이번 챕터에서는 신경망 네트워크 학습에 사용되는 최적화 기법들을 소개한다. 특히, 비용 함수 를 크게 감소시키는 신경망 네트워크의 파라미터 를 찾는 것에 초점이 맞춰져 있다.
우선 머신러닝을 학습할 때 사용되는 최적화와 순수 최적화가 얼마나 다른지 서술하고, 이후에 신경망 네트워크에서 최적화를 할 떄 발생하는 주요한 어려움을 제시한다.
8.1 How Learning Differs from Pure Optimization
딥 모델의 학습에서 사용되는 최적화 알고리즘은 전통적인 최적화 알고리즘과 다르다.
- 대부분의 머신러닝 시나리오
- 테스트셋에 대해 정의되고 다소 다루기 어려울 수 있는 성능 평가 에 대해 신경을 씀
- 우리는 를 오직 간접적으로만 최적화 우리가 그렇게 함으로써 가 개선될거라고 생각하며 다른 cost function 를 감소시킴
- 순수 최적화
- 를 최소화하는 것 자체가 목표
- 딥 모델을 학습시키는 최적화 알고리즘은 머신러닝의 목적 함수의 특정 구조에 대한 몇몇 전문 지식을 포함
학습 데이터셋에 대해 평균을 내는 비용함수는 다음과 같이 쓸 수 있다.
(여기서 L은 데이터 당 손실 함수이고, 는 가 input일 때 예측된 output, 은 경험적인 분포이다.)
지도 학습의 경우, 는 target output이다. 비지도 학습의 경우 L에 대한 항은 과 이다.
위에서 훈련 데이터셋에 대한 목적함수를 정의했다. 우리는 보통 유한한 학습 데이터셋 외에 the data generating distribution 전반에 거치는 기댓값에 대한 목적함수를 최소화하는 걸 선호한다.
8.1.1 Empirical Risk Minimization
머신러닝 알고리즘의 목표는 위에 서술된 expected generalization error를 줄이는 것이다. 이 양은 risk(위험)라고 알려져 있다. 만약 우리가 true distribution 를 안다면, 위험 최소화는 최적화 알고리즘에 의해 풀 수 있는 최적화 작업이다. 그러나 우리가 학습 데이터셋만 가지고 있어서 를 모를 때, 머신러닝 문제를 가진다.
머신러닝 문제를 최적화 문제로 바꾸는 가장 간단한 방법은 학습 데이터셋에 대한 expected loss를 최소화하는 것이다. 이는 true distribution 를 학습 데이터셋으로 정의된 경험적 분포 로 교체하는 것을 의미한다.
이제 경험적 위험을 최소화 하자.
이때 은 학습 데이터셋의 개수이다.
평균 학습 에러를 최소화하는 것을 기반으로 하는 학습 과정을 empirical risk minimization이라고 한다. 이 상태에서, 머신러닝은 straightforward optimization과 매우 유사하다. 바로 위험을 최적화하는 것이 아니라, 우리는 위험이 같이 크게 감소하길 바라면서 경험적 위험을 최적화한다.
경험적 위험을 최소화하는 것의 단점
- 오버피팅 될 가능성
높은 수용력을 가진 모델은 학습 데이터셋을 쉽게 기억할 수 있다.
- 경험적 위험을 최소화하는 것은 실현 가능성이 낮음
가장 효과적인 현대 최적화 알고리즘은 그래디언트 디센트를 기반으로 한 것이지만 많은 유용한 손실 함수들은 유용한 도함수를 가지고 있지 않다.(도함수가 0이거나 정의되지 않음)
==> 딥러닝에선 경험적 위험 최소화는 거의 사용하지 않음.
8.1.2 Surrogate Loss Function and Early Stopping
가끔, 우리가 신경쓰는 손실 함수는 효과적으로 최적화되지 않는다.
예를 들어, 0-1 손실 기댓값을 정확히 최소화 하는 것은 처리하기 어렵다.(입력 차원이 exponential)
이런 상황에선 대신 surrogate loss function을 최적화한다.
예를 들어, correct class의 음의 로그 우도는 0-1 손실의 대체재로 사용할 수 있다.
때때로, surrogate loss function은 실제로 더 학습할 수 있게 한다.
- 예를 들어, log-likelihood surrogate을 사용해 학습할 때, 테스트셋에 대한 0-1 손실은 학습 데이터셋 0-1 손실이 0이 된 후에도 계속 낮아진다.
- 이는 0-1 손실의 기댓값이 0인 경우에도, 클래스를 서로 멀리 밀어 분류기의 robustness를 향상시킬 수 있다.
일단 기본적인 최적화와 우리가 학습 알고리즘에서 사용하는 최적화의 가장 중요한 차이는 학습 알고리즘은 local minimum에서 멈추지 않는다는 것이다.
대신, 머신러닝 알고리즘은 보통 surrogate loss function을 최소화하지만 early stopping을 기반으로 한 수렴 기준을 만족하면 알고리즘을 멈춘다.
early stopping criterion은 실제 기본적인 loss function을 기반으로 하고, overfitting이 되기 시작하면 알고리즘을 멈추도록 설계되어 있다.
