
이번에 요약할 논문은 CNN의 깊이가 성능에 끼치는 영향을 연구한 논문인 Very Deep Convolutional Networks for Large-Scale Image Recognition입니다.
Link: arXiv - Very Deep Convolutional Networks for Large-Scale Image Recognition
Abstract 🍎
본 논문은 대규모 이미지 인식 환경에서 CNN의 깊이(depth)에 따른 정확도에 대해 연구한다.
매우 작은 3x3 convolutional 필터를 사용한 아키텍쳐에서 네트워크의 깊이를 증가시켰을 때의 평가를 중심으로, 해당 환경에서 16~19개의 layer로 깊이 만들어졌음에도 기존의 방법들보다 더 좋은 결과를 보인다.
이를 통하여 ImageNet Challenge 2014의 localization에서 1위, classification에서 2위를 달성했다.
또한 이 모델은 다른 데이터셋에 대해서도 준수한 성능을 보였다.
Introduction 🍏
대규모의 데이터셋, GPU와 같은 고성능의 계산 능력, 대규모 분산 cluster 덕분에 ConvNet은 이미지 인식분야에서 높은 성능을 보이고 있다.
이를 더욱 발전시키기 위해 더 작은 receptive window size와 첫 번째 Convolutional Layer에서 더 작은 stride를 사용해보는 등 다양한 시도가 존재한다.
본 논문에서는 ConvNet의 설계의 또 다른 관점인 깊이에 대해서 이야기한다.
ConvNet Configurations 🛠
Architecture 🧮
본 논문에서 제시되는 모델의 아키텍쳐는 다음과 같이 구성되어 있다.
- 학습시 입력은 224x224 RGB로 고정하며, 전처리는 RGB 평균값을 빼주는 것 외에는 하지 않는다.
- Convolutional Layer의 stride는 1로 고정이며, Convolutional 연산 후 해상도를 동일하게 유지하기 위해 spatial padding을 적용한다.
- Maxpooling Layer는 2x2 filter를 가지며, stride는 2로 총 5개가 적용된다.
- 모든 Hidden Layer에는 ReLU가 적용되며, 마지막 Fully-Connected Layer에는 softmax가 적용된다.
- Local Response Normalization(LRN)은 효과가 없고 계산량만 늘어나기에 사용하지 않는다.
Configurations 🔨
ConvNet의 구성은 다음 표와 같다.
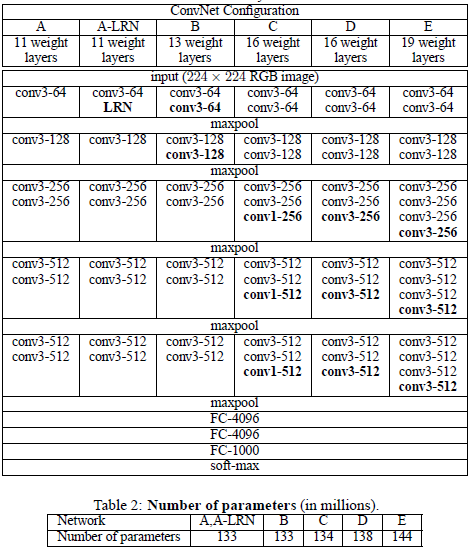
Source: Very Deep Convolutional Networks for Large-Scale Image Recognition
Discussion 🔮
3x3 Convolutional Layer를 세 개를 사용하는 건 7x7 Convolutional Layer를 사용하는 것과 같은데, 3x3 Convolutional Layer의 경우가 3개의 non-linear 층을 사용해 decision function이 더 discriminative해지고, 파라미터의 수가 더 적기에 효과적이다.
1x1 Convolutional Layer를 포함시키는 이유는 Convolutional Layer의 receptive filed를 건들지 않고도 decision function의 비선형성을 증가시키기 위함이다.
ILSVRC-2014의 classification부문에서 높은 성능을 보인 GooLeNet은 깊은 깊이와 작은 필터에 기반한 점으로 본 논문과 유사하다고 볼 수 있는데, 이는 CNN의 깊이가 깊어지면 성능이 좋아진다는 것을 보였다.
Classification Framework 🎰
Training 🏃♂️
훈련 과정은 Krizhevsky의 2012년 논문과 거의 동일하다.
- Batch Size: 256
- Momentum: 0.9
- L2 regularization : 5 x 10^-4
- Learning rate: 10^-2, valiation에 대한 accuracy 향상되지 않을 때마다 10배 감소시킴
- Weight decay: 5x10^-4
- Dropout: 0.5
파라미터의 잘못된 초기화는 성능에 영향을 줄 수 있기에, 이를 방지하고자 무작위로 초기화된 값으로 학습할 수 있는 얇은 모델을 학습시켰다.
학습시킨 후의 값을 더 깊은 모델의 Convolutional Layer를 초기화시켜줬다.
이외의 층은 평균이 0, 분산이 0.01인 정규분포를 사용해 초기화해주었다.
Conclusion 📒
본 논문의 결과를 당시의 SOTA와 비교한 표는 다음과 같다.
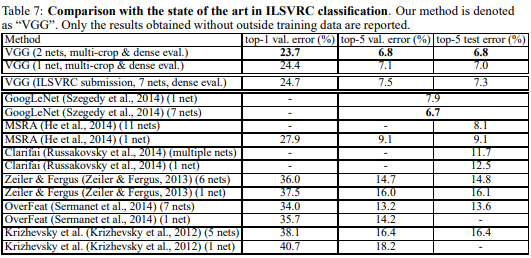
Source: Very Deep Convolutional Networks for Large-Scale Image Recognition
결론적으로 VGG-Net은 기존의 Convolutional 아키텍쳐보다 작은 receptive field 및 최대 19 깊이의 layer를 설계하여 좋은 성능을 만들었다고 볼 수 있다.
