
⚙️ 머신러닝 3주차 ➜▶❌❗
🤖 딥러닝이란!
= Deep neural networks = Multilayer Perceptron(MLP)
인공지능AI> 머신러닝> 딥러닝
선형회귀 사이에 비선형을 넣어서 쌓음 ➜ 딥러닝
🤖 딥러닝의 역사
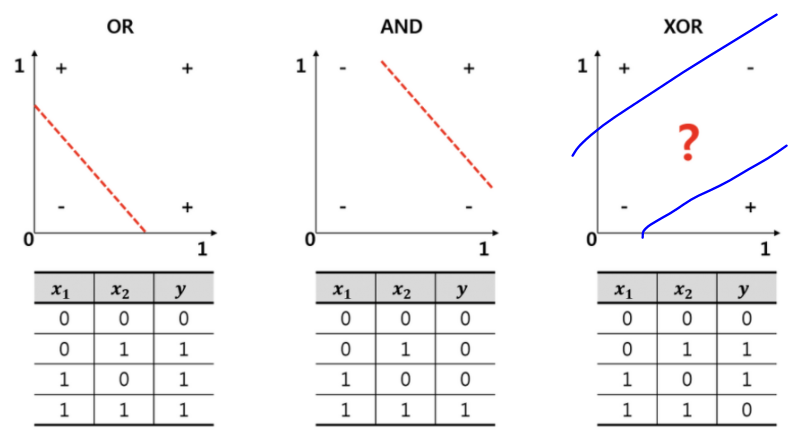
AND Gate(둘 중 하나가 0이면 0)/OR Gate(둘 중 하나가 1이면 1) ➜ 선형/논리 회귀로 풀 수 있음
XOR(같으면 0 다르면 1) ➜ 풀 수 없음(직선으로 0과 1의 섹션 구분이 불가능)
-
multilayer perceptron: perceptron으로 이뤄진 층들이 2개 이상
input layer-hiddden layer-output layer -
backpropagation(역전파): 출력과 정답값을 비교해서 잘못된 경우 돌아가서 weight와 bias를 바꾼다(피드백을 주는 것)
-
Deep Neural Networks 구성 방법
input nodes(갯수가 정해져있음) ➜ hidden nodes(조정함 보통 늘렸다가 줄이는 방식으로 설계)+활성함수(각각의 은닉층 뒤에)➜ output nodes(갯수가 정해져있음) -
네트워크의 너비와 깊이
베이스라인 모델을 가지고 튜닝을 해볼 수 있다
너비를 늘리는 방법: 은닉층의 갯수는 그대로, 노드의 갯수를 늘림
깊이를 늘리는 방법: 은닉층의 갯수를 늘리고, 노드의 갯수는 그대로
너비와 높이 모두 바꿔가면서 튜닝도 가능
➜ 과적합과 과소적합을 피하기 위해서 많은 실험(튜닝)이 필요함
🤖 딥러닝의 주요개념
머신러닝때부터 있던 게 발전된 개념들
사용할 수 있는 메모리의 용량은 정해져있기때문에 데이터셋을 쪼개서 반복학습을 시켜야함
batch size: 데이터셋을 쪼개는 단위
iteration: 나눈 데이터셋을 몇번 반복학습하는지
➜ batch X iteration = total data
epoch: 전체 데이터 셋을 반복학습 횟수
학습시에는 batch size 단위로 모델에 들어가게 됨
각 배치마다 forward, backpropagation을 다 하면 1 epoch
-
activation function: 모두 비선형
임계치를 넘어야 다음 노드로 값이 전달이 된다(뉴런의 개념과 동일)
➜ 활성화가 되는 임계치가 있어서 임계치를 넘지 못하면 0값으로(활성화x) 넘겨준다- Sigmoid
- Relu: 가장 단순하고 많이 사용됨
(x=<0,y=0 x>0,y=x) - Leaky Relu
- Elu
- tanh: 이미지 출력시
- Maxout
-
Linear regression(input layer) = Dense Layer = FCL(Fully Connected Layer)
-
오버피팅/ 언더피팅
모델의 복잡도(너비/깊이) 커질수록 트레이닝 에러는 줄어드는데 벨리데이션 에러가 갑자기 올라가는 순간이 있어서 테스트 에러가 가장 낮은 부분에서 끊어줄 필요가 있는데 이 부분을 베스트핏이라고 부른다
베스트 핏을 기준으로 왼쪽(학습이 덜 된)을 언더피팅 오른쪽을 오버피팅(복잡도(노드의 수)증가-에러는 커지는)이라고 한다
실무에서는 오버피팅의 경우가 많아서 모델의 복잡도를 줄여주거나 여러 스킬을 사용한다
🤖 딥러닝의 주요스킬
-
데이터 증강(data augumentation)
안하는 경우가 거의 없음 특히 이미지 처리에서 많이 사용
➜ 과적합(오버피팅)을 해결하기 위한 가장 좋은 방법
데이터를 실제로 더 모으기가 힘들기때문에 데이터를 보충하기 위해서 사용
ex) 반전, 회전, 크기 조절, 화질 조정, 밝기 조정, 노이즈추가, 픽셀 제거
➜ 이런 사진들을 모두 인간이 보는 것처럼 하나의 인스턴스로 보도록 하는 과정을 일반화(generalize)라고 한다 -
드랍아웃(dropout)
배치마다 랜덤하게 노드를 끊어준다
판단하는 노드가 너무 많으면 적합하지 않은 판단이 나오게 됨..