8.1.3 Batch and Minibatch Algorithms
일반적인 최적화 알고리즘과 구별되는 머신러닝 알고리즘의 특징은 목적 함수가 일반적으로 학습 데이터셋에 대한 합으로 분해된다는 것.
머신러닝에서 최적화 알고리즘은 보통 전체 비용 함수의 일부 항들만을 사용하여 추정된 비용 함수의 기댓값을 기반으로 파라미터를 업데이트한다.
예를 들어, log space에서 MLE문제를 각 데이터의 합으로 분해해보자.
이 합을 최대화 하는 것은 학습 데이터셋에 정의된 경험적 분포에 대한 기댓값을 최대로 하는 것과 같다.
최적화 알고리즘에서 사용되는 목적함수 의 대부분의 특성은 학습 데이터셋에 대한 기댓값이다.
예를 들어, 가장 흔히 사용되는 특성은 그래디언트이다
전체 데이터셋에서 모든 데이터에 대해 모델을 평가해야하기 때문에, 이 기댓값을 정확히 계산하는 것은 매우 비싸다. 실제로, 우리는 데이터셋에서 몇 개의 데이터를 랜덤하게 샘플링하고, 이 데이터들에 대한 평균을 구함으로써 기댓값을 계산할 수 있다.
n개의 샘플에서 추정된 평균의 표준 오차가 인 것을 떠올려보자. n이 100일 때와 10000일때를 비교해보면, 기댓값을 계산하는 계산량은 100배 차이나지만, 평균의 표본오차는 10배 감소한다. 대부분의 최적화 알고리즘은 실제 그래디언트를 느리게 계산하는 것보다 유사한 추정값을 빨리 계산할 때 훨씬 빨리 수렴한다.
적은 수의 샘플에서 온 그래디언트에서 또 생각해볼만한 통계적 추정은 학습 데이터셋의 redundancy이다. 최악의 경우, 모든 m개의 샘플이 서로 동일한 것일 수 있다. 실제로, 많은 수의 데이터가 그래디언트에 모두 매우 유사한 기여를 한다는 것을 알 수 있다.
전체 학습 데이터셋에서 사용하는 최적화 알고리즘은 batch 혹은 deterministic gradient 방법이다. 보통 "batch gradient descent"는 전체 학습 데이터셋의 사용을 암시한다. 다만,"batch"라는 용어는 데이터의 그룹을 표현하기 위해 사용한다. 예를 들어, 흔히 말하는 "batch size"는 minibatch의 사이즈를 의미한다.
한 번에 하나의 데이터만 사용하는 최적화 알고리즘은 stochastic 또는 online라 한다.
딥러닝에서 사용하는 대부분이 알고리즘은 1개 이상 전체 데이터 이하의 데이터를 가지고 학습한다. 이러한 방식을 minibatch 또는 minibatch stochastic이라 하고, 지금은 간단하게 stochastic이라 한다.
Minibatch 크기는 보통 다음과 같은 요소들에 의해 결정된다.
-
배치가 클수록 그래디언트를 정확하게 추정할 수 있지만, linear returns보다 덜하다.
-
멀티코어 아키텍쳐는 일반적으로 매우 작은 배치에서 활용도가 낮음.
-
배치의 모든 데이터가 병렬적으로 처리된다면, 메모리의 양은 배치 크기 만큼 커진다.
-
하드웨어의 몇몇 종류는 배열 크기를 특정하게 정할 때 런타임이 더 좋아진다.(ex. GPU는 2의 지수로 배치 크기를 정하는게 나음.)
-
작은 배치는 정규화 효과를 제공할 수 있다.(학습 과정에 노이즈를 더하는 느낌쓰)
** 작은 배치로 학습하는 것은 그래디언트의 변동성이 크기 때문에 안정성을 유지하기 위해 작은 학습률을 사용한다.
** 작은 배치 + 작은 학습률의 조합으로 런타임이 매우 길어질 수 있음.
몇몇 알고리즘은 소수의 데이터로 정확하게 추정하기 어려운 정보를 사용하거나 샘플링 에러를 증폭시키는 방식으로 정보를 사용하기 때문에 샘플링 에러에 대해 민감할 수 있다.
- 그래디언트 를 기반으로 한 업데이트는 보통 비교적 robust하고 100과 같은 더 작은 배치도 다룰 수 있다.
- Hessian matrix 와 와 같은 업데이트를 계산하는 이계(second-order) 방법은 10000과 같은 더 큰 배치를 필요로 한다.
또한 중요한 것이 minibatch가 랜덤으로 선택되어야 한다는 것이다.
데이터의 집합에서 그래디언트의 기댓값을 편향 없이 추정하기 위해선 데이터들이 독립이라는 가정이 필요하다.
많은 데이터셋이 연속적인 데이터가 매우 연관된 방식으로 배열되어 있다.
