Self-Supervised Learning(DenseCL, MoCo-v3, Barlow Twins)
Self-Supervised Learning 연구 흐름
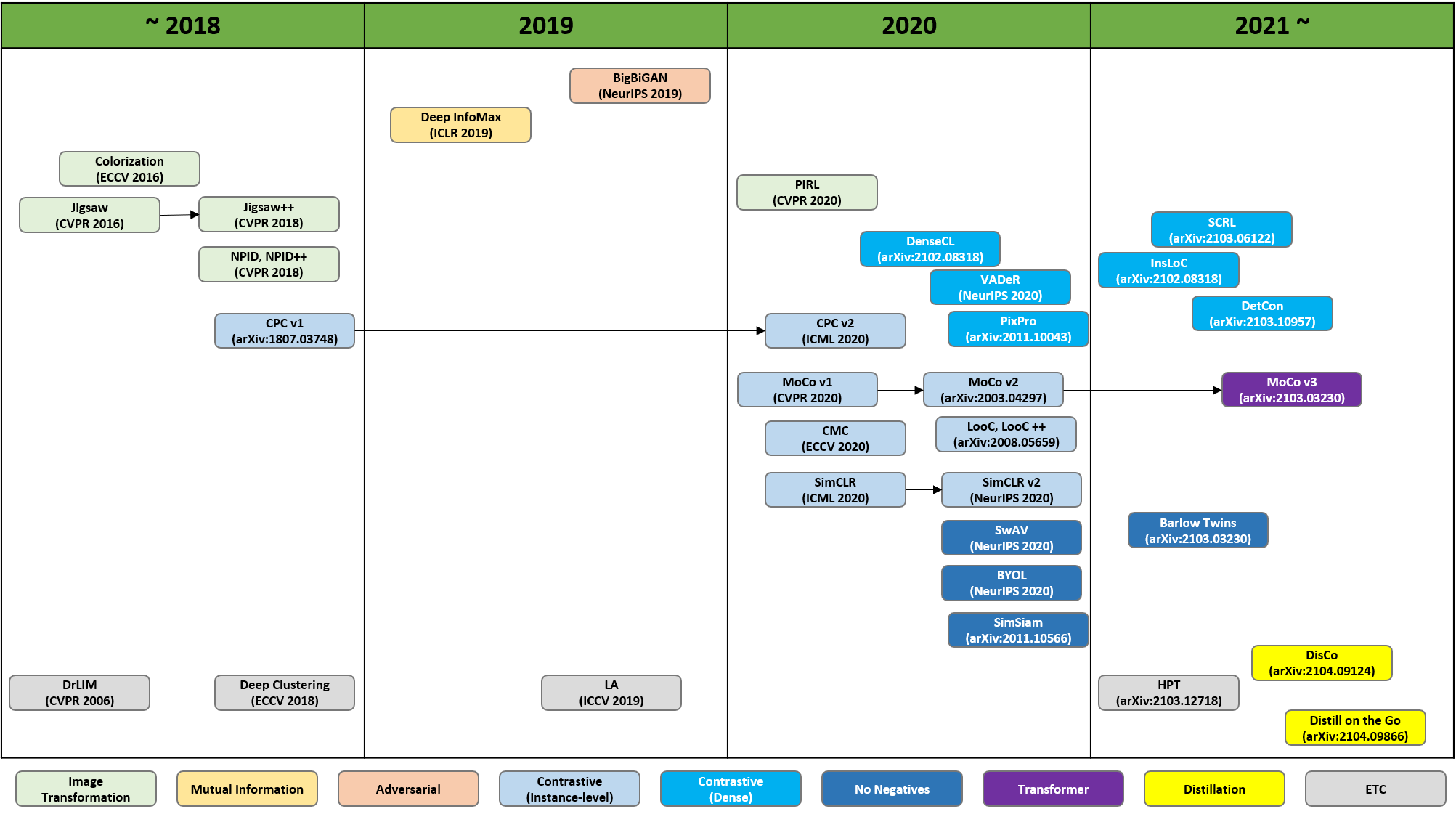
이 중, Constractive(Dense), No Negatives, Transformer기반 방법인 DenseCL, Barlow Twins, Moco v3에 대해 리뷰해보려 함.
