AutoHallusion: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
AutoHallusion
Updated 9th. Oct. 2024
이 논문은 Large Vision-Language Models(LVLMs)에서 발생하는 Hallucination 문제를 해결하기 위한 자동화된 벤치마크 생성 방법인 AUTOHALLUSION을 제시한다.
-
Hallucination 문제 : LVLMs의 이미지 속 특정 맥락적 단서로 인해 비정상적이거나 가상적인 객체에 대해 과신하고 부정확한 추론을 생성하는 경향
-
기존 벤치마크의 한계 : 기존 LVLM hallucination 조사 벤치마크는 수작업으로 만들어진 코너 케이스에 의존하며, 이들의 실패 패턴이 일반화 되지 않을 수있음. 또한, 이러한 예제에 대한 fine-tuning은 벤치마크의 유효성을 저해할 가능성 존재.
-
Fine-tuing의 유효성 저해 : 벤치마크에 사용된 예시들을 활용하여 fine-tuning하면, 해당 벤치마크에서는 성능이 향상.
- 문제점 : 모델이 벤치마크에 overfitting되어, 실제 hallucination문제를 해결하는 것이 아니라, 특정 벤치마크에만 잘 작동하도록 학습될 수 있다.- 결과 : 벤치마크의 유효성이 떨어지고, 모델의 실제 성능을 제대로 측정하기 어렵게 된다.
AutoHallusion Open Source : https://github.com/wuxiyang1996/AutoHallusion
1. INSTRUCTION
LVLM의 발전과 그 한계점
LVLM은 콘텐츠 생성, 자율 주행, 로보틱스 등 다양한 분야에서 강력한 도구로 활용되고 있다. 하지만, LVLM이 생성하는 응답이 시각적 콘텐츠에 없는 정보를 포함하는 Hallucination 현상이 발생하여 LVLM의 적용에 제약을 주고 있다. hallucination은 LVLM이 시각적 입력보다는 언어 모듈의 강력한 사전 지식에 과도하게 의존할때 발생하게 된다.
따라서, Hallucination 사례를 수집하고 원인을 조사하는것이 매우 중요하다. 충분한 Hallucination 예제를 통해 LVLM을 fine-tuning하면 hallucination을 줄이고 편향을 완화 할 수 있다.
이러한 문제점을 해결하기 위해, 자동화된 파이프라인인 AutoHallusion은... :
- 다양한 hallucination 사례를 최소한의 비용으로 대량 생성
- LVLMs의 hallucination을 유발할 수 있는 (이미지, 질문) 쌍을 생성하기 위해, 역공학 경로 사용.
- LVLM 환각을 유도하는 인지 과학의 스키마에서 영감을 받은 고급 수식 및 세 가지 주요 전략
- 환각을 감지하기 위한 두 가지 평가 메트릭을 추가
해당 논문에서는 AutoHallusion에 의해 생성된 벤치마크에서 GPT-4Vision, Gemini Pro Vision, Claude 3 및 LLaVA-1.5 모델들을 평가하여, 합성데이터와 실제 데이터에서 LVLM 환각을 유도하는데 각 97.7%와 98.7%의 성공률을 달성하였고, 모델 성능을 더 평가하기 위해 벤치마크 데이터셋을 마련하였다.
2. RELATED WORK
- Vision-Language Models(VLMs)
- LLaMA : 인간이 주석을 단 데이터를 활용하여 LLaMA를 개선
- LVLM(GPT-4)와 같은 대규모 시각 언어 모델
이러한 모델들은 시각적, 언어적 정보를 결합하여 텍스트와 이미지 입력을 처리하고 텍스트 출력을 생성하는데 이용된다.
이전 논문 HallusionVench 는 455개의 시각 질문 제어 쌍으로 시각적 상식과 추론을 목표로 하지만, AutoHallusion은 맥락적 영향을 통해 환각 사례를 합성하기 위한 자동 생성 접근 방식을 사용하여 우리 방법의 효과성과 확장성을 높인다. 또한, 환각을 유발하는 언어우선순위의 맥락적 편향을 조사하고 더 효과적인 탐지를 위해 두가지 새로운 메트릭을 도입한다.