- 예를 들어, 우리가 피 샘플 테스트 결과의 리스트가 있는 의학 데이터셋을 가지고 있다고 하자. 이 리스트는 첫번째 환자의 5개 피 샘플, 두번째 환자의 3개 피 샘플, .. 순으로 정리되어 있을 것이다. 만약 우리가 순서대로 데이터를 사용한다면, 데이터셋의 많은 환자 중 주로 한 명의 환자를 나타내기 때문에 우리의 미니배치 각각은 극단적으로 편향되어 있을 것이다.
그래서 미니배치를 선택하기 전에 데이터를 섞는 과정이 필수적이다. 하지만 매우 큰 데이터셋을 미니 배치를 구성할 때 마다 uniform하게 섞는 것은 불가능하다. 다행히 실제에선, 데이터셋을 한 번 섞고, 그 순서를 저장하는 것만으로도 충분하다.
머신러닝에서 많은 최적화 문제는 여러 데이터에 대해 병렬로 전체 개별 업데이트를 계산할 수 있을만큼 충분히 잘 분해된다. 다시 말해서, 우리는 여러 다른 미니 배치에 대한 업데이트를 계산하는 동시에 한 미니배치 에 대한 를 최소화 하는 업데이트를 계산할 수 있다.
미니배치 확률적 경사하강법의 흥미로운 동기는 데이터가 반복되지 않는 한 실제 일반화 오류의 그래디언트를 따른다는 것이다. 대부분의 미니배니 확률적 경사하강법의 구현은 데이터셋을 한 번 섞고, 여러 번 통과한다. 첫번째 통과할 때, 각 미니배치는 true generalization error의 편향되지 않은 추정값을 계산하는데 사용한다. 두번째 통과 시에, 데이터 생성 분포에서 새로운 데이터들을 얻는게 아니라 이미 사용했던 값들을 다시 샘플링 하기 때문에 추정값이 편향이 된다. 모르겠음
SGD가 generalization error를 최소화 한다는 사실은 데이터 또는 미니배치를 data의 stream에서 끌어 오는 online learning case에서 가장 쉽게 볼 수 있다. 다시 말해서, 고정된 학습 데이터셋을 받는 것 대신, 학습자가 data generating distribution 에서 오는 모든 데이터 (x,y)를 가지고 매순간 새 데이터를 보는 것과 유사하다.
등가는 x와 y가 모두 이산일 때 도출하기 가장 쉽다. 이 경우 generalization error은 다음과 같이 정확한 그래디언트를 가지는 합으로 쓸 수 있다.
그러므로, 우리는 데이터셋의 미니배치 {, ..., }을 샘플링 하고, 미니배치에 대해 파라미터 각각에 대한 손실의 그래디언트를 계산해 정확한 그래디언트의 편향되지 않은 추정량을 얻을 수 있다.
물론 이 해석은 데이터들이 재사용되지 않았을 때만 적용된다. 하지만 학습 데이터셋이 정말 크지 않다면 학습 데이터셋을 여러번 지나는 것이 보통 최선이다. 첫번째 외의 에폭은 편향된 값을 값을 가져, 학습 에러와 테스트 에러 사이의 갭을 증가시키지만 이를 상쇄할 만큼 학습 에러를 감소시키기 떄문에 충분한 이점이 있다고 본다.
8.2 Challenges in Neural Network Optimization
일반적으로 최적화는 매우 어려운 작업이다. 전통적으로 머신러닝은 최적화 문제를 convex하기 위한 목적 함수와 제약조건을 설계하면서 일반적인 최적화의 어려움을 피해왔다. 신경망 네트워크 학슴할 때, 우리는 일반적인 non-convex 문제에 직면하게 된다. 이번 세션에서는 딥 모델을 학습시킬 떄 사용하는 최적화에 포함된 여러 유명한 문제들을 살펴보려고 한다.
8.2.1 Ill-Conditioning
** 조건수가 큰 경우 == 약간의 값 변화에도 함수 결과값이 지나치게 크게 변화하는 경우
convex 함수를 최적화 할 때 발생하는 문제들이 있다. 가장 주요한 문제는 헤시안 행렬 의 ill-conditioning이다. 이는 볼록이든 아니든 대부분의 수치적 최적화에서 일반적인 문제이다.
ill-conditioning 문제는 일반적으로 신경망 네트워크 학습 문제에서 발생된다. ill-conditioning은 매우 작은 스텝이 비용 함수를 증가시킨다는 점에서 SGD가 "stuck"된다.
비용 함수의 second-order Taylor series expansion은 의 그래디언트 스텝이 비용에 더해질 것을 예측한다.
그래디언트의 ill-conditioning은 이 을 초과할 때 문제가 된다. 신경망 네트워크 학습 문제에서 ill-conditioning이 해로운지 아닌지를 확인하기 위해선, 와 항을 모니터링할 수 있다. 많은 경우에서, gradient norm은 학습 내내 크게 줄어들지 않지만, 항은 한 자릿 수 이상 크게 증가한다. 즉, 강한 gradient에도 불구하고 learning rate이 더 강하게 축소시키기 때문에 학습이 매우 느려진다.
ill-conditioning이 신경망 네트워크 학습 이외의 다른 설정에도 존재하지만, 이를 해결하기 위한 다른 기술은 신경망 네트워크에서 이용하기 어렵다.