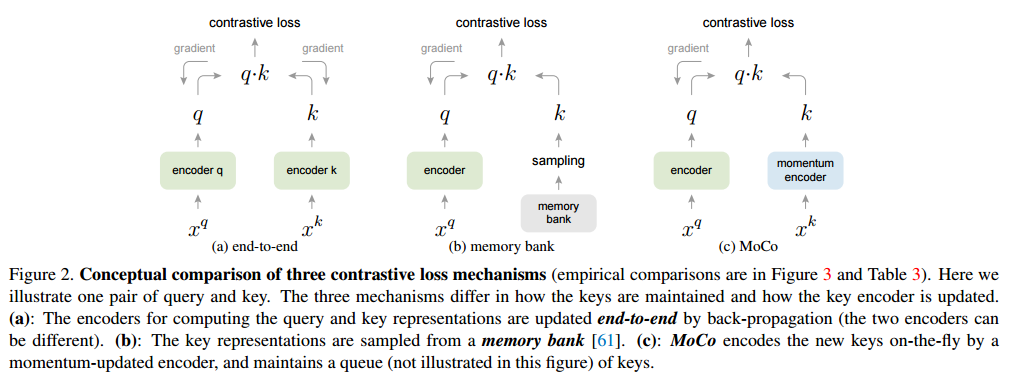
MoCo
MoCo의 핵심아이디어는
(1) negative representation을 저장하는 queue,
(2) key encoder의 mementum update 입니다.현재 batch에서 augmentation된 이미지는 queue에 enqueue 합니다. queue내에 존재하는 과거의 representation은 deque 합니다. encoder가 갱신됨에따라 과거의 representation은 consistent하지 않기 때문입니다. query encoder는 학습이 진행되면서 갱신이 되고, key encoder는 momentum 기법을 사용하여 서서히 갱신합니다(빠르게 변화하는 query와 똑같이 학습할 경우 key값들의 consistency가 유지되지 않아 loss가 전혀 수렴하지 않기 때문).
출처 : https://deep-learning-study.tistory.com/730
Dense Contrastive Learning for Self-Supervised Visual Pre-Training(DenseCL)
- 2020년에 실린 논문
MoCo-v2를 베이스로 하고, MoCo-v2에서 사용한 constrative learning(image로부터 추출한 하나의 벡터 기준)을 본 논문에선 gloabl contrastive learning이라고 부름.
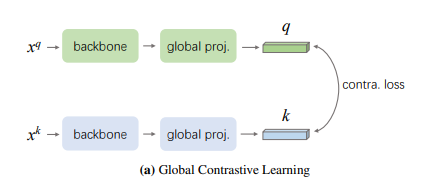
이렇게 학습시킨 모델을 dense prediction이 필요한 task(semantic segmantation, object detection, instance segmentation)에 fine-tuning하면 gap이 존재.
=> 왜? MoCo는 image classifiaciton을 기준으로 global representation을 추출해 constrative learning을 수행했기 때문!여기서 말하는 gap을 자세히 풀어서 설명하면,
1. 거의 모든 준지도 학습 방법은 instance discrimination과 같은 각 이미지를 분류하는 것 => global feature만 사용해 image-level의 prediction에 초점을 둠
2. 현재 방법들은 보통 이미지 분류 벤치마크로 평가되거나 최적화 됨
=> 하지만 이미지 분류를 잘한다고 해서 더 정확한 object detection을 잘한다고는 볼 수 없음
==> 이를 해결하기 위해 "pre-training as a dense prediction task directly"하자!
이 gap을 채우기 위해 dense contrastive learning(픽셀 단위에서 작동)을 도입한다.
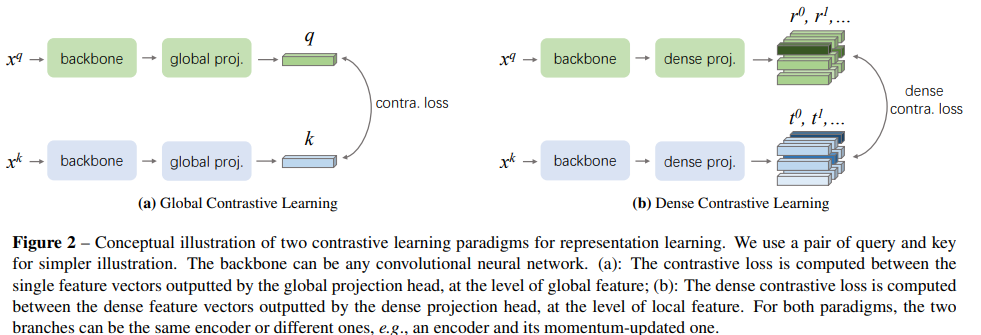
- head(dense projection head)를 하나 더 추가하여 dense feature map을 추출하고, 이 feature map의 vector사이에 constrative learning을 수행
DenseCL Pipeline
- input view과 주어질 때, backbone network를 사용해서 dense feature map을 추출, projection head로 보냄
- projection head는 2개의 sub-head가 병렬로 구성되고, 각각 global projection head와 dense projection head라 불림
- global projection head는 dense feature maps을 input으로 받아서 각 view에 대한 global feature를 생성
- global pooling layer와 MLP(fc layer - ReLU - fc layer로 구성)
- dense projection head는 같은 input을 사용하지만 output은 dense feature vectors
- 특히, gloabl pooling layer는 제거되고, MLP는 1x1 conv layer로 교체됨(그래도 global projection head와 같은 수의 파라미터 가짐)
- backbone과 2개의 병렬 projection heads가 global feature과 local feature수준 모두에서 constrastive sim loss에 의해 학습됨
** 기존의 MoCo Loss function(global feature)
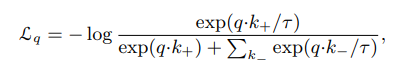
** 새로 제안한 Loss function(local feature)
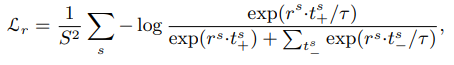
** 최종 Loss function
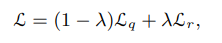
- 를 0.5로 두고 실험. 하지만 unstable.
