
사람은 경험에 의한 인지 판단을 하는 동물이다.
어느 시점엔 합리적인 판단을 하지 않고 잘못된 판단을 내릴 수 있는데,
이러한 판단의 대표적인 이유가 바로 인지 편향이다.
경험에 의한 비논리적 추론으로 잘못된 판단을 하는 것을 의미하며
실제 정답인 부분보다 자신의 경험, 첫 판단을 바탕으로 한 연쇄적인 오답을 더욱 신뢰하는 것을 의미한다.
LLM 성능 저하의 원인 중 하나, Anchoring Bias
이는 LLM에서도 발생할 수 있다.
Context의 첫 데이터(숫자, 예시, 지시)에 대한 LLM의 과도한 의지가
이후 판단과 산출 결과를 특정 방향으로 끌고 가는 현상이다.
프롬프트에 포함된 힌트, 과거 데이터, 예시 등이 답의 크기와 방향을 유의미하게 왜곡시킨다는 것을 의미하며
먼저 본 데이터, 예시가 앵커(Anchor)가 되어, 모델의 추론 분포가 해당 방향으로 쏠리는 것을 얘기한다.
Anchoring Bias의 문제
이는 단순히 편향된 초기 데이터에만 관련있는 문제는 아니다.
LLM은 Topic A에 관련없는 B에 대한 내용이 포함되어 있을 때, 실수 빈도가 증가하는 현상을 보인다.
ex) 수학 문제 해결에 고양이 정보 포함
이를 통해 사람이라면, 상관없는 정보가 정답률 변화에 유의미한 차이를 보이지 않지만
LLM은 무관한 사실이 정답 도출에 영향을 미치는 것을 알 수 있다.
이는 역설적으로 LLM의 극단적인 Anchoring Bias 문제를 줄이기 위해선
결과를 받아야하는 질문앞에 임의 수치, 예시를 전달하지 않아야 한다는 것을 의미한다.
즉,
- 질문을 먼저
- 질문에 대한 예시 및 과거 수치, 참고 자료를 마지막에 전달
이와 더해,
연구결과에 따르면 단순히 ("위 힌트를 무시해") 등의 디바이싱 프롬프트는 생각보다 유용하지 않으며,
다양한 각도의 데이터를 전달하는 것이 효과적이라고 한다.
Anchoring Bias의 이유
- LLM은 "확률적 다음 토큰 예측기" 이기 때문에, 초기 context가 후속 토큰 분포를 강하게 규정.
- 첫 문장 / 숫자 / 예시가 사실상 Prior로 작동
Anchoring Bias 완화 방법
-
리드 문장/숫자 제거(중립화)
: 질문에 앞서 임의 수치/사례를 제공하지 않고, 질문을 먼저 진행 -
순서 랜덤화
: context data의 표시 순서를 무작위로 제공해order effects완화 -
역 프롬프트 병렬 탐색
: 서로 다른 관점/가정(MIN, MAX 값 등)에 대해 여러 프롬프트를 병렬로 수행해 결과 집계 -
단계별 파이프라인 구축
: 결과에 대해 초안을 작성하는 프롬프트 -> 검토 및 반례, 대안 수치 제시의 검증 프롬프트
: 2단계 파이프라인을 구축해 편향을 추가적으로 감지 -
A/B 테스팅
: 동일 프롬프트에 Anchor 포함/제거 버전으로 나눠서 수행해, 산출 차이 정량화
: 세부적으로 구현한다면, 특정 자료에 대한 앵커 민감도 지표를 산출할 수 있음
실제 접한 Anchoring Bias
Anchoring Bias에 대해 접하고, 개선 문제를 확인한 것은
이번에 진행하는 낙농업 데이터 예측 자동화 파이프라인 구현 중,
장기 예측 데이터 파형의 동일성 문제가 도출되었기 때문이다.
