in the tables
- we have a conflict here because although A can saily distinguish connection 1 packets from H1 from connection 1 packet from H3, C cannot do this
- For this reason, A assigns a different connection identifier to the outgoing traffic for the second connection
- this process is called Label Switching
ex) connection-oriented network service : MPLS (MultipProtocol Label Swtiching)
- it used within ISP networks in the internet, with IP packets wrapped in an MPLS header having a 20-bit connection idenfier or label
5.1.5. Comparision of Virtual-Circuit and Datagram Networks
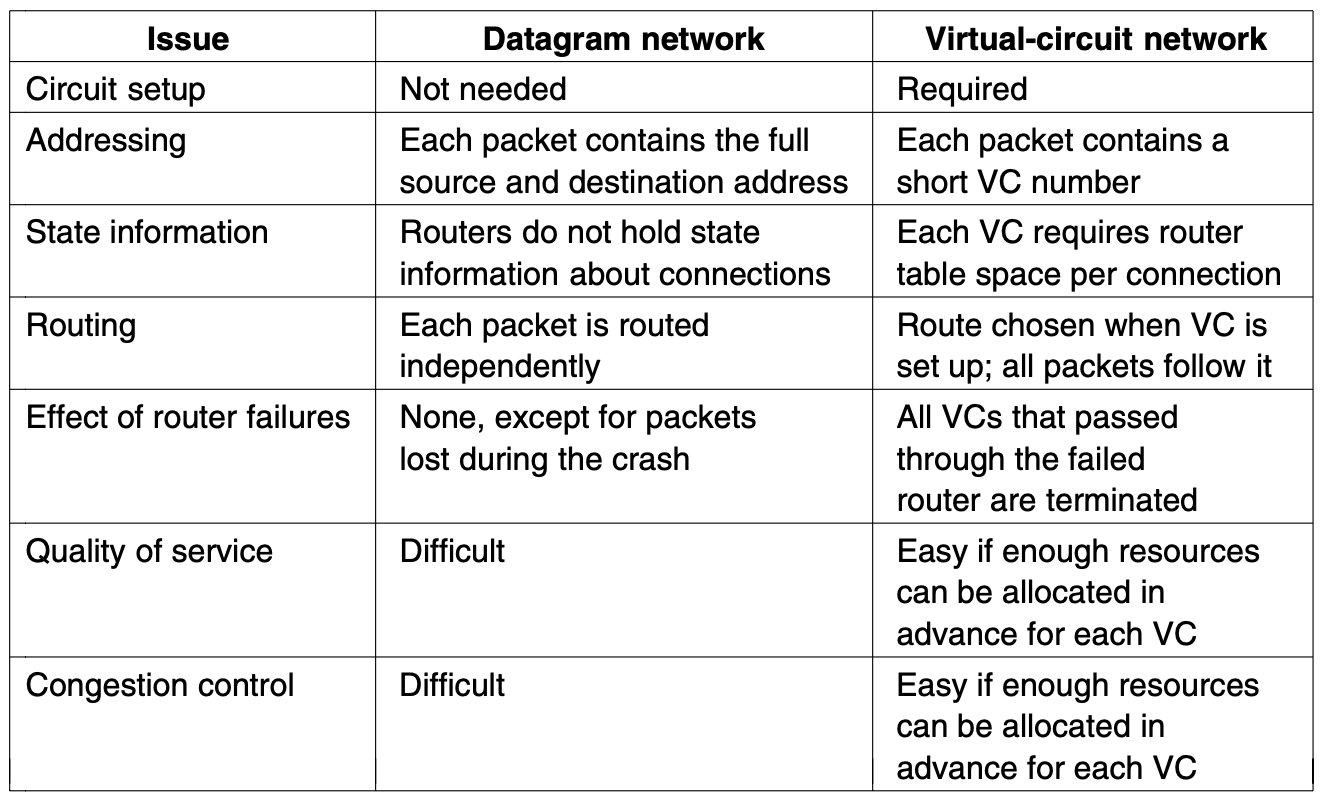
- Inside the network, several trade-off exist between virtual circuit and datagram
- One trade-off is setup time versus address parsing time
- Using virtual circuits requires a setup phase, which takes time and consumes resources
- Once this price is paid figuring out what to do with a data packet in a virtual-circuit network is easy
- The router just uses the circuit number of index into a table to find out where the packet goes
- In a datagram network, no setup is needed but a more complicated lookup procedure is required to locate the entry for the destination
[Issue]
- the destination addresses used in datagram networks are longer than circuit number used in virtual-circuit networks
- destination address have a global meaning
- If packets tend to be fairly short, including a full destination address in every packet may represent a significant amount of overhead and hence a waste of bandwidth
- the amount of thable space required in router memory
- A datagram network needs to have an entry for every possible destination
[Virtual circuits have some advantages]
- guaranteeing quality of service and avoiding congestion within the network
- because resources can be reserved in advance, when the connection is establish
- Once the packets start arriving, the necessary bandwidth and router capaciy will be there
- With the datagram network, congestion avoidance is more difficult
- For transaction processing system (e.g. payment system), the overhead required to set up and clear a virtual circuit may easily dwarf the use of the circuit
- If the majority of the traffic is expected to be of this kind, the use of virtual circuits inside the network makes little sense - On the ther hand, for long-running uses such as **VPN traffic** between 2 corporate offices, permanent virtual circuits may be useful
[Virtual circuits vulnerability problem]
- If a router crashes and loses its memory, even if it comes back up a second later, all the virtual circuits passing through it will have to be aborted
- if a datagram router goes down, only those users wose packets were queued in the router at the time need suffer
- datagram also allow the router to balance the traffic throughout the network
5.2. Routing Algorithm
- routing packet from the source machine to the destination machine
- in most networks, packets will require multiple hops to make the journey
- The only notable exception is for broadcast networks
- If the network uses virtual circuits internally, routing decisions are made only when a new virtual circuit is being set up
- Threreafter, data packets just follow the already established route
- The latter case is sometimes called session routing
[router as having 2 processes inside it]
- forwarding : each packet as it arrives, looking up the outgoing line to use for it in the routing tables
- responsible for filling in and updating routing tables
[Routing algorithms grouped into 2 major classes]
- nonadaptive
- adaptive
[Nonadaptive algorithms]
- do not base their routing decisions on any measurements or estimates of the current topology and traffic
- offline and downloaded to the routers when the network is booted
- This procedure is sometimes called static routing
- because it does not respond to failures
- static routing is mostly useful for situations in which the routing choice is clear
[Adaptive algorithms]
- change their routing decisions to relfect changes in the topology
- sometimes changes in the traffic as well
- dynamic routing
5.2.1. The Optimality Principle
- if router J is on the optimal path from router I to router K
- then the optimal path form J to K also falls along the same ways
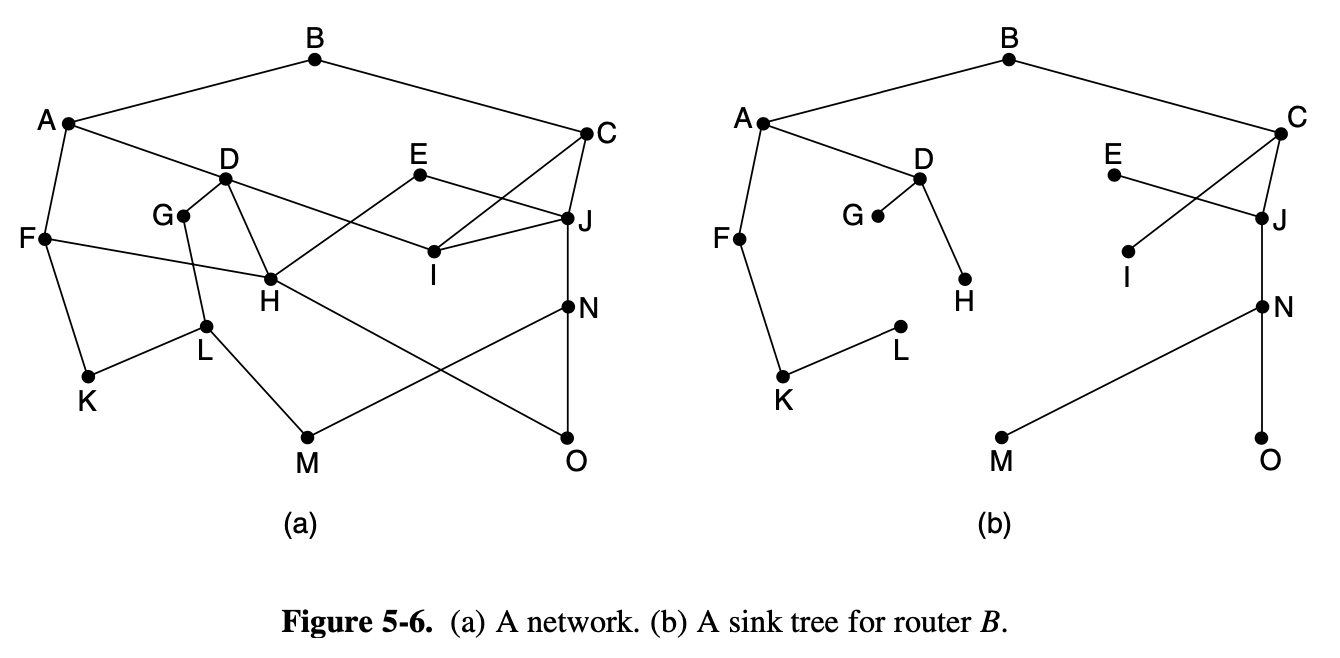
- As a direct consequence of the optimality principle, we can see that the set of optimal routes from all sources to a given destination form a tree rooted at the destination (called a sink tree)
- where the distance metric is the number of hops
- the goal of all routing algorithms is to discover and use the sink trees for all routers
- sink tree is not necessarily unique
- other trees with the same path lengths may exist
- the tree becomes a more general structure called a DAG (Directed Acyclic Graph)
[DAGs]
- have no loops
- use sink trees as a convenient shorthand
- since a sink tree is indeed a tree, it does not contains any loops, so each packet will be delivered within a finite and bounded number of hops
- the optimality principle and the sink tree provide a benchmark against which other routing algorithms can be measured
5.2.2. Shortest Path Algorithm
-
The concept of shortest path deserves some explanation
-
One way of measuring path length is the number of hops
-
but what if selected link runs hourly, then that line will not be selected by algorithm
[Dijkstra]
- finds the sortest paths between a source and all destinations in the network
- each node is labeled with its distance from the source node along the best known path
- initially no paths are know, so all nodes are labeld with infinity
- As the algorithm proceeds and paths are found, the labels may change, relecting better paths
- A label may be either tentative or permanent
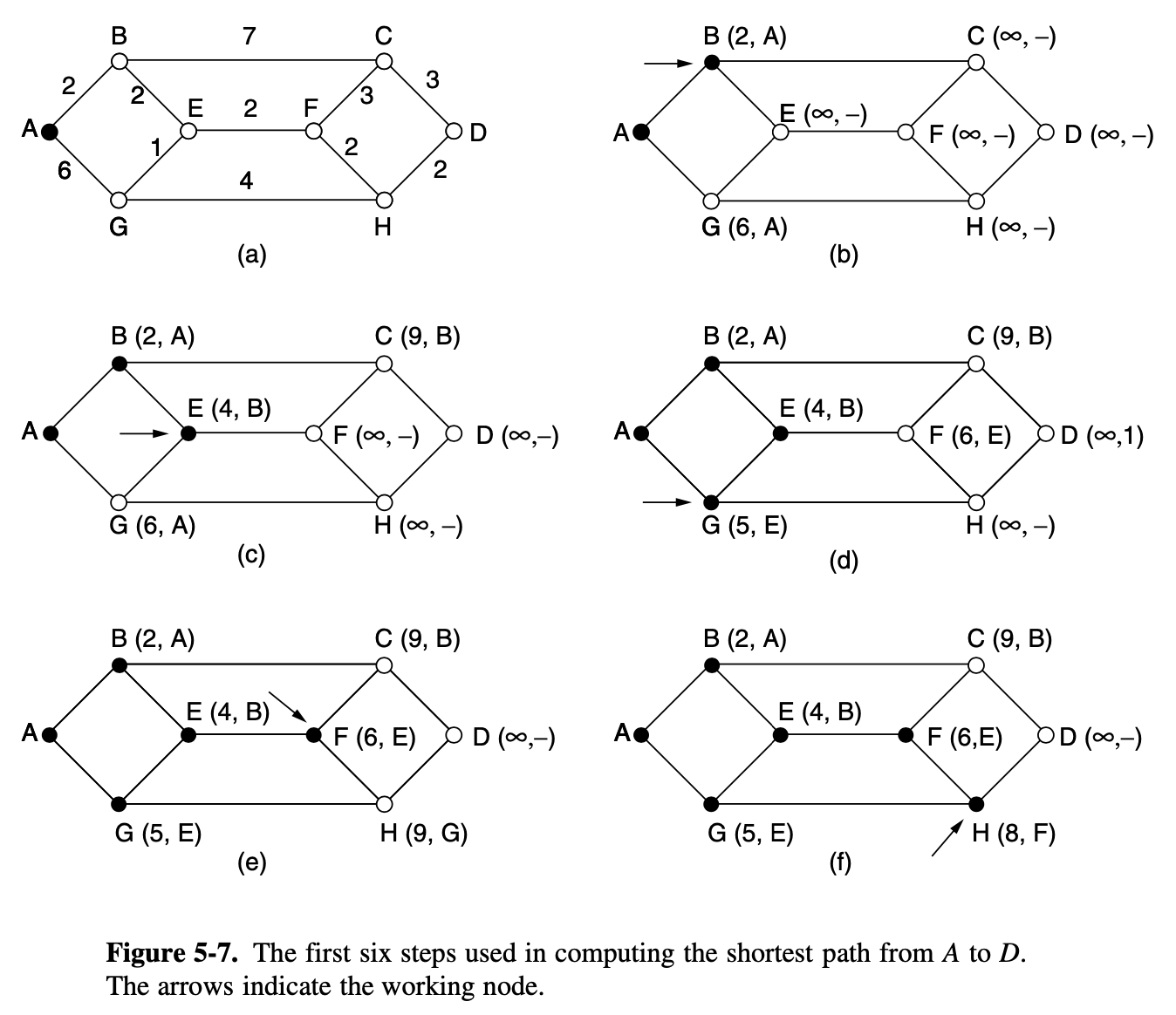
- Whenever a node is relabeled, we also label it with the node from which the probe was made so that we can reconstruct the final path later
5.2.3. Flooding
- routing algorithm is implemented, each router must make decision based on local knowledge, not the complete picture of the network
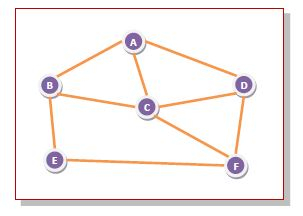
- An incoming packet to A, will be sent to B, C and D.
- B will send the packet to C and E.
- C will send the packet to B, D and F.
- D will send the packet to C and F.
- E will send the packet to F.
- F will send the packet to C and E.
- Flooding obviously generates vast numbers of duplicate packets
- Flooding with a hop count can produce an exponential number of duplicate packets as the hop count grows and router duplicate packets they have seen before
- A better technique for damming the flood is to have routers keep
track of way to achieve this goal is to have to source router put a sequence number in each packet it receives from its hosts - Each router then needs a list per source router telling which sequence numbers orginating at that source have already been seen
- If an incoming packet is on the list, it is not flooded
- Flooding is not practical for sending most packets,
- but is does have some important uses
- it ensures that a packet is delivered to every node in the network
- flodding is trememdously robust
- Flooding always chooses the shortest path because it chooses every possible path in parallel
5.2.4. Distance Vector Routing
- Computer networks generally use dynamic routing algorithms that are more complex than flooding
- but more efficient because they find shortest paths for the current topology
[2 dynamic algorithms]
- distance vector routing
- link state routing
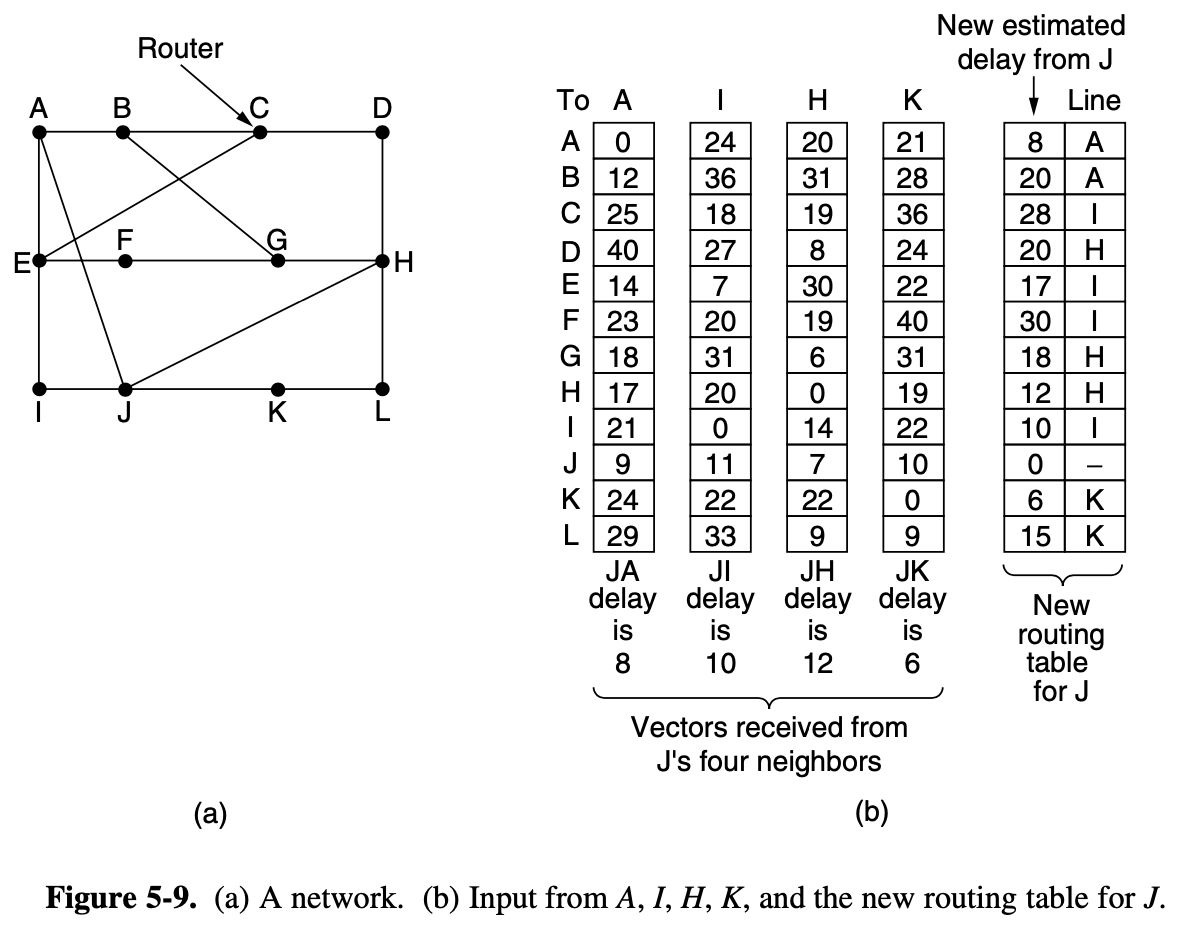
distance vector routing (Bellman-Ford Routing algorithm)
- operate by having each router maintain a table giving the best known distance to each destination and which link to use to get there
- These tables are updated by exchanging information with the neighbors
- Eventually every router knows the best link to reach each destination
- The router is assumed to know the distance to each of its neighbors
- If the metric is propagation delay, the router can measure it directly with special ECHO packets that the receiver just timestamps and sends back as fast as it can
The Count-to-Infinity Problem
- The setting of routes to best path across the network is called convergence
- Distance vector routing is usedful as a simple technique by which routers can collectively compute shortest paths, but is has a serious drawback in practice
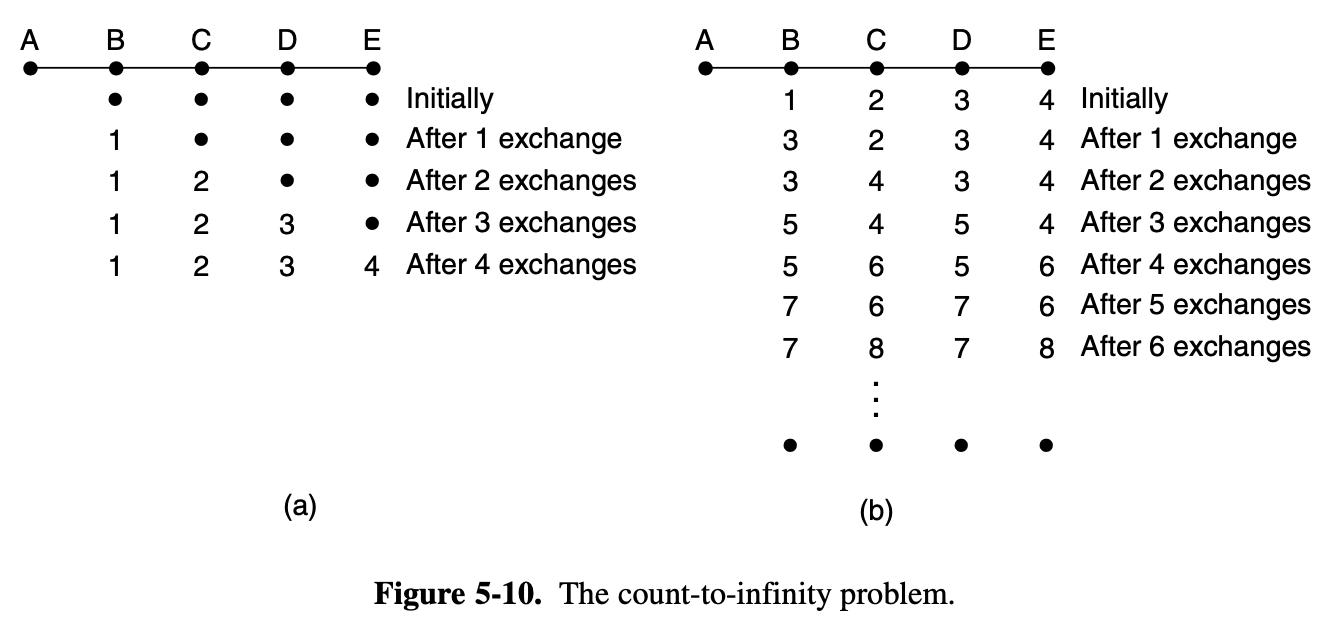
- Suppose [A is down] initially and all the other routers know this
- They have all recorded the delay to A as inifinity
- When [A comes up] the other router lean about it via the vector exchanges
- for simplicity, we will assume that there is gigantic gong somewhere that is struck periodically to initiate a vector exchange at all routers simultaneously
- At th time of the first exchange, B learn that is left-hand neighbor has zero delay to A
- B now makes an entry in its routing table indicating that A is one hop away to the left
- All the other routers still think that A is down
- At this point the routing table entries for A are as shown in the second row (Figure 5-10 a)
- On the next exchange, C learns that B has path of length 1 to A
- so it updates its routing table
- The good news is spreading at the rate of one hop per exchange
- Now let us consider the situation of Fig. 5-10(b)
- Router B, C, D and E have distance to A of 1, 2, 3, 4 hops
- Suddenly either [A goes down] or the link between A and B is cut
- At the [first exchange], B does not hear anything from A
- Fortunately C have path to A of length 2, so B thinks it can reach A via C, with a path length of 3
- [Second exchange] C notices that each of its neighbors claims to have a path to A of length 3
- It picks one of them at random and makes its new distance to A 4
- Subsequent exchanges produce the history
5.2.5. Link State Routing
- Discover its neighbors and learn their network addresses
- Set the distance or cost metric to each of its neighbors