사공이 많으면 배가 산으로 간다..
어떤 비율로 해야되는지는 알아서.. -
앙상블(ensemble)
컴퓨팅 파워 필수
여러개의 네트워크(딥러닝 모델)를 사용해서 여러개의 결과를 도출한 후 그 결과들을 하나의 개념(다수결/평균값/최댓값 등)으로 판단해서 최종 결과를 도출해낸다
앙상블을 사용하면 최소 2% 이상의 성능향상의 효과를 기대할 수 있음 -
Learning rate decay(Learning rate schedules)
실무에서 많이 사용
로컬 미니멈에 빨리 도달하고자할 때 사용
러닝 레이트를 점차적으로 줄이는 방법
오버슈팅을 막는 가장 좋은 방법(에러가 팍팍 줄어듬 = 정확도 증가)
➜ 케라스에서 tf.keras.callbacks.LearningRateScheduler() 와 tf.keras.callbacks.ReduceLROnPlateau() 를 사용하여 학습중 러닝레이트를 조절함
🤖 실습
XOR 실습 (3가지 방법으로)
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
# 데이터셋
x_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32)
y_data = np.array([[0], [1], [1], [0]], dtype=np.float32)- 이진 논리 회귀로 풀어보기
model = Sequential([
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=1000, verbose=0) # verbose=0 출력 양이 너무 많으니까 출력을 막음 1이면 출력함
y_pred = model.predict(x_data)
print(y_pred) # [[0], [1], [1], [0]]이 정답인데 완전히 다름 -> 논리회귀로 풀 수 없음
- XOR 딥러닝(MLP)
# 시퀀셜 api는 사용하기가 쉽고 이해가 쉽지만
# 실무에서는 순서대로 쌓는 네트워크가 거의 없기때문에 잘 사용하지 않는다
model = Sequential([
Dense(8, activation='relu'), #히든 레이어 노드 8개
Dense(1, activation='sigmoid'), #y(출력) 1개 결과값이 0/1 이므로 바이너리인 시그모이드 사용
])
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1)) # 모델을 만들어준다
model.fit(x_data, y_data, epochs=1000, verbose=0)
y_pred = model.predict(x_data)
print(y_pred)
- Keras Functional API
우리는 지금까지 Keras의 Sequential 클래스를 사용하여 Sequential API를 사용했습니다. Sequential API는 순차적인 모델 설계에는 편리한 API 이지만, 복잡한 네트워크를 설계하기에는 한계가 있기 때문에 실무에서는 Functional API를 주로 사용합니다.