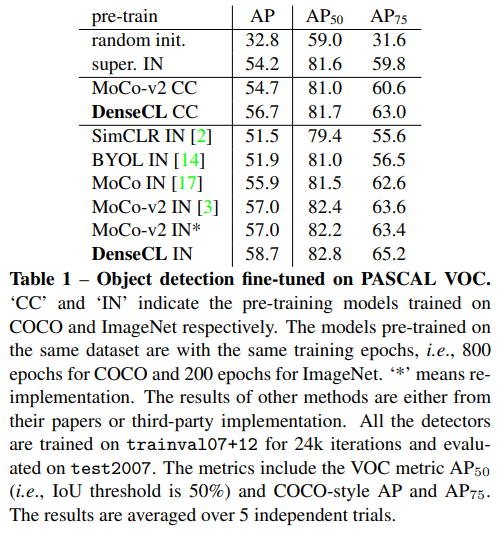
Experiments
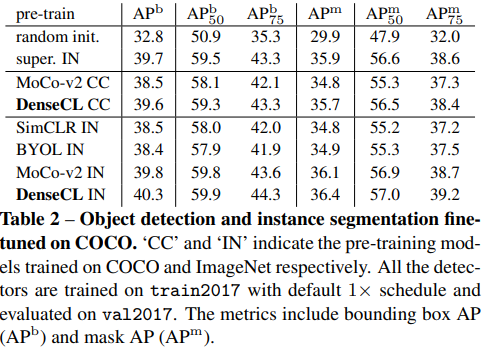
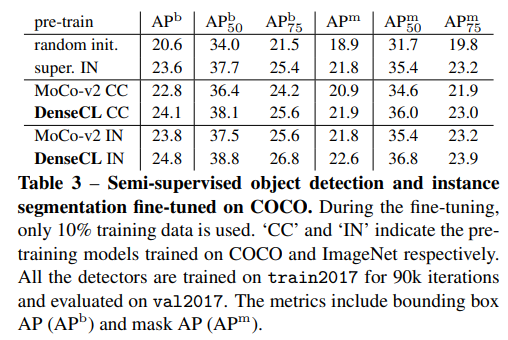
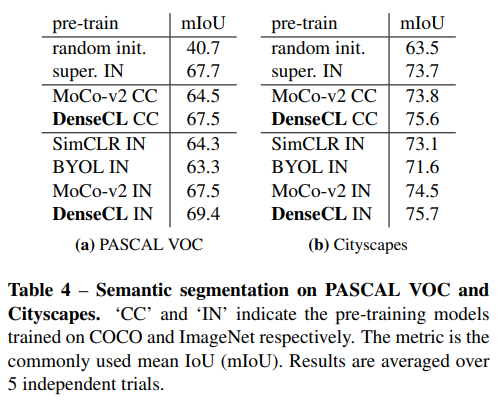
이렇게 학습한 모델은 dense prediction이 필요한 downstream task에 좋은 성능을 보인다. 심지어 supervision을 뛰어넘음
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
- 2021년 6월에 실린 논문
뇌신경과학자 Barlow가 주장한 가설에서 시작
"the goal of sensory processing is to recode highly redundant sensory inputs into a factorial code(a code with statistically independent components)"
(감각 처리의 목표는 매우 중복된 감각 입력을 요인 코드(통계적으로 독립적인 구성 요소를 가진 코드)로 재기록하는 것이다.)
한 데이터의 왜곡된 버전을 각각의 동일한 네트워크에 넣고, 결과값 사이의 cross-correlation을 측정해, 이를 최대한 identity matrix에 가깝게 만듦으로써 collapse를 피하게 하는 목적함수를 제안함.