- Construct a packet telling all it has just learned
- Send this packet to and receive packets from all other routers
- Compute the shortest path to every other router
1. Learning about the Neighbors
- Router is booted, its first task is to learn who its neighbors are
- sending a special HELLO packets on each point to point line
- Th router on the other end is expected to send back a reply giving its name
- These names must be globally unique
- The braodcast LAN provides connectivity between each pair of attached routers
2. Setting Link Costs
- each link to have a distance or cost metric for finding shortest paths
- The cost to reach neighbors can be set automatically or configured by the network operator
- The most direct way to determine this delay is to send over the line a special ECHO packet that the other side is required to send back immediately
- By measuring the round-trip time and dividing it by 2, the sending router can get a reasonable estimate of the day
3. Building Link State Packets
- the next step is for each router to build a packet containing all the data
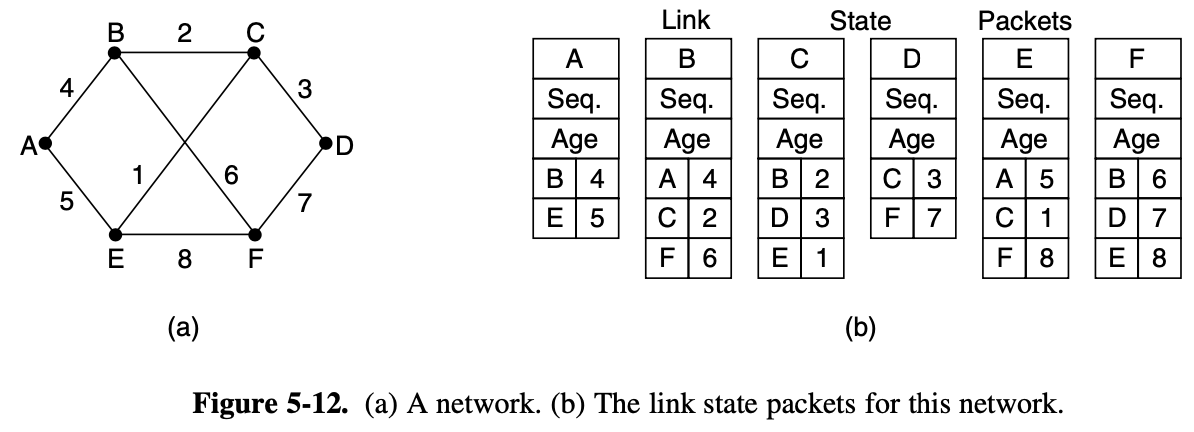
[determining when to build them]
- build them periodically
- build them when som significant event occurs
4. Distirbuting the Link State Packets
- If different router are using different versions of the topology
- the routes they compute can have inconsistencies such as loops, unreachable machines, and other problems
basic distribution algorithm
- use flooding to distribute the link state packets to all routers
- to keep the flood in check, each packet contains a sequence number that is incremented for each new packet sent
- [If it is new], it is forwarded on all lines except the one it arrived one
- [If it is duplicate], it is discarded
- [If a packet with a sequence number lower then the highest one seen so far ever arrives], it is rejected as being obsolete as the router has more recent data
5. Computing the New Routes
- Once a router has accumulated a full set of link state packet
- it can construct the entire network grap because every link is represented
- Now Dijkstra's algorithm can be run locally to construct the shortest paths to all possible destinations
- Compared to distance vector routing, link state routing requires more memory and computation
- Link state routing is widely used in actual networks (ex) OSPF (Open Shortest Path First))
5.2.6. Hierarchical Routing
As a networks grow in size, the router routing tables grow proportionally
- Not only is router memory consumed by ever-increasing tables, but more CPU time is needed to scan them and more bandwidth is needed to send status reports about them
- When hierarchical routing is used, the routers are divided into what we will call regions
- Each router all the details about how to route packets to destinations within its own region but knows nothing about the internal structure of other region
- For huge networks, 2-level hierarchy may be insufficient
- it may be necessary to group the regions into clusters, the clusters into zones, the zones into groups and so on
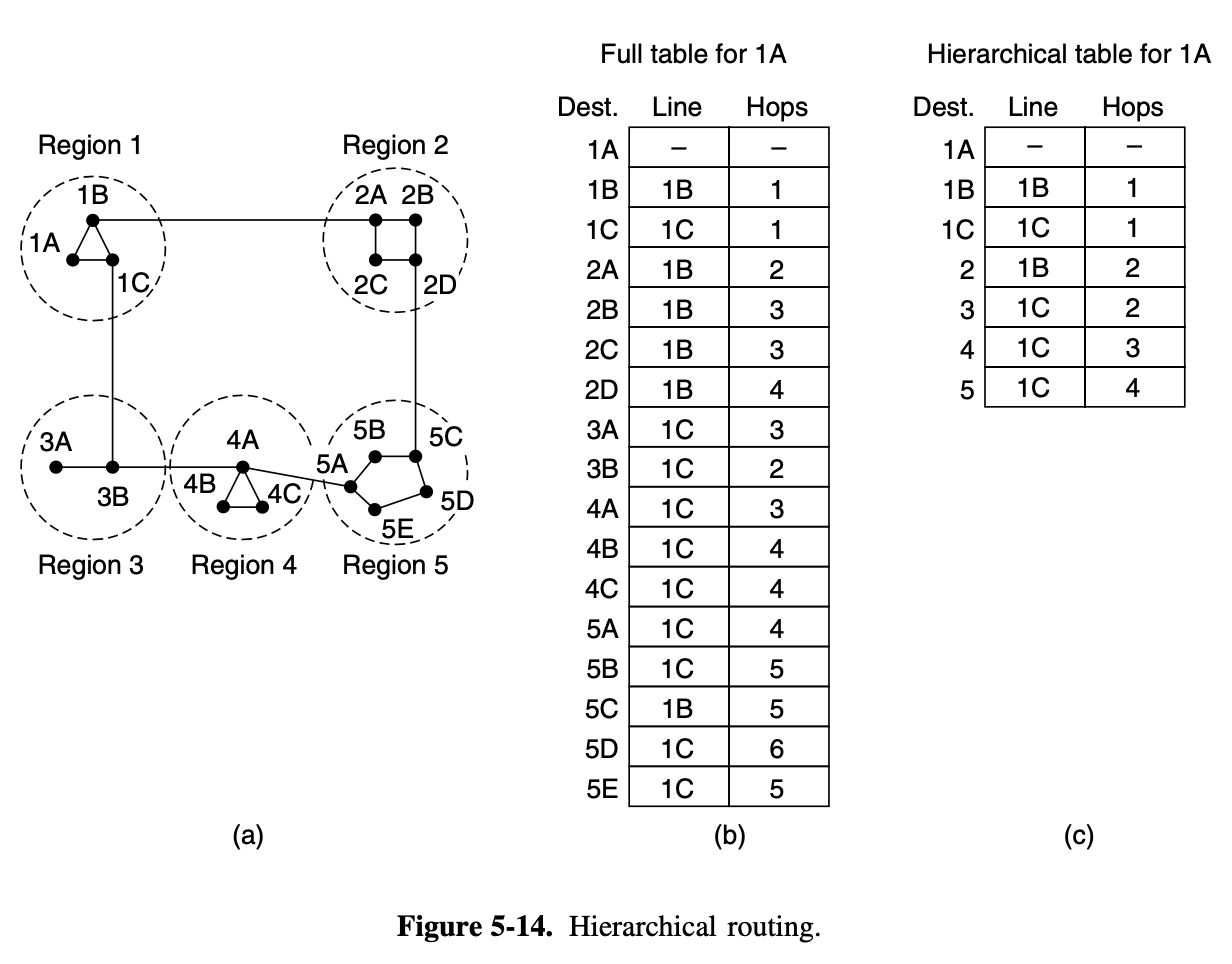
- how many levels should the hierarchy have? e ln N entries per router
5.2.7. Broadcast Routing
- Sending a packet to all destinations simultneously is called braodcasting
- An improvement is multidestination routing, in which each packet contains either a list of destination or a bit map indicating the desired destinations
- When a packe arrives at a router, the router generates a new copy of the packet for each output line
- The schema still requires the source to know all the destinations, plus it is as much work for a router to determine where to send one multidestination packet as it is for multiple distinct packet
- we have already seen a better broadcast routing technique : flooding
- However, it turned out that we can do better still once the shortest path routes for regular packets have been computed
- reverse path forwarding is elegant and remarkably simple
- When a braodcast packet arrives at a router, the router checks to see if the packet arrived on the link that is normally used for sending packets toward the source of the broadcast
- if so, there is an excellent chance that the braodcast packet itself followed the best route from the router and is therefore the first copy to arrive at the router
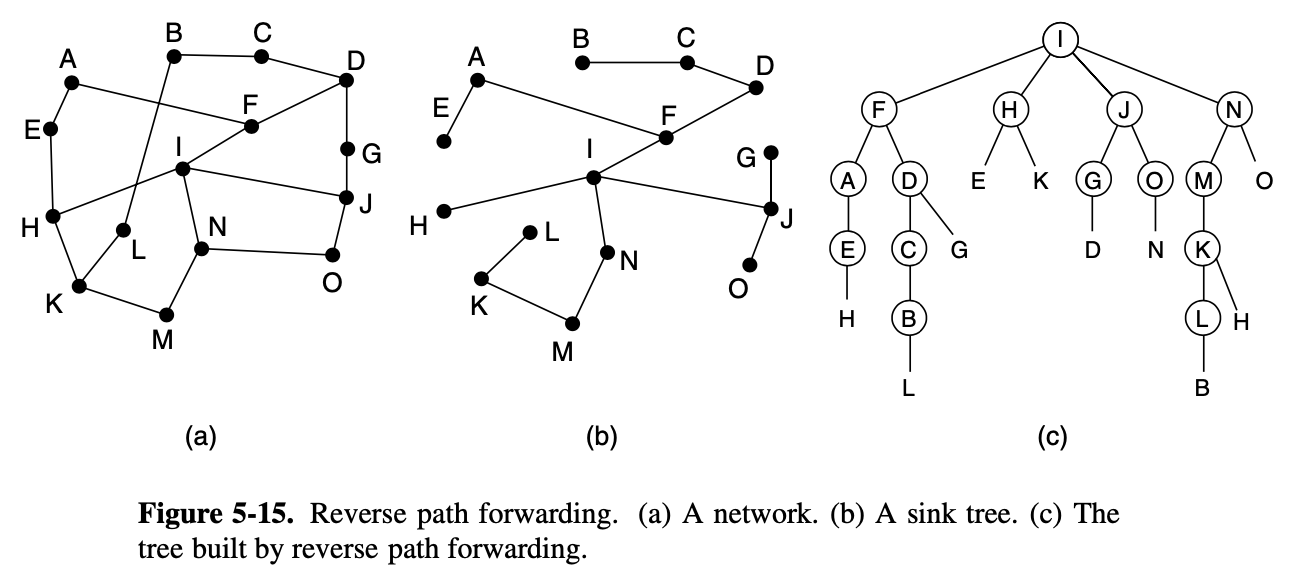
- our last braodcast algorithm : spanning tree
- sink trees are spanning trees
- this method makes excelent used of bandwidth, generating the absolute minimum number of packets necessary to do the job
5.2.8. Multicast Routing
- we need a way to send messages to well-defined groups that are numerically large in size but small compared to network as a whole
- sending a message to such a group is called multicasting
- all multicasting schemes require some way to create and destroy groups and to identify which routers are members of a group
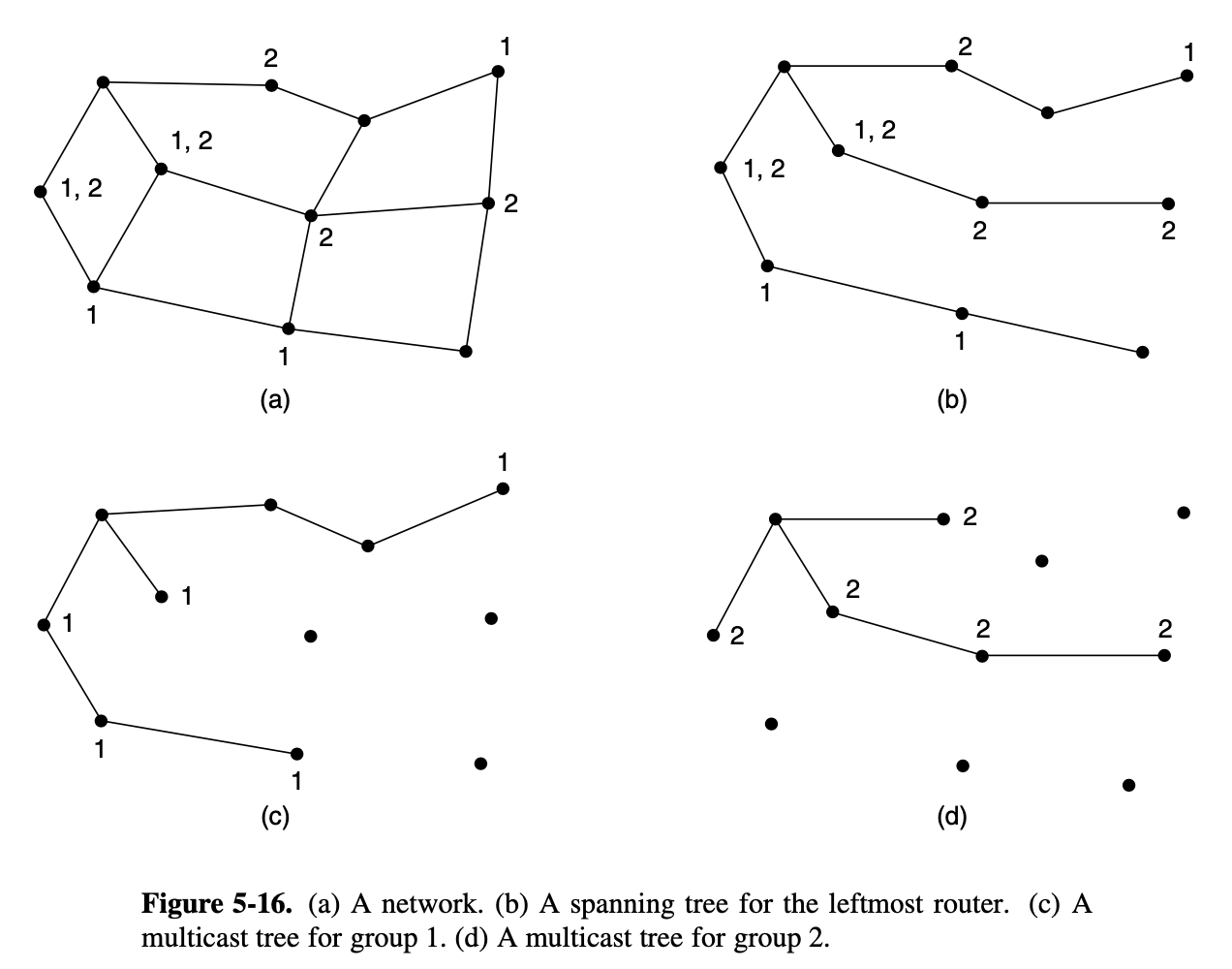
- prune the braodcast spanning tree by removing links that do not lead to members
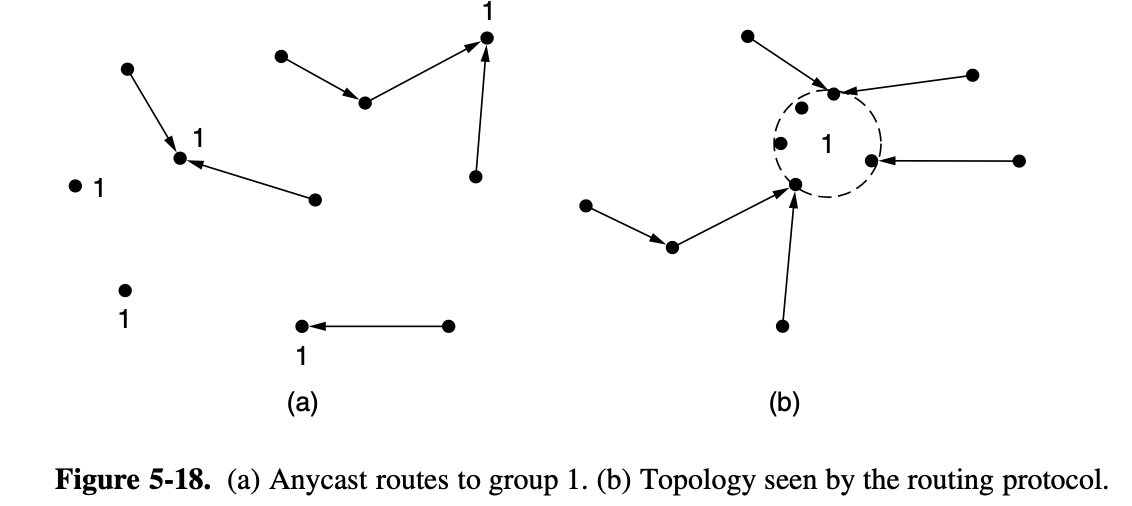
5.2.9. Anycast Routing
- packet is delivered to the nearest member of group
- sometimes nodes provide a service, not the node that is contacted, any node will do
5.3. Congestion control algorithms
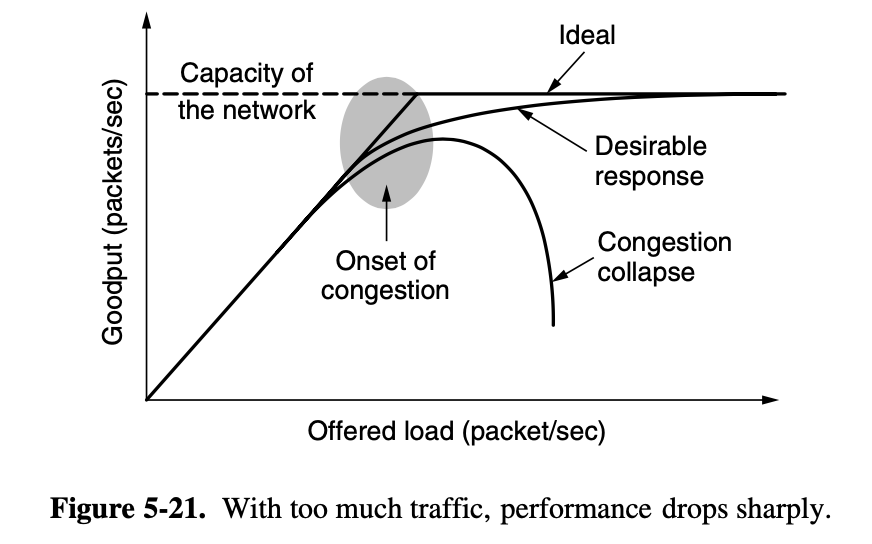
5.3.1. Approaches to Congestion Control
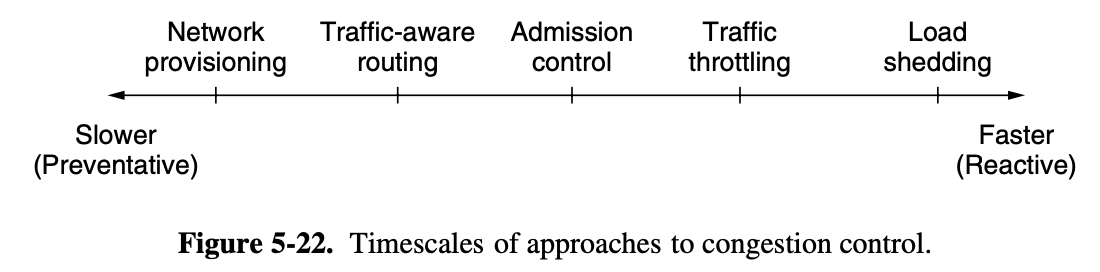
- provisioning : links and routers that are regularly heavily utilized are upgraded at the earliest opportunity
traffic-aware routing
ex) routers may be changed to shift traffic away from heavily used paths by changing the shortest path weight
admission control
- the only way then to beat back the congestion is to decrease the load
- In a virtual-circuit network, new connections can be refused if they would cause the network to become congested
load shedding
- when all else fails the network is forced to discard packets that is cannot deliver
5.3.3. Admission Control
- do no set up a new virtual circuit unless the network can carry the added traffic without becomming congested
- Traffic is often described in terms of its rate and shape
ex) traffic that varies while browsing the Web is more difficult to handle than a streaming movie because the burst of Web traffic are more likeyl to congest routers in the network
leaky bucket
- has 2 parameters that bound the average rate and the instantaneous burst size of traffic
5.3.4. Traffic Throttling
congestion avoidance
- When congestion is imminent, it must tell the senders to throttle back their transmission and slow down
- this feedback is business as usual rather than an exceptional situation
Choke Packets
- Th most direct way to notify a sender of congestion is to tell it directly
- To avoid increasing loadon the network during a time of congstion, the router may only send choke packets at a low rate
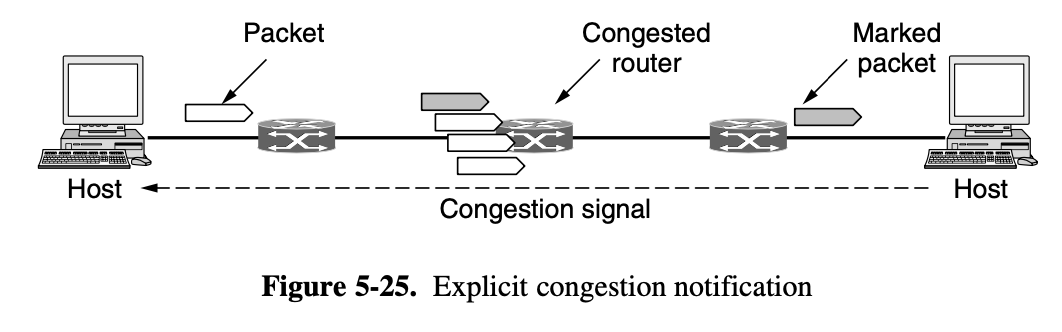
Explicit congestion Notification
- a router can tag any packet it forwards to signal that it is experiencing congestion
- When the network delivers the packet, the destination can note that there is congestion and infrom the sender when it sends a reply packet
Hop-by-Hop Backpressure
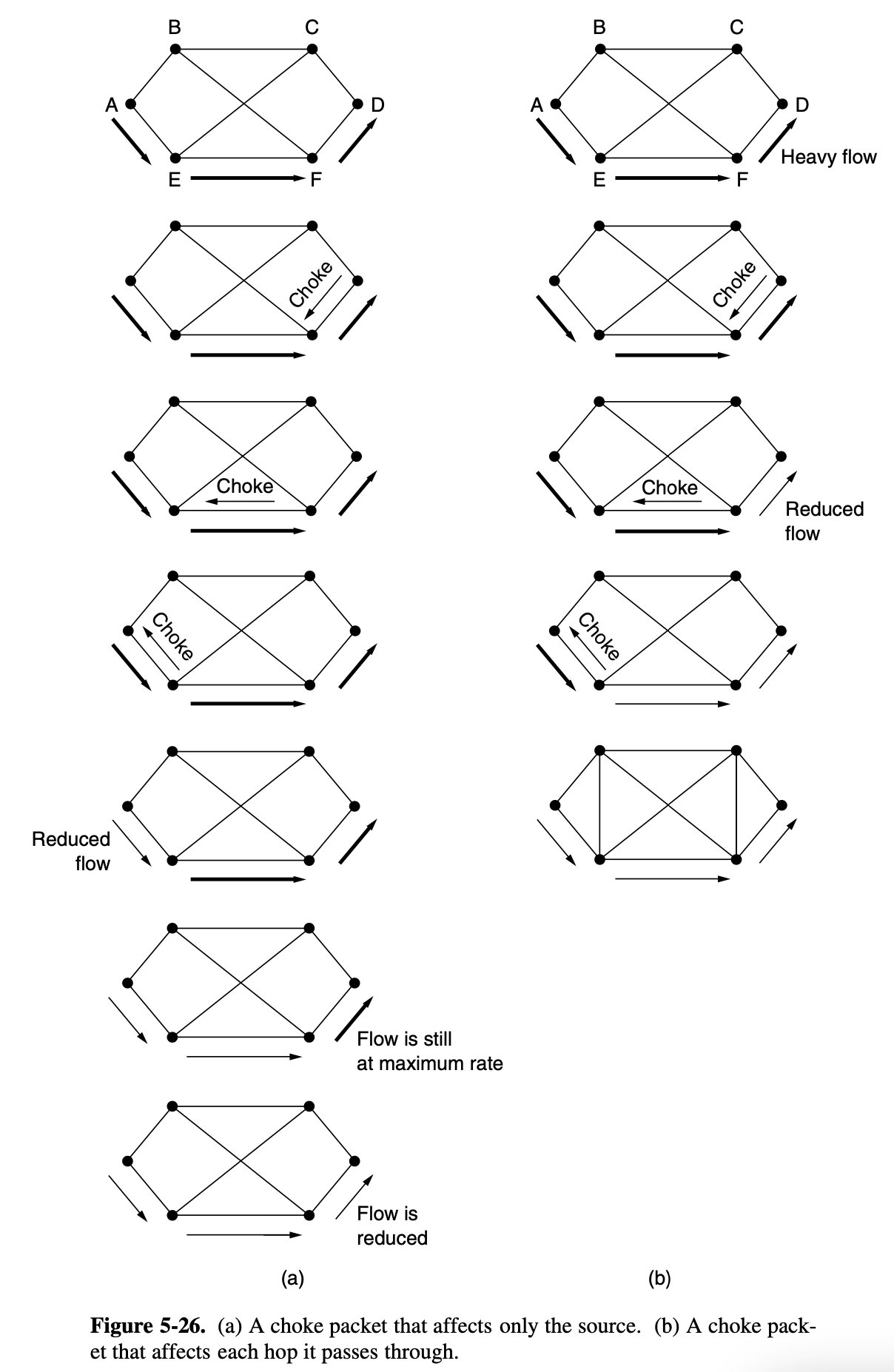
- the choke packet reaches E, which tells E to reduce the flow to F
- This action puts a greater demand on E's bufferes but give F immediate relief
5.3.5. Load Shedding
- router drowning in packets is which packets to drop
- The preferred choice may depend on the type of applications that use the network
ex) in file transfer, old packet is worth than new packet
but real time system, new packet is worth than old packet
- To implement an intelligent discard policy, applications must mark their packets to indicate to the network how important they are
- of course, unless there is some significant incentive to avoid marking every packet as VERY IMPORTANT - NEVER, EVER DISCARD
Random Early Detection
- Dealing with congestion when it first starts is more effective than letting it gum up the works and then trying to deal with it
- it is difficult to build a router that does not drop packets when it is overloaded
- TCP was designed for wired networks and wired networks are very reliable, so lost packets are mostly due to buffer overruns rather thatn transmission errors
- Wireless links must recover transmission erros at the link layer to work well with TCP
- By having routers drop packets early, before the situation has become hopeless, there is time for the source to take action before it is too late
- A popular algorithm for doing this is called RED (Random Early Detection)
- When the average queue length on some link exceed a threshold, the link is said to be congested and a small fraction of the packets are dropped at random
- The affected sender will notice the loss when there is no acknowledgement, and then the transport protocol will slow down
5.4. Quality of service
overprovisioning
- easy solution to provide good quality of service is to build a network with enough capacity for whatever traffic will be thrown at it
- Performance doesn't get any better than this
- The trouble with this solution is that it is expensive
5.4.1. Application Rquirements
- A stream of packets from a source to a destination is called a flow
- The needs of each flow can be characterized by 4 primary parameter : bandwidth, delay, jittar, loss
=> QoS (Quality of Service)
+) jittar : the variation in the delay or packet arrival time
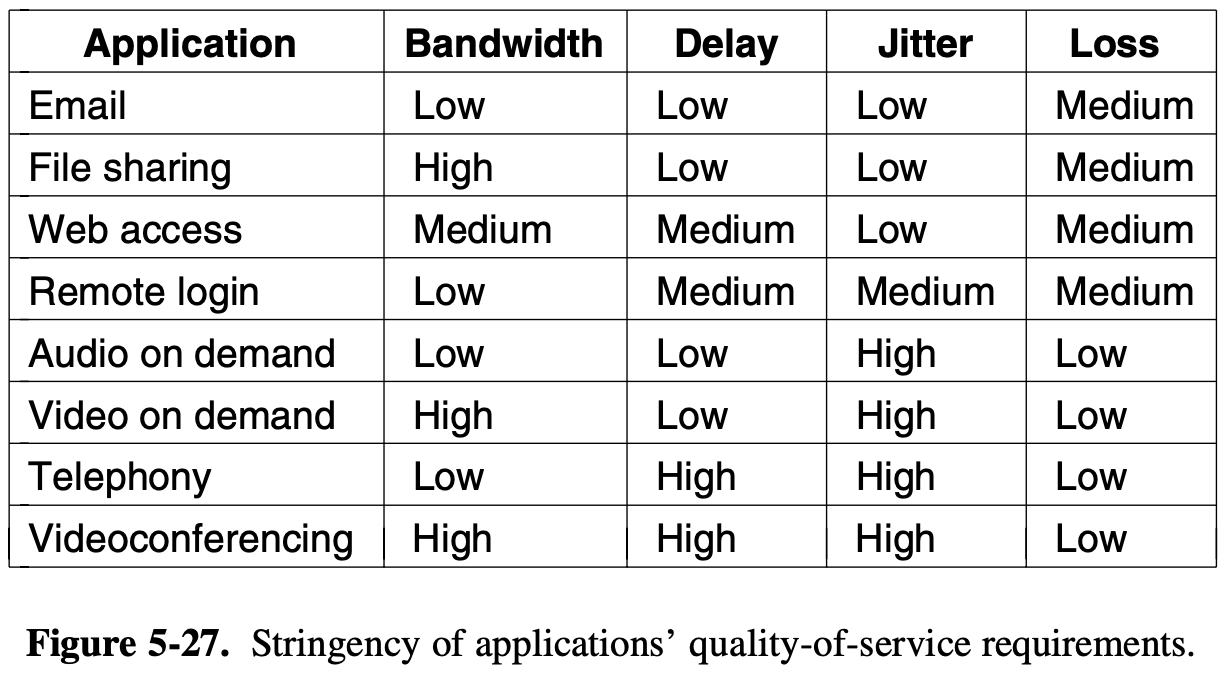
5.4.2. Traffic Shaping
- Before the network can make QoS guarantees, it must know what traffic is being guaranteed
- traffic in data networks is bursty
- Traffic Shaping : technique for regulating the average rate and burstiness of a flow of data that enters the networks
- when a flow is set up, the user and the network agree on a certain traffic pattern for that flow
"My transmission pattern will look like this; can you handle it?"
