ElasticSearch
ElasticSearch Fundamentals
Index
- Collection of
JSONdocuments - A logical grouping of all the
shardsfor a specific type, includingprimariesandreplicas
Alias
- more than one index
- Secondary name for a group of
indices
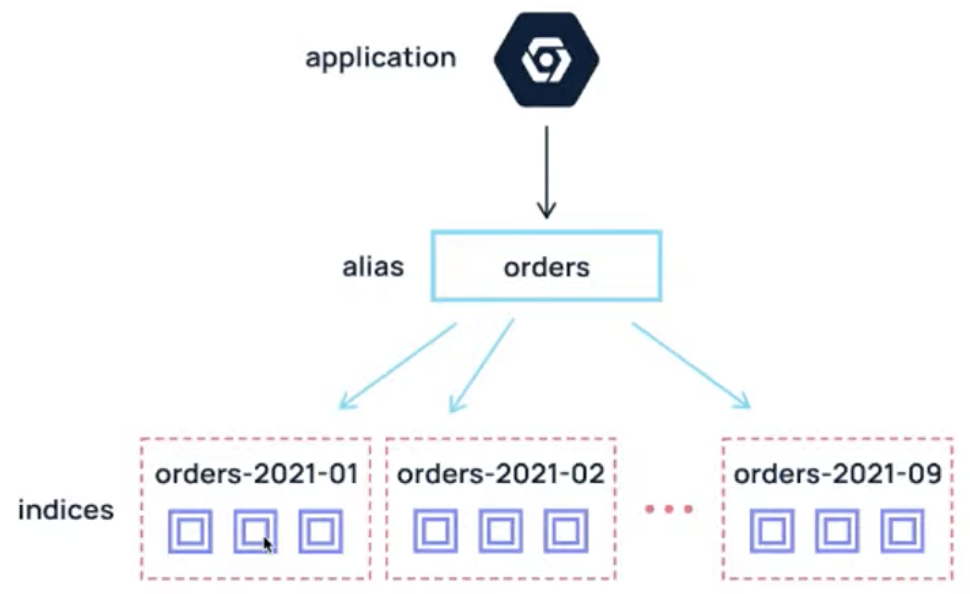
- allow for reindexing and rollover without a downtime and code-change
Node
- Single Elasticsearch instance : computer + disk
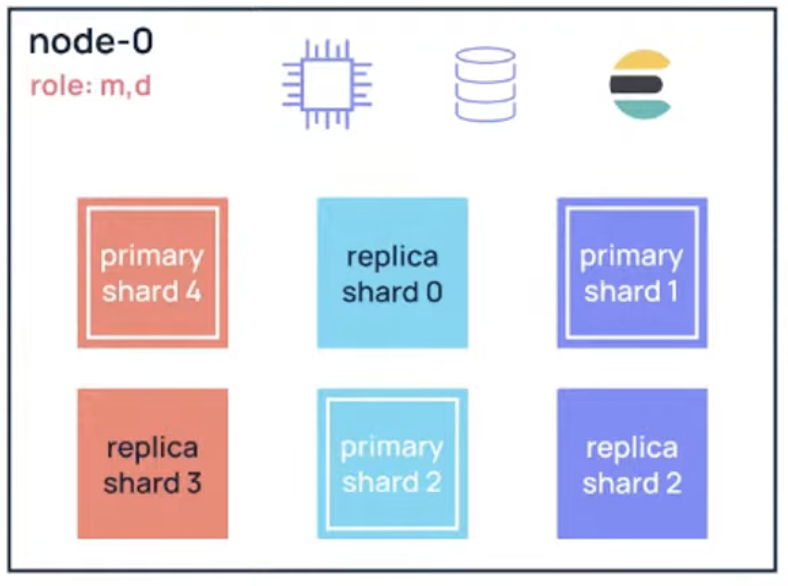
- Can assume
multiple rolesat the same time- master, data, ingest, transform, voting-only and more
- node.roles : [master, data, ingest]
- if not assigned, the node assumes all roles
Sort or nodes
[Master-eliglble node]
- A node that has master role
- makes it eligible to be elected as the master node
- which controls the cluster
- responsible for lightweight cluster-wide actions such as creating or deleting an index etc
- it is important for cluster health to have a stable master one
- Any master-eligible node that is not a voting-only node may be elected to become the master node by the master election process
- it is important for the health of the cluster that the elcted master node has the resource it need to fulfill its responsibilities
- if the elected master node is overloaded with other tasks then the cluster will not operate well
- The most reliable way to avoid overloading the amster with other tasks is to configure all the master-eligible nodes to be
dedicated master-eligible nodes - Master-eligible nodes will still alsot behave as coordinatin nodes that route requests from clients to the other nodes in the cluster but you should not use dedicated master nodes for this purpose
node.roles: [ master ]+) [Voting-Only node]
- master-eligible node is a node that participates in master elections but which will not act as the cluster's elected master node
- voting-only node can serve as a tiebreaker in electins
- not actually eligible to become the master at all
node.roles: [ data, master, voting_only ]- HA clusters requires at least three master-eligible nodes, at least two of which are not voting-only nodes
- Such a cluster will be able to elect a master node even if one of the nodes fails
[Data Node]
- A node that has the data role
- Data nodes hold data and perform data related operations such as CRUD, search and aggregations
- A node with the data role can fill any of the specialised data node roles
- hold the shards that contain the documents you have indexed
- data nodes handle data related operations like CRUD, search and aggregations
- it is important to monitor these resources and to add more data nodes if they are overloaded