- 예를 들어, Newton의 방법은 좋지 않은(poorly conditioned) 헤시안 행렬을 갖고 있는 convex 함수를 최소화 하는 좋은 방법이지만, 신경망 네트워크에 적용되기 전에 상당한 수정이 필요하다.
8.2.2 Local Minima
convex 최적화 문제의 가장 중요한 특징은 local minimum을 찾는 문제로 줄어들 수 있다는 것이다. 어떤 any local minimum은 global minimum이 보장된다. 몇몇 convex함수는 하나의 global minimum 보단 바닥에서 평평한 지역을 갖는다. 이 때, 평평한 지역에 속하는 어느 점이든 이용가능한 답이 된다.
neural net과 같은 non-convex함수에선 많은 local minimum이 가능하다. 실제로, 거의 모든 딥 모델은 본질적으로 매우 많은 local minimum을 갖도록 보장된다. 하지만 이게 중요한 문제는 아님!
신경망 및 동등하게 파라미터화된 여러 잠재 변수가 있는 모든 모델은 model identifiability으로 인해 여러 local minimum을 갖음.
충분히 큰 학습 데이터셋이 모델 파라미터의 하나를 제외한 모든 설정을 배제할 수 있는 경우, 모델을 식별할 수 있다고 함.
잠재 변수가 있는 모델은 서로 잠재 변수를 교환하여 동등한 모델을 얻을 수 있기 때문에 식별할 수 없는 경우가 많음.
- 예를 들어, 신경망을 취하고, unit i에 대해 들어오는 가중치 벡터를 unit j에 대해 들어오는 가중치 벡터로 교체한 다음, 나가는 가중치 벡터에 대해 동일한 작업을 수행하여 레이어 1을 수정할 수 있다.
각각 n개의 유닛을 갖는 m개의 레이어가 있다면, hidden layer를 배열하는 개의 방법이 있다. 이러한 종류의 식별 불가능성을 weight space symmetry라 한다.
weight space symmetry에 더해서, 많은 종류의 신경망 네트워크가 식별 불가능성의 추가적인 원인을 가진다.
- 예를 들어, 어떤 rectified linear 또는 maxout network에서, 우리는 나가는 가중치를 로 스케일링하고, unit의 모든 들어오는 가중치와 bias를 로 스케일링 할 수 있다.
이는 비용 함수가 모델의 output이 아니라 가중치에 대해 직접적으로 의존하는 weight decay와 같은 항을 포함하지 않는다면, Relu나 maxout network의 모든 local minimum이 동등한 local minima의 (mxn)차원 쌍곡선에 놓인다.
이러한 model identifiability 문제는 신경망 네트워크 비용 함수에서 local minima가 매우 많거나 셀 수 없을 수 있다는 것을 의미한다. 그러나 식별 불가능성에서 발생하는 모든 local minima는 비용 함수 값에서 서로 동등하다. 즉, 이러한 local minima는 non-convexity의 문제가 아니다.
model identifiabilty
: 동일한 성능을 내도록 학습시켜면 파라미터가 같은 것!
똑같은 문제를 똑같이 학습을 시켜도 같은 성능이지만 다른 파라미터를 갖게 됨. 즉, non-identifiability에서 오는 local minima가 비용이 같다 = 같은 성능을 내는 다른 파라미터들이 존재한다.
그래서 local minima가 많은 것은 큰 문제가 되지 않는다
local minima는 global minimum에 비해 높은 비용을 가질 때 문제가 된다. hidden units없이 global minimum보다 더 높은 비용으로 local minimum을 갖는 작은 신경망 네트워크를 구성할 수 있다. 높은 비용을 갖는 local minima가 흔하자면, 그래디언트 기반 최적화 알고리즘에서는 심각한 문제가 될 수 있다.
실제로 높은 비용을 갖는 local minima가 많은지, 최적화 알고리즘이 이를 직면하는지는 아직 연구되고 있다. 수년 동안, 대부분의 연구자들은 local minima을 신경망 네트워크 최적화에서 성가신 흔한 문제로 여겨왔다. 오늘날엔 그렇지 않은 것 같다. 여전히 연구 영역으로 남아 있지만, 전문가들은 이제 충분히 큰 신경망의 경우 대부분 local minimum이 낮은 비용 함수 값을 가지고, global minimum을 찾는 것이 중요하지 않다고 말합니다.
local minima를 배제할 수 있는 테스트는 시간 경과에 따른 그래디언트의 norm을 그래프로 그리는 것이다. 그래디언트의 norm이 무의미한 크기로 줄어들지 않는다면, 그 문제는 local minima도 아니고 다른 종류의 임계점도 아니다. 이러한 종류의 negative test는 local minima를 배제할 수 있다. 고차원에서 local minima를 문제라고 설립하긴 어렵다. local minima외에 많은 구조들 또한 작은 그래디언트를 갖는다.