위에서 했던 XOR 딥러닝 문제를 Functional API로 다시 작성해보겠습니다!
import numpy as np
from tensorflow.keras.models import Sequential, Model # Model 추가됨
from tensorflow.keras.layers import Dense, Input # Input추가됨
from tensorflow.keras.optimizers import Adam, SGD
input = Input(shape=(2,)) # 인풋 노드 갯수 x1,x2
hidden = Dense(8, activation='relu')(input) # 히든에는 인풋 레이어를 넣어주고
output = Dense(1, activation='sigmoid')(hidden) # 아웃풋엔 히든 레이어를 넣어준다
model = Model(inputs=input, outputs=output) #시퀀셜 대신 모델
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.summary()
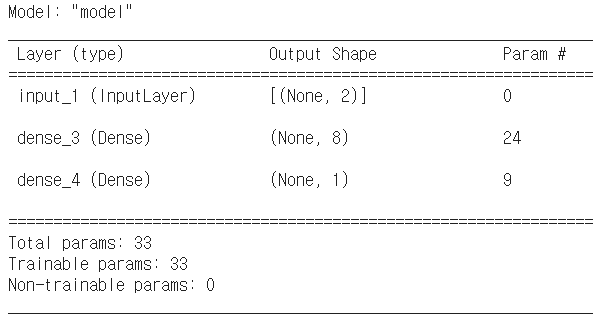
➜ Sequential API를 사용하면 구조를 확인하기 힘들지만 Functional API를 사용하면 model.summary()를 사용하여 구조를 확인하기 쉽다
➜ none은 배치사이즈 이건 사용하는 사람 마음대로 조절 가능
➜ 보통 normalization layer나 dropout는 트레이닝을 안하기 때문에 Non-trainable params 로 카운트됨
model.fit(x_data, y_data, epochs=1000, verbose=0)
y_pred = model.predict(x_data)
print(y_pred)
딥러닝 실습
영어 알파벳 수화 데이터셋
https://www.kaggle.com/datamunge/sign-language-mnist
# 패키지 로드
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
# 데이터셋 로드
# 데이터셋이 훈련용, 테스트용으로 첨부터 분리되어있음
train_df = pd.read_csv('sign_mnist_train.csv')
test_df = pd.read_csv('sign_mnist_test.csv')
# 라벨분포 그래프로 확인
# 9=J or 25=Z 는 동작이 들어가므로 제외 = 총 24개
plt.figure(figsize=(16, 10)) # 그래프 크기(가로,세로)
sns.countplot(train_df['label'])
plt.show()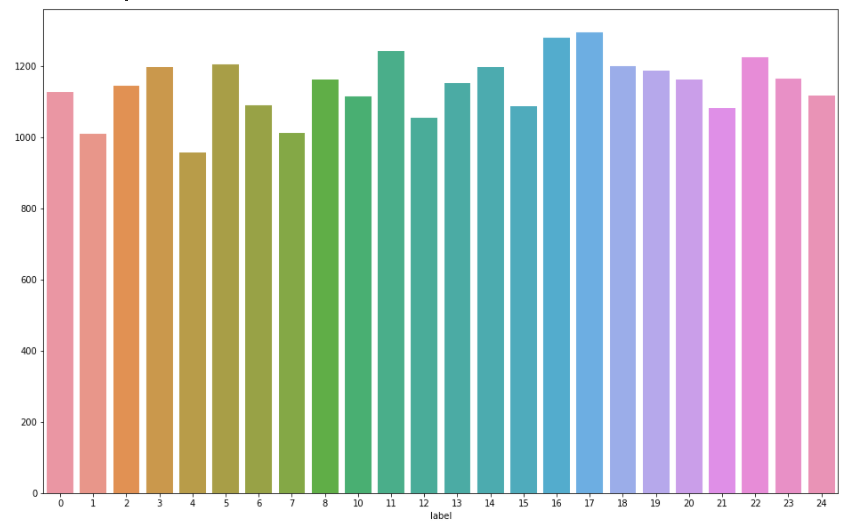
# 전처리 - 입력과 출력 칼럼 나누기
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values # values: numpy array로 변환하게됨
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
y_test = test_df[['label']].values
print(x_train.shape, y_train.shape) # (27455, 784) (27455, 1)
print(x_test.shape, y_test.shape) # (7172, 784) (7172, 1)
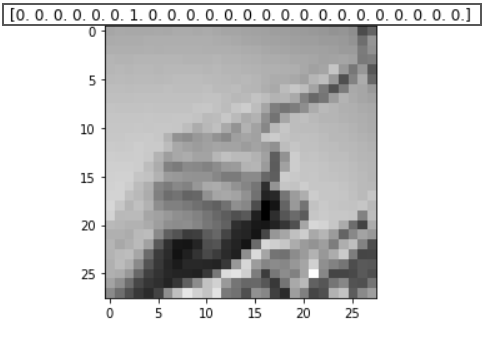
# 데이터 미리보기
index = 1
plt.title(str(y_train[index]))
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
#픽셀이 일렬로 늘어서있으면 그림형태를 보기가 어려우니까 원래 모양(28*28)대로 바꿔줌, 그레이스케일
plt.show()
#원핫인코딩
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray()
y_test = encoder.fit_transform(y_test).toarray()
print(y_train.shape) #(27455, 24)원핫인코딩을 한다음 데이터 미리보기를 다시하면 라벨 데이터가 바뀐 것을 확인할 수 있다
원래 y_train index[1] 은 6 ➜ 7번째 칸이 1로 채워진 배열로 변함