==> 데이터의 왜곡된 버전의 임베딩 벡터를 유사하게 만들어서, 이러한 벡터들 요소 사이의 redundancy를 최소화! 이러한 방법을 BARLOW TWINS(BT)라고 함.
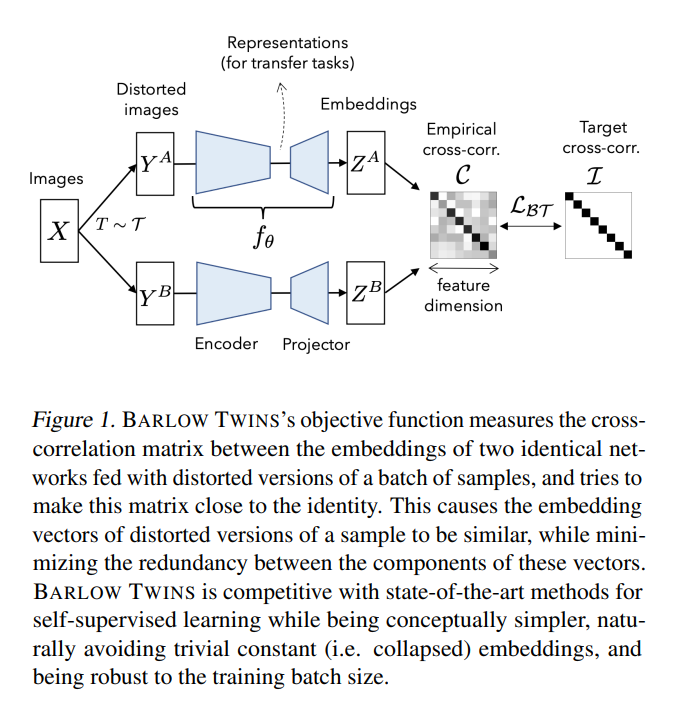
BT는 큰 배치를 필요로 하지 않을 뿐만 아니라(negative sample이 필요 없으니까) predictor network, gradient stopping 과 같은 network twins사이의 asymmetry도 없는게 특징.
- 매우 큰 고차원의 output vector에서 이점을 얻어 이전 준지도 분류보다 뛰어나고, 현재 SOTA인 linear classifier head를 가진 분류 모델 그리고 object detection과 분류의 전이학습 모델과 동등
Implements details

loss function

- C는 cross-corrleation matrix, 각각 element의 값은 -1에서 1사이
- b는 batch samples의 인덱스, i와 j는 네트워크 결과의 vector dimension
- 직관적으로 invariance term이 1과 동등하길 바라는 term. 즉, 왜곡이 생겨도 같은 데이터라면 같아야하는, invariance해야하는 값. 반대로 redundancy reduction term은 0이 되길 바라는 값으로, 다른 vector component와는 상관관계가 없길, non-redundant하길 바람.
Image augementations
각 입력 이미지는 다음과 같은 변형을 거침
: random cropping, resizing to 224X224, horisontal flipping, color jittering, converting to grayscale, Gasussian blurring, solarization.
처음 2개는 모두 적용, 나머지 5개는 랜덤하게 적용됨.
Architecture
- encoder는 ResNet-50 network(마지막 분류 레이어 없이, 2048 output units) + projector network로 구성
- proejector network는 3개의 linear layers로 구성, 각각 8192개의 output unit을 가짐. 앞에 2개 레이어는 batch normalization layer와 ReLU가 세트로 구성됨. encoder의 결과값을 "representation"이라 하고, projector의 결과값을 "embeddings"라 함. 각각 representation은 다운스트림 태스크에 사용되고 embeddings은 BT의 loss function으로 들어감.