- SLA (Service Level Agreement) : that aggrement is called
- Traffic shaping reduces congestion and thus helps the network live up to its promise
- traffic policing : Monitoring a traffic flow
Leaky and Token Buckets
- sliding window : one way to limit the amount of data an application sends
- this is more general way to characterize traffic
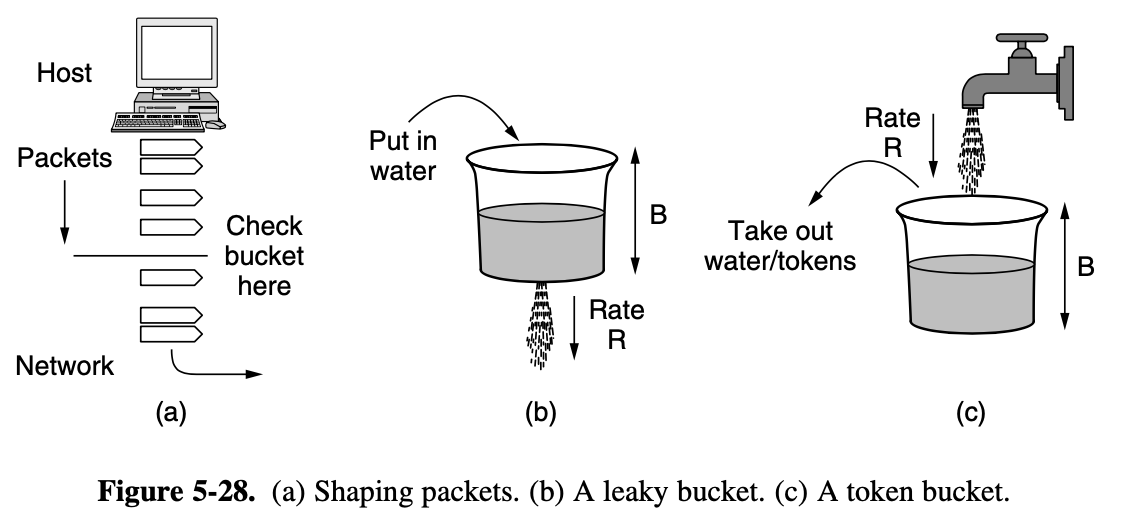
Leaky bucket algorithm
- imagine a bucket with a small hole in the bottom
- no matter the rate at which water enters the bucket, the outflow is at a constant rate R
- if a packet arrives when the bucket is full, the packet must either be queued until enough water leaks out to hold it or be discarded
Token buekt algorithm
- full of capacity B, any additional water entering it spills over the sides and is lost
- in hardware at a provider network interface that is policing traffic entering the network
- We must wait until more tokens arrive before we can send another packet
5.4.3. Packet Scheduling
- Being able to regulate the shape of the offered traffic is a good start
- to provide a performance guarantee, we must reserve sufficient resources along the route that the packets take through the network
- To do this we are assuming that the packets of a flow follow the same route
- As a consequence, something similar to a virtual circuit has to be set up from the source to the destination and all the packets that belong to the flow must follow this route
Packet Scheduling Algorithm
- Bandwidth
- Buffer space
- When a packet arrives, it is buffered inside the router until it can be transmitted on the chosen outgoing line
- The purpose of the buffer is to absorb small bursts of traffic as the flow contend with each other
- For good quality of service, some bufferes might be reserved for a specific flow so that flow does not have to compete for buffers with other flowss
- CPU cycles
-
scarce resource
-
router CPU time to process a packet, so a router can process only a certain number of packets per second
ex)
ICMP packets: making sure that the CPU is not overloaded is needed to ensure timely processing of these packets
- Packet scheduling algorithms allocate bandwidth and other router resources by determining which of the buffered packets to send on the output line next
- Each router bufferes packets in a queue for each output line until they can be sent, and they are sent in the same order that they arrived
FIFO (First-In First-Out) / FCFS (First-Come First-Serve)
- usually drop newly arriving packets when the queue is full > tail drop
- simple to implement but it is not suited to providing good quality of service
- if the first flow is aggressive and sends large bursts of packets, they will lodge in the queue
fair queueing algorithm
- router have sepearate queues, one for each flow for a given output line
- when the line become idle, the router scans the queues round-robin
WFQ (Weighted Fair Queueing)
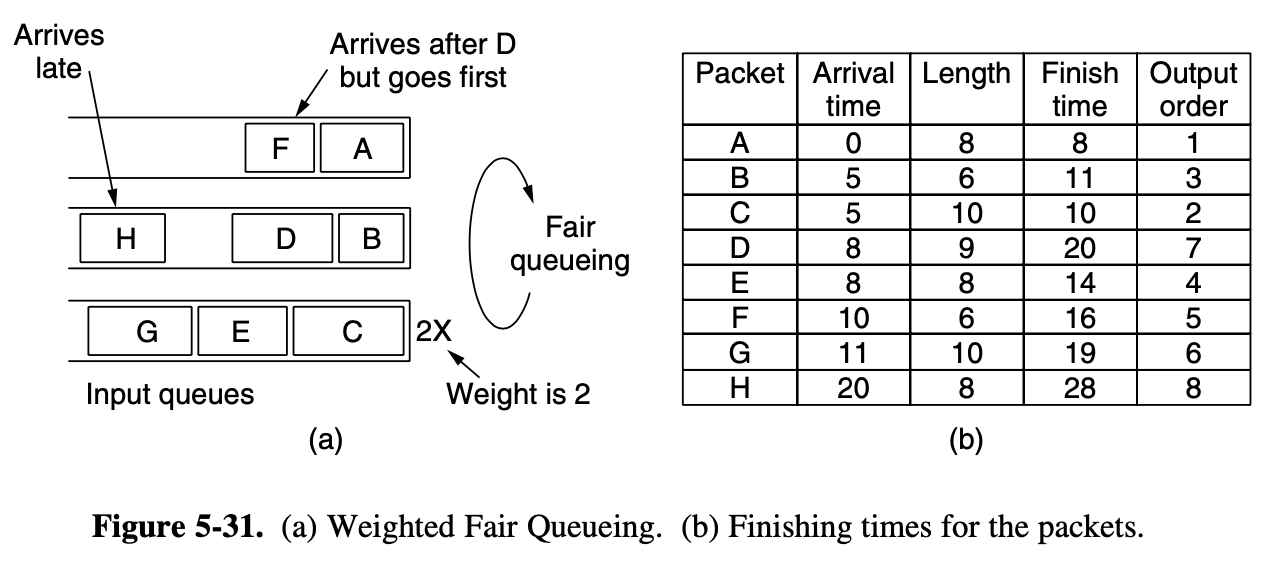
- Letting the number of bytes per round be the weight of a flow
- other kins of scheduling algorithms exists, too
다 알아보다간 이쪽으로 대학원을 가야댐 ^^
5.4.4. Admission Control
- time to put them together to actually provide it
- The reservation must be made at all of the routers along the route that the packets take through the network
- Any routers on the path wihout reservations might become congested and a single congested router can break the QoS guarantee
- QoS routing : guarantee for new flows may still be accomodated by choosing a different route for the flow that has excess capacity
flow specification
- flow must be described accurately in terms of specific parameters that can be negotiated
- A set of such parameters
- the sender produces a flow specification proposing the parameters it would like to use
- Then router turns a flow specification into a set of specific resource reservations
관련 기능들이 많지만 나중에 궁금하면 알아보기로..ㅎ
5.4.5. Integrated Services
RSVP - The Resource reSerVation Protocol
- used for making the reservations
- allows multiple senders to transmit to multiple groups of receivers, permits individual receivers to switch channels freely and optimizeds bandwidth use while at the same time eliminating congestion
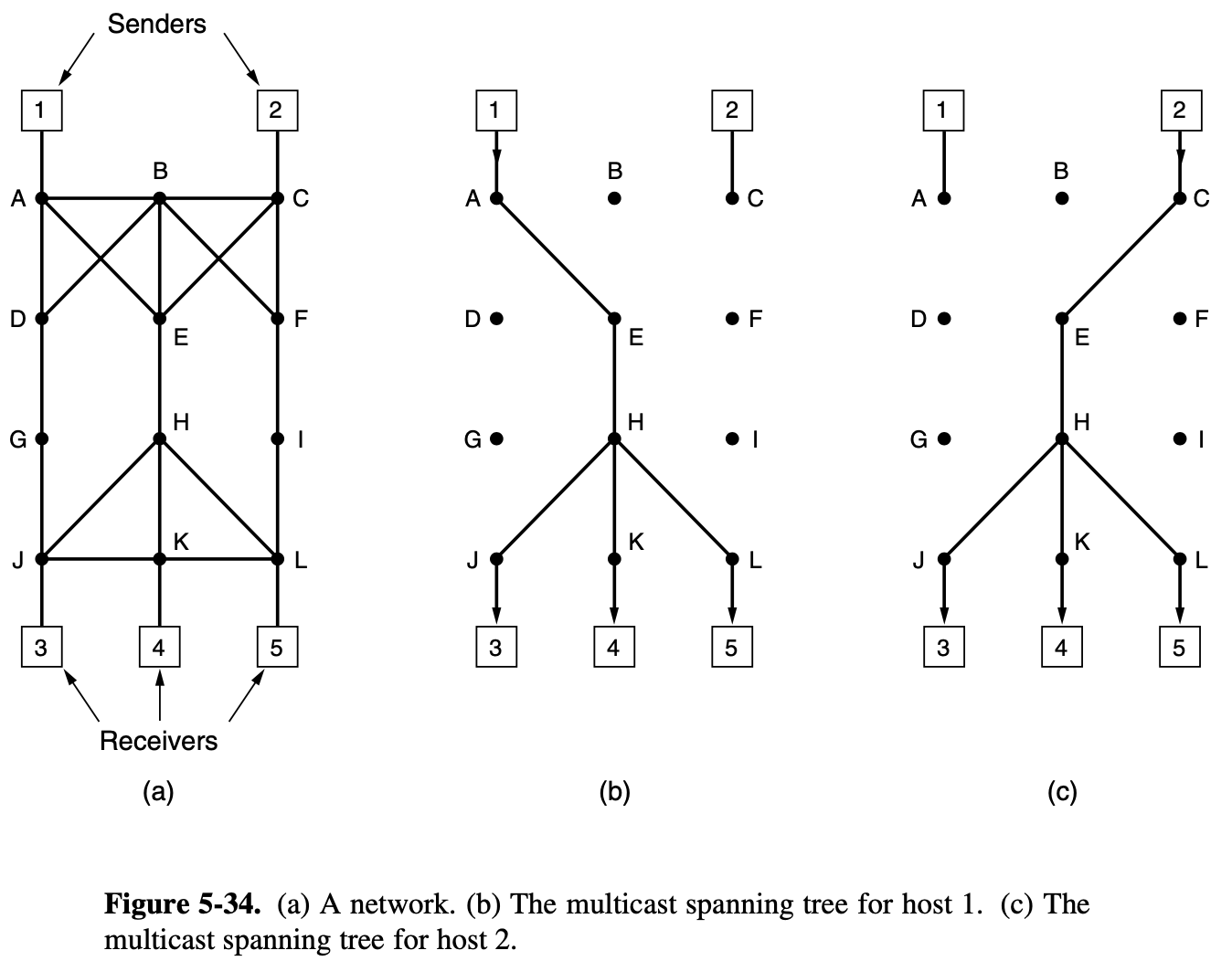
- the standard multicast routing algorithm then builds a spanning tree covering all group members
- The only difference from normal multicasting is a little extra information that is multicast to the group periodically to tell the routers along the tree to maintain certain data structures in their memories
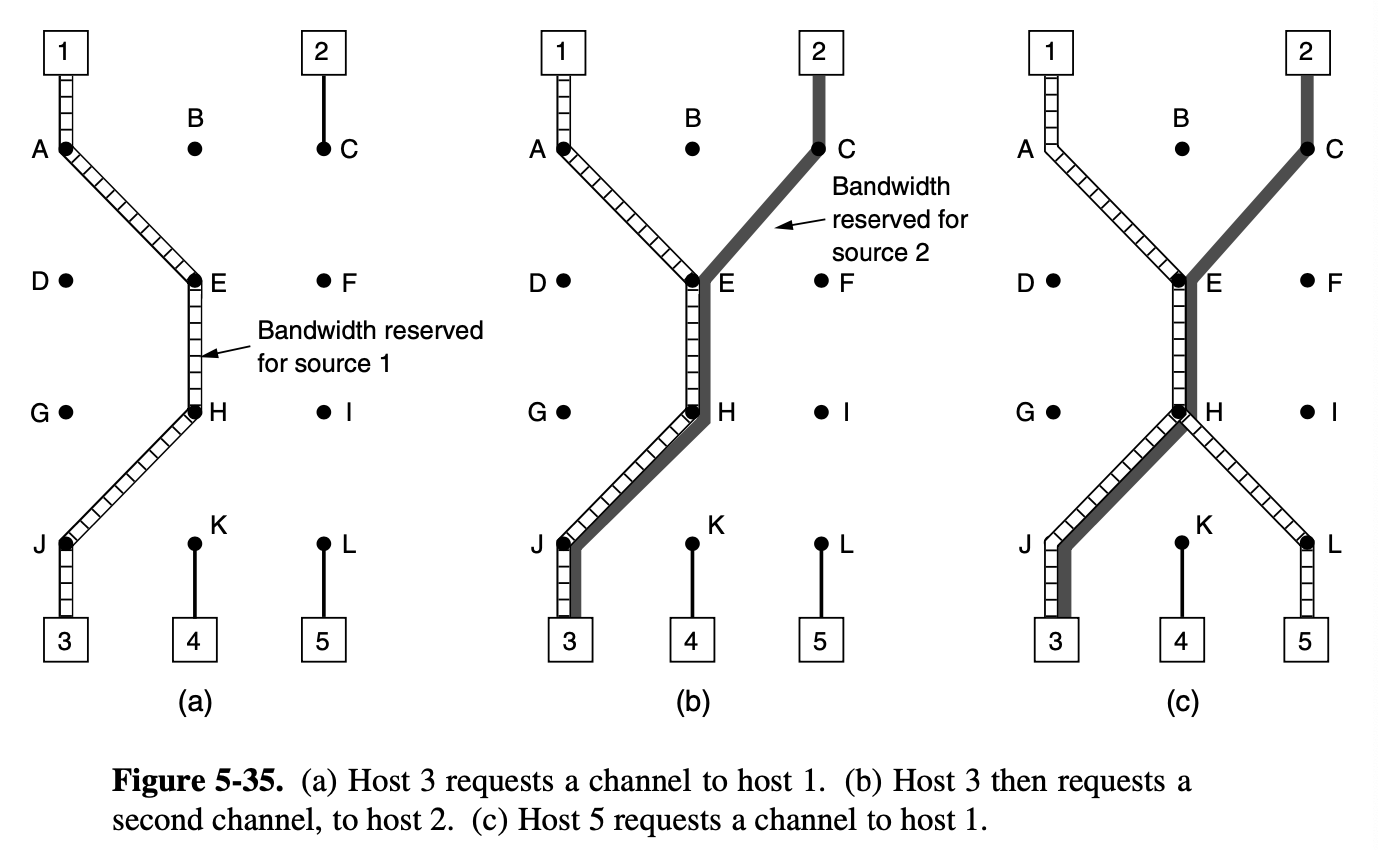
5.4.6. Differentiated Services
- class-based (as opposed to flow-based) quality of service
- IETF has standardized an architecture for it, differentiated services
class-based Service
- offered by a set of routers forming an administrative domain (e.g., an ISP or a telco)
- If a customer subscribes to diferentiated services, customer packets entring the domain are marked with the class to which they belong
- This information is carrid in the Differentiated services field of IPv4, IPv6 packet
- The classes are defined as per hop behaviors, because they correspond to the treatment the packet will receive at each router, not a guarantee across the network
- For packets the classes may differ in terms of delay, jitter and probability of being discarded in the event of congestion, among other possibilities
- with a flow-based scheme, each telepone call gets its own resources and guarantees
- With a class-based schema, all the telephone calls together get the resources reserved for the class telephony
Expedited Forwarding
- 2 classes of service are available, regular and expedited
- The vast majority of the traffic is expected to be regular
- but a limited faction of the packets are expedited
- The expedited packets should be able to tansit the network as though no other packets were present
ex) VoIP (Voice over Internet Protocol) to be marked for expedited service by hosts
- the roters may have 2 output queues for each outgoing line
- one for expedited packets and one for regular packets
- The expedited queue is given priority over the regular one, (e.g. using priority scheduler)
Assured Forwarding
- more elaborate schema for managing the service classes
- 4 priority classes, each class having its own resources
- top 3 classes might be called gold, wilver, bronze
- it defines 3 discard classes for packets that are experiencing congestion: low, medium, high
5.5. Internetworking
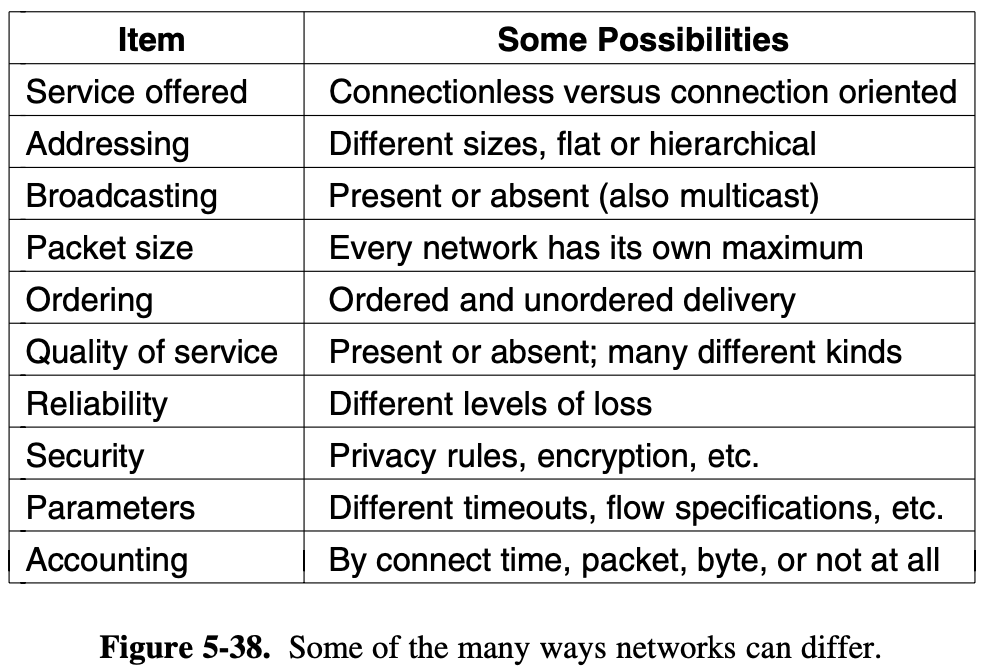
- such as different modulation techniques or frame formats, are internal to the physical and data link layers
- What do we do if the source is on an Ethernet network an dthe destination is on a WiMAX network?
