
본 내용은 한빛미디어의 [혼자 공부하는 머신러닝+딥러닝]을 참고하였습니다.
Chapter 01. 나의 첫 머신러닝
01-1. 인공지능과 머신러닝, 딥러닝
-
인공지능이란?
-> 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술. -
머신러닝(ML)이란?
-> 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야.
-> 대표적인 라이브러리 : scikit-learn -
딥러닝(DL)이란?
-> 인공 신경망(Artificial Neural Network)을 기반으로한 머신러닝 알고리즘
-> 대표적인 라이브러리 : 구글의 Tensorflow, 페이스북의 Pytorch
01-2. 코랩과 주피터 노트북
-
코랩(Colab)
-> 구글에서 제공하는 클라우드 기반의 주피터 노트북 개발 환경** 노트북 : 텍스트와 프로그램 코드를 자유롭게 작성할 수 있는 온라인 에디터, 코랩의 프로그램 작성단위
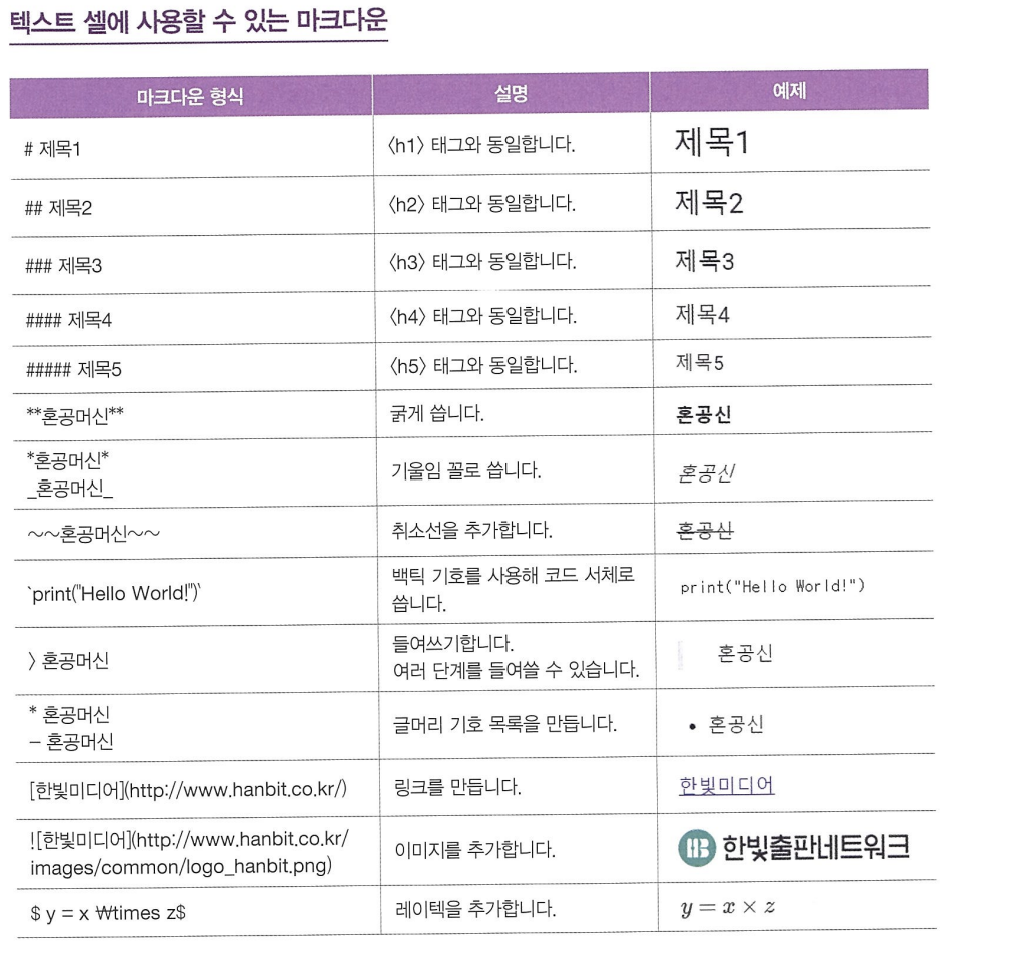
-셀에서 사용하는 툴바와 마크다운
01-3. 마켓과 머신러닝
-
특성(feature)
-> 데이터를 표현하는 하나의 성질(Ex- 생선의 길이, 크기) -
훈련(Training)
-> 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정.
-> Scikit-learn에서 fit()메서드가 이를 담당함 -
KNN(K-Nearest Neighbor)알고리즘
-> 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을
참조하여 분류하는 알고리즘 ( k의 기본값은 5)from sklearn.neighbors import KNeighborsClassifier #KNN 클래스 import kn = KNeighborsClassifier() #KNN 사용 kn.fit(fish_data, fish_target) #Training method인 fit() 사용-> kn.n_neighbors 변수 값을 설정하면 knn 이웃 개수 선언 가능(기본값=5)
-
모델(Model)
-> 머신러닝 프로그램에서 알고리즘이 구현된 객체 -
정확도
-> (정확히 맞힌 개수) / (전체 데이터 개수)
-> scikit-learn에서는 0~1사이의 값을 갖고 score()메서드를 사용하여 정확도를 평가kn.score(fish_data, fish_target)
Chpter 02. 데이터 다루기
02-1. 훈련 세트와 테스트 세트
-
지도학습 vs 비지도 학습
*지도학습 : input과 target을 전달하여 모델을 훈련하고 데이터를 예측하는 데 사용
ex) KNN(K-Nearest Neighbor)*비지도학습 : target 데이터 없이 input 데이터로만 모델을 훈련하고 어떤 특징을 찾는 데 사용
ex) K-means
-
훈련 세트(training set)
-> 모델을 훈련할 때 사용하는 데이터, 훈련 세트가 클 수록 좋음 -
테스트 세트(test set)
-> 모델을 테스트 할 때 사용하는 데이터, 전체 데이터에서 보통 20~30%를 테스트 세트로 사용함 -
샘플링 편향
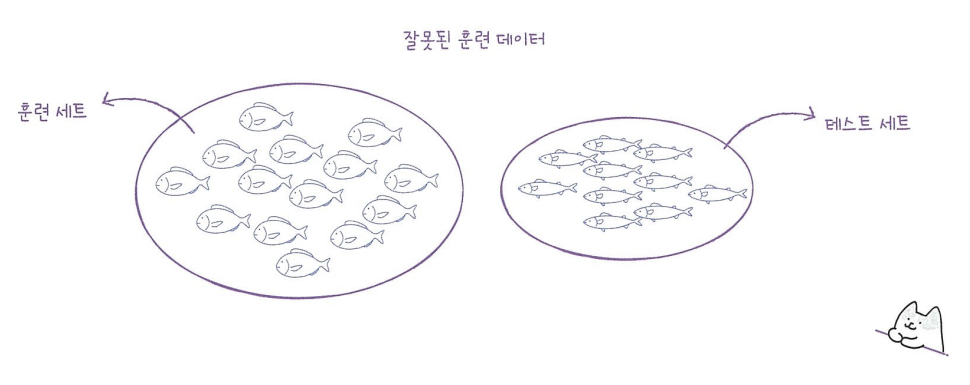
-> 데이터가 편향되어있음
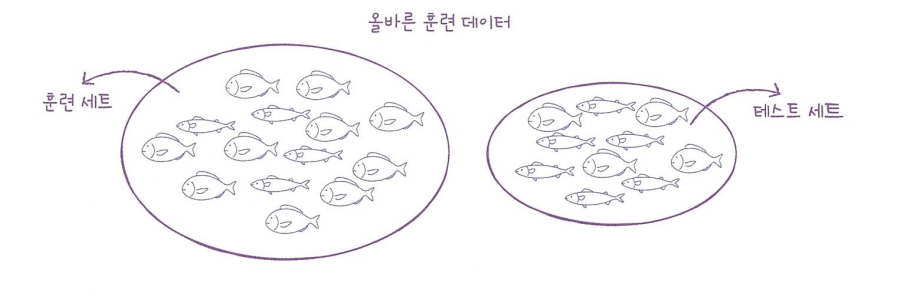
-
핵심 함수(numpy)
seed() : 난수를 생성하기 위한 정수 초깃값을 지정.
arange() : 일정한 간격의 정수 또는 실수 배열을 만듦
shuffle() : 주어진 배열을 랜덤하게 섞음. 다차원일 경우 첫 번째 행에 대해서만 섞음
02-2. 데이터 전처리
데이터 전처리
-> 모델에 훈련 데이터를 주입하기전에 데이터를 가공
-
numpy 형태