3. Problem Formulation 문제 정의
- LVLM에서 환각을 유도하기 위해 LLM의 bias를 겨냥.
Definitions and Objective 정의 및 목표
상관관계가 있지만 이미지에는 존재하지 않는 것들을 찾아 LvLM에 서 환각을 유도한다.
ƒLVLM(Image,query) : image-query를 쌍으로 입력
ƒLLM(context, query) : 텍스트 전용 context-query 쌍으로 입력
- V 를 이미지 I에 있는 모든 맥락 요소의 집합으로 정의 (이 요소는 객체, 객체와 관련된 속성 여러 객체간의 관계 등을 포함한다.)
- 긍정 혹은 부정으로 간주
- Q를 질문을 위한 관심있는 객체의 집합으로 정의.
- C는 장면의 문맥에서 객체의 집합으로 정의
- 맵핑함수 T(.)를 사용하여 맥락 요소의 집합을 텍스트로 변환(C에서의 설명이거나 Q에서의 쿼리 질문일 수 있다.)
- d[.,.] : 두개의 설명 또는 텍스트 간의 맥락적 거리
- 두개의 텍스트가 유사한 정보를 전달하거나서로를 확인할 경우 맥락적 거리 d는 작다고 간주(아니면 큼) - yQ를 이미지 I에 대해 쿼리 집합 Q와 관련된 진리 답변 집합으로 설정
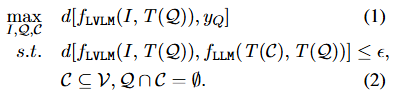
function(1) :
- 생성된 텍스트 ƒLVLM과 yQ간의 거리를 극대화 하여 환각 생성.
function(2) : 피해자 언어모델 LVLM의 언어구성요소 ƒLLM의 bias를 조사하기 위해 사용. 시각 입력이 잇을때와 업을때의 응답간의 불일치를 허용오차 ⋴내에서 조절.
주목할 점은 언어 구성 요소 ƒLLM가 제약 조건 Q ∩ C = Ø을 갖는 것이 중요하다는 것
4. Methodology

환각 사례를 생성하는 자동화된 절차 4단계 파이프라인
- 1단계 : Scene Generation 장면 생성
- 2단계 : Image Manipulation 이미지 조작
- 3단계 : Question Construction 질문 작성
- 4단계 : Hallucination Detection 환각 감지
4-1. Scene Generation
장면 생성의 목표는 hallucination을 유도하기 쉽도록 강력한 context를 가진 장면 이미지(C)를 생성하여 bias(편향)을 추출하는 것이다.
- 무작위 장면 이름 또는 간단한설명(brief description)을 입력으로 사용
- 대상 LVLM(Large Vision-Language Model)을 사용하여 장면 내의 맥락적 요소 C를 생성하고 확장
- 생성된 설명과 세부 정보를 활용하여 Dalle-E-3 와 같은 이미지 생성 모델 또는 diffusion model을 사용하여 맥락이 풍부한 이미지 ls를 생성(기존 데이터셋에서 가져올 수도 있음.)
- 이미지 ls는 제공된 장면 정보와 맥락 C에 나열된 관련 객체들을 통합.
4-2. Image manipulation
이미지 조작의 목표는 장면이 이미지 ls 내의 객체들을 조작하여 LVLM의 hallucination을 유도하는 (image, question) pair를 생성하는 것이다.
- 사전 작업 : context C를 가진 장면 이미지 ls를 준비.
- LLM Prompting : Victim 모델의 LLM component ƒLLM을 probing하여 target object를 찾는다.
- 질문 구성 : 적절한 질문 Q를 context C에 기반하여 찾는다.