ex) dedicated data node
node.roles: [ data ][Ingest Node]
- A node that has the ingest role
- Ingest nodes are able to apply an ingest pipeline to a document in order to transform and enrich the document before indexing
- With a heavy ingest load, it makes sense to use dedicated ingest nodes and to not include the ingest role from nodes that have the master or data role
- can execute pre-processing pipelines, composed of one or more ingest processors
- depending on the type of operations performed by the ingest processors and the required resources
- it make sens to have dedicated ingest nodes, that will only perform this specific task
+) [Coordination only node]
- if you take away the ability to be able to handle master duties then you are left with a coordination node that can only route requests, handle the search reduce phase and distribute bulk indexing
- coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes
node.roles: [ ][Remote-eligible node]
- A node that has the
remote_cluster_clientrole which makes it eligible to act as a remote client - act as a cross-cluster client and connects to remote cluster
- once conncted, you can search remote clustes using cross-cluster search
[Machine learning node]
- A node that has the ml role
- If you want to use machine learning features
- there must be at least one machine learning node in your cluster
[Transform node]
- A node that has the transform role
- If you want to use transform, there must be at least one transform node in your cluster
- run transforms and handle transform API requests
- transforms settings
node.roles: [ transform, remote_cluster_client ]+) Note : Coordiation Node
- Request may involve data held on different data nodes
- in the scatter phase, the coordination node forwards the request to the data nodes which hold the data
- Each data node executes the request locally and returns its results to the coordinating node
- In the gather phase, the coordination node reduces each data node's result into a single global result set
- Every node is implicitly a coordination node
- This means that s node that has an explicit empty list of roles via node.roles will only act as a coordination node which cannot be disabled
- As a result, such a node needs to have enough memory and CPU in order to deal with the gather phase
Changing the role of a node
Each data node maintins the following data on disk:
- the shard data for every shard allocated to that node
- the index metadata corresponding with every shard allocated to that node and
- the cluster-wide metadata, such as settings and index templates
