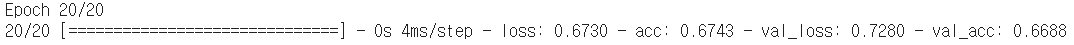⚙️ 머신러닝 2주차
1주차는 회귀 2주차는 분류
선형회귀로 풀 수 없는 '분류' 문제들은 논리회귀로 풀 수 있다
선형회귀의 결과는 직선그래프/ 논리회귀의 결과는 곡선 그래프
ex) n%의 확률로 fail(0)/pass(1) 한다고 예측할 수 있음
임계치(threshold)는 필요에따라 조정할 수 있음
전처리(preprocessing): 머신러닝의 70-80%를 차지하는 부분 raw data를 가공하는 일
정확도에 영향을 많이 미치기때문에 아주아주 중요한 부분!
🤖 논리 회귀(Logistic regression)
- logistic function (= sigmoid function(딥러닝에서))
선형회귀 함수와 같으나 시그모이드 함수를 붙여 0-1 사이의 출력값을 가지도록 조정함입력 ▶ 선형모델 ▶ 시그모이드 ▶ 출력
- 손실함수: cross entropy
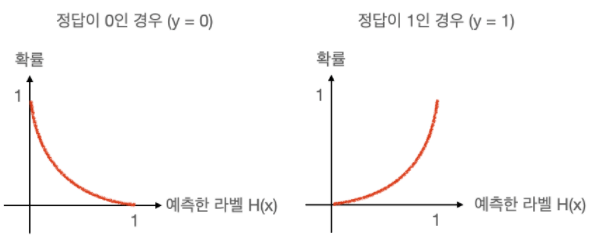
- 확률 분포 그래프: x축: 라벨(클래스) y축: 확률
ex) 정답값이 0인 경우 출력값이 0일 확률을 100%에 가깝도록 만들어줌
반대로 정답값이 1인 경우 출력값이 1일 확률을 100%에 가깝도록 만들어줌
케라스에서 binary_crossentropy 사용
- 확률 분포 그래프: x축: 라벨(클래스) y축: 확률
🤖 다항 논리 회귀(Multinomial Logistic regression)
단항 논리회귀와 다른 점: 라벨(클래스)이 여러개!
- 원핫 인코딩(one-hot encoding):
다항 논리회귀 문제의 출력값을 컴퓨터가 인식하기 좋은 0,1로 이루어진 형태로 변환클래스의 갯수만큼 배열을 0으로 채운다 ▶ 각 클래스의 인덱스 위치에 1을 넣는다
- softmax 함수
선형 모델을 거친 결과값(logit)을 모두 더했을 때 1이 되도록 만들어줌
(당연히 logit의 가중치를 고려함)
-> 예측 결과를 확률로 표현하기 위해
-> 정답값인 라벨도 원핫 인코딩을 거치면 합이 1이 된다 - 손실함수: cross entropy (논리회귀와 동일)
예측 결과그래프와 정답값그래프간의 차이를 줄여준다
케라스에서 categorical_crossentropy 사용
🤖 머신러닝 모델(classifier)
분류를 잘 할 수 있는지 = 선을 잘 그을 수 있는지를 생각하면 쉽다
- SVM(support vector machine)
support vector와 margin의 값이 클수록 좋다 - KNN(k-nearest neighbor)
ex) K=2인 경우 가장 가까운 객체 2마리로 인스턴스의 클래스를 구분한다 - Decision Tree
생각보다 성능이 좋아 간단한 문제를 풀 때 많이 사용됨 - Random Forest
여러개의 DT를 사용해서 각각 결과를 내고 그 중 다수인 것으로 최종 결과를 선택
성능이 좋아 많이 사용됨
➜ 선형/논리 모델로 해결이 안될 때 사용해보면 좋다
🤖 전처리과정(Pre-processing)
단위를 맞추고 예외사항들을 지워준다(아웃라이어 제거)
- 정규화(Normalization)
데이터를 (보편적으로)0-1사이의 값으로 만든다 - 표준화(Standardiztion)
데이터의 평균을 0, 표준편차를 1이 되도록 만들어 데이터 분포를 정규분포로 바꾼다
원래 데이터에서 평균값을 빼주면 중심이 0으로 맞춰지고
표준편차 값으로 나눠주면 데이터가 밀집된다
두가지 모두 학습속도(최저점 수렴 속도)를 향상시켜주고 그래프의 굴곡을 작게 만들어 로컬 미니멈에 빠질 가능성을 낮춰준다
🤖 실습
이진 논리 회귀
https://www.kaggle.com/heptapod/titanic
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key- 데이터셋 다운로드
!kaggle datasets download -d heptapod/titanic
!unzip titanic.zip- 필요한 패키지 임포트
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 전처리 과정(표준화)- 데이터 로딩하기
df = pd.read_csv('train_and_test2.csv')- 전처리하기
# 사용할 컬럼 추출하기
df = pd.read_csv('train_and_test2.csv', usecols=[
'Age', # 나이
'Fare', # 승차 요금
'Sex', # 성별
'sibsp', # 타이타닉에 탑승한 형제자매, 배우자의 수