Optimization
BYOL에 설명된 optimization protocol을 사용. LARS optimizer를 쓰고, 1000epoch, 2048 batch 사용
Experiments
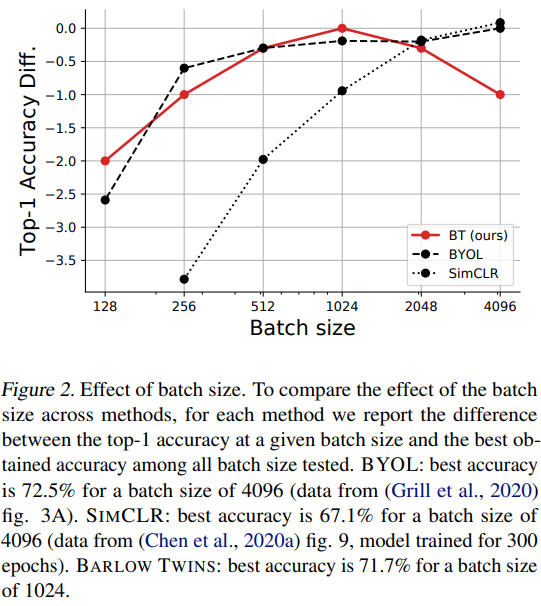
압도적으로 좋은 기록은 아니지만, 다른 SOTA모델에 준하는 퍼포먼스를 보여줌
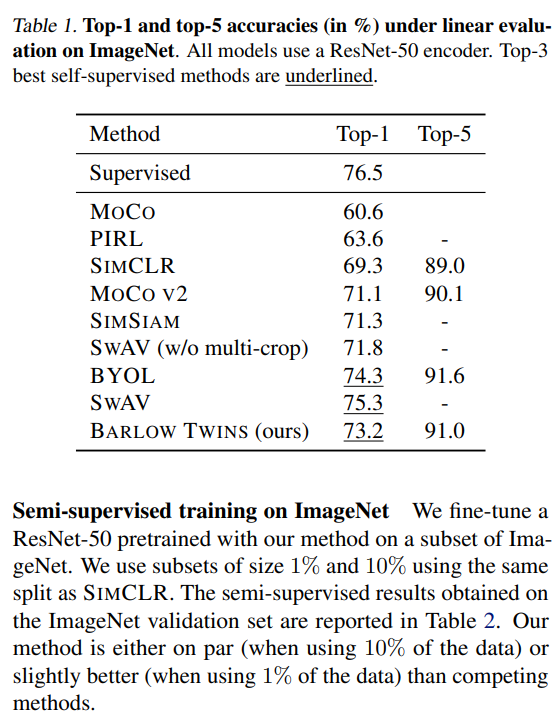
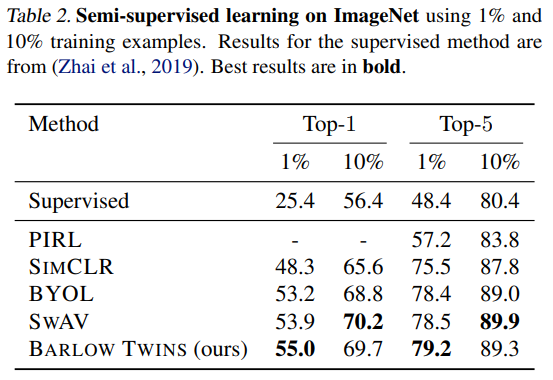
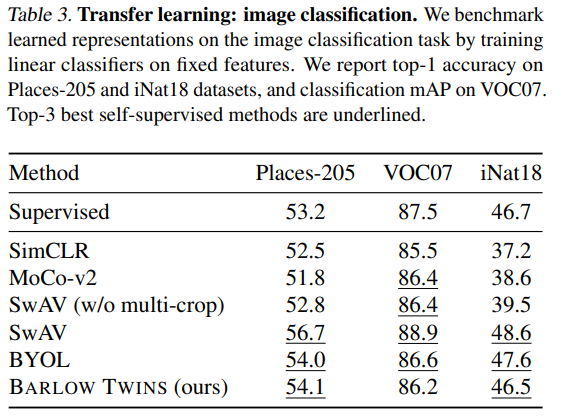
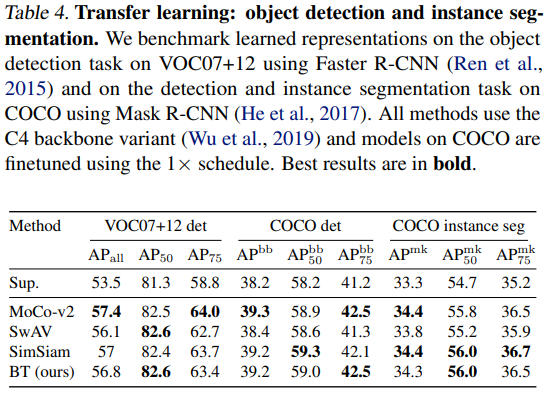
두드러지는건 배치가 작아도 어느정도 성능이 나온다는 것
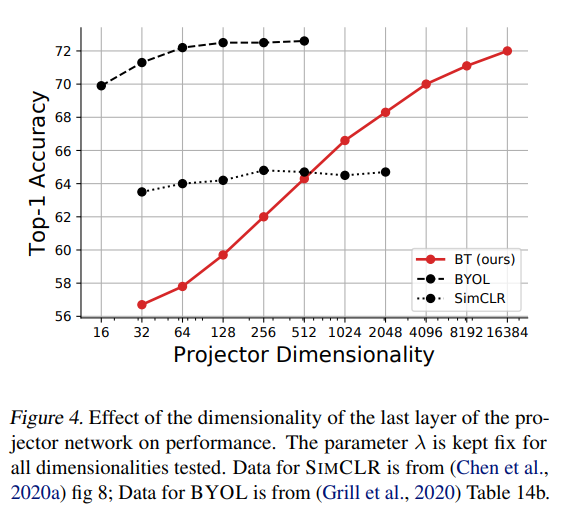
projector dimensionality를 높여가며 비교했을 때
An Empirical Study of Training Self-Supervised Vision Transformers(MoCo v3)