numpy를 이용해 위의 데이터를 가공해야함!

-
train_test_split

-> 매우 중요!! 계속 쓰임
표준점수
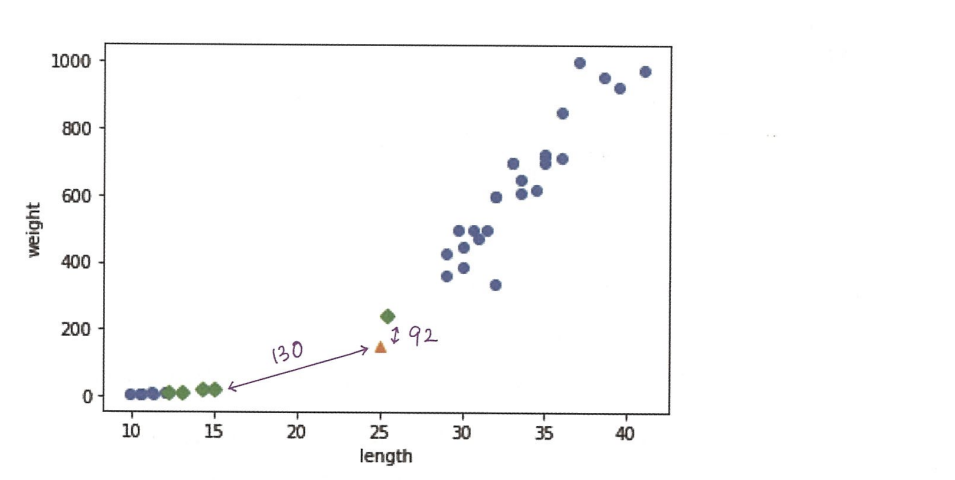
-> 데이터의 스케일이 다름!!
- 표준화 : 훈련 세트의 scale을 바꾸는 방법
-> (원 점수 - 특성(feature)의 평균) / 표준편차
*반드시 training set의 평균과 표준편차로 test set을 바꿔야함
브로드캐스팅(broadcasting)
-> 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장