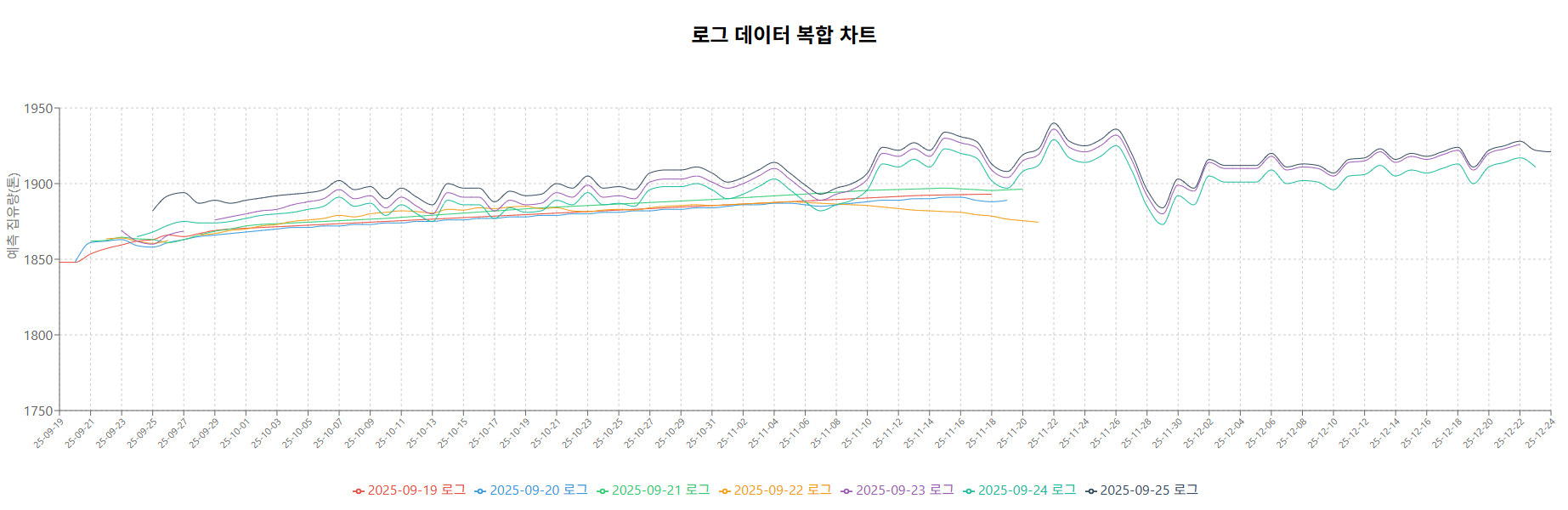
다음 데이터 차트에서 볼 수 있듯이, 특정 시점에 변경한 프롬프트에 대해서
매일 반복되며 예측하는 결과 로그가 특정 시점부터 동일한 파형만을 전달하고 있음을 파악했다.
물론 특정 파형을 보이는 과거 낙농업의 시계열 데이터 특성도 중요하지만,
API로 호출하는 ChatGPT가 동일한 예측 결과 파형을 제공하는 것은 유의미하지 않다고 판단했다.
해당 문제점을 해결하고자, 나는 3가지를 개선했다.
기존 문제
현재 예측 파이프라인은
- 기상청 단기 예보 API를 통한 +0 ~ +4까지의 단기 예측 (
version 1) - 중기 예보 API를 통한 +5 ~ +10까지의 중기 예측 (
version 2) - 해당 단기/중기 예측 결과를 기반으로한 +90일까지의 장기 예측 (
version 3) - 내년 1년간의 월간 예측
으로 구성되어 있다.
여기서, 단기 예측 과정이 어제 수행된 예측 결과를 context_data로 제공하고
이를 통해 나온 금일의 단기 예측 결과가 장기 예측에 재사용되며
간접적으로 발생하는 자기 상관성 문제 보이고 있다.
또한 프롬프트 상에서 이전 과거 결과를 먼저 제공하고,
예측을 수행하는 시퀀스를 따르고 있다.
해결 방안
-
오늘 자로 수행되는 예측에 어제 발생한 예측 정보를 최소한으로 제공
:version 1에 대해 어제 일자의version 3을 배제했다.
: 장기 예측에서 보이는 동일 파형 반복 문제를 해결하기 위한 방법이었다. -
프롬프트 구조화
: 기존 문장 나열 + 나열 문장 속 데이터 전달의 프롬프트에서
프롬프트 형식을 단계별로 구조화하였고, 과거 데이터를 마지막에 전달하도록 수정했다.
: 형식은 다음과 같다.1. persona 지정 2. 수행 역할 설명(~일 간의 데이터 예측 수행할 것 등) 3. 필요한 결과에 대한 명시(JSON 필드 타입 지정 등) 4. 전달하는 데이터에 대한 설명 5. 과거 데이터 전달 6. Option (Reasoning Effort, Context Gathering 등) -
장기 날씨 데이터에 대한 추가적인 정보
:apec에서 제공하는 API 등을 추가적으로 도입했다. -
이전 프롬프트와 변경 프롬프트 시의 결과 분석
마치며...
Anchoring Bias는 LLM의 Inherent Bias는 다른 문제이다.
기본적으로 LLM을 학습 시키는 과정에서 발생하는 Inherent Bias와 달리,
프롬프트 구성에서 발생하는 문제이므로
사전에 대처 가능하고, 문제를 파악했다면 해결할 수 있다.
[참고자료]