- 2021년 8월에 실린 논문
- MoCo기반의 framework + ViT
MoCo framework 개선
-
크게 2가지 측면에서 개선
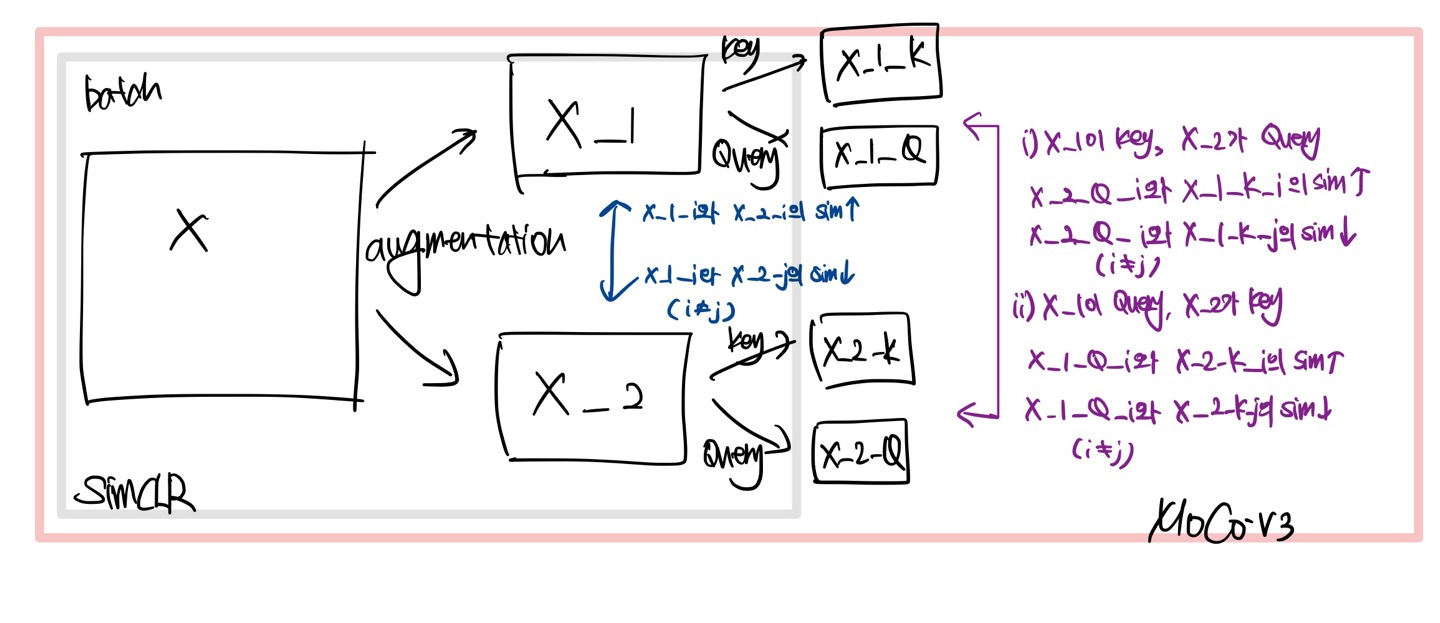

- 기존 MoCo기반 아이디어 중 하나인 queue구조의 dictionary를 없애고, SimCLR에서처럼 큰 batch size(=4096)를 사용해 batch내부의 다른 이미지들을 negative sample로 활용
- 기존의 projection head에 더해 prediction head를 추가하여 query encoder를 구성.
Query와 달리 key encoder는 prediction head를 넣어주지 않음.
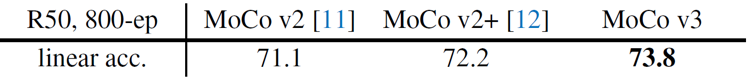
- 이 두 가지 개선사항으로 MoCo v3는 이전 버전과 비교해 1.6%의 linear envaluation 성능 향상을 보여줌.
