
자료구조
-
Array를 적용시키면 좋을 데이터의 예를 구체적으로 들어주세요. 구체적 예시와 함께 Array를 적용하면 좋은 이유, 그리고 Array를 사용하지 않으면 어떻게 되는지 함께 설명해주세요.
어레이는순차적으로 데이터를 저장해서 인덱스를 사용한 빠른 검색이 가능하며 데이터의 삽입/삭제는 비교적 느린 자료구조입니다. 어레이를 적용하기 좋은 대표적인 예는 주식차트가 있습니다. 주식차트는 날짜별로 주가가 저장되어야하지만 삽입이나 삭제는 발생하지 않으므로 어레이를 사용하면 효율적으로 데이터를 저장할 수 있습니다. 어레이를 사용하지 않고 순서가 없는 자료구조를 사용한다면저장되어있는 자료를 빠르게 찾기가 어려워효율적인 조회가 불가능합니다. -
Stack과 Queue의 실사용 예를 들어 간단히 설명해주세요.
스택은 단방향 자료구조로 가장 늦게 저장된 데이터를 가장 먼저 꺼내쓸 수 있습니다. 이런 특징을 사용한 실례는 브라우저에서 뒤로가기, 문서 작업에서 ctrl+z등이 있습니다. 큐는 양방향 자료구조로 먼저 저장된 데이터가 먼저 쓰입니다. 실례로는 OS의 CPU스케쥴링, 인쇄 대기열 등이 있습니다.
+BFS(큐) -
해시 테이블(Hash Table)과 시간 복잡도에 대해 설명해주세요
해시테이블은 딕셔너리 형태로 데이터를 저장하는 자료구조입니다. 해시테이블의 인덱스는 키값을 해싱한 값이고 이 인덱스를 사용해서 대응되는 밸류값을 찾습니다.
내부적으로 배열을 사용하여 데이터를 저장하기때문에 인덱스를 통한 랜덤엑세스가 가능하여 데이터 조회에 O(1)의 시간복잡도를 가집니다.
✔️인덱스 충돌(해시충돌)이 일어날 경우 뭐있었지 - 체이닝, 개방주소법으로 해결
✔️버킷이 array라고 보면 되나 - 맞는거같음
버킷 안에 하나 이상의 슬롯이 있음 - 실제 데이터가 저장되는 공간
- 자바에서는 seperate chaining으로 충돌을 해결함
해시 충돌시 슬롯이 더 필요해지기때문에 여분의 슬롯을 둠
슬롯은 링크드리스트(일정 갯수를 초과하면 트리노드형태로 전환)
- Hash Map과 Hash Table의 차이점에 대해 설명해주세요.
파이썬에서는 둘의 차이가 없지만 자바에서는 차이가 있습니다.
자바에서해시맵과 해시테이블은 스레드 관점에서 안전성에 차이가 있어 실행환경에 따라 구분하여 사용합니다.
해시테이블은 동기화를 지원하여 멀티스레드 환경에서 병럴처리가 되어 안전하게 사용할 수 있지만 해시맵은 동기화를 지원하지 않아 해시테이블보다 멀티스레드 환경에서 안전하지 않지만 싱글스레드에서는 더 빠른 검색이 가능합니다.
+해시테이블은 키값에 널을 허용하지 않고 맵은 허용함
공통
해싱으로 키를 인덱스로 만들어 검색속도가 빠름
해시테이블 vs 해시맵
⚡해시 테이블
thread-safe
Hashtable의 모든 Data 변경 메소드는 syncronized로 선언되어 있다. 즉 메소드 호출 전 스레드간 동기화 락을 통해 멀티 쓰레드 환경에서 data의 무결성을 보장해준다.
동기화 처리를 하기때문에 해시맵보다 느리다
⚡해시맵
thread-unsafe
멀티스레드의 경우 스레드에 동시 접근함(동기화 지원x)
보조해시를 사용해서 충돌 발생률이 적음 (자바)
해시맵은 키와 밸류에 널값을 저장할 수 있다
순서가 없고 buckets(버킷 어레이)에 값을 분산 저장
저장은 느리지만 다량의 데이터 검색에 용이
- http://nnoco.tistory.com/73 → 입력시간이 다른기능보다 느림
키밸류 쌍의 수에 따라 동적으로 크기가 변화하는 associate array
- associate array == map, dictionary, symbol table
https://reakwon.tistory.com/151
http://wiki.hash.kr/index.php/%ED%95%B4%EC%8B%9C%EB%A7%B5
https://velog.io/@kwj2435/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-Hash-HashMap-HashTable
django
➡️DRF Custom UserModel
- Django User 모델과 DRF Custom User 모델의 차이는 무엇입니까?
