
⚙️ 머신러닝 1주차
🤖 머신러닝의 종류:
- 지도학습: 정답을 주고 학습시킴 (우리가 배울 분류, 회귀가 여기에 포함됨)
➜ 정답이 없는 경우는 레이블링/어노테이션을 통해 입력값에대한 정답을 일일이 입력해줘야함 - 비지도학습: 정답이 따로 없고 굳이 어떤 기준이 없을 때 알아서 비슷한 것끼리 묶어서 분류함 = 군집화(clustering)
➜ 오래 걸림 - 강화학습: 주어진 데이터 없이 행동에 대한 보상을 얻으면서 학습
➜ 모든 상황에 대해서 예측하고 답을 설정하기 어려운 경우( 경우의 수가 큰 경우) 효율적인 학습법
🤖 선형회귀와 가설, 손실함수
입력값과 결과값의 데이터를 가지고 1차함수 모델(가설)을 만들 수 있다.
이 그래프와 실제 데이터(점)간의 간격(직선거리= cost, 손실함수)이 짧을수록 모델이 학습이 잘 되었다고 할 수 있다.
다중선형회귀(multi-variable linear regression)는 입력 변수(variable)가 여러개(multi)인 선형회귀
🤖 경사 하강법 Gradient Descent Method
optimizer 중 하나
learning rate(lr): 전진하는 단위
➜ 너무 작으면 시간이 오래걸리고 크면 overshooting(진동/발산)할 가능성이 있음
➜ 적당한 lr을 찾기 위해선 노가다가 필수
손실 함수의 최소화가 목표 ➜ 손실 함수의 최저점에 도달하면 학습 종료
랜덤으로 선택된 점에서 시작 ➜ lr 단위로 점진적으로 문제 풀이 진행 ➜ 손실 함수의 최저점에 도달할 때까지 학습
local이 아닌 global cost minimum을 찾아야함
좋은 가설과 좋은 손실함수를 통해 기계가 잘 학습할 수 있도록 해야한다!
🤖 데이터 셋의 분류
- training set: 머신러닝 모델을 학습시키는 용도로 사용 전체의 80%
- validation set: 머신러닝 모델의 성능을 검증, 튜닝하는 지표가 됨
➜ 학습 단계에서 사용되고, 정답 라벨이 있으나 모델에게 직접 보여주지 않기 때문에 모델 성능에 영향을 미치지 않음 - test set: 정답 라벨이 없는, 실제 환경에서의 데이터셋
➜ 실제 제품에서 제대로 동작하는지 확인
🤖 실습
tensorflow (비추)
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
# 데이터 정의
x_data = [[1, 1], [2, 2], [3, 3]]
y_data = [[10], [20], [30]]
# 변수 정의
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W')
b = tf.Variable(tf.random.normal(shape=(1,)), name='b')
# 가설, 비용, 옵티마이저 정의
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
#
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
# 매 스텝마다 결과값 출력-> 비용함수가 줄어드는지 확인
for step in range(50):
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data})
print('Step: %2d\t loss: %.2f\t' % (step, c))
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}))keras( tensorflow의 상위 API )
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])
# keras는 numpy로 가공된 데이터를 취급함
model = Sequential([
Dense(1)
])
# 출력되는 결과값(레이어)은 1개
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=100) # epochs는 반복횟수🤖 kaggle 데이터로 선형회귀 실습하기
kaggle: 다양한 데이터셋이 공개되어있는 사이트
https://www.kaggle.com/datasets/ashydv/advertising-dataset
데이터셋 처리하기
# 라이브러리 임포트
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
# -> 여기까진 기본적으로 동일
import numpy as np
# -> 데이터 가공
import pandas as pd
# -> .csv 파일 읽을 때 사용
import matplotlib.pyplot as plt
import seaborn as sns
# -> 그래프 그릴 때 사용
from sklearn.model_selection import train_test_split
# -> train data와 test data 분리
# 데이터셋 불러와서 형태 보기(습관을 들이는 게 좋음)
df = pd.read_csv('advertising.csv')
df.head(5)
# -> 앞에서부터 5줄 읽어오기 <-> df.tail(5)
# 데이터셋 크기 확인
print(df.shape)
# -> (200, 4) (=데이터 갯수, 칼럼 수)
# 데이터셋 살펴보기
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4)
# 데이터셋 가공하기
x_data = np.array(df[['TV']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
print(x_data.shape)
print(y_data.shape)
# -> (200,1), (200) 출력됨
# 데이터셋 모양 맞춰주기
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
# -> 뒷자리엔 1을 쓰고 앞자리엔 남은거 붙여라(-1)
print(x_data.shape)
print(y_data.shape)
# 데이터셋 학습/ 검증 데이터로 분할하기(실무에선 꼭 테스트데이터까지 3가지로 분할할 것)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)(이어서) 학습시키고 검증데이터로 예측하기
# 학습시키기
model = Sequential([
Dense(1)
])