Similary, each master-eligible node maintins the following data on disk
- the index metadata for every index in the cluster and
- the cluster-wide metadata such as settings and index template
- nodes without the data role will refuse to start if they find any shard data on disk at startup
- nodes without both the master and data roles will refuse to start if they have any index metadata on disk at startup
roles
- master
- data
- data_content
- data_hot
- data_warm
- data_cold
- data_frozen
- ingest
- ml
- remote_cluster_client
- transform
Cluster
- a collection of connected nodes
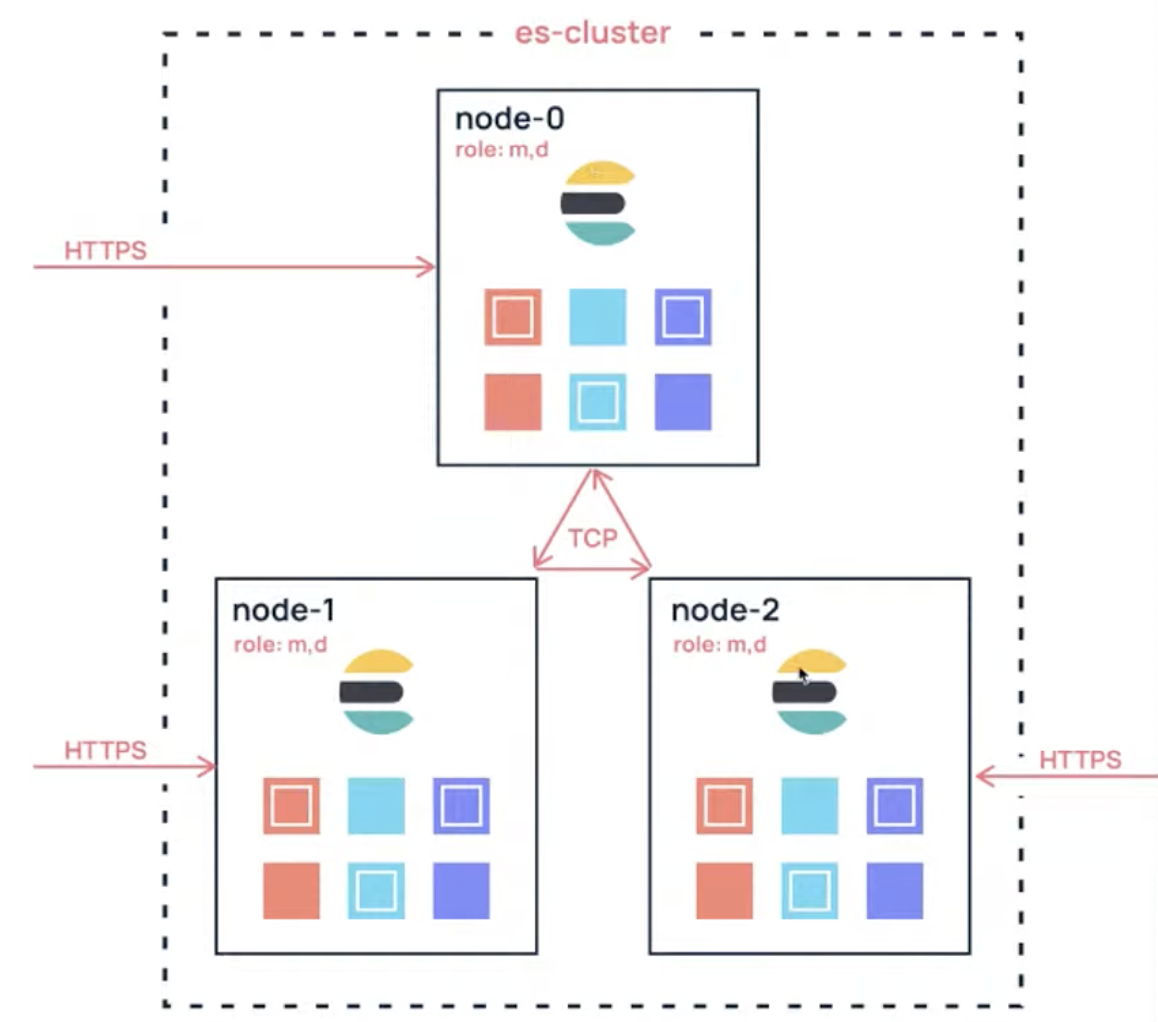
- identified by its
cluster name - each node in a cluster knows about the other nodes
- cluster state
- node configuration
- cluster setting
- indices, mapping, settings
- location of all shards
Cluster Size
- 1 <= nodes # <=
no_limit - Larger cluster (> 100 nodes)
== more searchable data
== larger cluster state
== harder for the master to manage
== more operational issue (unneccssary CPU usage) - cross cluster replication and cross cluster search are now available
A Typical Large Production Cluster
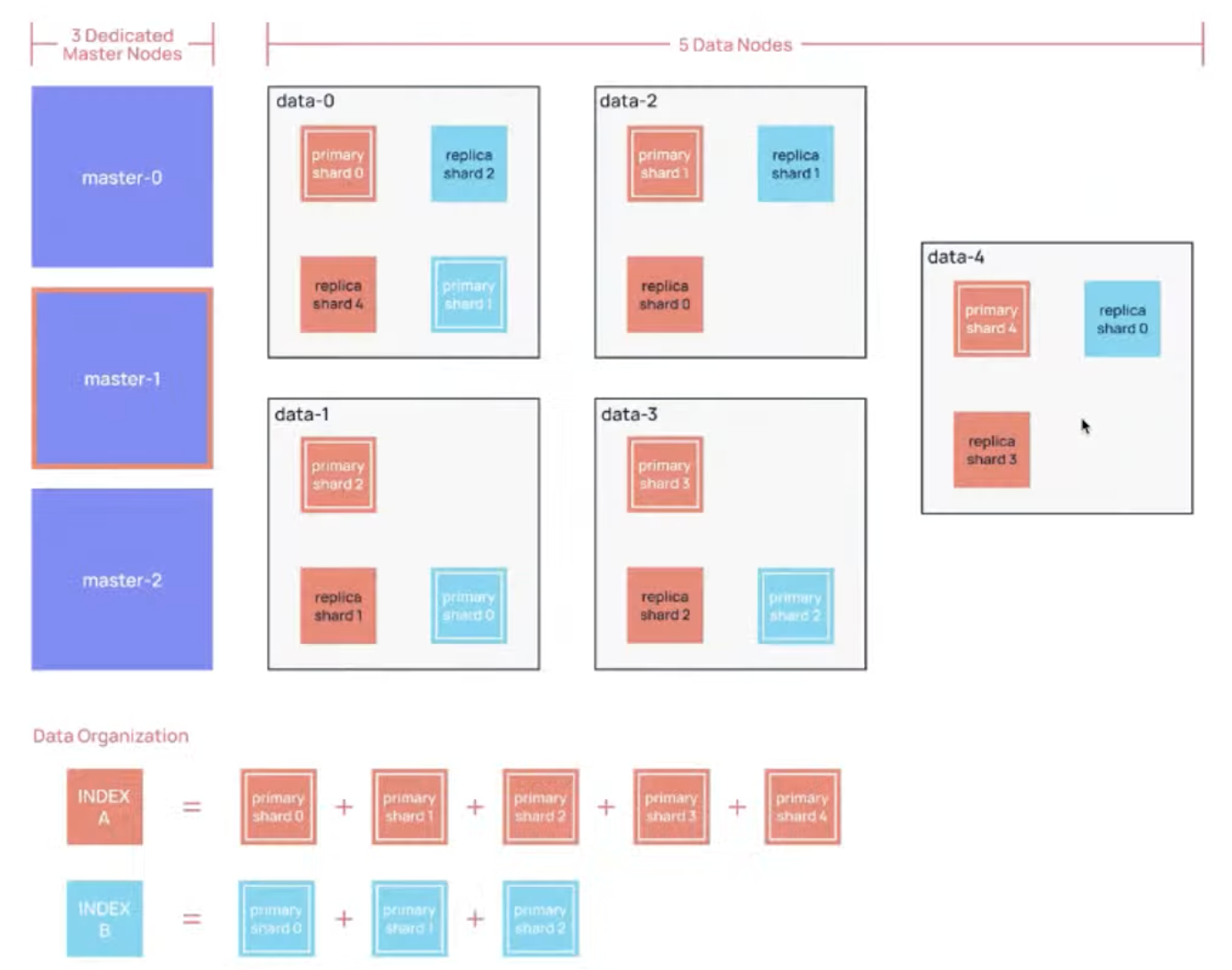
ElasticSearch Architecture
Master Node (aka master-eligible nodes)
- in-charge of light-weight cluster-wide actions
- cluster settings- deleting or creating indices and settings
- adding or removing nodes
- shard allocation to the nodes
- a stable master node is required for the cluster health
- since, an elastic serach node can assume multiple roles simultaneously
- small cluster : you can have same node assigned as data and master role (and others)
- large cluster : you can have dedicated master and data nodes (seperation of concrens)
- Dedicated master nodes don't need to have same compute resource as the data node
- data node will required 1~2 tier higher
Electing a master among master-eligible nodes
- there's single elected master node within a cluster at a time
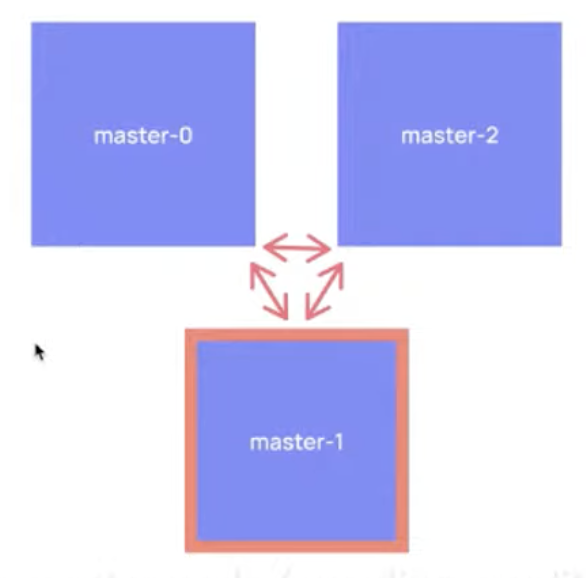
- master election happens at
- cluster startup- when the existing elected master node fails
- Elasticsearch uses Quorum-based decision making for electing master node
(avoiding a split-brain scnario)
n/2 + 1master-eligible nodes are required to respond during the master election process
- you can add or remove master-eligible nodes to a running cluster
- Elasticsearch will maintin the voting-configurations (response from the master-eligible nodes) automatically
- you must not stop half or more of the nodes in the voting configuration at the same time
- Otherwise the cluster will become unavailable