Django User 모델은 AbstractUser를 상속받아서 USERNAME_FIELD(로그인 ID)을 정의된 username 필드를 사용하고 커스텀하게 되면 AbstractBaseUser를 상속받아서 USERNAME_FIELD를 자유롭게 선택할 수 있다
커스텀 유저 모델을 정의할 때는 유저매니저를 이용해서 유저를 만든다..
여기서 DRF는 상관이 없다
Custom UserModel
BaseUserManager를 상속받은 UserManager 클래스를 이용해서 create_user, create_superuser 함수를 정의함
그 아래 User 모델을 커스텀해서 정의하는데 UserManager를 통해 유저를 생성하고 (objects=UserManager()) 보통 AbstractBaseUser를 상속받고(정해진 필드가 거의 없어 자유도가 높음. 인증기능도 상속받음) 넣고싶은 필드를 정의하고 필수 입력값 등을 정할 수 있다
UserManager
class UserManager(BaseUserManager):User
class User(AbstractUser):
class AbstractUser(AbstractBaseUser, PermissionsMixin):
class AbstractBaseUser(models.Model):유저모델 오류없이 가져오는 방법
settings.AUTH_USER_MODEL == get_user_model()
from django.contrib.auth import get_user_model➡️조건과 일치하는 object를 가져오는 방법
objects.filter().exists()
- object를 담은 queryset을 반환한다
- get 보다 속도가 빠름
filter().first()<->last(): 가져온 결과가 none인 경우 none을 반환
objects.get()
object를 반환한다
쿼리문으로 하나의 object를 가져오는 경우
object vs queryset
DB에서 전달받은 객체들의 리스트
QuerySet객체는 iterate하는 시점에서 딕셔너리로 반환된다.
➡️ django ORM method
F( )
F(테이블의 칼럼/필드값)
파이썬 메모리로 가져오지 않고 - 파이썬이 모르는 채로 - 데이터베이스에서 연산할 수 있다(객체를 DB에서 가져오고, 메모리에 올리고 연산하고, 다시 저장하는 과정이 축약된다)
- Django에서는 F() 객체를 만나면, Python 연산자를 오버라이딩하여 캡슐화된
SQL문을 생성한다.
따라서 쿼리의 수를 줄일 수 있다
따라서 race condition을 피할 수 있다
- 데이터베이스의 필드값을 파이썬의 스레드로 가져와서 처리할 때 다수의 요청에 의해서 다수의 쿼리가 발생하기때문에 한정된 스레드(자원)에 대한 경쟁이 발생한다
*파이썬은 GIL에 의해 싱글스레드로 동작한다
실행 및 DB반영시기 파이썬이 아는 시점이 언젠지❓
인스턴스가 save()되거나 update()될 때 쿼리문이 실행되어 데이터베이스 필드 값을 기반으로 필드 값을 변경한다
F와 자주 쓰이는 .annotate( )
- 필드 값을 복사해서 새로운 이름의 필드에 저장
기존 필드에 해당하는 새로운 필드를 만들고 그 값들을 가져오는 것이므로annotate → values순서# Order 클래스의 product 필드는 Product 클래스와 ForiegnKey로 연결 # <소문자클래스명__클래스의불러오려는칼럼>으로 불러올 수 있다 # .values()는 해당 칼럼의 값들을 가져온다 order = Order.objects.values('created', 'product__name','product__price') # product__name과 product__price 필드의 값을 복사해서 name, product에 저장 order = Order.objects.annotate(name =F('product__name'), price=F('product__price').values('created','name','price')
- 계산한 값을 새로운 필드에 저장
기준이 되는 값을 먼저 가져오고 그 값을 토대로 계산한 값을 새로운 필드에 넣기때문에values → annotate순서
ex. 날짜별 판매량daily_list = order_log.values('created' ).annotate(daily_total=Sum('product__price'))http://raccoonyy.github.io/django-annotate-and-aggregate-like-as-excel/
https://blog.myungseokang.dev/posts/django-f-class/
https://a-littlecoding.tistory.com/55
프로그래머스 문제 풀기
➡️ 캐시개념