8.2.3 Plateaus, Saddle Points and Other Flat Regions
안장점 주변 몇몇 값들은 더 높은 비용을 가지지만, 다른 점들은 또 낮은 값을 갖는다. 안장점에서, 헤시안 행렬은 양수 고유값과 음수 고유값을 모두 갖는다. 양수 고유값과 관련된 고유벡터를 따라 놓여있는 점들은 안장점보다 더 큰 비용을 가지고, 반면에 음수 고유값과 관련된 고유벡터를 따라 놓여있는 점들은 더 작은 비용을 갖는다. 우리는 안장점을 local minimum과 local maximum이 교차하는 지점으로 볼 수 있다.
랜덤 함수들의 대부분의 클래스는 다음 행동을 보인다.
: 저차원의 공간에서, local minima는 흔하다.
: 고차원의 공간에서, local minima는 드물고 saddle point가 더 흔하다.
함수 에 대해, local minima에 대한 안장점의 수의 비율의 기댓값이 n과 함께 지수적으로 커진다. local minimum에서 헤시안 행렬이 오직 양수 고유값을 갖는다는 것을 생각해보자. 그리고 안장점에서 헤시안 행렬은 양수, 음수 고유값을 둘다 가진다. 각 고유값의 부호가 동전을 던져서 결정된다고 상상해보면, 낮은 차원일 땐 local minimum을 쉽게 얻을 수 있다. 하지만 n차원의 공간에선, n번의 동전이 모두 같은 면을 가져야하므로 지수적으로 거의 불가능하다.
랜덤 함수의 놀라운 특성은 낮은 비용을 가진 지역이 도달할수록 헤시안의 고유값이 양수가 될 확률이 높아진다는 것이다. 한 논문은 이론적으로 비선형성이 없는 얕은 autoencoder가 global minimum과 saddle point를 갖지만, global minimum보다 더 높은 비용을 갖는 local minimum은 없음을 보였다. 이러한 네트워크의 output은 input이 선형 함수이지만 손실함수가 non-convex한 함수이기 때문에 비선형 신경망의 모델로 연구하는데 유용하다. 후에, 보다 실제 신경망 네트워크가 많은 높은 비용의 안장점을 갖는 손실 함수를 가진다는 것을 실험적으로 보였다.
학습 알고리즘에서 안장점의 증식이 갖는 의미
- 그래디언트 정보만을 사용하는 1차 최적화 알고리즘에서는 명확하지 않다.
그래디언트는 종종 안장점 근처에서 매우 작아진다. - 한편, 경사하강법은 실험적으로 많은 경우에서 안장점을 탈출하는 것이 가능함을 보였다.
- continuous-time gradient descent는 분석적으로 안장점에 끌리기보다는 반발하는 것으로 나타난다고 주장했지만, 경사 하강법을 보다 현실적으로 사용하려면 상황이 다를 수 있다.
Newton의 방법에서, 안장점이 문제를 구성한다는 것은 명백하다.
- 경사하강법은 언덕을 내려가게 설계되었지, 명시적으로 임계점을 찾게 설계되진 않았다.
- 그러나, Newton의 방법은 그래디언트가 0인 점을 찾아 풀도록 설계되었다. 적절한 수정 없이는 안장점으로 점프할 수 있다.
- 고차원 공간에서 안장점의 증식은 2차 방법이 신경망 훈련을 위한 경사하강법을 대체하는데 성공하지 못한 이유를 설명한다.
- 2차 최적화를 위해 saddle-free Newton method를 도입했고, 기존 버전에 비해 크게 향상되었다.
maxima역시 고차원이 될 수록 지수적으로 생길 확률이 낮아짐
또한 일정한 값의 넓고 평평한 영역이 있을 수 있다.
- 이 위치에서 그래디언트와 헤시안 행렬은 모두 0이다.
- 모든 수치 최적화 알고리즘에 주요 문제를 제기한다.
- convex문제에서는 넓고 평평한 영역이 global minimum으로 구성되어야 하지만 일반적인 최적화 문제에서는 이러한 영역이 목적 함수의 높은 값에 해당할 수 있다.
8.2.4 Cliffs and Exploding Gradients
층이 많은 신경망의 비용함수 공간에는 cliff에 비유할 수 있는 아주 가파른 영역이 있는 경우가 많다(ex. 고도의 비선형 심층 신경망, 순환 신경망). 이 때, 기울기 갱신 단계에서 매개변수들이 크게 변해 이러한 cliff구조를 완전히 뛰어넘는 일이 흔하게 발생한다.
cliff를 위에서 아래로, 혹은 아래에서 위로 접근하면 문제가 발생할 수 있지만, gradient clipping을 이용하면 이러한 문제를 막을 수 있다.
gradient clipping
: 기울기가 최적의 "크기"를 나타내는 것이 아니라 아주 극소량의 영역 안에서 최적의 "방향"을 나타낸다는 것을 깨닫는데에서 시작.