- Perform a rolling-restart instead, if you are upgrading or doing other maintenance work
Important Elasticsearch configuration
Path settings
- Elasticsearch writes the data you index to indices and data streams to a data directory
path:
data: /var/data/elasticsearch
logs: /var/log/elasticsearchCluster name setting
cluster.name: logging-prodNode name setting
- human readable identifier
node.name: prod-data-2Network host setting
- default, only binds to loopback addressses such as 127.0.0.1
- resilient production cluster must involve nodes on other servers
network.host: 192.168.1.10-
address of this node for both HTTP and transport traffic
-
will bind to this address and will also use it as its publish address
-
if you write down network.host field elastic search assumes that you are moving from develpment mode to production mode
Discovery and cluster formation settings
discovery.seed_hosts
- without any network configuration, elasticsearch will bind to the available loopback addresses and scan local ports 9300, 9305 to connect with other nodes running on the same server
- when you want to from a cluster with nods on other hosts
- settings provide a list of other nodes
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
- [0:0:0:0:0:ffff:c0a8:10c]:9301 cluster.initial_master_nodes
- start elasticsearch cluster for the first time
- cluster bootstraping step determines the set of master-eligible nodes whose votes are counted in the first election
cluster.initial_master_nodes:
- master-node-a
- master-node-b
- master-node-cHeap size settings
- We recommend the default sizing for most production environments
- if needed, you can override the default sizigng by manually setting the JVM heap size
JVM heap dump path setting
- by default, elasticsearch configures the JVM to dump the heap on out of memory execption to the default data directory
GC Logging settings
- default configuration rotates the logs every 64MB and can consume up to 2GB of disk space
+) Thread Pools
- 이거 다 정리하려면 오늘 하루 꼬박 걸림 그냥 가서 보는게 훨 낫따
Resilient ElasticSearch Cluster
- A resilient cluster requires redundancy for every required cluster component
- this mean a resilient cluster must have
- at least
three master-eligiblenodes - at least
two nodes of each role - at least
two copies of each shard(one primary and one or more replicas)
- at least
Small clusters
- you can start with nodes having shared roles (data + master)
- minimum : 2 master-eligible nodes + 1 voting-only-master-eligible tiebreaker node
- better : 3 master-eligible nodes
Large clusters
- dedicated master-eligible nodes = 3
- zonal redundancy with one master-eligible node in each or the 3 zones