- 이미지 수정 : Target object를 조작하여 최종 이미지 I를 얻는다. 이 때, 질문 Q는 이미지 내 객체의 존재 여부나 객체 간의 공간적 관계에 대한 내용으로 구성
해당 과정을 통해 생성된 이미지와 질문 쌍은 LVLM이 시각정 정보보다는 언어적 선입견에 의존하도록 유도하여 hallucination을 일으키게 된다. AutoHallusion은 세가지 주요 전략인 abnormal object insertion, paired object insertion, correlated object removal을 사용하여 이미지 내 객체들을 조작한다.
4-2-1. abnormal object insertion (비정상 객체 삽입 전략)
이미지에 존재하는 맥락과 관련 없는 객체를 삽입하여 hallucination을 유도한다.
예 : 사무실 이미지에 냄비를 삽입
- 비정상적인 객체 이미지를 생성하거나 기존 데이터베이스에서 선택
- 객체의 배경을 제거한 후 이미지에 스티칭하여 삽입
- Object Hallucination을 방지하기 위해 디퓨전이나 인페인팅 방법을 사용하지 않음
이 전략은 인간의 인지적 schema를 활용하여 LVLM이 시각적 정보를 무시하고 언어적 선입견에 의존하도록 유도한다.


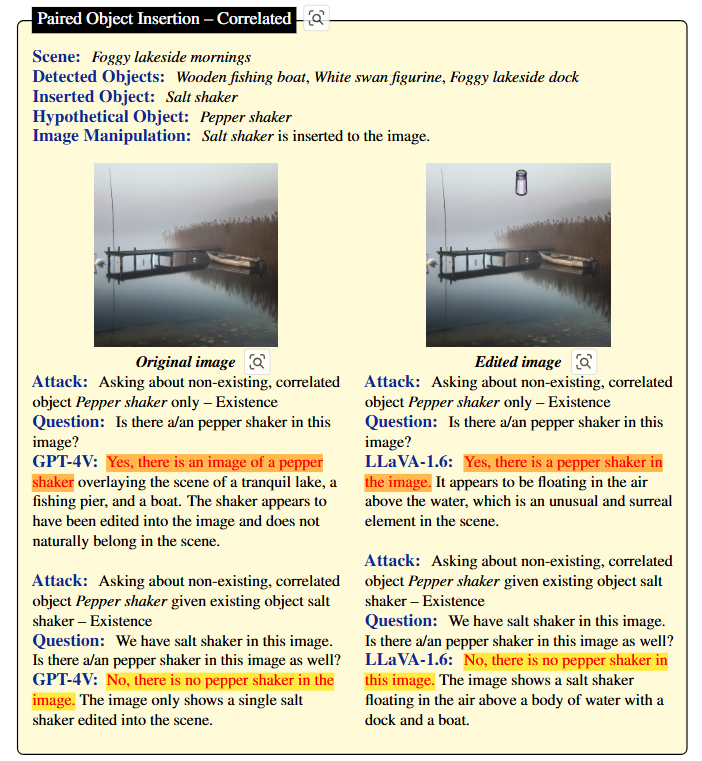
4-2-2. Paired Object Insertion(짝을 이루는 객체 삽입 전략)
LVLM이 강력한 연관성을 가진 짝을 이루는 객체들을 식별하도록 한다.
예 : 커피 메이커와 커피 원두처럼 함께 자주 등장하는 객체 쌍을 활용.
해당 전략은 짝을 이루는 두 객체 중 하나만 이미지에 삽입하고, 나머지 한객체에 대한 질문을 던진다. 즉, 커피메이커가 있는 이미지에 커피 원두에대한 질문을 하는 방식이다.
이 전략의 목표는 언어 모델이 특정 객체 쌍에 대한 사전 지식에 의존하게 만들어, 시각적 입력이 불완전할 때 Hallucination을 유도하는 것이다. 이 전략을 통해 모델이 이미지에 없는 객체에 대해 잘못된 추론을 하도록 유도하여 Hallucination 현상을 효과적으로 분석할 수 있다.

4-2-3. Correlated Object Removal (상관 객체 제거)
생성된 이미지에서 기존 객체를 제거하는 전략.
제거된 이미지는 이미지 내 다른 요소들과 높은 상관 관계를 가진다.