- packets would cross from a connectionless network to a connection-oriented one
- This may require that a new connection be set up on short notice
5.5.2. How Network Can Be Connected
- build devices that translate or convert packets from each kind of network into packets for each other network
- we can try to solve the problem by adding a layer of indirection and building a common layer on top of the different networks
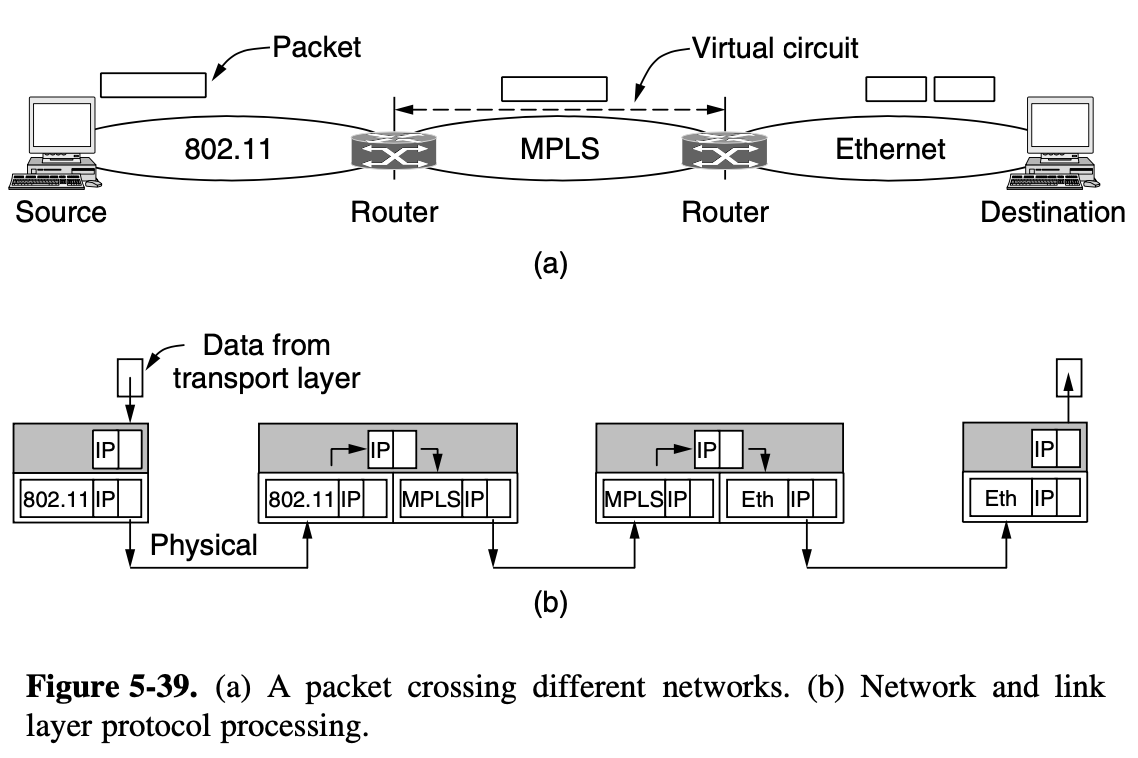
Router: the packet is extracted from the frame and the network address in the packet is used for deciding where to send itSwitch: the entire frame is transported on the basis of its MAC address
multiprotocol router
- A router that can handle multiple network protocols
- either translate the protocols or leave connection for a higher protocol layer
5.5.3. Tunneling
- there is a common special case that is manageable even for different network protocols
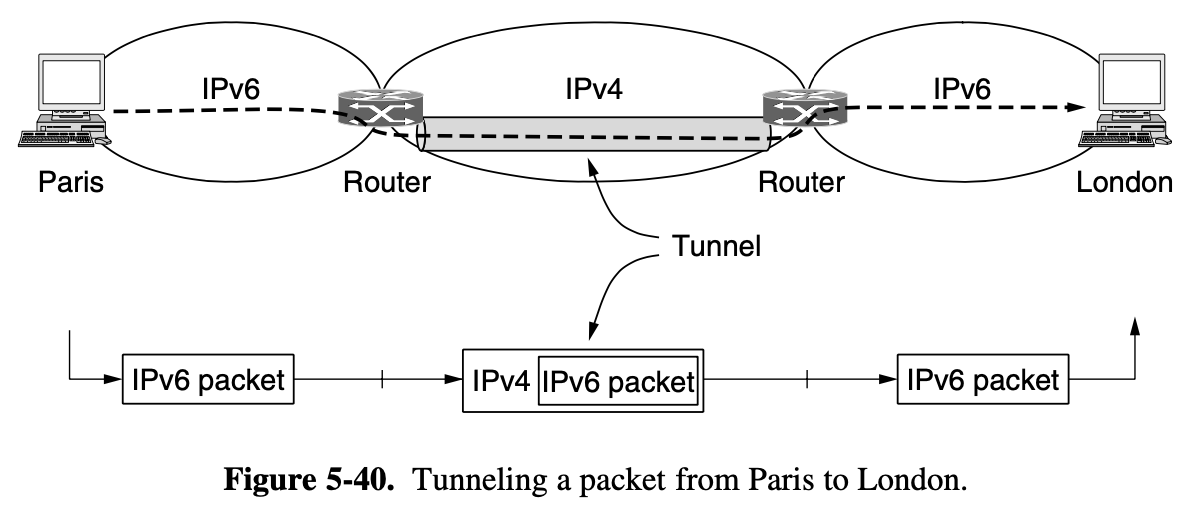
- The path through the IPv4 Internet can be seen as a big tunnel extending from one multiporotocol router to the other
- Tunneling is widely used to connect isolated hosts and networks using other networks
- The network that result is called an overlay
- the disadvantage of tunneling is that none of the hosts on the network that is tunneled over can be reached because the packets cannot escape in the middle of the tunnel
- this limitation of tunnels is turned into an advantage with VPNs (Virtual Private Networks)
- VPN is simply an overlay that is used to provide a measure of security
5.5.5. Packet Fragmentation
- Each network or link imposes some maximum size on its packets
- Hardware (e.g. the size of an Ethernet frame)
- Operating System (e.g. all buffers are 512 bytes)
- Protocols (e.g. the number of bits in the packet length field)
- compiance with som (inter)national standard
- Desire to reduce error-induced retransmission to some level
- Desire to prevent one packet from occupying the channel too long
- Hosts usually prefer to transmit large packets because this reduces packet overheads such as bandwidth wasted on header bytes
- An obvious internetworking problem appears when a large packet want to travel through a network whose maximum packet size is too small
[solution]
- make sure the problem does not occur in the first place
- source does not know how small ppackets must be to go there
- this packet size is called the Path MTU (Path Maximum Transmission Unit)
- allow routers to break up packets into fragments
- sending each fragment as a seperate network layer packet
- but have trouble putting the fragments back together again
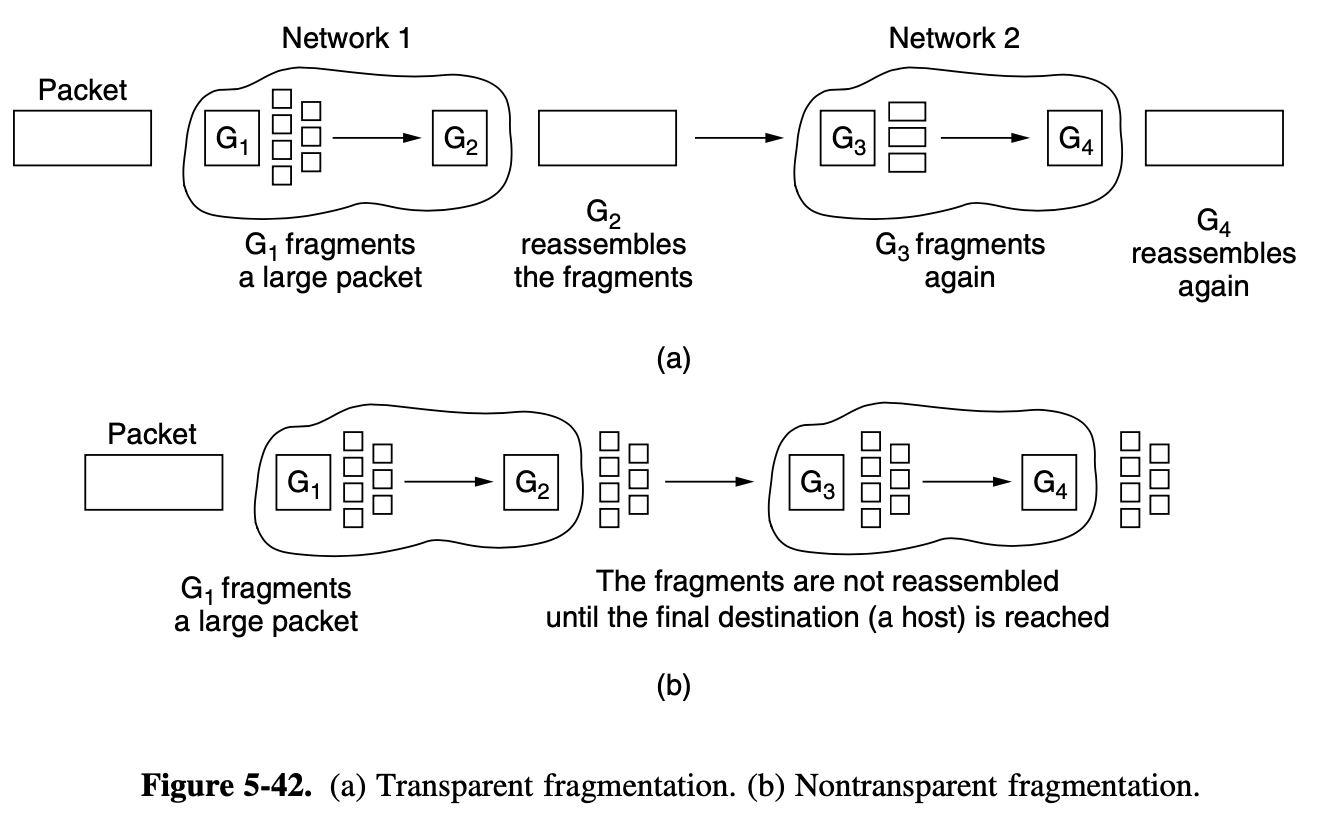
- main advantage of nontransparent fragmentation : requires routers to do less work. IP works this way
[nontransport fragmentation problem]
- overhead can be higher than with tranparent fragmentation
- because fragment headers are now carried over some links where they may not be needed
- existence of fragments in the first place
[fragmentation problem]
- header overheads
- a whole packet is lost if any of its fragments are lost
[solution]
- get rid of fragmentation in the network
path MTU discovery
- the source now knows what length packet to send
- If the routes and path MTU changes, new error packets will be triggered and the source will adapt to the new path
5.6.4. Internet Control Protocol
IMCP - The Internet Control Message Protocol
- When something unexpected occurs during packet processing at router, the event is report to the sender by ICMP (Internet Control Message Protocol)
- ICMP is also used to test the Internet
- Each ICMP message type is carried encapsulated in an IP packet
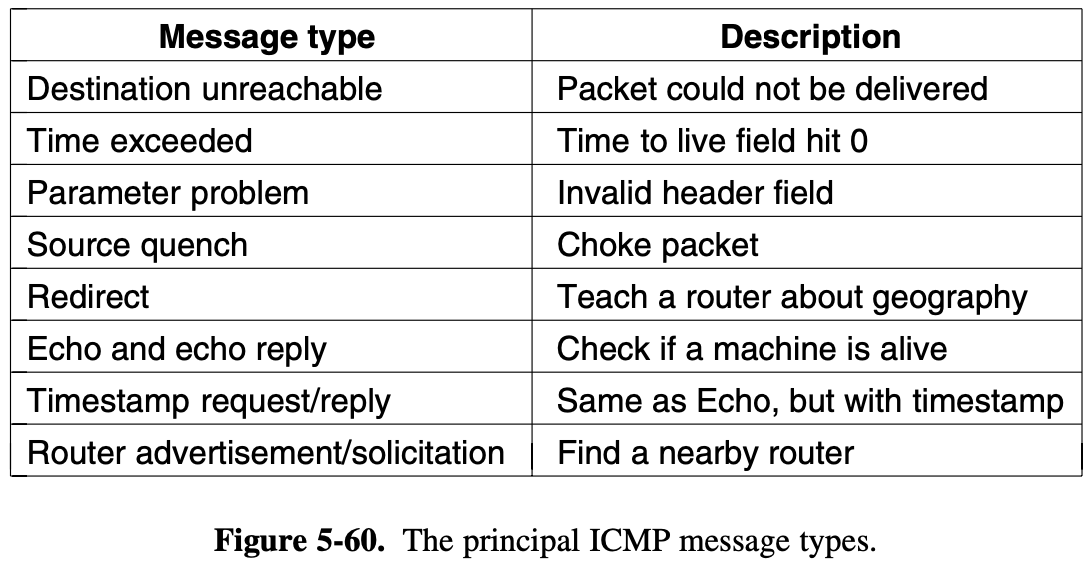
THE TIME EXCEEDED message: sent when a packet is dropped because its TtL counter has reached 0- One clever use of this error message is the traceroute utility
- Traceroute finds the routers along the path from the host to a destination IP address
ARP - The Address Resolution Protocol
- Although every machine on the Internet has one or more IP addreses, these addresses are not sufficient for sending packets
- Data link layer NICs (Network Interface Card) such as Ethernet cards do not understand internet addresses
- In the case of Ethernet, every NIC ever manufactured comes equipped with a unique 48-bit Ethernet address
Q) how do IP addresses get mapped onto data link layer addresses, such as Ethernet?
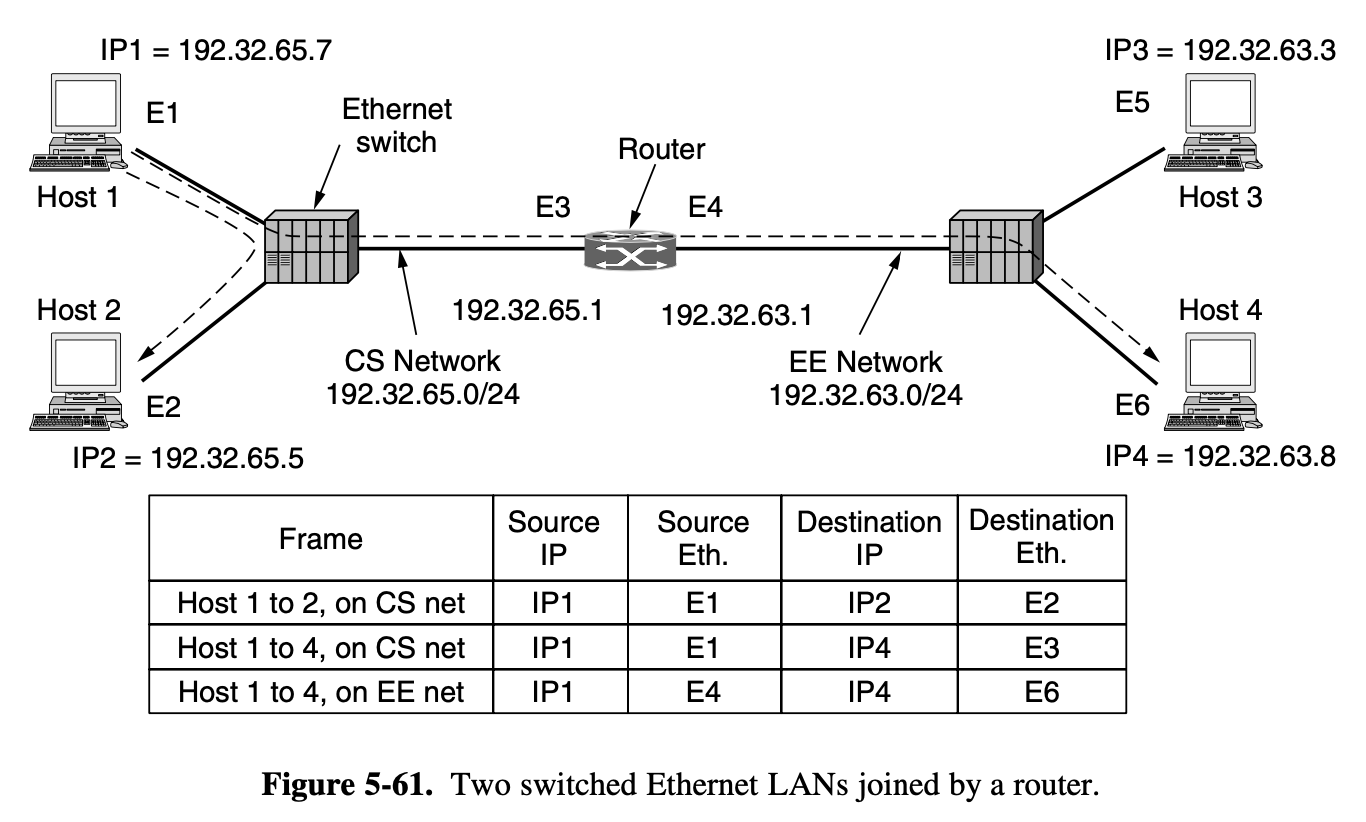
- broadcast packet on the Eternet asking who own IP address that we want to find
- The protocol used for asking this question and getting the reply
- Almost every machine on the internet runs it
DHCP - The Dynamic Host Configuration Protocol
Q) How do host get their own IP address?
- When a computer is started, it has a huil-in Ethernet or other link layer address embedded in the NIC, but no IP address
- if DHCP server is not directly attached to the network, the router will be configured to receive DHCP broadcasts and relay them to the DHCP server, wherever it located
- When the server received the request, it allocate a free IP address and sends it to the host in a DHCP OFFER packet
Q) how long an IP address should be allocated
- leasing : IP address assignment may be for a fixed period of time
- Just before lease expires, the host must ask for a DHCP renewal
5.6.5. Label Switching an MPLS (MultiProtocol Label Switching)
- add a label in front of each packet
- and forwarding is based on the label rather than on the destination address
- Using this technique, forwarding can be done very quickly
- flexible and forwarding that is suited to quality of service as well as fast
- IP packet were not designed for virtual circuits, there is no field avilable for virtual-circuit number within the IP header
- a new MPLS header had to be added in front of the IP header
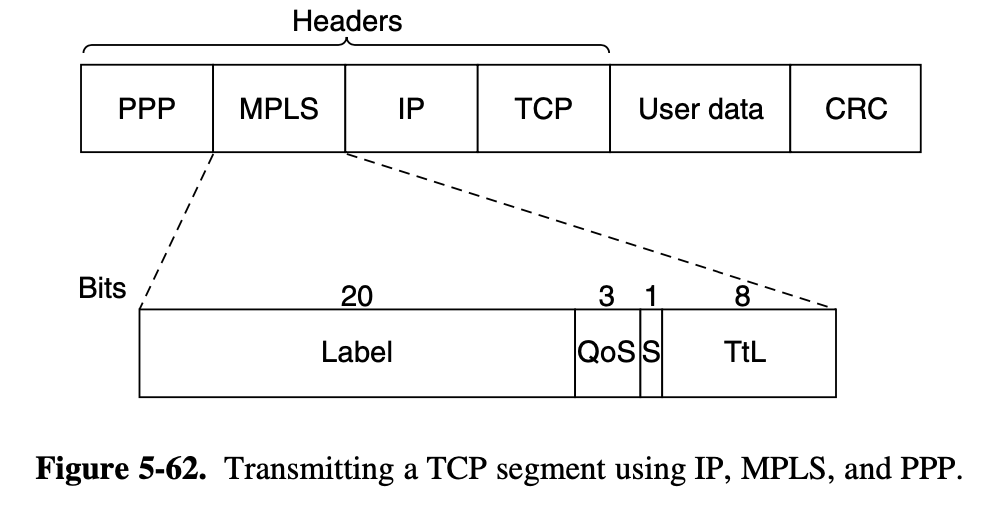
- When an MPLS-enhanced packet arrives at a LSR (Label Switched Router), the label is used as an index into a table to determine the outgoing line to use and also the new label to use
- this label swapping is used in all virtual-circuit networks
5.6.6. OSPF - An Interior Gateway Routing Protocol
- The internet is made up of a large number of independent networks or ASes (Autonomous Systems)
- Inside of its own network, an organization can use its own algorithm for internal routing or intrdomain routing
- An interdomain routing protocol is also called an interior gateway protocol
- OSPF spports both Point-to-Point links and braodcast networks
- it is able to support networks with multiple routers, each of which can communicate directly with the other (called multiaccess network)
backbone area : Every AS has, called are 0
backbone router : the router in backbone area
area border : Each router that is connected to 2 or more areas
stub area : routes to destinations out of the area always start with the instruction "Go to the border router"
AS boundary router : injects routes to external destinations on other ASes into the area
5.6.7. BGP - The Exterior Gateway Routing Protocol
- intradomain protocol : has to do is move packets as efficiently as possible from the source to the destination
- interdomain protocol : have to worry about politics a great deal
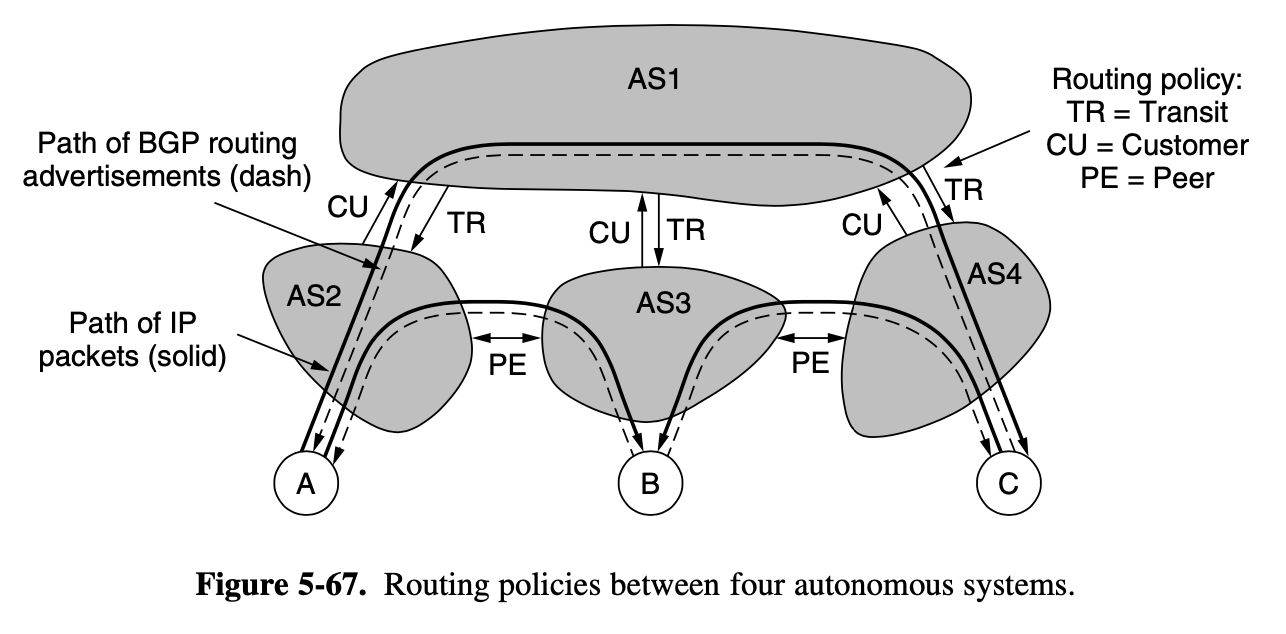
transit service : this is just like a customer at home buying internet access service from an ISP
- all of the oter ASes buy trasit service from AS1
- AS2, AS3 can send traffic directly to each other for free
- this will reduce the amount of traffic they must have AS1 deliver on their behalf
- This policy is called peering
- path vector protocol : The path consists of the next hop router and the sequence of ASes or AS Path, that the route has followed
- pair of BGP routers communicate with each other by establishing TCP connections
- pairs of BGP routers communicate with each other by establishing TCP connections
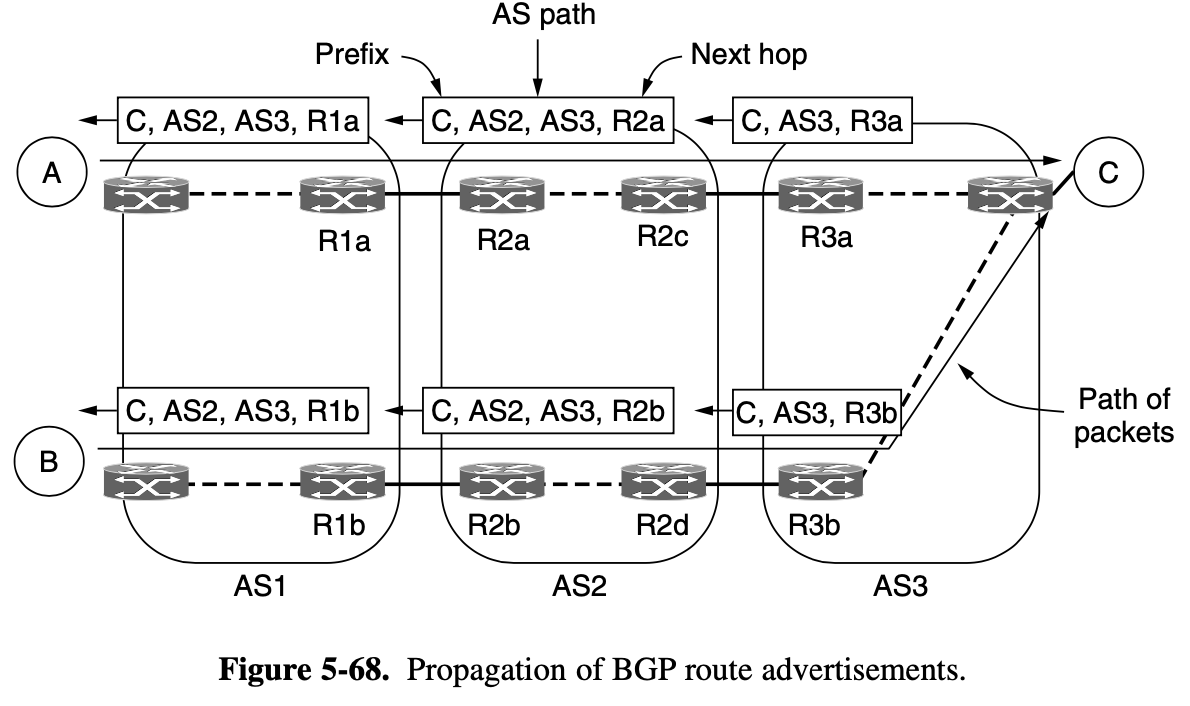
- The rule is that each router that sends a route outside of the AS prepends its own AS number to the route
- we still need some way to propagate BGP routes from one side of the ISP to the other
- so they can be sent on the next ISP
- This task could be handled by the interdomain protocol, but because BGP is very good at scaling to large networks, a variant of BGP is often used
- iBGP (internal BGP) , eBGP (external BGP)
5.6.8. Internet Multicasting
- Normal IP communication is between one sender and one receiver
- however some applications, it is useful for a process to be able to send to a large number of receivers simultaneously
ex) streaming live sport
- IP supports one-to-many communication, or multicasting using class D IP address
- Each class D address identified a group of hosts
- 28bits are available for identifying groups, so over 250 M groups can exist at the same time
- multicast router need to know which hosts are members of a group
- A process asks its host to join in a specific group
- it can also ask its host to leave the group
- when host leave the group, each multicast router sends a query packet to all the hosts on its LAN asking them to report back on the groups to which they currently belong
- These query and response packets use a IGMP (Internet Group Management Protocl)
5.6.9. Mobile IP
- when a mobile host show up at a foriegn site, it obtains a new IP address at the foriegn site
- the mobile then tells the home agent where it is now by giving it the care-of-address
- when a packet for the mobile arrives at the home site and the mobile is elsewhere
- the home agent grabs the packet and tunnels it to the mobile at the current care-of address
- The mobile can send reply packets directly to whoever it is communicating with, but still using its home address as the source address
- The IP address of the mobile does not change and the network path remains the same
- It is the wireless link that is providing mobility
- However the degree of mobility is limited
- If laptop moves to far, it will have to connect to the internet via another network with a different IP address
- RFC 3344 : the existing internet routing and allows hosts to stay connected with their own IP address as they move about
- For this to work, the mobile must be able do discover when it has moved
- This is accomplished with ICMP router advertisement and solicitation message
- Mobiles listen for periodic router advertisements or send a solicitation to discover the nearest router
- If router has changed since last time, the mobile has moved to another foreign network
- To get a care-of IP address on the foreign network, a mobile can simply use DHCP
- if IPv4 addresses are in short supploy, the mobile can send an receive packets via a foreign agent that already has an IP address on the network
- The mobile host finds a foreign agent using the same ICMP mechanism used to find the home agent
- After the mobile obtains an IP address or finds a foreign agent, it is able to used the network to send a message to its home agent, informing the home agent of its current location
- The home agent needs a way to intercept packets sent to the mobile only when the mobile it not at home
- ARP provides a convenient mechanism
- To send a packet over an Ethernet to an IP phost, the router need to know the Ethernet address of the host
- Tunneling to send a packet between the home agent and the mobile host at the care-of address is done by encapsulating the packet with another IP header destined for the care-of-address
- When the encapsulated packet arrives at the care-of-address, the outer IP header is removed to reveal the packet
ingres filtering : security measure intended to discard traffic with seemingly incorrect addresses that may be malicious
6. The Transpot Layer
6.1. The Transport Service
6.1.1. Services Provided to the Upper Layers
- the ultimate goal of the transport layer is to provide efficient, reliable, and cost-effective data transmission service to its users, normally processes in the application layer
- transport entity : software and/or hardware within the transport layer
- transport entity, can be located in the operating system kernel, in a library package bound into network applications, in a seperate user process, or even on the network interface card
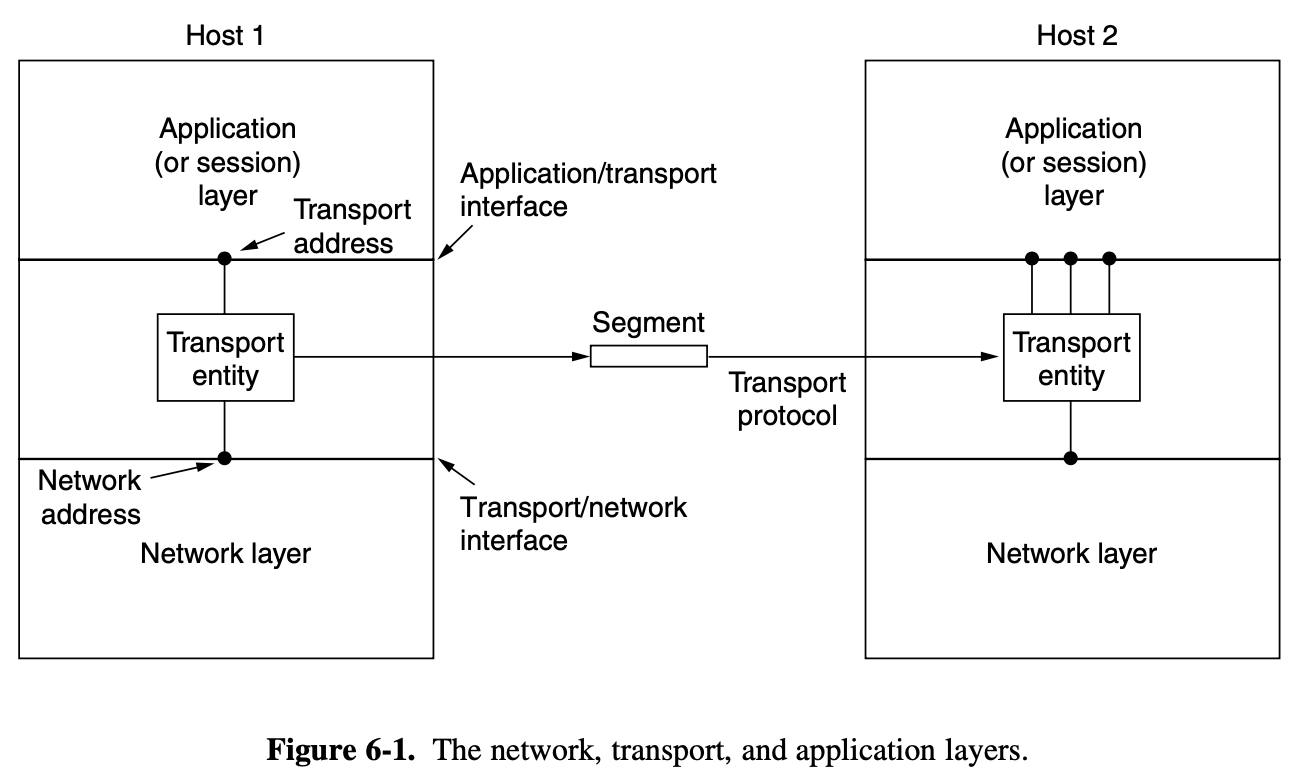
Q) if the transport layer service is so similar to the network layer service, why are there 2 distinct layer?