: 전통적인 경사 하강법 알고리즘이 아주 큰 크기의 update step을 적용하는 상황에서 이 기법은 그러한 step의 크기를 줄이는 효과를 냄.
=> 근사적으로 cliff를 한 번에 벗어날 가능성이 줄어듦.
8.2.5 Long-Term Dependencies
계산 그래프가 극도로 깊어질 때, 발생하는 어려움 중 하나이다. 주로, 층이 많은 순방향 신경망, 순환 신경망 등에서 나타나는 문제이다(같은 매개변수들을 되풀이해서 적용할 때).
예를 들어, 행렬 를 거듭 곱하는 연산으로 이뤄진 경로가 계산 그래프에 있다고 가정하자. t번의 단계가 지나면 이는 를 곱하는 것과 같게 된다. 이 때, 의 고윳값 분해가 라고 하자. 그렇다면 다음과 같은 식이 성립한다.
크기가 1과 가깝지 않은 임의의 고윳값 는, 1보다 크면 발산하고, 1보다 작으면 소실한다. vanishing and exploding gradient problem문제는 이러한 그래프를 통과하는 그래디언트들이 에 따라 지수적으로 비례한다는 사실을 가리킨다. 기울기 소실 문제가 바생하면, 비용함수를 개선하기 위해 파라미터가 움직여야할 방향을 알기가 어려워지고, 기울기 폭발이 발생하면 학습이 불안정해진다. 앞서 나온 cliff구조는 이러한 기울기 폭발 현상의 한 예이다.
8.2.6 Inexact Gradients
대부분의 최적화 알고리즘은 우리가 정확한 그래디언트나 헤시안 행렬에 접근할 수 있다는 가정을 두고 설계된다. 하지만 실제 응용에선, 이들이 잡음 섞인 근삿값 또는 편향된 추정량으로만 주어질 때가 많다. 거의 모든 심층 학습 알고리즘은 샘플링 기반 추정에 의존한다(미니 배치를 이용해서 기울기를 계산하는 형태).
이 외에, 우리가 최소화 하려는 목적 함수 자체가 다루기 어려울 때도 있다. 목적 함수가 다루기 어려울 때, 그래디언트 역시 다루기 어렵다 .이러한 경우 우리는 그래디언트를 근사하는 방법을 사용한다.
- 예를 들어, 볼츠만 기계의 처리 불가능한 로그가능도의 기울기를 근사할 때는 contrastive divergence기법이 유영하다.
그래디언트 추정이 완벽하지 않다는 점을 고려해서 설계한 신경망 최적화 알고리즘이 다양하게 있다. 또한, 실제 손실함수보다 근사하기 쉬운 surrogate 손실 함수를 사용하는 것도 좋은 방법이다.
8.2.7 Poor Correspondence between Local and Global Structure
지금까지 살펴본 문제점은 주어진 한 점에서 손실함수가 갖는 불리한 특성들(cliff, saddle point ..)에서 기반한 것이었다.
하지만 이러한 문제점을 모두 극복한다 해도, 국소적으로 가장 많이 개선되는 방향이 훨씬 낮은 비용의 먼 지역을 가리키지 않는다면 여전히 저조한 성능을 보일 수 있다.
훈련에 걸리는 시간의 대부분이 solution에 도달하는 데 필요한 궤적의 길이에 기인한다. 아래 그림에서도 궤적(파란색 선)의 대부분이 산 모양의 구조를 멀리 돌아가고 있다는 것을 알 수 있다.
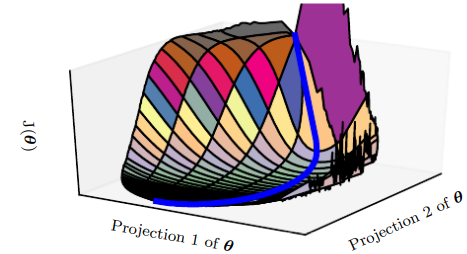
최적화의 어려움에 관한 연구 중에는 학습이 최소점이나 극소점, 안장점에 도달하는지의 여부에 초점을 둔 것들이 많지만, 실제 응용에선 신경망이 그런 종류의 임계점에 아예 도달하지 않는다. 기울기가 작은 영역이 도달하지 않는 경우도 있고, 이러한 임계점들이 반드시 존재한다는 보장도 없다.
- 예를 들어, 손실함수 에선 최소점이 없고, 대신 모델의 확신이 커지면서 어떤 값에 다가갈 뿐이다.
- 가 이산 변수이고, 가 소프트맥스 함수로 주어지는 분류기의 경우, 모델이 학습 데이터셋의 모든 데이터를 전확히 분류할 수 있다면 음의 로그가능도가 0에 임의로 다가갈 순 있지만 딱 0이 되진 않는다.
- 이와 같이, 실수값의 모델 에서는 음의 로그가능도가 음의 무한대로 다가갈 수 있다. 가 모든 학습 데이터셋 타겟의 값을 정확하게 예측한다면 , 학습 알고리즘에 의해 가 무한대로 증가할 수 있다.