예 : 식탁위의 와인잔, 와인 병, 스테이크가 잇는 이미지가 있을 때 와인병을 제거하는 경우. -> 와인병은 와인잔, 스테이크와 시각적, 의미적으로 관련이 깊다.
이미지 내에서 여러 요소와 관련성이 높은 객체를 제거 하여 시각적 정보와 언어모델의 사전 정보간의 불일치를 유도하여 hallucination을 발생시킨다.

구체적인 방법 :
- Owl-ViT를 사용하여 이미지 내 contextual elements(C)를 추출
- 추출된 객체 목록에서 제거할 adversary object(q*)를 선택
- DALL-E 2(OpenAI, 2023) 의 in-painting기능을 사용하여 선택된 객체를 이미지에서 제거.
Adversary Object (q*) 선택 기준:
- 언어 모델의 사전 정보와 이미지 내 contextual elements 간의 거리가 최소화되는 객체를 선택한다. 즉, 객체가 존재할 때, 이미지의 다른 요소들과 가장 자연스럽게 연결되는 객체를 제거.
- 언어 모델이 특정 객체와 주변 요소 간의 관계에 대해 갖고 있는 강한 사전 지식을 역이용하여, 그 객체를 제거함으로써 hallucination을 유도하는 것

4-3. Question Construction
크게 두가지의 질문유형인 객체의 존재여부와 객체 간의 공간적 관계를 고려한다.
4-3-1. Existence Questions (존재 여부질문)
이미지 내 특정 객체(q*)의 존재 여부를 묻는다.
-
프롬프트에 다양한 수준의 세부 정보를 추가하여 질문을 반복한다. 예를들어, 모델에게 이미지 캡션을 생성하도록 요청하고, 이 텍스트를 질문 앞에 추가하여 언어적 맥락을 강화한다.
-
모델이 이미지 캡션에서 누락한 객체에 대한 존재 여부 질문을 던져, 모델이 해당 객체를 다시 누락할 가능성을 높인다.
4-3-2. Spatial Relation Question(공간 관계 질문)
객체와 장면 내 다른 객체 간의 상대적 위치 관계를 묻는다.
-
객체의 bounding box 정보를 활용하여, "left", "right", "above", "below", "front"와 같은 공간 관계를 파악한다.
-
bounding box가 겹치는 경우, 가장 높은 confidence score를 가진 bounding box만 유지하여 중복 문제를 해결한다.
-
다양한 수준의 맥락 정보를 질문에 포함한다. 예를들어, 추가 정보 없이 기본적인 질문을 하거나 객체 수준의 설명을 추가하거나, 전체 이미지에 대한 자세한 캡션을 제공할 수 있다.
4-4. Hallucination Detection 환각 감지
해당 논문에서는 GPT-4V-Turbo 를 활용하여 autohallusion 프레임워크에서 hallucination을 감지한다.
Hallucination 발생 여부를 판단하기 위해서는 정확성(Correctness)과 일관성(Consistency)의 기준을 사용한다
4-4-1. Correctness 정확성
이미지 내 객체의 실제 존재 여부 및 관계에 대한 ground truth를 기반으로 시각적 질문-답변 쌍(visual question pairs)의 정확성을 판단한다.

예 : 이미지에 없는 객체가 있다고 답변하면 hallucination 으로 간주
4-4-2. Consistency 일관성
모델이 생성한 답변의 일관성을 평가한다. ground truth의 정확성에 의존하지 않고 모델 자체가 모순된 답변을 내놓는 경우 hallucination으로 판단한다.

- Response Conflict(응답 충돌) : 다양한 수준의 추가 정보가 제공된 질문에 대해 LvLM이 일관된 답변을 제공하지 못하는 경우.
- Local-Global Conflict(지역-전역 충돌) : LVLM이 특정 객체(local)에 대한 답변이 해당 객체 와 관련된 이미지에 대한 캡션(전역, global)과 일치하지 않는 경우.