- cross-cluster replication
Sizing ElasticSearch Cluster
Sharding Strategy
- Each elasticsearch index has one primary shard by default
- set at the index creation time
- you can increase number of shards per index (max 1024) by changing
index.number_of_shardsrequires reindexing
- total shards
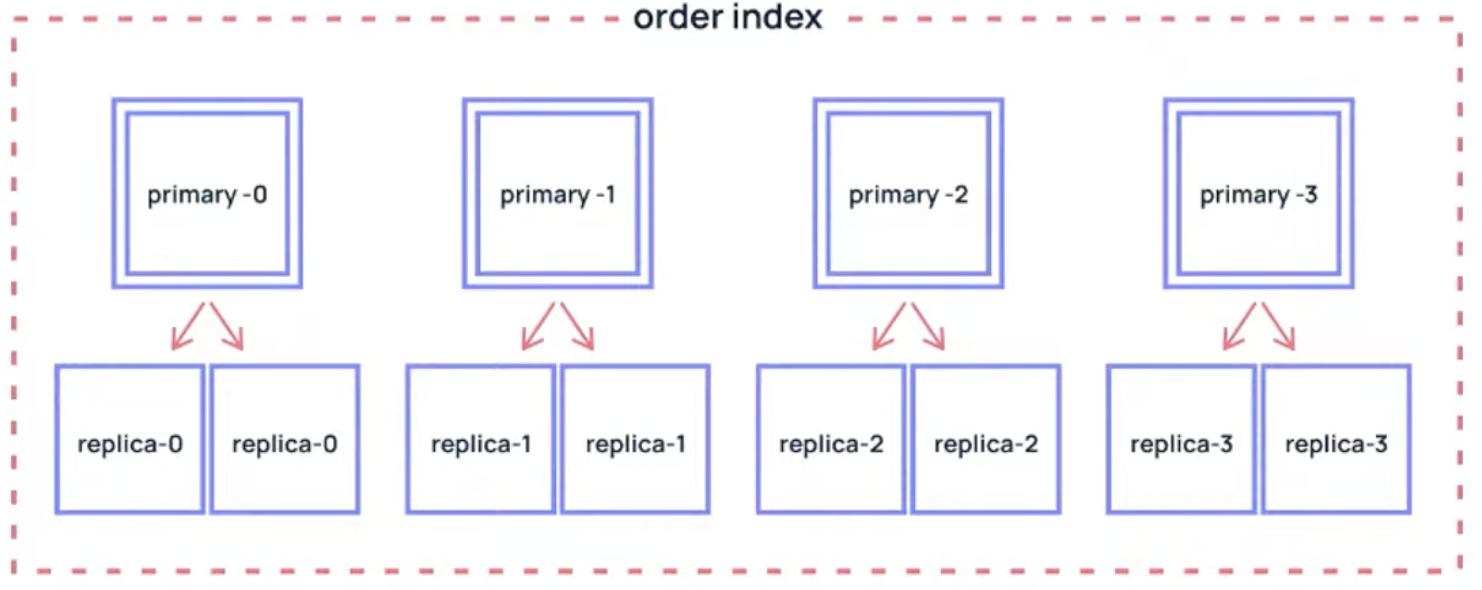
- more primary shards
== more parallelis
== fater indexing preformance
== a bit slower search performance
- aim for shard size between 10GB and 50GB
- better=25GB for search use cases
- larger shards makes the cluster less likely to recover from failure
- harder to move to other nodes when a node is going under maintainence
- Aim for 20 shards or fewer per GB of heap memory
- For example, a node with 30GB of heap memory should have at most 600 shards
Sizing ElasticSearch Cluster
- Number of shards = (SourceData + Room to Grow) x (1 + 10% Indexing Overhead) / Desired Shard size
- Minimum storage required = SourceData x (1 + Number of Replicas) x 1.45
- For a cluster handling complex aggs, search queries, high throughout, frequent updates
- node config = 2 vCPU core and 8GB of memory for every 100 GB for storage - Set ES node JVM heap size to no more than 50% of the physical memory of the backing node
Let's assume
- you have 150GB of existing data to be indexed
- Number of primary shards (starting from scratch or no growth) = (150 + 0) x 1.10 / 25 ~= 7
- Number of primary shards (with 100% growth in a year) = (150 + 150) x 1.10 / 25 ~=13
- Remember you cannot change # primary shards of an index without reindexing, So pre-plan or use index rollover
Let's assume
-
Goging with minimum 3 nodes (master + data)
-
Assuming, we would have 1 replica per shard
-
Minimum storage required = 150 x (1 + 1) x 1.45 = 435 GB of total disk space
-
Compute and Memory = 435 x (2 vCPU and 8 GB memory) / 100 = 9 vCPUs and 35GB of memory
-
3 nodes each having 3vCPU 12GB memory and 150GB disk storage
-
With 12GB node memory, you can set the JVM heap size to 6GB (== max 120 shards per node, 360 shards total)
Oraganizing Data in ElasticSearch
Multitenancy
A cluster per tenant
- Best isolation of network, compute, storage
- Needs high degree of automation to create and manage these many clusters
An index per tenant
- Logical isolation with access control
- But quickly runs into the oversharding problem: too many smaller shards -> larger cluster state
A Document per tenant
- Make scaling super easy and best suite for search use cases
- Need to havve a tenantId field per document
- Need to scope search and indexing requests to the tenantId