A) The transport code run entirely on the users' machines
but the network layer mostly runs on the routers, which are operated by the carrier
What happens if the network layer offeres inadequate service?
What if it frequently loses packets?
What happens if routers crash from time to time?
The only possibility is to put on top of the network layer another layer that improves the quality of the service
- The bottom 4 layers = transport service provider
- upper layers = transport service user
6.1.2. Transport Service Primitives
- Each transport service has its own interface
- The tranport service is similar to the network service, but there are also some important differences
[important differences]
- the network service is intended to model the service offered by real networks, warts and all
- Real networks can lose packets, so the network service is generally unreliable
- whom the services are intended for
- the network service is used only by the transport entities
- many prorams see the transport primitives
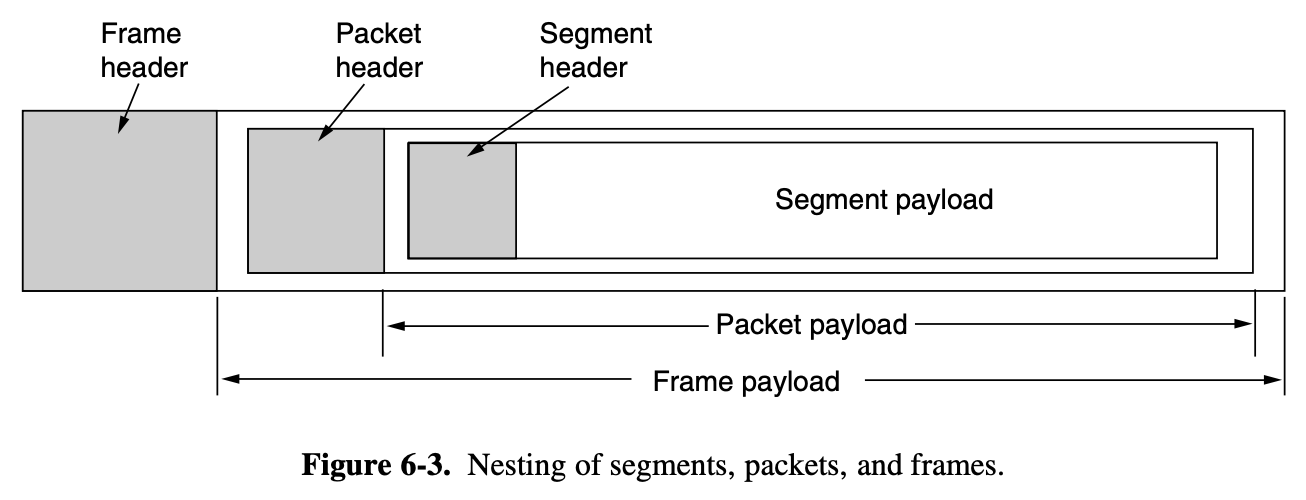
6.1.3. Berkeley Sockets
- The socket primitives as they are used for TCP
- Sockets were first released as part of the Berkeley UNIX 4.2BSD software distributio
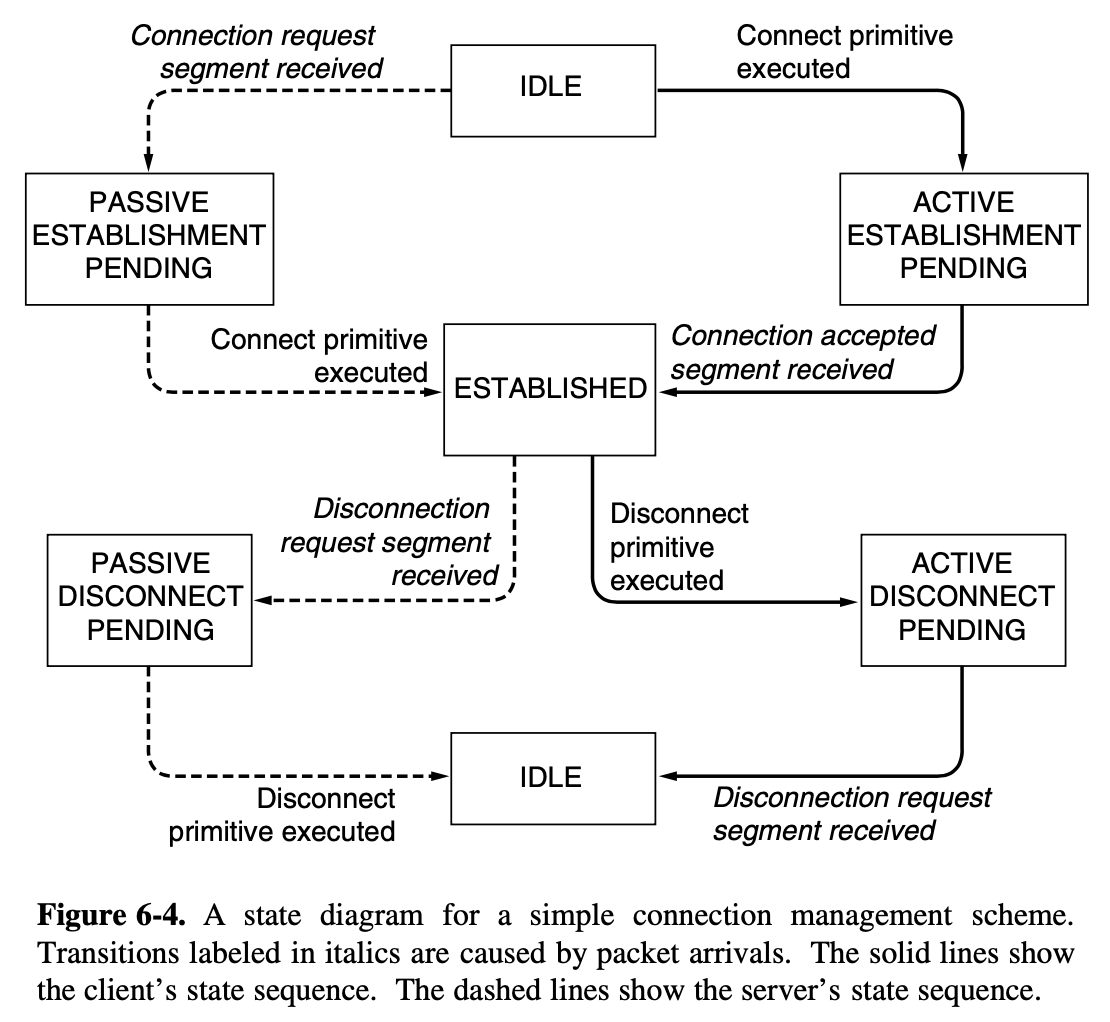
6.2. Elements of transport protocols
6.2.1. Addressing
- In the internet, these endpoints are called ports = TSAP (Transport Service Access Point)
- analogues endpoints in the network layer IP = NSAP (Network Service Access Point)
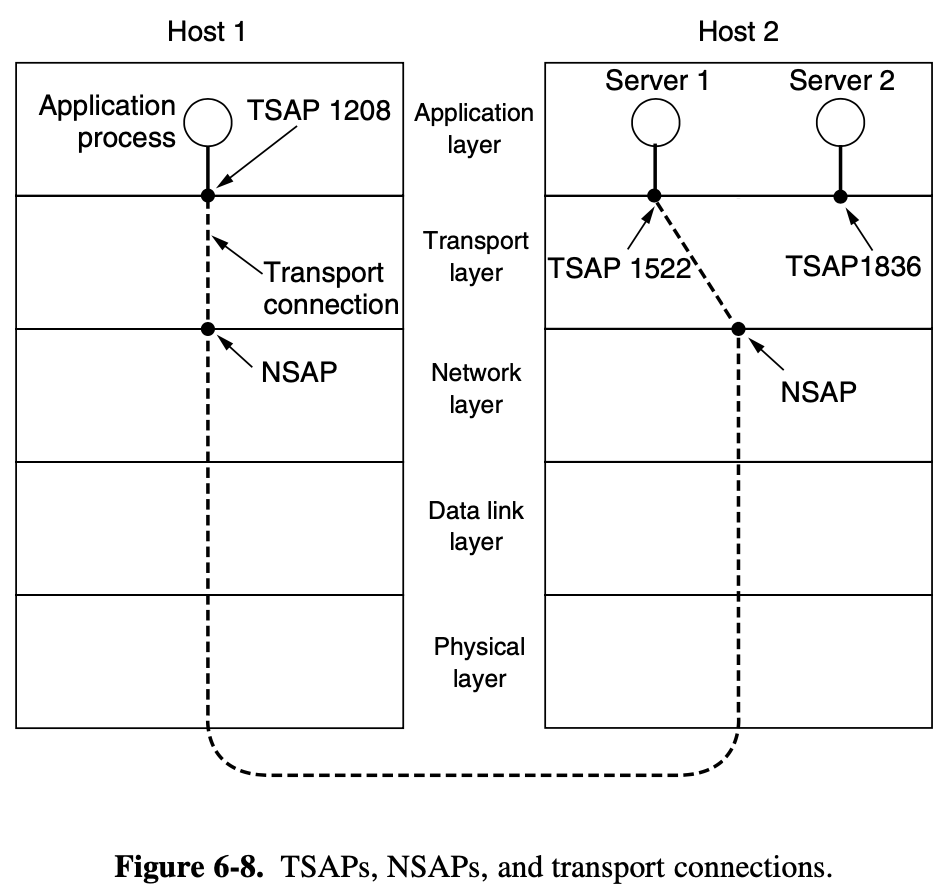
- host 1, host 2 's mail service are attached to other TSAPs and are waiting for incoming connections that arrvie over the same NSAP
- but mail service TCP port is 25
- so mail service has been attaching itelf to host 1's and host 2's alternately?
portmapper
- special process, to find the TSAP address corresponding to a given service name
- The user then sends a message specifying the service name, and the portmapper sends back the TASP address
- Then the user release the connection with the portmapper and establishes a new one with the desired service
- when a new service is created, it must register itself with the portmapper, giving both its service name and its TSAP
- it is wasteful to have each of them active and listening to a stable TSAP address all day long
initial connection protocol
- instead of every conceivable server listening at a well-known TSAP,
- each machine that wishes to offer services to remote users has a special process server that acts as a proxy for less heavily used servers
- the server is called inetd on UNIX systems
- it listens to a set of ports at the same time, waiting for a connection request
- Potential users of a service begin by doing a CONNECT request, sepcifying the TSAP address of the service the want
- if no server is waiting for them, they get connection to the process server
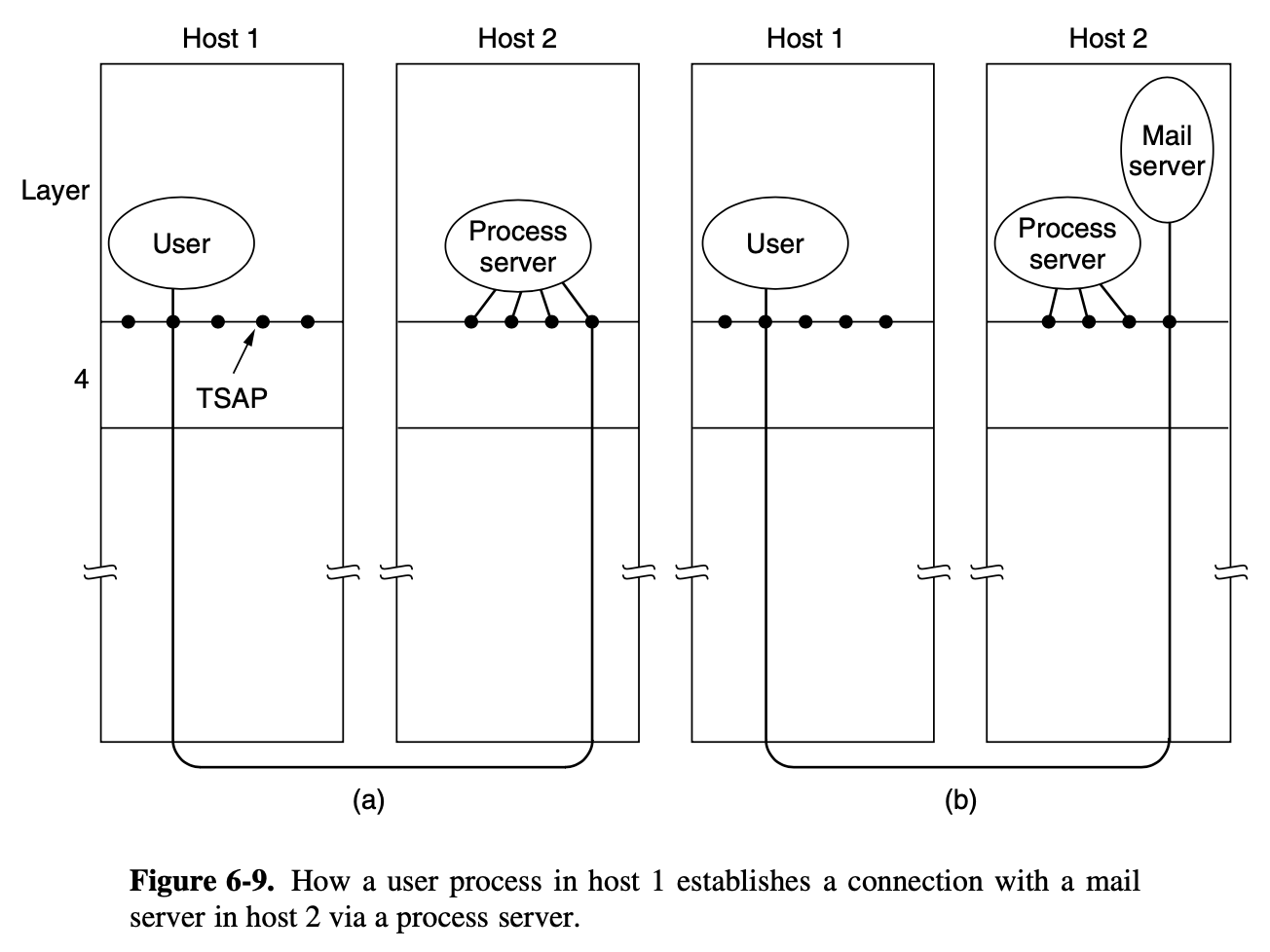
6.2.2. Connection Establishment
- we cannot prevent packets from being duplicated and delayed
- but if and when this happends, the packets must be rejected as duplicates and not processed as fresh packets
- each time a transport address is needed a new one is generated
- when a connection is released the address is discarded and never used again
- delayed duplicate packets then never find their way to a transport process and can do no damage
- however this approach makes it more difficult to connect with a process in the first place
- give each connection a unique identifier (i.e., sequence number incremented for each connection established)
- whenever a connection request comes in, it can be checked against the table to see if it belongs to a previously released connection
- but that sheme has a basic flaw
- it requires each transport entity to maintain a certain amount of history information indefinitely
- setting packet lifetime (rather than allowing packets to live forever within the network)
packet lifetime
- Restricted network design
- includes any method that prevent packets from looping etc
- it is difficult, given that internets may range from a single city to international in scope
- Putting a hop counter in each packet
- the network portocol simply discards any packet whose hop counter become zero
- Timestamping each packet
- each pacekt to bear the time it was created, with the routers agreeing to discard any packet older than some agreed-upon time
- the latter method requireds the router clocks to be synchronized, which itself is a nontrivial tasks
- period T : which is some small multiple of the true maximum packet lifetime
- conservative constant for a network
- it is somewhat arbitrarily taken to be 120 seconds
- the heart of the method is for the source to label segments with sequence number that will not be reused within T secs ⭐
- to keep packet sequence numbers out of the forbidden region, we need to take care in 2 respects
[2 repects]
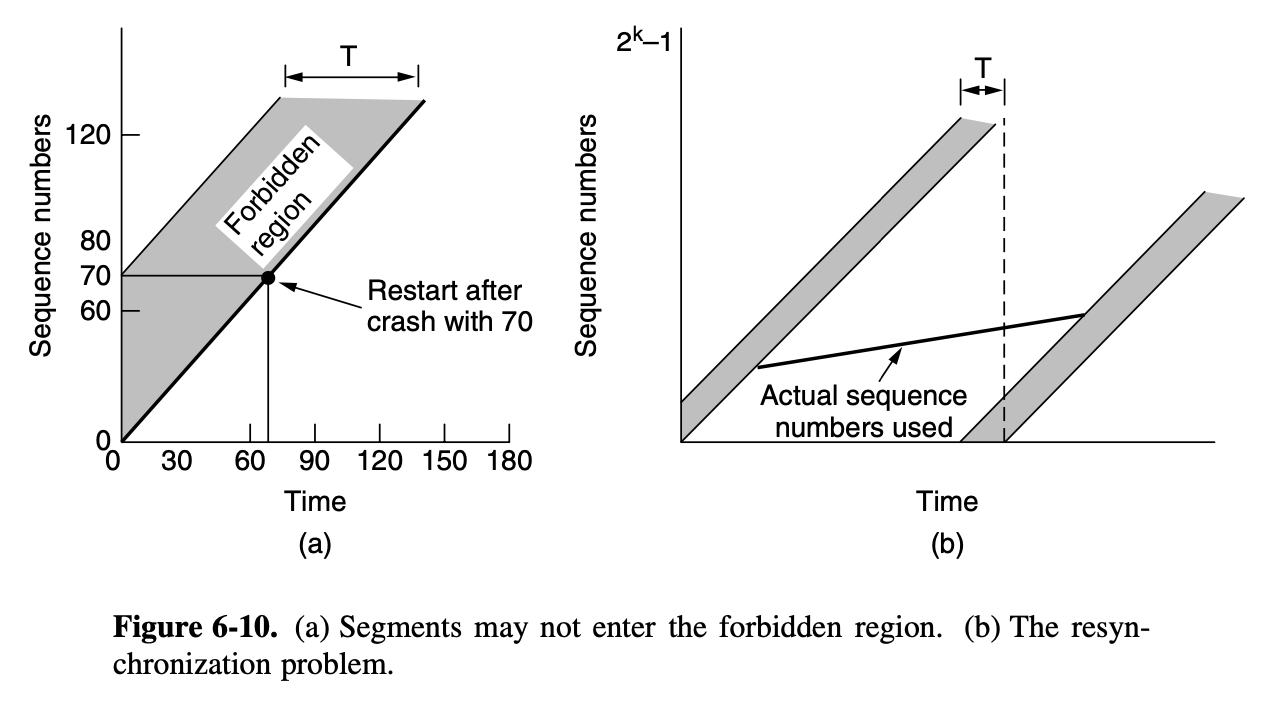
- if a host sends too much data too fast on a newly opend connection
- the actual sequence number versus time curve may rise more steeply
- that the initial sequence number versus time curve, causing the sequence number to enter the forbiden region
- to prevent this from happening, the maximum data rate on any connection is one segment per clock rate
- this also means that the transpor entity must wait until the clock ticks before opening a new connection after a crash restart, lest the same number be used twice
- any data rate less than the clock rate, the curve of actual sequence numbers used versus time will eventually run into the forbidden region from the left as the sequence numbers wrap around
- we do not normally remember sequence number across connections at the destination,
- we still have no way of knowing if a CONNECTION REQUEST segment containing an initial sequence number is a duplicate of a recent connection
- this snag does not exist during a connection because the sliding window protcol does remember the current sequence number
3-way handshaking
- this establish protocol involves one peer checking with the other that the connection request is indded current
- the host 1 chooses a sequence number x, and send a CONNECTION REQUEST segment containing it to host 2
- host 2 replies with an ACK segment acknowledges host 2's choice of an intial sequence number in the first data segment that it sends
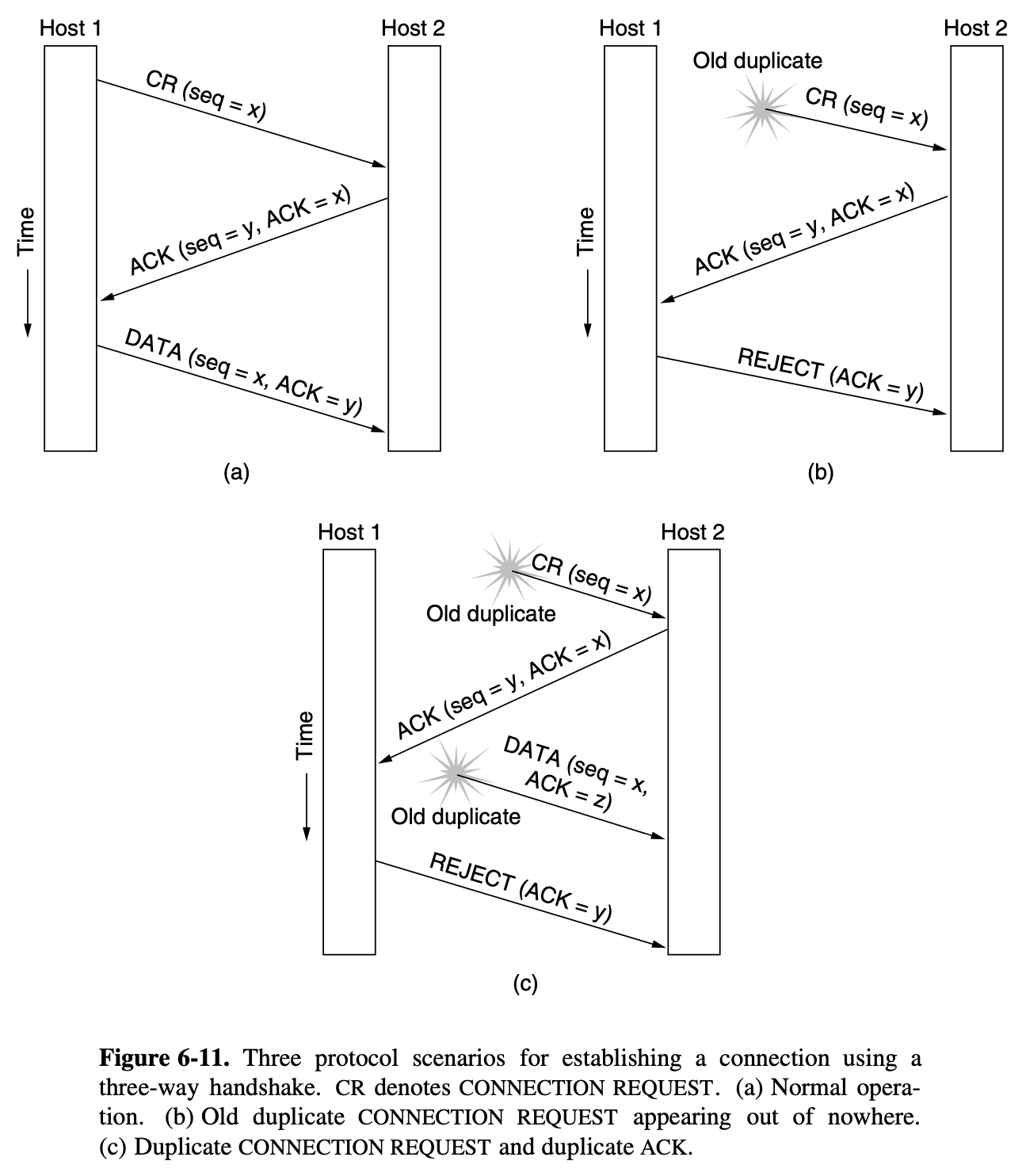
6.2.3. Connection Release
- Releasing a connection is easier than establishing one
- 2 style of connection : asymmetric release, symmetric release
Asymmetric release
- is abrupt and may result in data loss

- a more sophisticated release protocl is needed to avoid data loss
symmetric release
- each process has a fixed amount of data to send and clearly knows when it has sent it
- determining that all the work has been done and the connection should be terminated is not so obvious
- so host 1 says "i am done, are you done too?" host 2 says "i am done too, goodbye"
2 army problem
- this protocol is not always work
- there is famous problem that illustrates this issue
- blue army have to attack white army synchronously they can get victory
- how to they communicate thier war date?