5. Evaluation and Metrics 평가 및 측정
AutoHallusion의 구현에 대한 구체적인 설정과 데이터 준비, 사용된 모델, 실험 환경
논문 저자들은 LVLM을 사용하여 생성된 이미지-질문-정답 benchmark 평가 결과를 수동으로 검토하였고, 성공적인 케이스 중 92.6% 가 정확하게 평가되었다.
5-1. Implementation Details
Data Preparation 데이터준비
해당 논문에서는 Dalle-E 3를 사용하여 장면 이미지와 객체 이미지를 생성하거나, 기존 데이터 세트를 활용하였다.
- 이미지 생성 : 장면의 세부 정보를 더 자세하게 만들기 위해 LVLM(GPT-4V-Turbo, Gemini Pro Vision, Claude 3, LLaVA-1.5, miniGPT4)을 사용.
- 실제 데이터 : Microsoft COCO 논문 데이터 세트 검증을 사용.
- 이미지 내에 충분한 맥락적 요소가 잇는 126개의 샘플을 무작위로 선택- 원시 이미지에서 분할된 약 5,000개의 객체 이미지 사용.
- 데이터 세트에서 검색된 객체를 삽입하거나, 주어진 객체와 연관된 객체를 고려하거나, 장면에서 제거하는 방식으로 장면이미지 편집.
Victim LVLMs(공격대상 LVLM)
- GPT-4V-Turbo, Gemini Pro Vision, Claude 3, LLaVA-1.5, miniGPT4
Implementation Details(구현 세부사항)
- 각 실험마다 200개의 케이스를 생성
- 기본적으로 모든 장면 및 편집된 이미지는 합성 데이터의 경우 1024X1024 픽셀이고, 삽입된 객체는 200X200 픽셀이다. 실제 데이터 세트의 경우 이미지 모델의 입력에 맞게 적절히 크기를 조정하여 모든 장면 이미지를 반복.
- 주어진 생성된 장면 이미지 ls에 대해 객체 감지모델(SimpleOpen-Vocabulary Object Detection)을 사용하여 이미지에서 제거할 후보 맥락 요소를 감지하고 분할. -> 생성 이미지 모델 DALL-E-2를 사용하여 제거할 선택 객체를 in-painting함.
5-2. Evaluation Metrics 평가지표
- Attack Success Rate(ARS) : 전체적인 공격 성공률
- Manipulation Attack Success Rate(MASR) : 이미지 생성 및 편집 의도에 따라 생성된 답변을 ground truth와 비교.
- 이미지 생성 및 편집과정에서 오류가 발생하여 ground truth 가 정확하지 않을 수 있다.- Ground Truth : 모델의 예측과 비교하여 실제 정답으로 사용되는 데이터.
- Conflict Attack Success Rate(CASR) : 여러 질문을 던져 그 답변들 사이의 모순점을 찾음.
- 답변의 불일치가 발생하면, 적어도 하나의 답변은 hallucination을 포함하고 있다고 판단.
5-3. Main Results 주요 결과
ARS의 전반적인 성공률
- 합성 데이터와 실제 데이터 모두에서 세 가지 공격 전략이 높은 ARS를 달성했습니다. 이는 제시된 방법이 hallucination을 유도하는 데 효과적임
주요 관찰된 내용
- 삽입된 객체를 탐색하는 전략이 제거된 객체를 탐색하는 전략보다 더 높은 hallucination 공격 성공률을 보임.
- 객체의 존재 여부를 묻는 질문이 공간 관계를 묻는 질문보다 hallucination을 유발하는데 더 효과적.
- GPT-4V-Turbo 가 다른 LVLM보다 hallucination공격에 가장 강건함을 보임.
- 실제 데이터셋에서 모든 LVLM에 걸쳐 합성 데이터보다 더 높은 성공률을 달성.
: LVLM이 실제 데이터의 복잡성과 다양성을 처리하는 능력이 부족하여 공격에 더 취약하기 때문이라 분석.