- Need to have strong access control mechanism as there's no network, compute or storage isolation
Provisioning Elasticsearch
Managed service by Elastic.co

Self-Hosted on Kubernetes using ECK Operator

Self-Hosted on your cloud provider (virtual machine cluster)

Monitoring ElasticSearch
Important Metrics to Monitor
- CPU, Memory and Disk IO utilization of the ndoes
- JVM Metrics : Heap, GC and JVM Pool Size
- Cluster availability (green, yellow, red) and allocation states
- Node availability (up or down)
- Total number of shards
- Shard size and aviliability
- Request rate and latency
Scaling Elasticsearch Cluster
Handling Data Growth
- Aim for 20 shards or fewer per GB of heap memory
Options
- Data retention : If possible delete/archive the odler shards as per a retention policy. Goest best with ILM
- Use shrink index API to shrink an existing index into a new index with fewer primary shards
- requested number of primary shards in the target index must be a factor of the number of shards in the source index
- e.g. an index with 8 primary shards can be shrunk into 4, 2 or 1 primary shards or an index with 15 primary shards can be shrunk into 5,3,1
- adding new data nodes to the cluster
Index lifecycle management (ILM)
Managing indices
- Automatically manage indices according to performance, resiliency and retention requirements using simple ILM policies
[index lifecycle phases]
- Hot : actively being updated and queried
- Warm : no longer being updated but acively being queried (logs and similar immtable objects)
- Cold : no longer being updated an is queried infrequently
- Frozen : no longer being updated and is queried rarely (Okay for searches to be extremely slow)
- Delete : no longer needed and can safely be removed
- ILM policy specifies which phases are applicable, what actions are preformed in each phaase and when it trasitions between phases
Data Tiers
-
Specialized node.roles roles to tie data nodes to specific data tiers
- data_hot
- data_warm
- data_cold
- data_frozen
-
you can attach best performing hardware to the data_hot nodes with SSDs while using slower and cheaper hardware for the other nodes in that list
-
helps in tremendous cost saving
Quorum-based decision making
- Electing a master node and changing the cluster state are the two fundamental tasks that master-eligible nodes must workk together to perform it
- It it mportant that these activities work robustly even if some nodes have failed
quorum: a subset of the master-eligible nodes in the cluster- quorums are carefully chosen so the cluster does not have a "split brain" -