최적화를 어렵게 만드는 문제들
- 목적함수의 속성(그래디언트)는 오직 근사적으로만 계산 가능.
(근사한 추정량에는 편향이나 변동이 존재) - local descent가 타당한 solution으로의 비교적 짧은 경로를 정의한다 해도, 경사 하강법이 실제로 local descent path를 따라가지 못할 수 있다.
- 목적함수에 poor conditioning이나 불연속 기울기 같은 문제점이 존재할 경우, 그래디언트가 목적 함수의 적절한 모델을 제공하는 영역이 아주 작을 수 있다.
step size가 인 local descent가 solution까지의 적절한 짧은 경로를 정의해도, 우리는 오직 인 local descent direction만을 계산할 수 있다. => 계산 비용 높아짐 - 종종, local information이 가이드를 제공하지 않을 수 있음
- 함수에 넓은 평평한 영역이 있을 때.
- 알고리즘이 어떤 한 임계점에 정확히 도달 했을 때.
8.2.8 Theoretical Limits of Optimization
연구에 따르면, 신경망 학습을 위해 설계할 수 있는 모든 최적화 알고리즘의 성능에는 일정한 한계가 존재한다.
하지만 이러한 한계가 신경망의 실제 응용에서 미치는 영향은 미비하다.
- 일부 이론적 결과들은 신경망의 unit이 이산 값들을 출력할 때만 적용됨.
=> 하지만 대부분의 신경망 unit은 연속 값을 출력. local search을 통한 최적화 가능 - 처리 불가능한 종류의 문제들이 존재한다는 이론적 결과도 있음.
=> 구체적인 문제가 이 부류에 해당하는지 판정하기는 어려움 - 주어진 크기의 신경망에 대한 해를 찾는게 처리 불가능하다는 연구 결과도 있음.
=> 하지만 실제에선 더 큰 신경망을 이용해 쉽게 해를 구할 수 있음.
=> 학습에서 필요한건 정확한 최적의 해가 아니라 일반화 오차가 좋아지기만 하면 됨.
8.3 Basic Algorithms
8.3.1 Stochastic Gradient Descent
머신러닝 전반, 특히 심층 학습에서 가장 자주 쓰이는 최적화 알고리즘은 확률적 경사 하강법(stochastic gradient descent, SGD)와 친구들이다. data generating distribution에서 독립적으로 추출한 m개의 데이터로 이루어진 미니배치의 평균 그래디언트를 통해 학습 데이터셋 전체의 그래디언트의 불편추정량을 구할 수 있다.
이를 알고리즘으로 나타내면 다음과 같다.

SGD 알고리즘의 핵심 파라미터는 학습 속도이다. 이전에 설명한 SGD는 고정된 학습 속도 을 사용했다. 하지만 실제 응용에선 시간에 따라 학습 속도를 점차 줄일 필요가 있으므로, 학습 속도를 시간에 따른 로 표기한다.
학습 속도를 줄여야 하는 이유는 SGD의 그래디언트 추정에서 노이즈가 도입되기 때문이다. 학습 과정에서 m개의 학습 데이터를 무작위로 추출하는 것이 하나의 노이즈의 요소로 작용하는데, 이는 알고리즘이 최솟값에 도달해도 사라지지 않는다. 반면, BGD에서는 총 비용함수의 그래디언트의 참값이 학습이 진행 됨에 따라 점점 작아져서, 최솟값에 도달하면 0이 된다.
BGD의 장점
- 전체 데이터에 대해 업데이트가 한번에 이루어지기 때문에 후술할 SGD 보다 업데이트 횟수가 적다. 따라서 전체적인 계산 횟수는 적다.
- 전체 데이터에 대해 error gradient 를 계산하기 때문에 optimal 로의 수렴이 안정적으로 진행된다.
- 병렬 처리에 유리하다.
BGD의 단점
- 한 스텝에 모든 학습 데이터 셋을 사용하므로 학습이 오래 걸린다.
- 전체 학습 데이터에 대한 error 를 모델의 업데이트가 이루어지기 전까지 축적해야 하므로 더 많은 메모리가 필요하다.
- local optimal 상태가 되면 빠져나오기 힘듦(SGD 에서 설명하겠음.)
따라서 BGD에서는 고정된 학습 속도를 사용해도 된다. SGD가 반드시 수렴한 충분조건은 다음과 같다.
실제 응용에서는 번째 반복까지는 학습 속도 를 다음과 같이 선형으로 감소하고, 번째 반복 이후에는 을 그대로 두는 방법이 흔히 쓰인다.
여기서 이다.
- 는 학습 데이터셋을 수백 번 정도 훑는데 필요한 반복 홧수로 설정
- 는 값의 약 1%정도로 잡아야 한다.
- 은 알고리즘을 여러 번 반복해보고, 최고의 성과를 낸 학습 속도 보다 크게 설정하는게 좋다.