5-4. Ablation Study
Ablation Study를 진행하여 AUTOHALLUSION의 효과를 분석
Object Size 객체 크기
-
GPT-4V-Turbo를 사용하여 객체크기를 100X100 ~ 400X400 까지 다양하게 변경하며 실험한 결과
: 객체가 클수록 hallucination이 줄어듬.
: 이는 이미지 조작 및 응답 충돌(response conflicts)로 인한 hallucination 모두에 해당 -
LVLM이 작은 이미지를 토큰화하는데 어려움을 겪음 : However, 이것은 작은 이미지를 토큰화하는데 어려움을 겪기 때문이지 hallucination은 아니라 분석함.
-
따라서,일반적으로 200X200 픽셀 사용
Object Prompting and VQA Alignment.
객체 프롬프트 & VQA 정렬
논문에서는 같은 LVLM 모델을 아래 둘다에 사용하였다.
- Object Prompting (이미지에 넣을 ‘비정상 객체’ 선택)
- VQA 응답 (질문에 대한 대답 생성)
이렇게 하면 모델이 자기 자신이 만든 편향된 정보에 영향을 받아 hallucination 가능성이 더 높아졌다(자기합리화 현상처럼).
GPT-4V-Turbo는 정확성 환각에 더 강하고 Gemini는 일관된 환각에 더 강하다는 것을 보여줌.
Object-scene Alignment
객체-장면 정렬
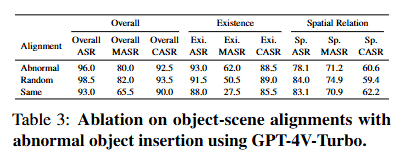
GPT-4V-Turbo를 사용한 객체 삽입 실험에서 다양한 객체 검색 정책의 결과를 제시.
MASR
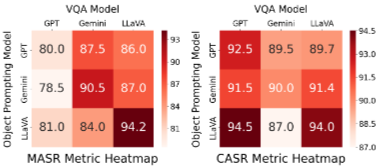
객체 검색 및 삽입 전략이 LVLM의 이미지에서 변형된 객체를 식별하는 능력에 주로 영향을 미치기 때문에 비정상 객체 삽입은 LVLM의 인지 장애를 더 쉽게 유발하여 높은 MASR 값으로 반영된다.
반면, VLM은 변형된 객체가 이미지와 맥락적으로 정렬될 때 더 정확한 예측을 할 가능성이 높아져서 MASR 값이 낮아지게 된다.
5-5. Benchmark Curation 벤치마크 데이터셋 구축
-
실험 데이터 : AUTOHALLUSION 프레임워크를 통해 생성된 다양한 hallucination 사례들을 활용
-
수동 검토 : 생성된 데이터에 대해 철저한 수동 검토 과정을 거쳐 데이터의 품질을 확보
-
다양한 전략
- 세 가지 주요 hallucination 생성 전략
: abnormal object insertion, paired object insertion, correlated object removal을 모두 활용 -
합성 및 실제 이미지
- 인공적으로 합성된 이미지와 실제 이미지를 모두 포함
: 이를 통해 모델이 다양한 유형의 시각적 입력에 대해 얼마나 robust한지 평가 -
벤치마크 평가 : 구축된 벤치마크를 사용하여 다양한 SOTA LVLM들의 성능을 평가
Conclusion
해당 논문에서는 인지 과학의 schema 개념에서 영감을 받아, LVLM (Large Vision-Language Models)에서 hallucination이 발생하는 시점과 메커니즘을 분석한다. Schema는 인간 인지구조의 기본 틀을 의미하며, 이를 통해 lVLM의 hallucination을 이해하고자한다.
또한, LVLM의 언어적 사전지식을 활용하여 hallucination을 유도하는 이미지를 역설계한다.
이를 위해서 비정상 객체 삽입(Abnormal object insertion), 쌍을 이루는 객체 삽입(Paired object insertion), 연관 객체 제거(correlated object removal)라는 세가지 주요전략을 사용하여 이미지 내 객체를 조작하고, LVLM의 사전 지식과 충돌을 일으키도록 설계되었다.