split brain scenario: it's partitioned into 2 pieces such that each piece may make decisions that are inconsistent with those of the other piece
- to be sure that the cluster remains availble your must not stop half or more of the nodes in the voting configuration at the same time
- if there are 3, 4 master-eligible nodes, the cluster can tolerance one of them being unavailable
Master Elections
- uses an election process to agree on an elected master node
- both at startup and if the existing elected master fails
- any master-eligible node can start an election, and normally the first election that takes place will succeed
The following settings must be considered before going to production
+) The following settings must be considered before going to production
Configuring System Settings
.zip, .tar.gz
- Temporarily with
ulimit - Permanently in
/etc/security/limits.conf
ulimit
- can be used to change resource limits on a temporary basis
- limits usually need to be set as root before switching to the user that will run Elasticsearch
sudo su
ulimit -n 65535
su elasticsearch /etc/security/limits.conf
- to set the maximum number of open files for the
elasticsearchuser to 65,535, add the following line to thelimits.conffile
elasticsearch - nofile 65535+) Ubuntu and limits.conf
- Ubuntu ignores the
limits.conffile for processes started byinit.d - To enable the
limits.conffile, - edit
/etc/pam.d/suand uncomment the following line
Sysconfig file
- RPM :
/etc/sysconfig/elasticserach - Debian :
/etc/default/elasticsearch
Systemd configuration
- using RPM or Debian packages on System that use systemd
- system limits must be specified via systemd
- The Systemd service file (
/usr/lib/systemd/system/elasticserach.service) contains the limits that are applied by default - To override them, add file called
/etc/systemd/system/elasticserach.service.d/override.conf - after change the file run the following command to reload units
sudo systemctl daemon-reloadDisable Swapping
- Most operating systems try to use as much memory as possible for file system caches and eagerly swap out unused application memory
- this can result in parts of the JVM heap or even its executable pages being swapped out to disk
- There are 3 approaches to disabling swapping
- The preferred option is to completely disable swap
Disable all swap files
sudo swapoff -a- to disable it permanently, you will need to edit the
/etc/fstab
Configure Swappiness
- ensure that the sysctl value
vm.swappinessis set to 1 - this reduce the kernel's tendency to swap and should not lead to swapping under normal circumstances
+) Is it safe to turn swap off permanently?