'Parch', # 타이타니게 탑승한 부모, 자식의 수
'Pclass', # 티켓 등급 (1, 2, 3등석)
'Embarked', # 탑승국
'2urvived' # 생존 여부 (0: 사망, 1: 생존)
])
df.head(5)
# 원하는대로 잘 바뀌었는지 확인
# 숫자가 아닌 값이 있는지 확인
print(df.isnull().sum())
# 비어있는 행 없애기
df = df.dropna()
# 머신러닝을 위한 데이터는 문자/null값이면X
# 반드시 숫자여야하므로 빈값이 포함된 행을 제거한다
# 간단하게 데이터셋 미리보기
sns.countplot(x='Sex', hue='2urvived', data=df)
# 클래수 갯수 확인하기
sns.countplot(x=df['2urvived'])
# X, Y 데이터 분할하기
x_data = df.drop(columns=['2urvived'], axis=1)
# x값으로는 결과값인 '생존여부'를 제외하고 모두이므로 이에 해당하는 칼럼만 제외시켜준다
x_data = x_data.astype(np.float32) # 소수점 32비트
y_data = df[['2urvived']]
y_data = y_data.astype(np.float32)
# 표준화하기
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
# x 데이터만 단위가 다 다르니까 표준화 작업을 한다
print(x_data.values[0])
print(x_data_scaled[0])
# 첫번째 인덱스에 해당하는 값으로 잘 바뀌었는지 확인
# 학습/검증 데이터 분할하기
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
# print(x_train.shape, x_val.shape)
# -> (1045, 7) (262, 7)
# 1045개로 학슴, 262개로 검증 7은 칼럼 수- 모델 학습시키기
model = Sequential([
Dense(1, activation='sigmoid')
])
# 결과물은 하나, 리니어 실행 후 시그모이드 실행
model.compile(loss='binary_crossentropy',
# 논리회귀는 바이너리 크로스엔트로피를 손실함수로 사용한다
optimizer=Adam(lr=0.01), metrics=['acc'])
# 논리회귀는 로스값만 봐서는 얼마나 학습이 잘 됐는지 알기 어렵기때문에
# 분류 문제를 풀 땐 metrics를 사용한다
# acc 는 정확도를 나타내고, 0-1 사이의 값을 가진다
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=20
)다항 논리 회귀
https://www.kaggle.com/datasets/brynja/wineuci
이전 과정은 모두 동일
-데이터셋 로드
df = pd.read_csv('Wine.csv')
df.head(5)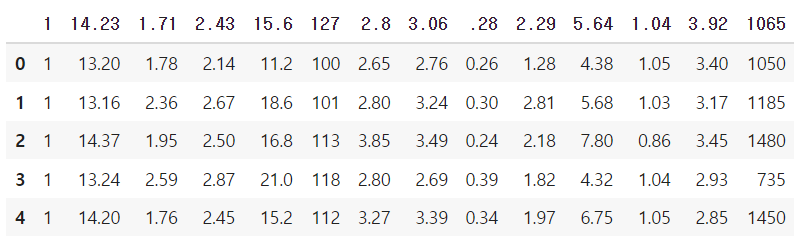
➜ 데이터프레임의 헤더가 누락되어있음
- 헤더의 내용을 채워주기
df = pd.read_csv('Wine.csv', names=[
'name'
,'alcohol'
,'malicAcid'
,'ash'
,'ashalcalinity'
,'magnesium'
,'totalPhenols'
,'flavanoids'
,'nonFlavanoidPhenols'
,'proanthocyanins'
,'colorIntensity'
,'hue'
,'od280_od315'
,'proline'
])
df.head(5)- 정답 라벨의 개수 확인
sns.countplot(x=df['name'])- 전처리
- 비어있는 행 확인
- 데이터 분할
- 데이터 표준화
- One-hot encoding
encoder = OneHotEncoder()
y_data_encoded = encoder.fit_transform(y_data).toarray()
print(y_data.values[0]) #y data의 첫번째 행의 값을 가져온 것
print(y_data_encoded[0])
print(y_data.values[1]) # 그러니까 0,1,2 모두 name이 1로 값이 같으니까 모두 동일하게 [1.],[1. 0. 0.]이 나옴
print(y_data_encoded[1])
print(y_data.values[176]) # 뒤에 name=3인게 나오면 [3.][0. 0. 1.] 이렇게 잘 나옴 ㅋㅋㅋ []안에 들어가는건 당연히 인덱스인데!