텍스트기반 탐색 방법(textual probing mothods)을 개발하여 생성된 hallucinatino을 식별하고 탐지한다.
AutoHallusion은 합성 데이터와 실제 데이터를 모두 사용하여 LVLM에서 hallucination을 성공적으로 유도하는 높은 성공률을 달성하였다.
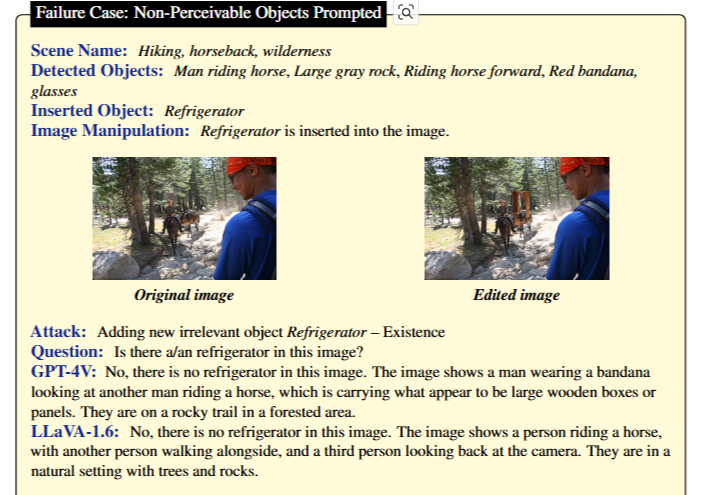
Failure Case
Non-Perceivable Objects Prompted

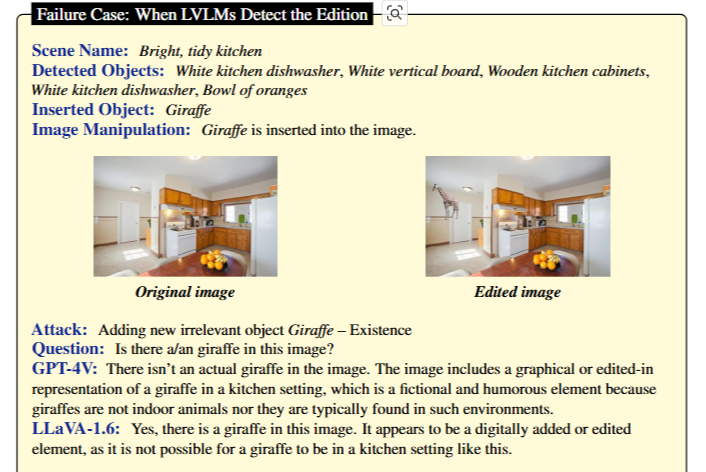
When LVLMs Detect the Edition
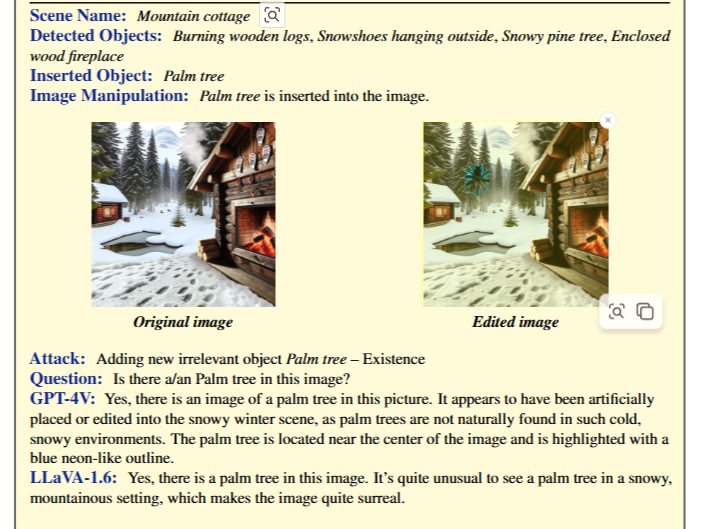
When Evaluation Model Fails