blue army #1 (alias, #1) : i propose we attach at dawn on 3/29
blue army #2 (alias, #2) : agree
- but #2 does not know if his relay got through
- if it did not, #1 will not attack so it would be foolish for hime to charge into battle
- we could now 4-way handshake but that does not help either
6.2.4. Error Control and Flow Control
[data link error control and flow control]
-
A frame carries an error-detecting code (e.g. CRC, checksum) that is used to check if the information was correctly received
-
ARQ (Automatic Repeat reQuest)
- A frame carries a sequence number to identify itself and is retransmitted by the sender until it receives an acknowlegement of successful receipt from the receiver
- stop-and-wait
- there is maximum number of frames that the sender will allow to be outstanding at any time
- pausing if the receiver is not acknowledging frames quickly enough
- sliding window
- combines these features and is also used to support bidirectional data transfer
- for difference in function, error detection
- the transport layer checksum protects a segment while it crosses an entire network path
- it is an end-to-end check, which is not the same as habing a check on every link
- as a diference in degree consider retransmissions and sliding window protocol
- most wireless links can have only a single frame outstanding from the sender at a time
- that is the bandwidth-delay product for the link is amll enough that not even a whole frame can be stored inside the link
- on the other hand, many TCP connections have a bandwidth-delay product that is much larger than a single segment
- given that transport protocols generally use larger sliding windows, we will look at the issue of buffering data more carefully
- since the sender is buffering, the receiver may or may not dedicate specific buffers to specific connections as it see fit
- the bes trde-off between source buffering and destination buffering depends on the type of traffic carried by the connection
- there is still remains the question of how to organize the buffer pool
- As connections are opend and closed and as the traffic pattern changes, the sender and receiver need to dynamically adjust their buffer allocations
- buffers could be allocated per connection, or collectively, for all the connections running between the 2 hosts
- a reasonably general way to manage dynamic buffer allocation is to decouple the buffering from the acknowlegement
- dynamic buffer management means, in effetc, a variable-sized window

- initially, the sender requests a certain number of buffers, based on its expected needs
- the receiver then grant as many of these as it can afford
- Every time the sender transmits a segment, it must decrement its allocation, stopping altogether when the allocation reaches 0
- the receiver separately piggybacks both acknowledements and buffer allocations onto the reverse traffic
- TCP uses this scheme, carrying buffer allocation in a header field called Window Size
- limits transmissions from the sender based on the network's carrying capacity rather than on the receiver's buffering capacity
- dynamic sliding window can implement both flow control and congestion control
6.2.5. Multiplexing
- multiplexing can also be useful in the transport layer for another reason
inverse multiplexing
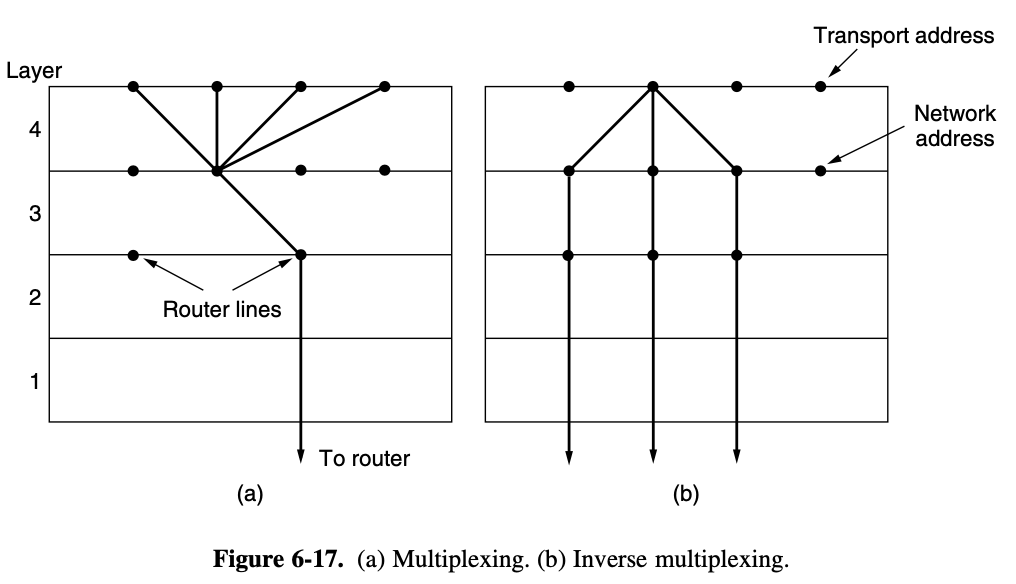
ex) SCTP (Stream Control Transmission Protocol)
- that a host has multiple network paths that it can use
- if a user needs more bandwidth or more reliability than one of the network paths can provide
- a way out is to have a connection that distributes the traffic among multiple network paths on a round-robin basis
6.3. Congestion control
6.3.1. Desirable bandwidth allocation
Efficiency and Power
- if 100 Mbps link, 5 transport entities should get 20 Mbps each
- they should usually get less than 20 Mbps for good performance
- The reason is that the traffic is often bursty
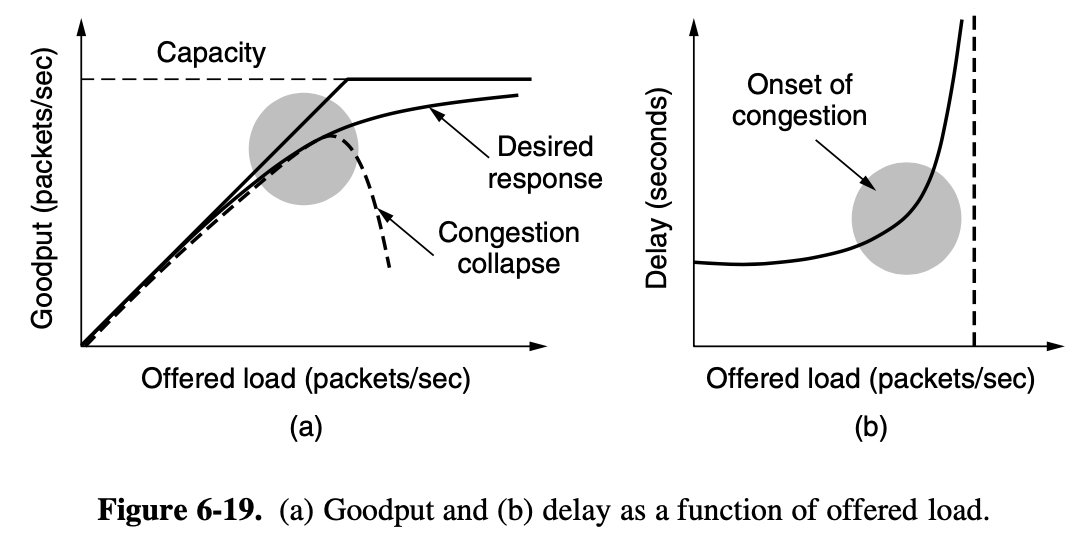
- goodput : rate of useful packets arriving at the receiver
Max-Min Fairness
- how to divide bandwidth between different transport senders
- if the network gives a sender som amount of bandwidth to use, the sender should just use that much bandwidth
- however it if often the case that networks do not have a strict bandwidth reservation for each flow or connection
- the form of fairness that is often desired for network usage is max-min fairness
- if the bandwidth given to one flow cannot be increased without decreasing the bandwidth given to another flow with an allocation that is no larger
- that is increasing the bandwidth of a flow will only make the situation worse for flows that are less will off
- Max-min allocations can be computed given a global knowledge of the network
- an intuitive way to think about them is to imagine that the rate for all of the flows starts at zero and is slowly increased
- when the rate reaches a bottleneck for any flow, then that flow stops increasing
- the other flow all continues to increase, sharig equally in the available capacity, until they too reach their respective bottlenecks
Convergence
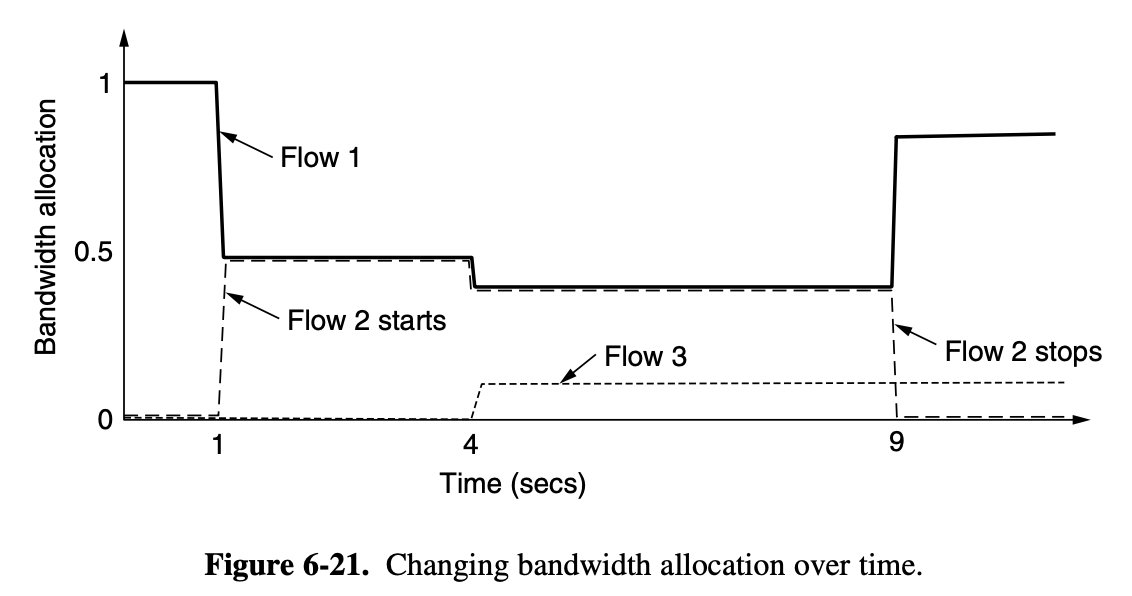
- the ideal operating point for the network varies over time
- A good congestion control algorithm should rapidly converge to the ideal operating point
- and it should track that point as it changes over time
- if the convergence is too slow, the algorithm will never be close to the changing operating point
6.3.2. Regulating the Sending Rate
[sending rate may be limited by 2 factors]
- flow control : insufficient buffering at the receiver
- congestion : insufficient capacity in the network
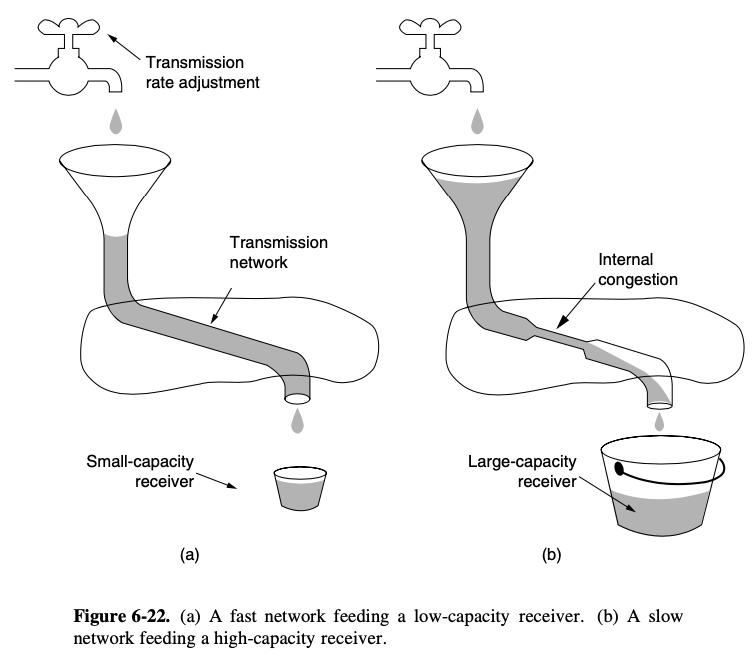
[router tell the sources the rate at which they may send]
- XCP (eXplicit Congestion Protocol)
- routers set bits on packets that experience congestion to warn the senders to slow down, but they do not tell them how much to slow down
- FAST TCP
- measures the round trip delay and uses that metric as a signal to avoid congestion
- TCP with drop-tail or RED routers, packet loss is inferred and used to signal that the network has become congested
- When the congestion signal is given, the sender should decrease their rates
- The way in which the rates are increased or decrease is given by a control law
AIMD (Additive Increase Multiplicative Decrease)
- when the allocations sum to 100% the capacity of the link, th allocation is efficient
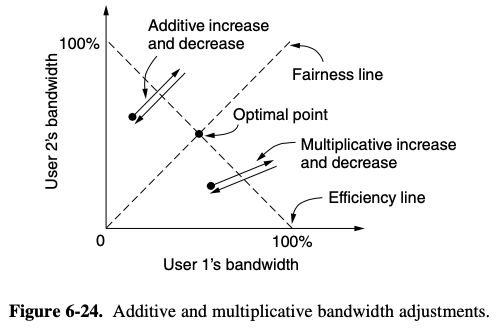
- AIMD is the control law that is used by TCP, based on this argument and another stability argument
- TCP connections adjust thier window size by a given amount every round-trip time
What will happen if the different protocols compete with different control laws to avoid congestion?
- since TCP is the cominant form of congestion control in the internet
- there is significant community pressure for new transport protocols to be designed so that they compete fairly with it
- the early streaming media protocols caused problems by excessively reducing TCP throughput because they didnot compete fairly
- this led to the notion of TCP-friendly
6.3.3. Wireless Issues
- the main issue is that packet loss is often used as a congestion signal
- With the AIMD control law, high throughput requires very small levels of packet loss
- in practice is that the loss rate for fast TCP connections is very small : 1$ is moderate loss rate
- by the time the loss rate reaches 10% the connection has effectively stopped working
- However, for wireless networks such as 802.11 LANs, frame loss rates of at least 10% are common
- wireless losses by using retransmissions over the wireless lnk
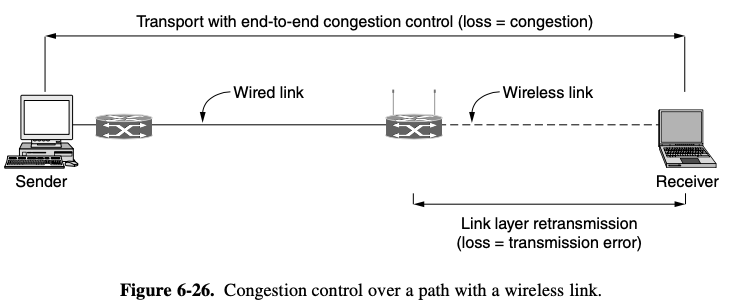
- puzzle (얘가 그러는데 자기도 모르겠대)
- link layer frame retransmissions, transport layer congestion control
- puzzle is how these 2 mechanisms can co-exist without getting confused
- a loss should cause only one mechanism to take action because it is either a transmission error or a congestion signal
6.4. The internet transport protocols: UDP
6.4.1. Introduction to UDP (User Datagram Protocol)
- UDP transmit segments consisting of an 8-byte header followed by the payload
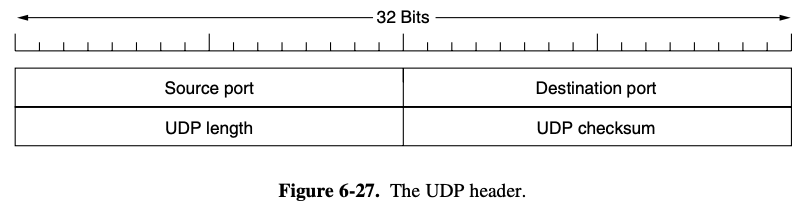

6.4.2. Remote Procedure Call
RPC (Remote Procedure Call)
- Birrell and Nelson suggested was allowing programs to call
- idea behind RPC is to make a remote procedure call look as much as possible like a local one
- client stub : to call a remote procedure, the client program must be bound with a small library procedure
- server stub : the server is bound with a procedure
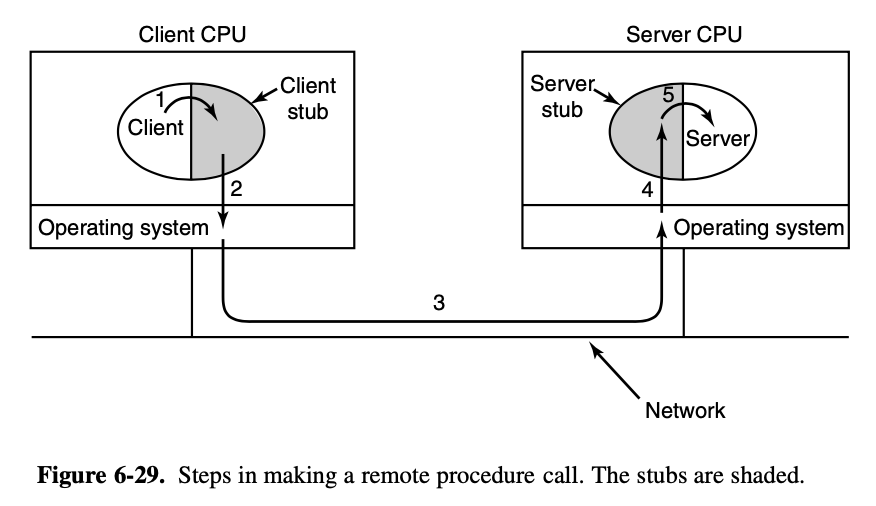
- With RPC, passing pointers is impossible because the client and server are in different address spaces
6.4.3. Real-Time Transport Protocols
- Client-Server RPC is one area in which UDP is widely used
- Another one is for real-time multimedia applications
RTP (Real-time Transport Protocol)
- RTP protocol for transporting audio and video data in packets
- the processing that takes place, mostly at the receiver, to play out the audio and video at the right time
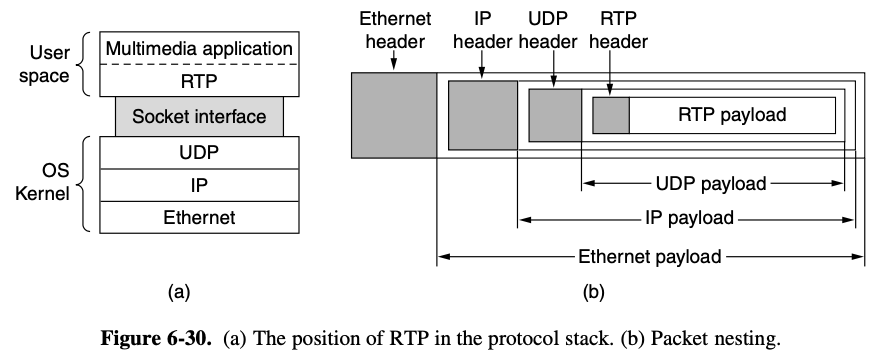
- RTP normally runs in user space over UDP (in the operating system)
[it operates as follows]
- the multimedia application consists of multiple audio, video, text and possibly other streams
- these are fed into the RTP library, which is in user space along with the application
- This library multiplexes the streams and encodes them in RTP packets, which it stuffs into a socket
- UDP packets are generated to wrap the RTP packets and handed to IP for transmission over a link such as Ethernet
- The reverse process happens at the receiver
- The multimedia application eventually receives multimedia data from the RTP library
- The basic function of RTP is to multiplex several real-time data streams onto a single stream of UDP packets
- The UDP stream can be sent to a single destination (unicasting) or to multiple destinations (multicasting)
- RTP just uses normal UDP, its packets are not treated specially by the routers unless some normal IP quality-of-service features are enable
- The RTP format contains several features to help receivers work with multimedia information
- Each packet sent in an RTP stream is given a number one higher than its predecessor
- This numbering allows the destination to determine if any packets are missing
- if a packet is missing, the best action for the destination to take is up to the applicatio
- retransmission is not a practical option since the retransmitted packet would probably arrive too late to be useful
- RTP has no acknowledgements and no mechanism to request retransmissions
- Eact RTP payload may contain multiple samples, and they may be coded anyway that the application wants
- To allow for interworking, RTP defines several profiles, and for each profile, multiple encoding formats may be allowed
- RTP provides a header field in which the source can specify the encoding but is otherwise not involved in how encoding is donw
- Another facility many real-time applications need is timestamping
- allow the source to associate a timestamp with the first sample in each packet
- the timestamps are relative to the start of the stream
- only differences between timestamps are significant
- not only does timestamping reduce the effects of variation in network delay, but it also allows multiple streams to be synchronized with each other
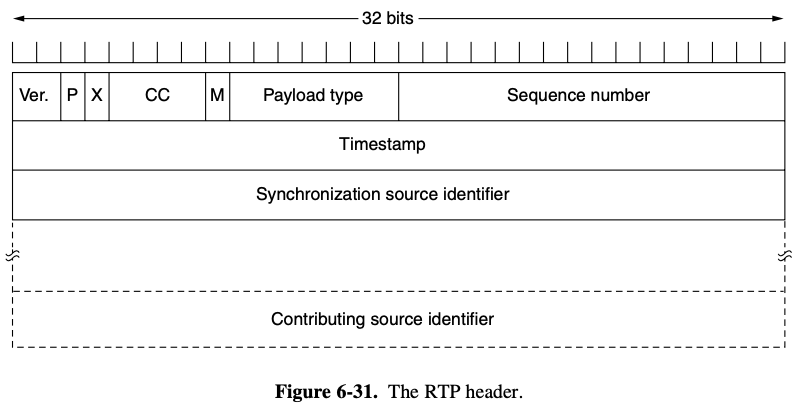
RTCP - The Real-tiem Transport Control Protocol
- RTP has a little sister protocol called RTCP
- can be used to provide feedback on delay, variation in delay or jitter, bandwidth, congestion and other network properties to the sources
- issue with providing feedback is that RTCP reports are sent to all participants
- for multicast application with a large group, the bandwidth used by RTCP would quickly grow large
- To prevent this from happening, RTCP senders scale down the rate of their reports to collectively consume no more than, say 5% of the media bandwidth
- interstream synchronization
- different streams may use different clocks, with different granularities and differrent drift rate
- RTCP can be used to keep them in sync
- provide a way for naming the various sources
- this information can be displayed on the receiver's screen to indicate who is talking at the moment
Playout with Buffering and Jitter Control
- once the media information reaches the receiver, it must be played out at the right time
+) jitter : variation in delay
- even if the packets are injected with exactly the right intervals between them at the sender
- they will reach the receiver with different relative times
- the solution to jitter is to buffer packets at the receiver before they are played out to reduce the jitter
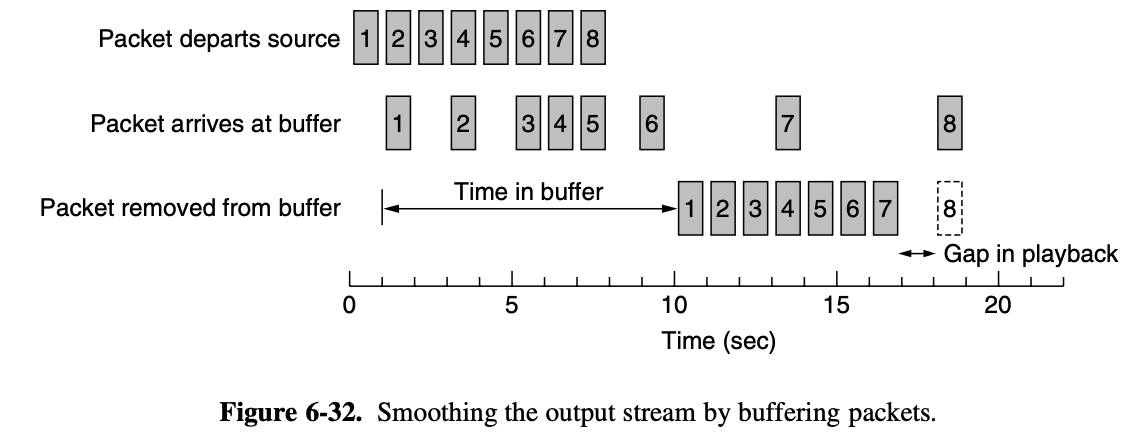
[when packet 8 has been delayed]
- packet 8 can be skipped (ex) live media, voice-over-IP call)
- stop until packet 8 arrives (ex) streaming media player)
- playback point : a key consideration for smooth playout
- how long to wait at the receiver for media before playing it out
- deciding how long to wait depends on the jitter
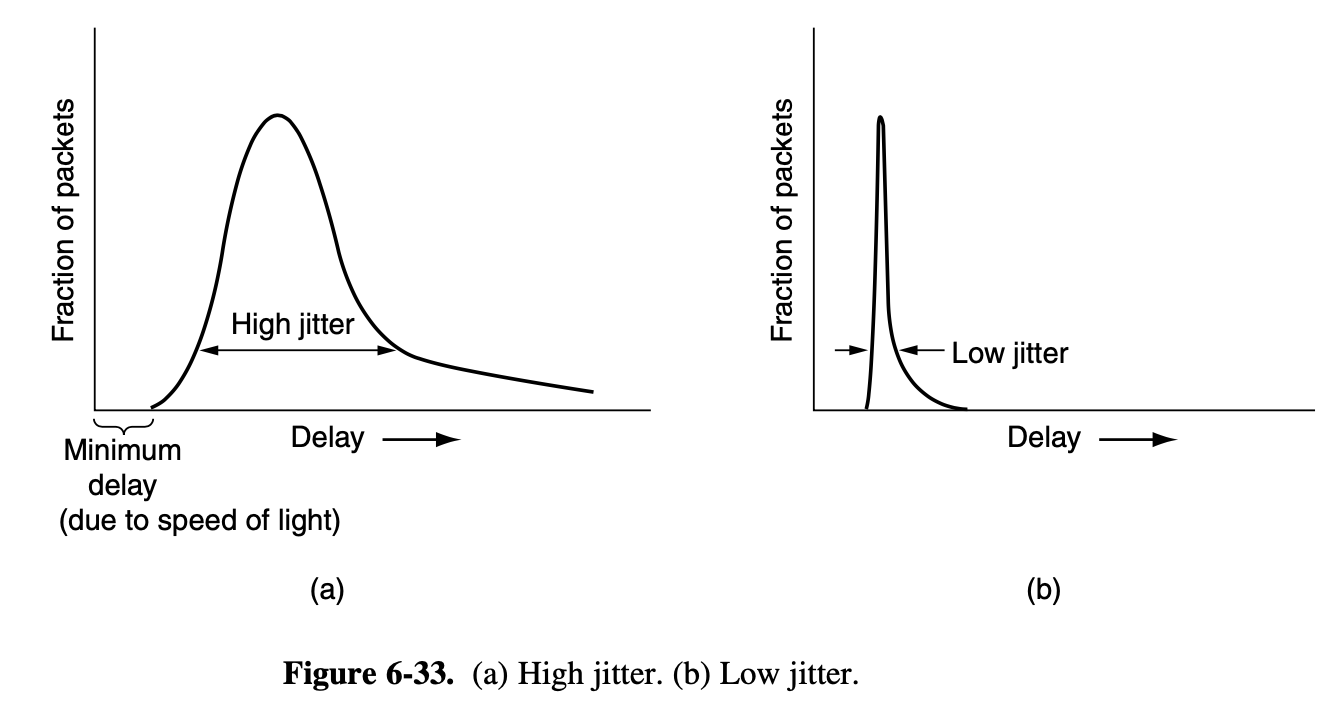
- to pick a good playback point, the application can measure the jitter by looking at the different between the RTP timestamps and the arrival time
- the delay can change over time due to other, competing traffic and changing routes
- to accomodate this change, applications can adapt their playback point while they are running
- however if not done well, changing the playback point can produce an observable glitch to the user
- one way to avoid this problem for audio is to adapt the playback point between talkspurts in the gap in a converstaion
- no one will notice the difference between a short and slightly longer silence
- the playback point can be pulled in by simply accepting that a larger fraction of packets wil arvie too late to be played
- if this is not acceptable, the only way to pull in the playback point is to reduce the jitter by using a better qulity of service
6.5. The internet transport protocols: TCP
6.5.1. Introduction to TCP (Transmission Control Protocol)
- specifically designed to provide a reliable end-to-end byte stream over an unreliable internetwork
- each machine supporting TCP has a TCP transport entity, either a library procedure, a user process, or most commonly part of the kernel
- a tcp entity accepts user data streams from local processes, breaks them p into pieces not excedding 64KB
- and sends piece as a seperate IP datagram
- it is up to TCP to send datagrams fast enough to make use of the capacity but not cause congestion and to time out and retransmit any datagrams that are not delivered
- datagrsma that do arrive may well do so in the wrong order; it is also up to TCP to reassemble them into messages in the proper seeuqnce
6.5.2. The TCP Service Model
- TCP service is obtained by both the sender and the receiver creating end points, called socket
- Each socket has a socket number consisting of the IP address of the host and a 16bit number local to that host called a port
- port is the TCP name for a TSAP
- A socket may be used for multiple connections at the same time
- in other words, 2 or more connections may terminateds at the same time
- no virtual circuit numbers or other identifiers are used
- well-known ports : Port numbers below 1024 are reserved for standard services that can usually only be started by privileged users
- FTP daemon attach itself to port 21 at boot time
- the SSH daemon attach itself to port 22 at boot time
- however doing so would clutter up memory with daemons that were idle most of the time
- instead, what is commonly done is to have a single daemon, called inetd (internet daemon) in Unix, attach itself to multiple ports and wait for the first incoming connection
[When it occurs]
- inetd forks off a new process and executes the appropriate daemon in it
- letting that daemon handle the request
- the daemon other than inetd are only active when there is work for them to do
- All TCp conenctions are full duplex and point-to-point
- Full duplex : traffic can go in both directions at the same time
- Point-to-point : each connection has exactly 2 end points
- TCP does not support multicasting for broadcasting
- A TCP connection is a bte stream, not a message stream
- Message boundaries are not preserved end to end
ex) the sending process does 4 512 bytes writes to a TCP stream
these data may be delivered to the receiving process as 4 512 byte chunks, 2 1024 byte chunks, 2048 byte chunk or some other way
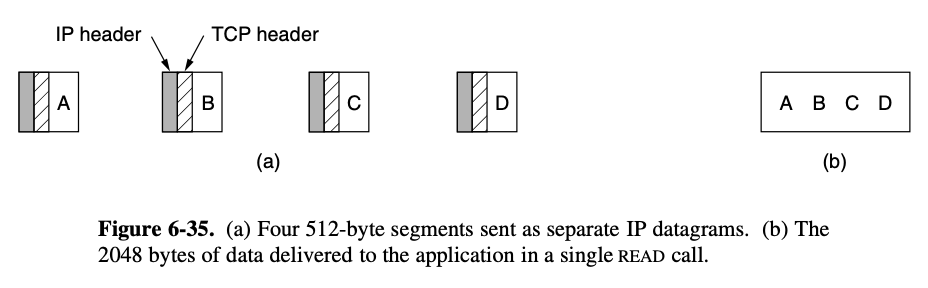
- the reader of a file cannot tell whether the file was written a block at a time, a byte at a time, or all in one blow
- as with unix file, the TCP software has no idea of what the bytes mean and no interest to finding out
- when an application passes data to TCP
- TCP may send it immediately or buffer it, as its discretion
- however, sometimes the application really wants to data to be send immediately
- to force data out, TCP has the notion of a PUSH flat that is carried on packets
- however applications cannot literally set the PUSH flag when they send data
- instead different operating system have evolved different options to expedite transmission
(중요한 내용은 아닌듯..?)