SGD와 관련 미니배치 또는 online gradient기반 최적화 알고리즘은 업데이트 당 계산 시간이 학습 데이터 수에 비례하지 않아야 함. 최종 테스트 셋 에러가 어떤 고정된 허용치 이하가 되면 학습 데이터셋 전체를 다 훑지 않았어도 알고리즘을 종료하게 설정하면, 데이터셋이 커도 수렴할 수 있다.
최적화 알고리즘의 수렴 속도를 파악할 때 사용하는 척도는 로 정의되는 초과 오차(excess error)이다.
== 현재 비용함수가 가능한 최소 비용보다 얼마나 큰지를 나타낸 값
이론적으ㄹ, BGD가 SGD보다 수렴 속도가 좋다. 하지만 크라메르-라오 한계에 따르면 일반화 오차는 보다 빠르게 감소할 수 없다.(이보다 수렴이 빠르다는 것은 over fitting에 해당할 수 있다)
8.3.2 Momentum
Momentum은 학습을 빠르게 하기 위해 고안된 것으로, 특히 높은 curvatue이나 작지만 일관된 그래디언트, 노이즈가 섞인 그래디언트가 있는 상황에서 학습을 빠르게 해줌.
momentum 알고리즘은 이전 단계의 기수적으로 감소하는 이동 평균을 누적해서, 그 기울기들의 방향으로 계속 이동한다.
- 속도(velocity)역할을 하는 변수 을 사용
: 파라미터들이 파라미터 공간에서 움직이는 방향과 빠르기를 결정
: 매 스텝에서 알고리즘은 이 속도를 음의 기울기의 지수 감소 평균(exponentially decaying average of the negative gradient)으로 설정 - 모멘텀 = 질량 x 속도
- 모멘텀에서는 입자의 질량이 1이라고 가정하므로, 속도 벡터 자체를 입자의 운동량으로 간주
- 하이퍼파라미터 은 이전 단계 기울기들의 기여가 지수적으로 얼마나 빠르게 감소하는지를 결정
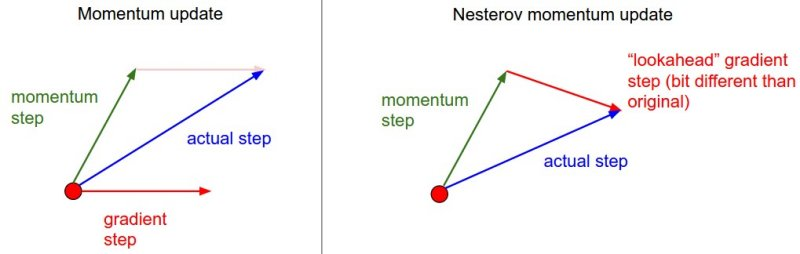
업데이트 룰은 다음과 같다속도 는 기울기 성분 을 누적한다.
가 에 비해 클수록 이전 기울기들이 현재 방향에 더 큰 영향을 미친다.

모멘텀 학습 알고리즘이 해결하고자 하는 주된 문제는 2가지이다. - poor conditioning of the Hessian matrix
- variance in the stochastic gradient
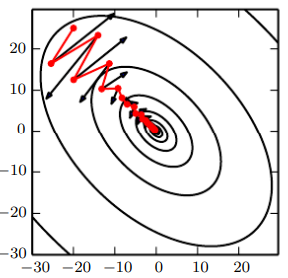
이 그림은 1번이 어떻게 극복되는지 보여준다. 빨간선이 모멘텀 학습 알고리즘이 따르는 경로이다. 그 경로의 각 단계에 있는 검은색 화살표는 해당 점에서 보통 경사 하강법이 따라갔을 단계를 나타낸다. 불량조건 이차 목적함수가 마치 가파른 경사면이 있는 협곡과 비슷한 모양임을 알 수 있다. 모멘텀 방법은 이런 협곡을 길이 방향으로 통과하지만, 경사 하강법은 협곡의 좁은 축을 가로지르며 왕복해 시간을 낭비한다.
이전에는 스텝 크기를 단순히 gradient norm에 학습 속도를 곱한 것으로 설정했다. 이제는 스텝 크기가 기울기들의 수열(sequence)가 얼마나 크고 어떻게 정렬되는지에 따라 달라진다. 스텝 크기는 정확히 같은 방향을 가리키는 인접한 기울기들이 다수힐 때 최대가 된다. 모멘텀 알고리즘이 항상 그래디언트 를 관측하다면, 학습은 의 방향으로 가속되다가 결국에는 종단 속도(terminal velocity)에 도달한다.
이때 각 스텝 크기는 다음과 같다.
따라서, 모멘텀 하이퍼파라미터를 의 관점에서 생각하면 좋다. 예를 들어, 는 경사 하강법 알고리즘을 기준으로 최대 빠르기에 10을 곱하는 것에 해당한다.(는 0.5나 0.9, 0.99등이 흔히 쓰인다. 학습 초반에는 작은 값으로 시작해 점차 증가하는 방식을 쓸 수도 있음)
임의의 한 시점에서 입자의 위치는 로 주어진다. 입자에 가해지는 모든 힘의 합, 즉 알짜힘(net force) 에 의해 입자는 다음과 같이 가속된다.