A swappiness setting of zero means that the disk will be avoided unless absolutely necessary (you run out of memory)
Enable bootstrap.memory_lock
- use mlockall on Linux/Unix system
- try to lock the process address space into RAM, preventing any ElasticSearch haep memory from being swapped out
- to enable a memory lock, set
bootstrap.memory_lockto true inelasticsearch.yml
bootstrap.memory_lock: truemlockallmight cause the JVM or shell sessio to exit if it tries to allocate more memory than it available
File Descriptor
- ElasticSearch uses a lot of file descriptors or file handles
- Running out of file descriptors can be disastrous and will most probably lead to data loss
- make sure to increase the limit on the number of open files descriptors for the user running Elastisearch to
65,536 or higher
Virtual Memory
- uses
mmapfsdirectory by default to store its indices - default operating system limits on mmap counts is likely to be too low which may result in out of memory exceptions
sysctl -w vm.max_map_count=262144- To set this value permanently, update
vm.max_map_countin/etc/sysctl.conf - To verify after rebooting, run
sysctl vm.max_map_count
Number of Threads
- Elasticsearch uses a number of thread pools for different types of operations
- is able to create new threads whenever needed
- make sure that the number of threads that the Elasticsearch user can create is at least 4096
/etc/security/limits.conf
ulimit -u 4096DNS Caching settings
- Elasticsearch runs with a security manager in place
- With a security manager in place,
- the JVM defaults to caching positive hostname resolutions indefinitely
- defaults to caching negative hostname resolutions for ten seconds
- Elasticsearch overrides this behavior with default values to cache positive lookups for 60 seconds
- to cache negative lookups for ten seconds
- theses value should be suitable for most environment
- if not, you can edit
es.networkaddress.cache.ttl,es.networkaddress.cache.negative.ttlin the JVM options - JVM options ignored by Elasticsearch settings
Ensure JNA temporary directory permits executables
- Elasticsearch uses the Java Native Access library and another library called
libffi - on linux, the native code backing these libraries is extracted at runtime into a temporary directory and then mapped into executable pages int Elasticsearch's address space
- this requires the undeflying files not to be on a filesystem mounted with the
noexecoption
- Ealsticsearch will create its temporary directory within
/tmp - however some hardened linux installations mount
/tmpwith thenoexecoption by default - This prevent JNA and
libffifrom working correctly
java.lang.UnsatisfiedLinkerError
failed to map segment from shared object
failed to allocate closure- To resolve these problem, either remove the
noexecoption from your/tmpfilesystem or configure Elasticsearch to use a different location for its temporary directory by setting the$ES_TMPDIR
export ES_TMPDIR=/usr/share/elasticsearch/tmp- if you are using
systemdto run Elasticsearch as a service - add following line to the [Service] Section in a service override file
Environment=ES_TMPDIR=/usr/share/elasticsearch/tmpTCP retransmission timout
- Each pair of Elasticsearch nodes communicates via a number of TCP connections which remain open until one of the nodes shuts down or communication between the nodes is disrupted by a failure in the underlying infrastructure
- Elasticsearch must wait while the retransmissions are happening and can only react once the operating system decides to give up
- Most Linux distribution default to retransmitting any lost packets 15 times
- Retransmissions back off exponentially, so these 15 retransmissions take over 900 seconds to complete
- The linux default allows for communication over networks that may experience very long period of packet loss
- but this default is excessive and even harmful on the high quality networks used by most Elasticsearch installation
- when a cluster detecs a node failure it reacts by reallocating lost shards, rerouting searches and maybe electing a new master node
- Highly available clusters must be able to detect node failures promptly, which can be achieved by reducint the permitted number of retransmissions
- Connections to remote clusters should also prefer to detect failures much more quickly thatn the linux default allows
- Linux users should therefore reduce the maximum number of TCP retranmissions
sysctl -w net.ipv4.tcp_retries2=5- To set this value permanently, update the
net.ipv4.tcp_retries2, setting in/etc/sysctl.conf - To verfiy after rebooting, run
sysctl net.ipv4.tcp_retries2
Related configuration
- Elasticsearch also implements its own internal health checks with timeouts that are much shorter than the default retransmission timeout on Linux
- Since these are application-level health checks their timeout must allow for application-level effects such as garbage collection pauses
- you should not reduce any timeout related to these application-level health check
- you must also ensure your network infrastructure does not interfere with the long-lived connections between nodes, even if those connections appear to be idle
- Device which drop connections when they reach a certain age are a common source of problems to Elastic search clusters, and must not be use