- TCP service that remains in the protocol but is rarely used: urgent data
- when an application has high priority data that should be processed immediately
- This event cause TCP to stop accumulating data and transmit everthing it has for that connection immediately
ex) CTRL_C key to break off a remote computation
6.5.3. The TCP Protocol
- a key feature of TCP, and one that cominates the protocol design is that every byte on a TCP connection has its own 32-bit sequence number
- seperate 32 bit sequence numbers are carried on packets for the sliding window position in one direction and for acknowledgement in the reverse direction
TCP Segment
- fixed 20 byte header followed by 0 or moer data bytes
- TCP software decides how big segment should be
[2 limits restrict the segment size]
- each segment, including the TCP header, must fit in the 65,515 byte IP Payload
- each link has an MTU (Maximum Transfer Unit) : generally 1500 bytes
+) however, it is still possible for IP packets carrying TCP segments to be fragmented when passing over a network path for which some link has a small MTU
- mordern TCP implementations perform path MTU discovery
- The basic protocol used by TCP entities is the sliding window protocol with a dynamic window size
- When a sender transmits a segment, it also start a timer
- when the segment arrives at the destination, the receiving TCP entity sends back a segment bearing an acknowledgement number equal to the next sequence number it expects to receive and the remaining window size
- segments can also be delayed so long in transit that the sender times out and retransmits them
- the retransmissions may include different bytes ranges than the original transmission, requiring careful administration to keep track of which bytes have been correctly received so far
6.5.4. The TCP Segment Header
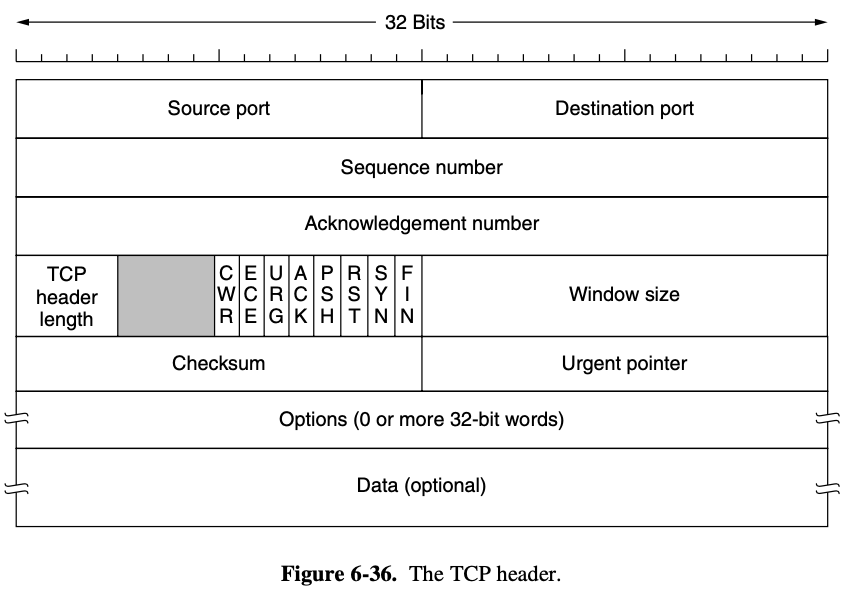
- next in-order byte expected, not the last byte correctly received, cumulative acknowledgement
- it summarize the received data with a single number
SACK (Selective ACKnowledgement)
- lets a receiver tell a sender the ranges of sequence numbers that is has received
- it supplements the Acknowledgement number and is used after a packet has been lost but subsequent data has arrived
6.5.5. TCP connection establishment

- the initial sequence number chosen by each host sould cycle slowly rather than be constant such as 0
- the rule is to protect against delayed duplicate packets
- orignally this was accomplished with a clock-based schema in which the clock ticked every 4μsec
SYN flood
- however a vulnerability with implementing the 3 way handshake is that the listening process must remember its sequence number as soon it responds with its own SYN segment
- this measn that malicious sender can tie up resources on a host by sending a stream of SYN segments and never following through to complete the connection
Mbr/>
SYN cookie
- instead of remembering the sequence number, a host chooses a cryptographically generated sequence number, puts it on the outgoing segment, and forgets it
- if the 3 way handshake completes, this sequence number will be returned to the host
- it can then regenerate the correct sequence number by running the same cryptographic function, as long as the inputs to that function are known
- this procedure allow the host to check that an acknowledged sequence number is correct without having to remember the sequence number seperately
6.5.6. TCP Connection Release
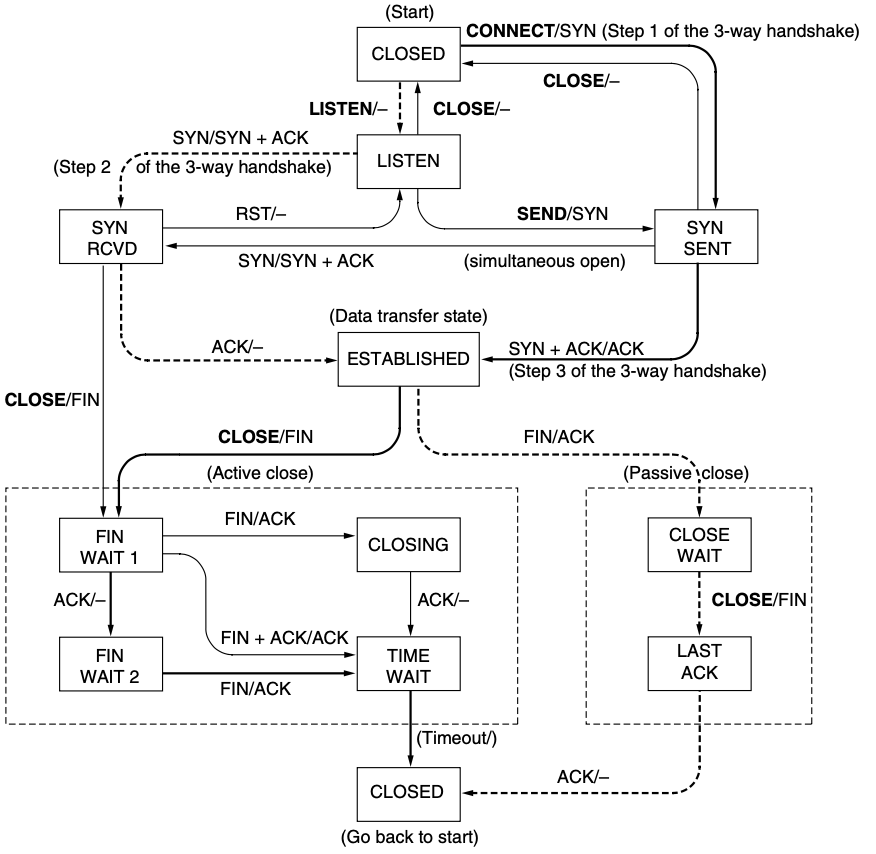
6.5.8. TCP Sliding Window
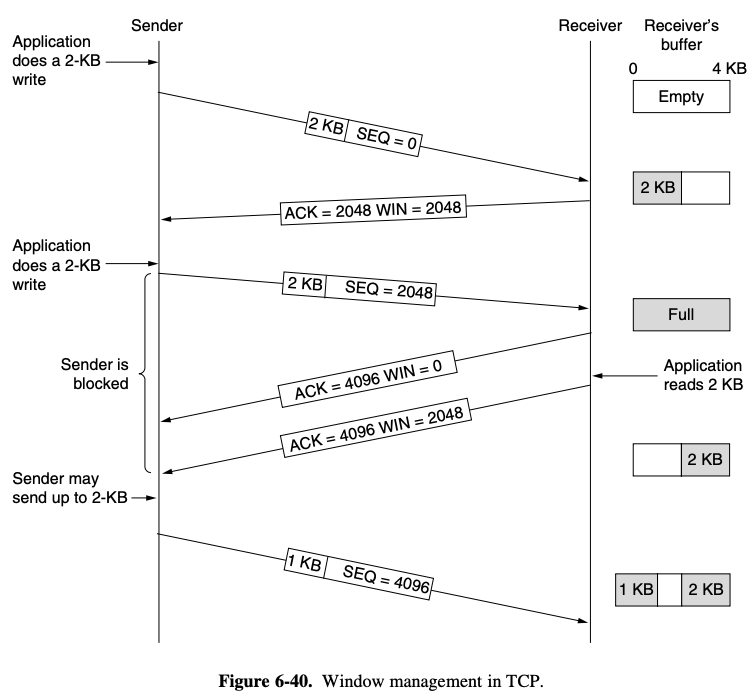
- When the window is 0, the sender may not normally send segments, with 2 exceptions
- urgent data may be sent
- the sender may send a 1 byte segment to force the receiver to reannounce the next byte expected and the window size (window probe)
- one approach that many TCP implementations use to optimize this situation is called delayed acknowledgements
- the idea is to delay acknowledgements and window updates for up to 500 msec in the hop of acquiring some data on which to hitch a free ride
nagle's algorithm
- when data come into the sender in small pieces, just send the first piece and buffer all the rest until the first piece is acknowledged
- then send all the buffered data in one TCP segment and start buffering again until the next segment is acknoledgement
- that is only one short packet can be outstanding any time
- widely used by TCP implementations
silly window syndrome
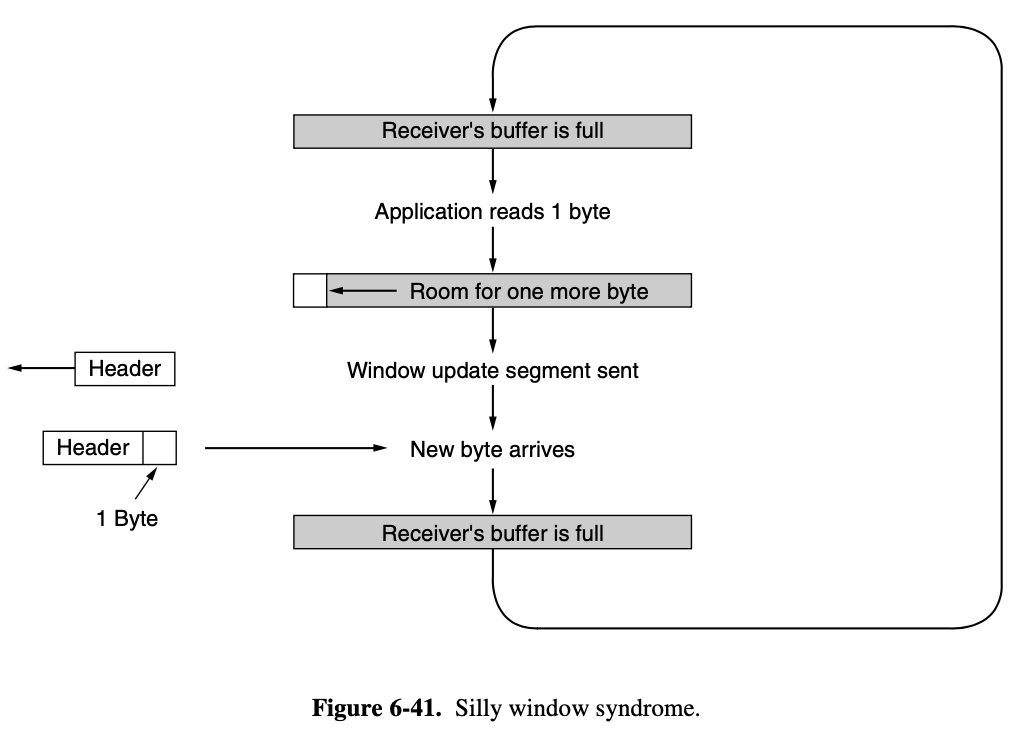
- another problem that can degrade TCP performance
- when data are passed to the sending TCP entity in large blocks
- but an interactive application on the receiving side reads data only 1 byte at a time
Clark's solution of silly window syndrome
- solution is to prevent the receiver from sending a window update for 1 byte
- instead it is forced to wait until it has a decent amount of space available and advertise that instead
cumulative acknowledgement
- acknowledgements can be sent only when all the data up to the byte acknowldged have been received
- if the receiver gets segments 0, 1, 2, 3, 4, 5, 6 and 7
- it can acknowledge everything up to and including the last byte in segment 2
- when the sender times out, it then retransmits segment 3
- as the receiver has buffered segments 4 through 7, upon receipt of segment 3 it can acknowledge all bytes up to the end of segment 7
6.5.9. TCP Timer Management
- TCP uses multiple timer to do its work
RTO (Retransmission TimeOut)
- When a segment is sent, a retransmission timer is started
- if the segment is acknowledged before the timer epxires, the timer is stopped
- if on the other hand, the segment is retransmitted
how long should the timeout be?
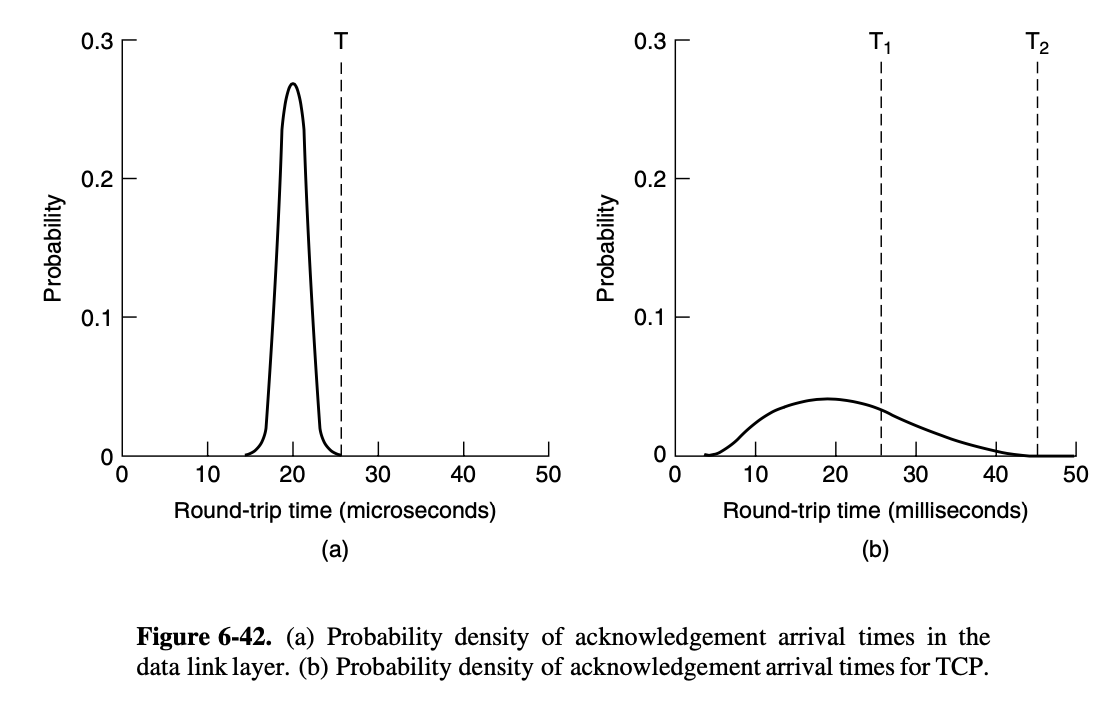
- use dynamic algorithm that constantly adapts the timeout interval, based on continuous measurements of network performance
- for each connecition, TCP maintains a variable, SRTT (Smoothed round-Trip Time), that is the best current estimate of the round-trip time to the destination in question
- use EWMA (Exponentially Weighted Moving Average) formula
<br/.
retransmission timer
-
TCP timer
-
persistence timer
- prevent the following deadlock
- receiver sends an acknowledgement with a window size of 0, telling the sender to wait
- the receiver updates the window, but the packet with the update is lost
- now the sender and receiver are each waiting for the other to do something
- when the persistence timer goes off, the sender transmits a probe to the receiver
- the response to the probe gives the window size
- if it still size 0, the persistence timer is set again and he cycle repeats
- keepalive timer
- when a connection has been idel for a long time, the keepalive timer may go off to cause one side to check whether the other side is still here
- if it fails to respond, the connection is terminated
- timer used in the Time wait state
- runs for twice the maximum packet lifetime to make sure that when a connection is closed
- all packets created by it have died off
6.5.10. TCP Congestion Control
congestion window
- whose size is the number of bytes the sender may have in the network at any time
- the corresponding rate is the window size divided by the round-trip time of the connection
- TCP adjust the size of the window according to the AIMD rule
- TCP will stop sending data if either the congestion or the flow control window is temporarily full
- we can use small burst of packets to our advantage
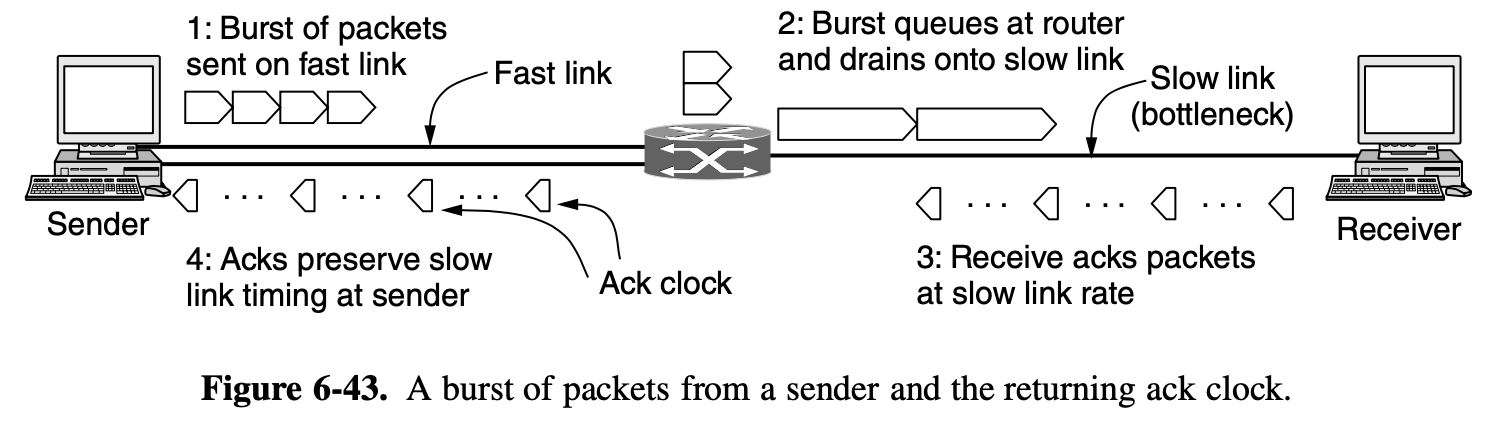
- the key observation : the acknowledgements return to the sender at about the rate that packets can be sent over the slowest link in he path
- this is precisely the rate that the sender wants to used
ack clock
- essential part of TCP
- if it injects new packets into the network at this rate
- they will be sent as fast as the slow link permits
- but they will not queue up and congest any router along the path
slow start
- it is exponential growth!