# -> 선형회귀함수 정의
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
# Adam: gradient descent optimizer 보다 성능이 좋음
# 학습시킬 땐 fit!
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # 반복학습 횟수
)
# -> 결과물의 loss는 train loss/ val_loss 는 validation loss
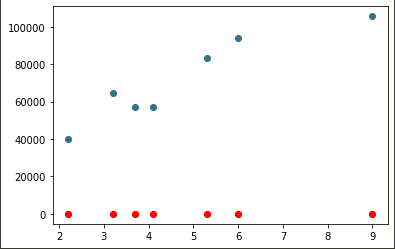
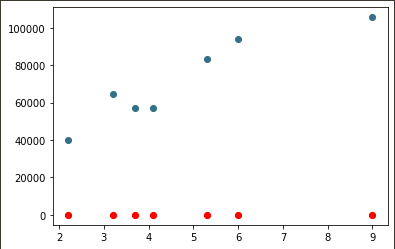
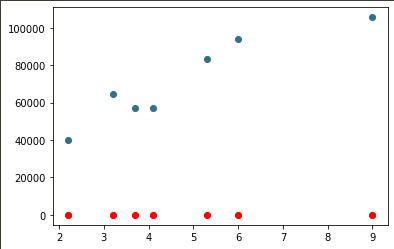
# 검증 데이터로 예측하기
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val) #y_val: 정답값
plt.scatter(x_val, y_pred, color='r') #y_pred: 예측값
# -> 예측 데이터는 빨간색으로 그려라
plt.show()🤖 여러개의 인풋값을 이용해서 예측해보기
다중 선형 회귀
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('advertising.csv')
x_data = np.array(df[['TV', 'Newspaper', 'Radio']], dtype=np.float32)
# 선형회귀랑 같지만 인풋값(x)이 3개로 증가함
y_data = np.array(df['Sales'], dtype=np.float32)
x_data = x_data.reshape((-1, 3))
# 칼럼이 3개니까
y_data = y_data.reshape((-1, 1))
# 모양만 맞추는 거니까 1임
print(x_data.shape) # (200,3)
print(y_data.shape) # (200,1)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
# test_size: 검증할 데이터를 20%로 지정하고 나머지는 학습데이터로
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=100
)
y_pred = model.predict(x_val)원래는 3차원 함수로 그려야하지만 아직 어려우니까 각각의 x에 대한 y값을 2차원 그래프로 하나씩 그려본다
x_val[:0] : tv
x_val[:1] : newspaper
x_val[:2] : radio
plt.scatter(x_val[:0], y_val)
plt.scatter(x_val[:0], y_pred, color='r')
plt.show()🤖 1주차 숙제 - 혼자서 Linear regression 구현하기
https://www.kaggle.com/datasets/rsadiq/salary
- Learning rate(lr), 2. Optimizer(Adam, SGD), 3. 손실함수(loss)를 mean_absolute_error를 바꾸면서 실험하기
➜ model.compile(loss='mean_absolute_error',optimizer=Adam(lr=0.1))
❓근데 분명 수업에서 아담이 더 업그레이드된 버전이라고 그랬는데 SGD 써야 로스가 유의미하게 줄어든다 왜그러지??????????????? 데이터마다 다른건가 SGD의 mse가 제일 잘 나오고 나머지는.. 모지..
SGD ➜
mean_squared_error

mean_absolute_error
Adam ➜
mean_squared_error
mean_absolute_error

ㅘ!