메모리에서 사용했던 내용을 다시 접근할 때 더 빠르게 접근할 수 있도록 보관하는 것
한번 사용된 데이터가 재사용될 가능성이 크다는 점을 이용한 메모리 저장 방식
Cache Hit
CPU가 참조하고자 하는메모리가? 데이터가 캐시에 존재하고 있을 경우Cache Miss
CPU가 참조하고자 하는 메모리가 캐시에 존재하지 않을 때
Least Recently Used algorithm
주기억장치에 가장 오랫동안 참조되지 않은 페이지를 교체하는 방법
- 페이지: 메모리에 저장되는 저장단위
누가 가장 오래 참조되지 않았는지를 알아야하므로 시간을 기록해둬야해서 오버헤드가 크다
장점: 가장 최근에 사용한 페이지~가장 적게 참조된 페이지까지 정렬되므로 이 두 페이지에 대해서 O(n)의 시간복잡도를 가진다
한가지 값에 대해 접근할 때마다 업데이트가 되기 때문에 업데이트는 O(n)의 시간복잡도를 가진다
단점: 길이가 n인 linked-list와 이를 추적하기 위한 동일한 크기의 hash map이 필요하여 저장공간을 많이 차지한다
- O(n)의 시간복잡도를 가지고 2개의 자료구조를 사용하게 된다
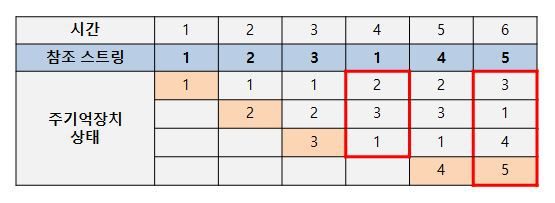
참조스트링: 접근하고자하는 값을 나타냄
1-2-3-1-4-5 순서로 접근함
주기억장치는 4칸으로 제한되어있을 때, 마지막 5에 접근할 때 주기억장치의 메모리를 초과하기때문에 메모리에서 가장 이전에 참조한 2를 없애고 5를 추가한다
➡️ 캐시
from collections import OrderedDict
def solution(cacheSize, cities):
frequency=OrderedDict()
hit, miss = 0, 0
for city in cities:
city=city.lower()
if city not in frequency.keys():
miss+=1
frequency[city]=1
if cacheSize<len(frequency):
least=list(frequency.keys())[0]
del frequency[least]
else:
frequency[city]+=1
frequency.move_to_end(city,last=True)
hit+=1
return hit*1+miss*5캐시에 저장된 city의 빈도수를 저장하는 딕셔너리frequency를 만든다
이 때 순서(캐시에 들어온)가 보장될 수 있도록 collections에서 OrderedDict를 임포트해서 사용해준다
hit은 캐시에 있어서 꺼내 쓴 경우를 카운트하고
miss는 캐시에 없어서 DB에서 꺼내써야하는 경우를 카운트한다
대소문자를 구분하기때문에 모두 소문자로 통일해주고
frequency에 키값으로 city가 없다면(굳이 key로 하지 않아도 키만 검색해주는 것 같은데 이거 확인해봐야지⭕)
캐시에 없다는 거고
그럴 때 해당 딕셔너리에 요소를 추가해주고 한번나온 거니까 값은 1로 추가해준다 → frequency.update({city:1}) 와 동일하다
캐시 사이즈보다 frequency가 더 크다면 저장할 수 있는 메모리를 초과한 것이므로 가장 이전에 참조된 데이터를 삭제해야한다
least변수에 가장 적게 참조된 frequency의 첫번째 키 값을 인덱스를 이용해서 넣어주고 그 변수를 이용해서 딕셔너리에 해당 요소를 삭제한다(ordered dict이면 인덱스를 쓸 수 있나?? 만약 그렇다면 least를 구할 필요가 없다 ❌)
만약 city가 캐시에 있다면 해당 city의 빈도수를 1 증가 시켜주고
해당 도시를 맨 마지막 위치로 옮겨주어야 최근 사용됐다는 걸 알 수 있기때문에 OrderedDict.move_to_end(키값, last=True) 를 해준다
큐/스택으로 다 풀 수 있다구..
힙으로도 해봐야징 이이이이
➡️딕셔너리 언제까지 날 괴롭힐거야?
기억해
len()
get()
in 키값 안에서 검색 ⭐
딕셔너리 to 튜플
zip(dict.keys(),dict.values())
OrderedDict 💕
파이썬 3.6부터 딕셔너리도 순서 저장한다더니 순 뻥이다
그거때매 75점 맞았잖아??? 내 눈에 보이는 걸 그대로 믿으면 안된다 안되는 거였던 것.. 그게 아니곡서야 어떻게 이걸로 해결이 돼???
from collections import OrderedDict
- 키-밸류 생성 순으로 들어간다
- 이미 존재하는 키에 대해서는 값을 바꾸더라도 순서 유지
- 메서드
두 메서드 모두last=옵션을 사용할 수 있다 기본이Falsepopitem()마지막 값 리턴하고 삭제
last=False옵션을 넣으면 첫번째 값을 리턴하고 삭제 ⭐move_to_end()키-밸류 쌍을 처음/ 마지막으로 이동
https://2030bigdata.tistory.com/108
https://dongdongfather.tistory.com/71