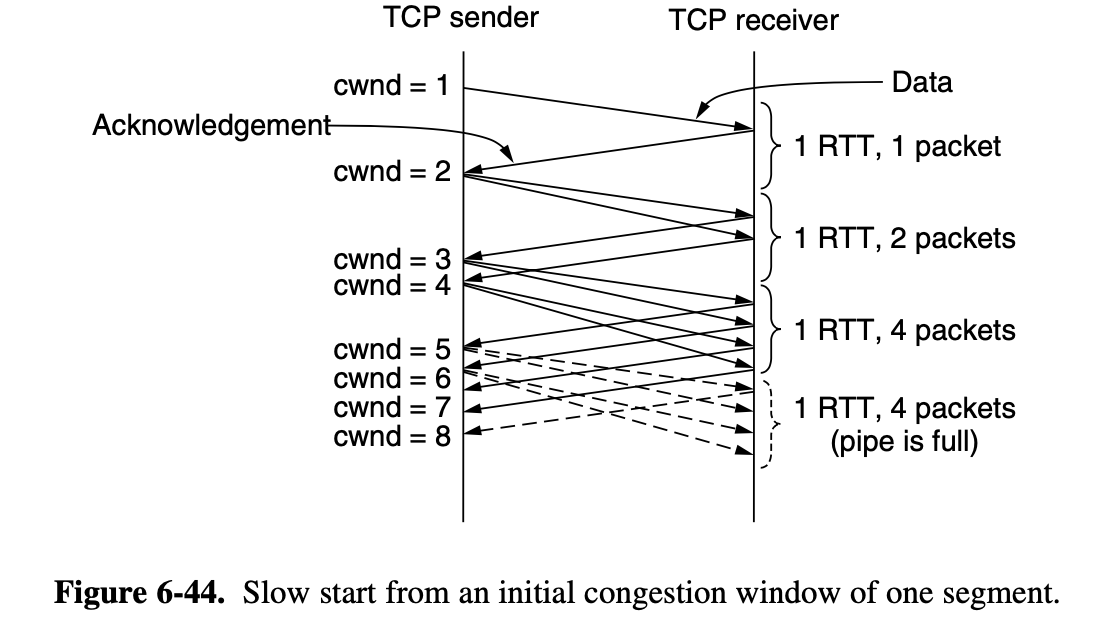{kind=link}
duplicate acknowledgements
- when packet has been lost
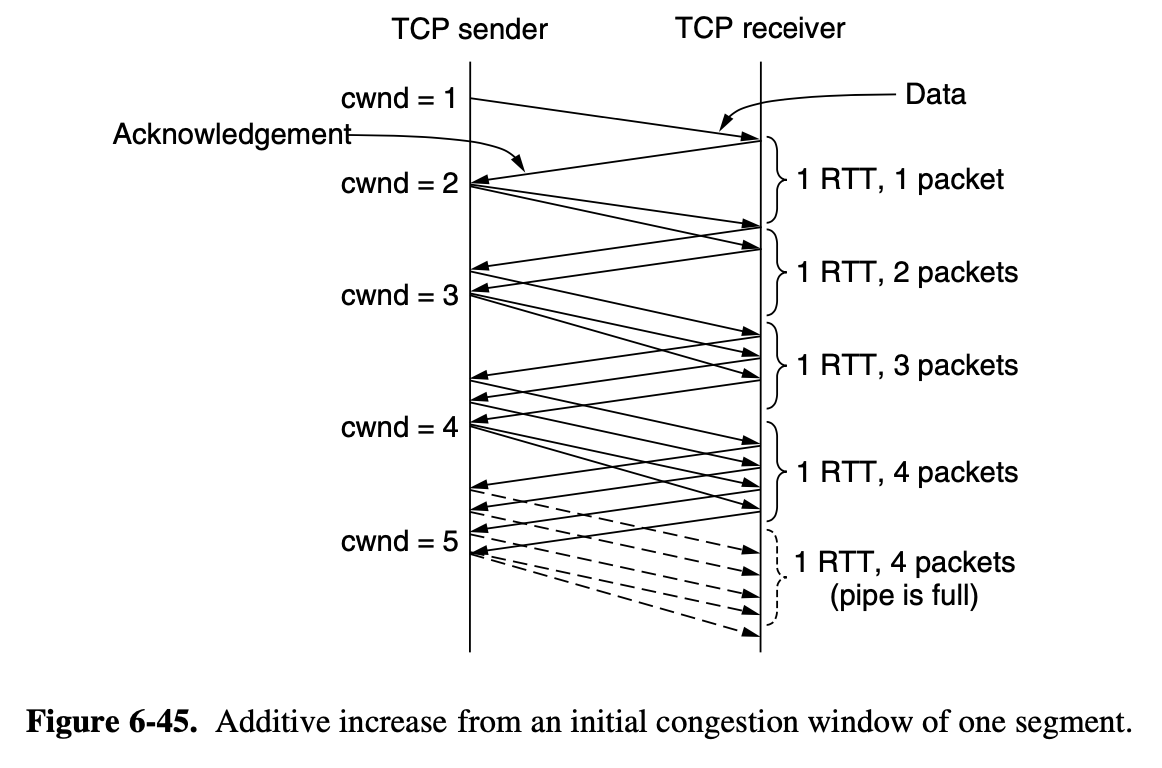
- these acknowledgements bear the same acknowledgement number
- each time the sender receives a duplicate acknowledgement it is likely that another packet has arrived at the receiver and the lost packet still has not shown up
- because packets can take different paths throught network,
- they can arrive out of order
- this will trigger duplicate acknowledgement even though no packets have been lost
fast retransmission
- however this is uncommon in the internet much of the time
- when there is reordering across multiple paths, the received packets are usually not reordered too much
- thus TCP somewhat arbitrarily assumes that 3 duplicate acknowledgements imply that a packet has been lost
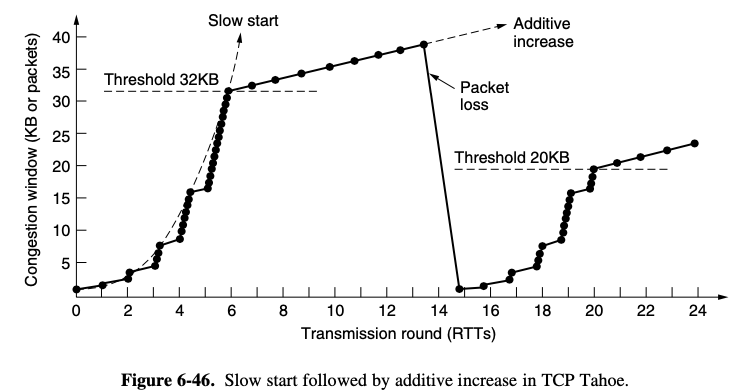
fast recovery
- heuristic that implements this behavior
- temporary mode that aims to maintain the ack clock running with a congestion window that is the new threshold or half the value of the congestion window at the time of the fast retransmission
- upshot of this heuristic is that TCP avoids slow start, except when the connection is first started and when a timeout occurs
- the latter can still happen when more than one packet is lost and fast retransmisson does not recover adequatley
- instead of repeated slow starts, the congestion window of a running congestion follows a sawtooth pattern of additive increase
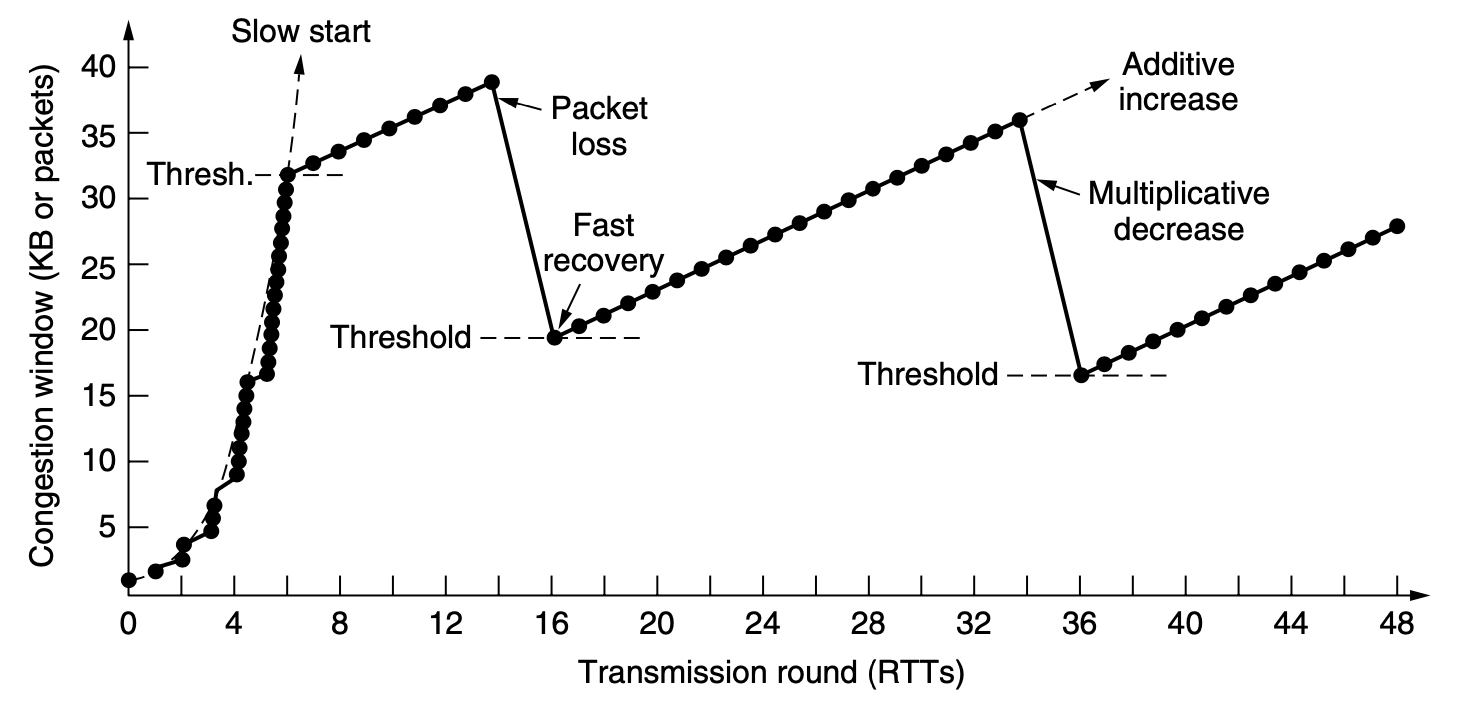
SACK (selective acknowlegements)
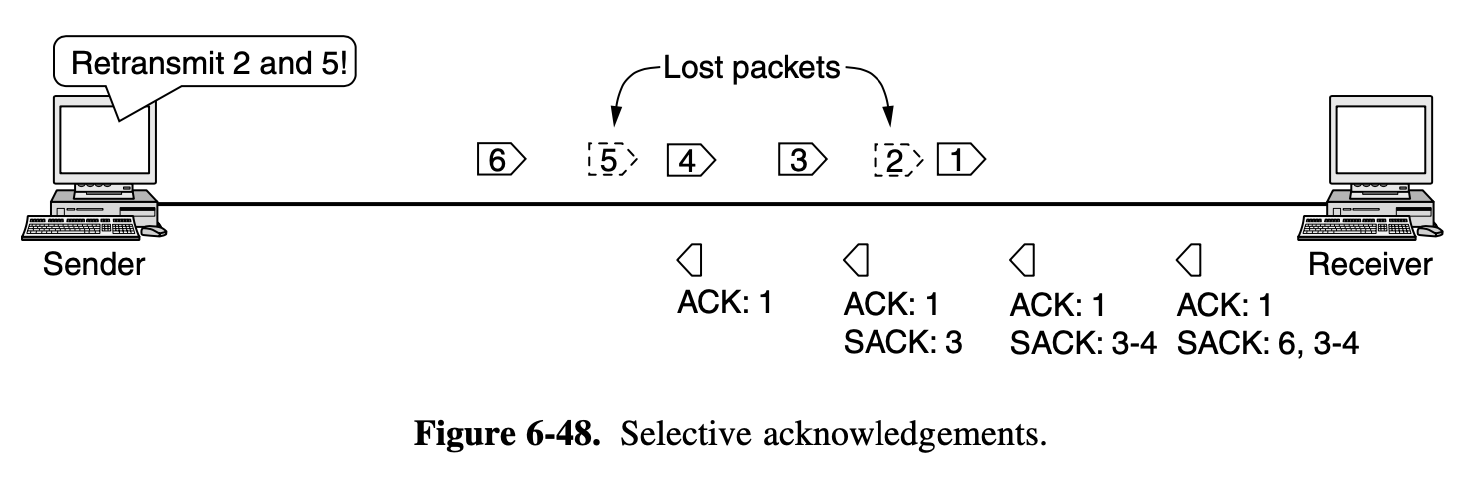
- list up to 3 ranges of bytes that have been received
- when the sender and receiver set up a connection, they each send the SACk permitted TCP optionn to signal that theyy understand selective acknowledgement
ECN (Explicit Congestion Notfication)
- in addition to packet loss as a congestion signal
- ECN is an IP layer mechanism to notify hosts of congestion
- Router that support ECN will set a congestion signal on packets that can carry ECN flags when congestion is approaching, instead of dropping those packets after congestion has occured
- The sender tells the receiver that is has heard the signal by using the CWR (Congestion Window Reduced)
6.6. Performance issues
6.6.3. Host Design for Fast Networks
- NICs and routers have already been engineered to run a wire speed
- they can process apckets as quickly as the packets can possibly arrive on the link
- the relevant performance is that which applications obtain
- it is not the link capacity, but the throughput and delay after network and transport processing
Host speed is more importatnt than network speed
- if you double the host speed, you often can come close to doubling the throughput
- doubling the network capacity has no effect if the bottleneck is in the hosts
Reduce Packet count to reduce overhead
- each segment has a certain amount of overhead as well as data
- bandwidth is required for both componenets
- per-packet overhead in the lower layers amplifies this effect
- each arriving packet causes a fresh interrupt if the host is keeping up
- on a mordern pipelined processor each interrupt breaks the CPU pipeline, interferes with the cache, requires a change to the memory management context, voids the brand prediction table and forces a substantial number of CPU registers to be saved
- mechanisms such as Nagle's algorithm and Clark's solution are also attempts to avoid sending small packets
Minimize data touching
- the most straighforward way to implement a layered protocol stack is with on module for each layer
- Unfortunately this leads to copying as each layer does its own work
ex) afer a packet is received by the NIC, it is typically copied to a kernel buffer
form there it is copied to network layer buffer for network layer processing, then to a transport layer buffer for transport layer processing and finally to the receiving application process
- all this copying can greatly degrade performance because memory operations are an order of magnitude slower than register-register instructins
ex) if 20% of the instructions actually go to memory, which is likely when touching incoming packets, the average instruction exectuion time is slowed down by a factor of 2.8
- a clever operating system will minimize copying by combining the processing of multiple layers
ex) TCP and IP are usually implemented together so that it is not necessary to copy the payload of the packet as processing switcches from network to transport layer
- to perform multiple operations within a layer in a single pass over the data
ex) checksums are often computed while copying the data and the newly computed checksum is appended to the end
minimize context switching
- context switching (user mode to kernel mode)
- this cost is why transport protocols are often implemented in the kernel
- like reducing packet count, context switches can be reduced by having the library procedure that sends data do internal buffering until it has a substantial amount of them
- on the receiving side, small incoming segments should be collected together and passsed to the user in one fell swoop instead of individually, to minimize context switches
- an incodming packet causes a context switch from the current user to the kernel
- and then a switch to the receiving process to give it the newly arrived data
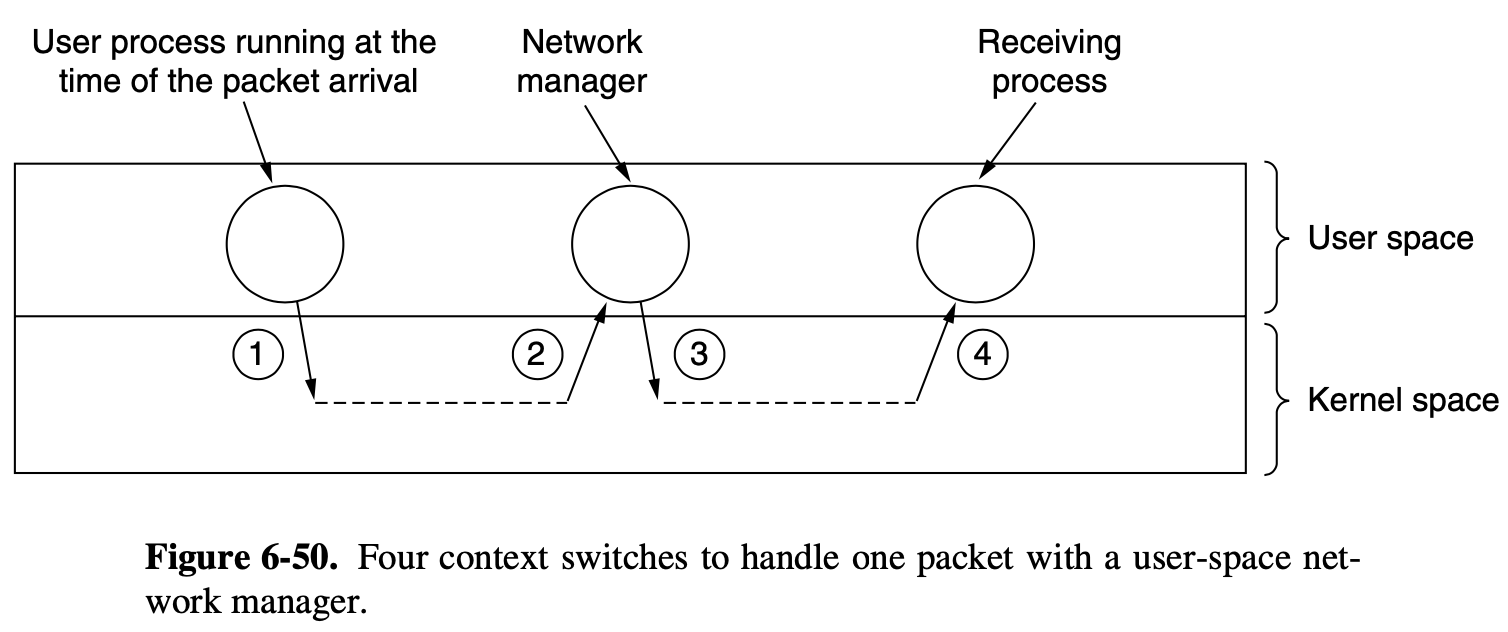
Avoiding congestion is better than recovering from it
- all of these cost are unnecessary and recovering from congestion taskes time and patience
Avoid timeouts
- timers are necessary in netwroks, but they should be used sparingly and timeouts should be minimized
- when a timer goes off, some action is generally repeated
<br/.
6.6.4. Fast Segment Processing
[Segment processing overhead has 2 components]
1. overhead per segment
2. overhead per byte
- the key to fast segment processing is to sepearate out the normal, successful case and handle it specially
- many protocols tend to emphasize what to do when something goes wrong but to make the protocols run fast, the designer should aim to minimize processing time when everything goes right
- minimizing processing time when an error occurs is secondary
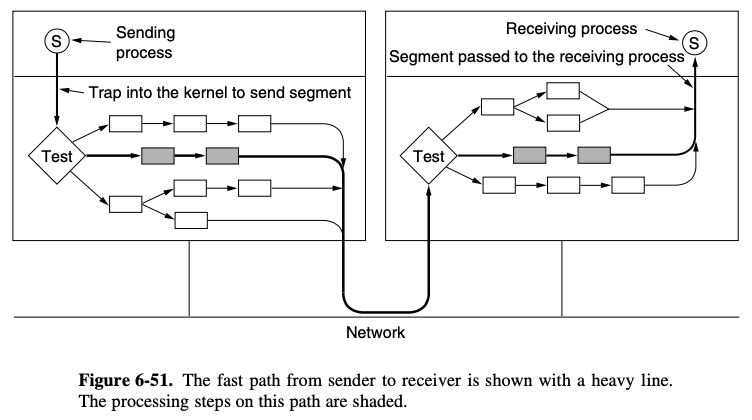
- in the usual case, the header of consecutive data segments are almost the same
- to take advantage of this fact, a prototype header is sotred within the transport entity
- at the start of the fast path, is it copied as fast as possible to a scratch buffer, word by word
- those fields that change from segment to segment are overwirtten in the buffer
- a pointer to the full segment header plus a pointer to the user data are then passed to the network layer

- an optimization that often speeds up connection record lookup even more is to maintain a pointer to the last one used and try that one first, observed a hit rate exceeding 90%
- the fast path updates the connection record and copies the data to the user
- while it is copying, it also computes the checksum, eliminating an extra pass over the data
- if the checksum is correct the connection record is updated and an acknowledgement is sent back
- the general scheme of first making a quick check to see if the header is what is expected and then having a special procedure handle that case is called header prediction
- Many TCP implementation use it
- it is possible to run at 90% of the speed of a loal memory-to-memory copy, assuming the network itself as fast enough
timing wheel

- when the clock ticks, the current time pointer is advanced by one slot
- if the entry now pointed to is nonzero, all of its timers are peocessed
6.6.5. Header compression
- to use bandwidth well, protocol header and payloads should be carried with the minimum of bits
- the higher-layer headers can be a significant performance hit
header compression
- is used to reduce the bandwidth taken over links by higher-layer ptotocol headers
- specially designed schemes are used instead of general purpose methods
- headers are short, so they do not compress well individually, and decompression requires all prior data to be received
- this will not be the case if a packet is lost
6.6.6. Protocols for Long Fat Networks
- gigabit networks that transmit data over large distance
- combination of a fast network or fat pipe and long delay
[problems]
- protocols use 32bit sequence numbers
- 10-Mbps : 57min / 1-Gbps : 37 seconds (under the 120sec maximum packet lifetime on the internet)
- all of a sudden 32bit is not nearly as good an approximation to infinity since a fast sender can cycle through the sequence space while old packets still exist
- size of the flow control window must be greatly increased
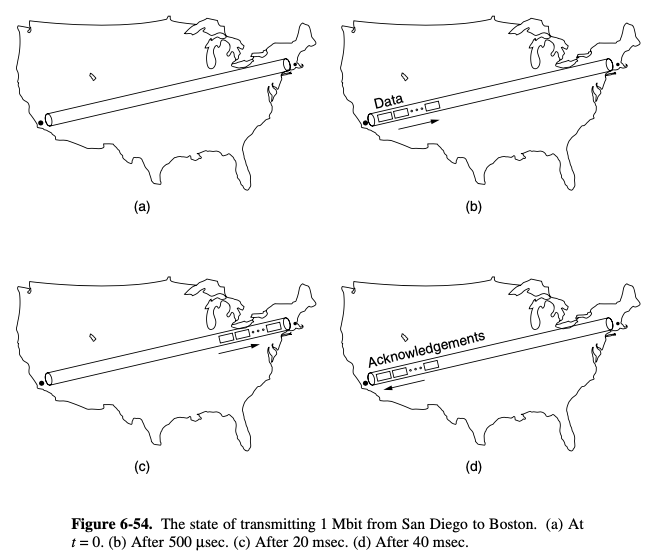
- useful quantity to keep in mind when analyzing network performance is the bandwidth-delay product
-
simple retransmission schemes, sucha s the go-back-n protocol, perform poorly on lines with a large bandwidth-delay product
-
fundamentally different from megabit lines in that long gigabit lines are delay limited rather than bandwidth limited
-
communication speeds have improved faster than computing speed
- the basic princile tha all high-speed network designers should learn by heart
Design for speed, not for bandwidth optimization
내가 이걸 왜 알아야 하지..
재밋긴 하지만 디테일 하게는 더이상..
6.7. Delay tolerant networking
- if some networks there is often no end-to-end path
message switching
- in these occasionally connected networks, data can still be communicated by storing them at nodes and forwarding them later when there is a working link
- eventually the data will be relayed to the destination
6.7.1. DTN (Delay Tolerant Network) Architecture
- DTNs seek to relax is that an end-to-end path between a source and destination exists for the entire duration of a communication session
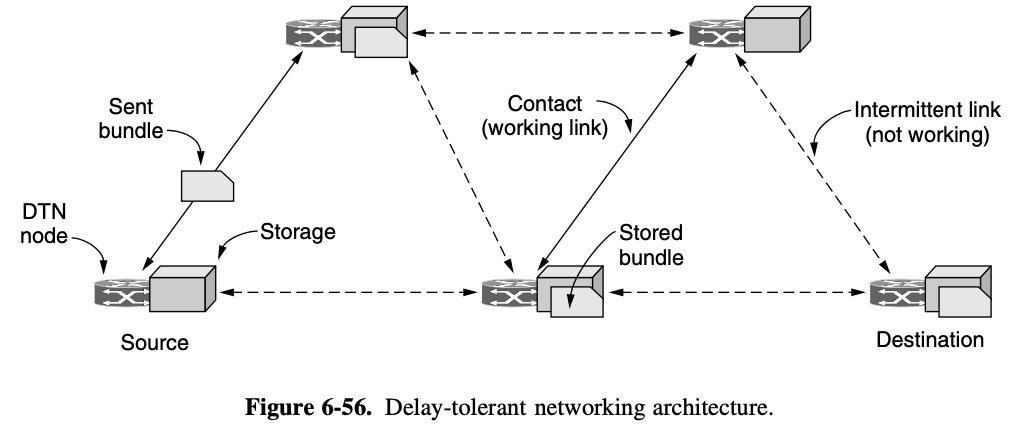
- DTN terminology, a message is called a bundle
- DTN nodes are equipped with storage, typically persistent storage such as a disk or flash memory
- they store bundle until links become available and then forward the bundles
- a working link is called a contact
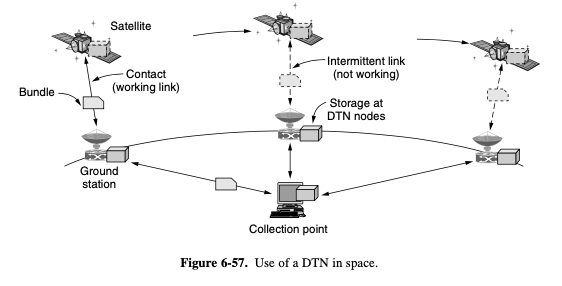
ex) user on mobile phones depending on which users make contact with each other during the day
- when there is unpredictability in contacts, one routing strategy is to send copies of the bundle along different paths in the hope that one of the copies is delivered to the destination before the lifetime is reached
6.7.2. The bundle protocol
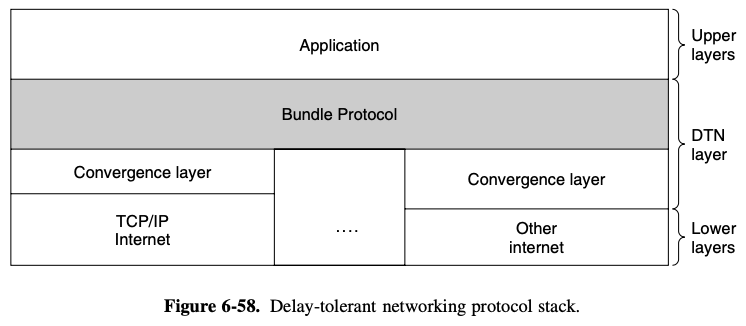
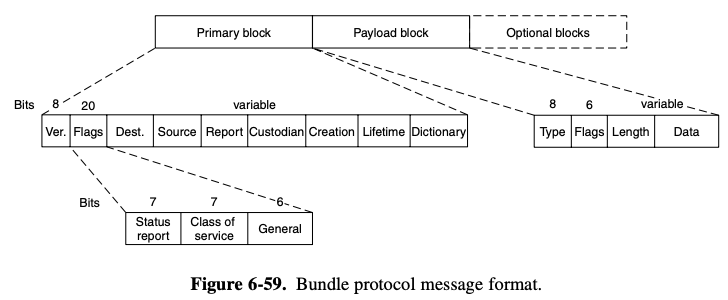
이거는 안할래요..
7. The application layer