이제 개선된 MoCo v3 framework에 Transformer기반 모델을 적용한 실험에 대해 알아보자!
Stability of Self-supervised ViT Training
MoCo v3을 ViT에 적용할 때, 학습의 instability 문제가 발생
- Batch에 따른 학습 곡선
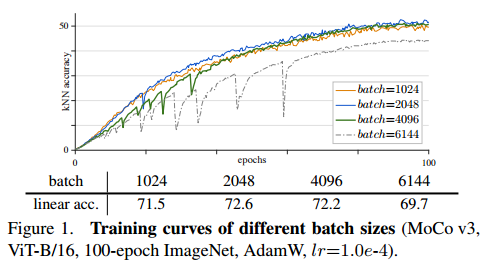
- 원래 contrastive learning기반 self-supervised learning은 batch를 키울수록, 더 많은 negative sample을 활용할 수 있어 성능에 도움이 되지만, ViT는 성능이 오히려 감소하는 것을 보임.
- batch=6144를 보면 불안정한 학습 곡선 + 성능 저하가 나타난다는 것을 알 수 있음
==> 이를 해결하기 위해 1가지 trick을 제안
- 학습률 및 최적화 기법에 따른 학습 곡선
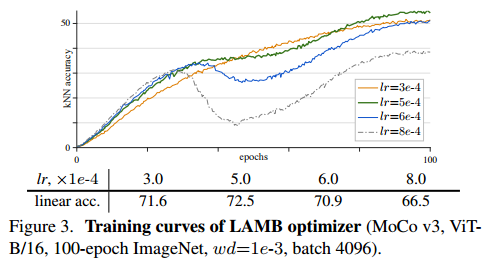
-
학습률이 작은 경우에 training이 더 stable하지만 under fitting됨.
-
학습률이 클 경우엔 less stable하고 정확도도 낮아짐
-
LAMB optimizer가 학습률에 더 민감. 그래서 해당 논문에선 AdaW를 사용해 실험 진행
A Trick for Improving Stability
그렇다면 왜 instability가 발생할까?
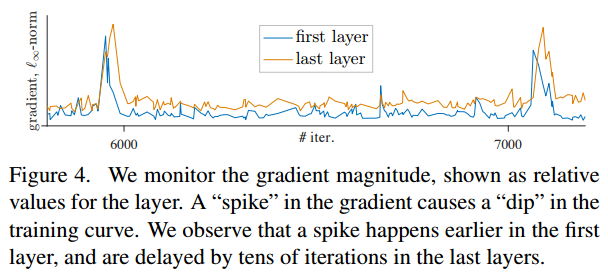
-
- 위 그림은 iter에 따른 gradient변화를 layer별로 보여주고 있음.
- 첫번째 레이어에 gradient spike가 발생하고 몇 epoch뒤에 last layer에도 gradient spike가 발생.
==> 이를 보고 저자는 instability가 shallower layer에서 발생한다 추측
==> 그래서 학습 동안 patch projection을 freezingPatch projection in ViT
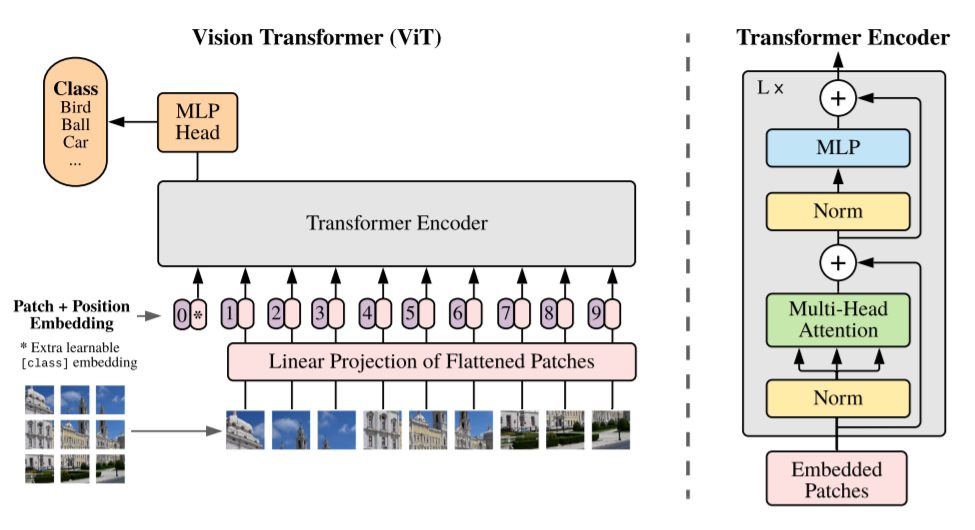
이 그림에서 밑단을 보면, 그림을 patch로 나눠서 embedding하게 된다. 이 때 patch 각각을 flatten해서 embedding matrix와 linear projection하게 되는데, 이 부분을 patch projection이라고 한다.