print(y_data_encoded[176])- 학습/검증 데이터 셋 분할
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data_encoded, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape) #(142, 13) (36, 13) 13은 feature의 갯수
print(y_train.shape, y_val.shape) #(142, 3) (36, 3) 3은 와인의 종류(1,2,3)- 모델 학습
model = Sequential([
Dense(3, activation='softmax')
]) #출력이 3개(와인 종류)니까 3, 다항이니까 소프트맥스
model.compile(loss='categorical_crossentropy',
# 다항이니까 손실함수 categorical_crossentropy
optimizer=Adam(lr=0.02), metrics=['acc'])
# 학습시키기
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20
)
➜ val_acc 와인 종류를 나누는 정확도 94%
❌오류
다항 논리 회귀에서 데이터를 학습시킬 때
/usr/local/lib/python3.7/dist-packages/keras/optimizer_v2/adam.py:105: UserWarning: The lr argument is deprecated, use learning_rate instead.
❗ 해결learning_rate로 고쳐쓰면 오류는 안나는데 그래도 강의자료랑 값이 다르게 나온다
아래는 왜 같이 출력되는지 모르겠다
super(Adam, self).init(name, **kwargs)
🤖 2주차 숙제
https://www.kaggle.com/datasets/mathchi/diabetes-data-set
-
데이터셋 미리보기

-
클래스 갯수 확인하기
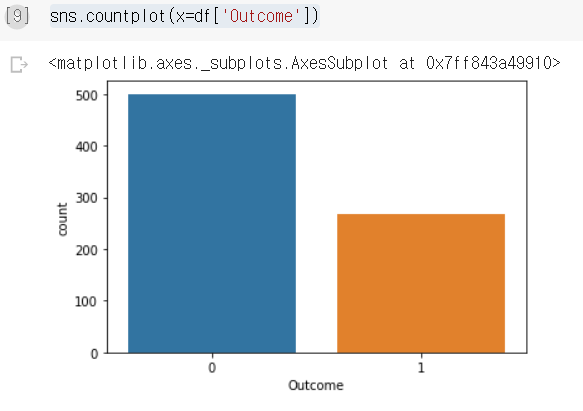
-
비어있는 행 확인

-
X,Y 데이터 분할하기
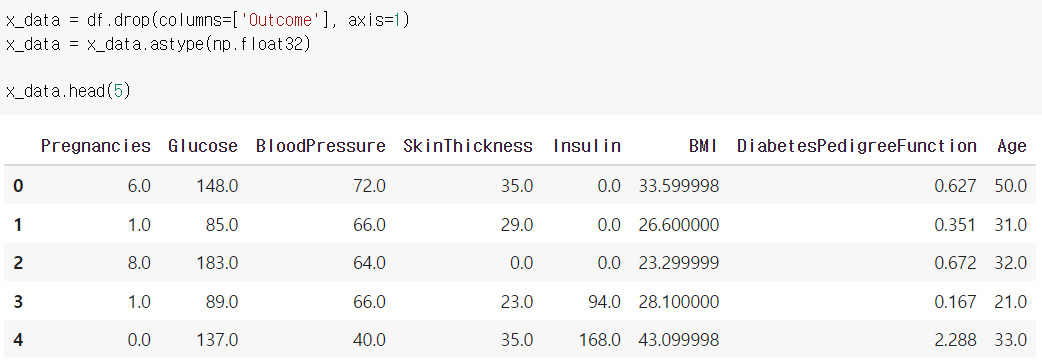
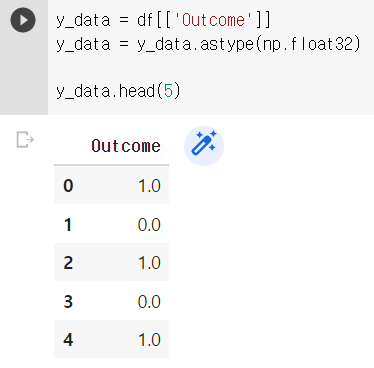
-
표준화

-> 이렇게 - 값이 나와도 되나?????????????????? 답안에도 데이터가 0인 부분은 마이너스로 나와있긴한데....흠..? -
학습시키기