==> 즉, patch를 embedding하는 patch projection을 학습되지 않은 random patch projection으로 고정해 사용(stop-gradient로 간단히 구현 가능).
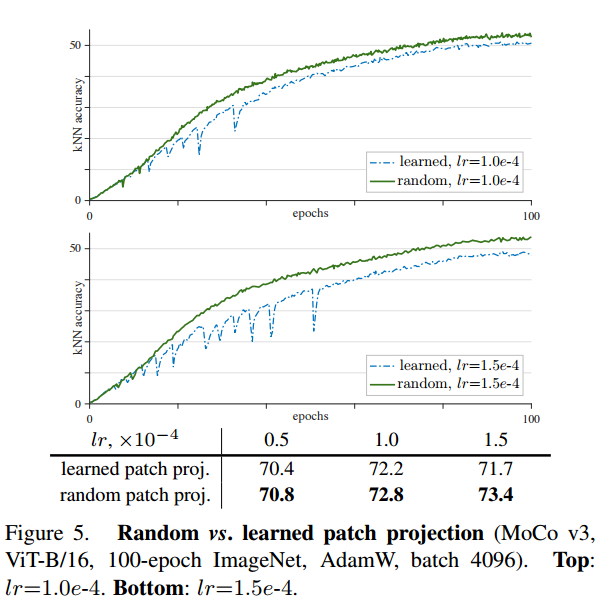
- random patch projection이 위의 초록색 선인데, 확실히 학습이 더 statbilize되고, 정확도도 향상되었다는 것을 알 수 있다.
- 이 random patch projection이 다른 self-supervised learning + ViT방법에도 효과적이라는 것을 보여줌
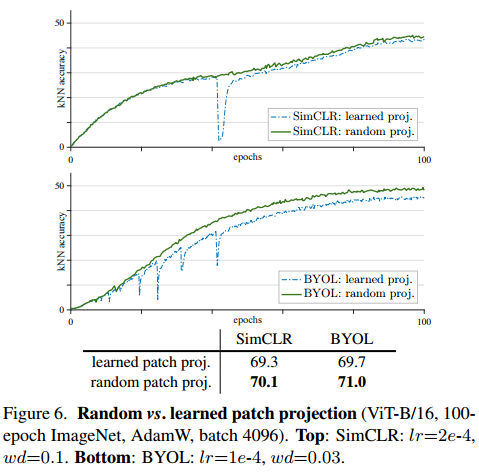
==> 저자는 이 실험을 통해 patch projection layer를 학습하는 것은 필수적이지 않다는 것을 보여줌. 기존 patch의 정보를 보존하기 위해 random projection이 충분하다!
Experiments
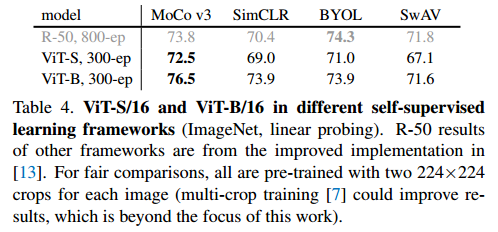
- ViT에 여러 self-supervised learning방법을 적용한 결과
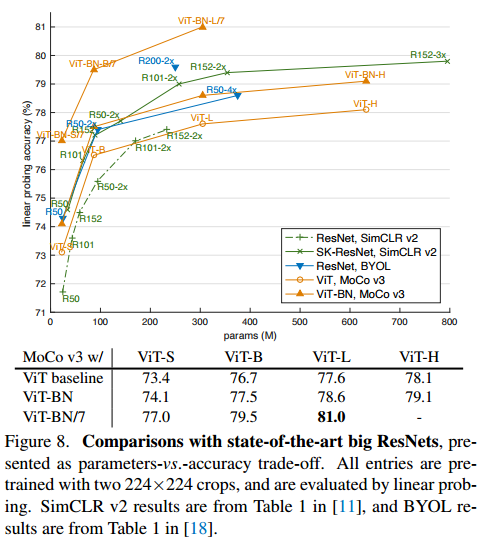
- SOTA 모델과의 비교
- transfer learning 결과

reference
https://deep-learning-study.tistory.com/746
https://ffighting.tistory.com/39
https://deep-learning-study.tistory.com/935
https://arxiv.org/pdf/2103.03230
https://arxiv.org/abs/2104.02057
https://arxiv.org/pdf/2011.09157