# 일반화(normalization)
# 이미지 데이터는 픽셀이 0-255 사이의 정수(unsigned integer 8bit = uint8)로 되어 있습니다.
# 이것을 255로 나누어 0-1 사이의 소수점 데이터(floating point 32bit = float32)로 바꾸고 일반화 시키도록 할게요!
# 반드시 한번만! 실행할 것 여러번하면 계속 나눠버림
x_train = x_train / 255.
x_test = x_test / 255.
# 네트워크 구성
input = Input(shape=(784,)) # 인풋노드 784개
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(24, activation='softmax')(hidden) # 24개니까 다항
# 히든레이어들은 모두 덴스(fully connected layer)로 되어있다
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
# 모델을 구성함(다항이니까 손실함수는 카테고리크로스엔트로피)
model.summary()
# 서머리를 통해 개요를 볼 수 있는 것도 논시퀀셜의 장점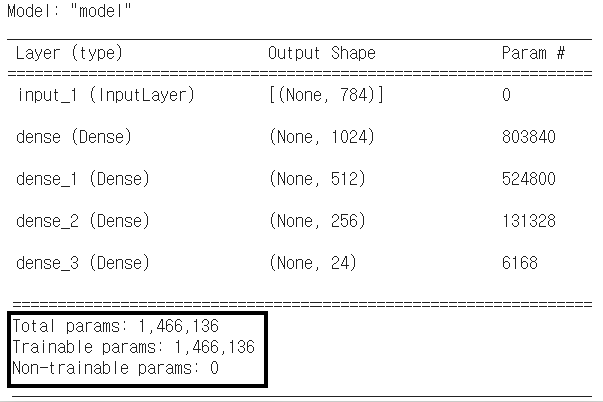
140만개의 웨이트와 바이어스를 학습시킨다
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)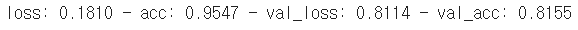
val_acc 81%의 정확도로 인식할 수 있다
# 학습결과 그래프 그리기
# loss는 낮아지는 방향으로 가야함
plt.figure(figsize=(16, 10))
plt.plot(history.history['loss']) #파란색
plt.plot(history.history['val_loss']) #주황색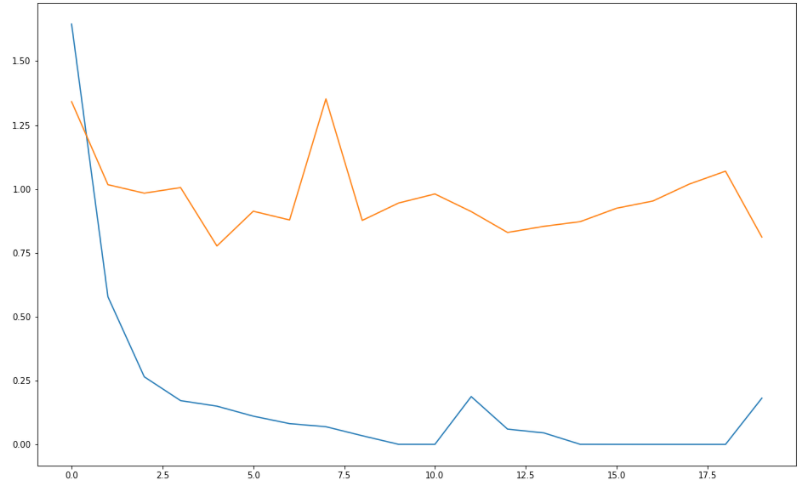
# acc은 높아지는 방향으로 가야함
plt.figure(figsize=(16, 10))
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])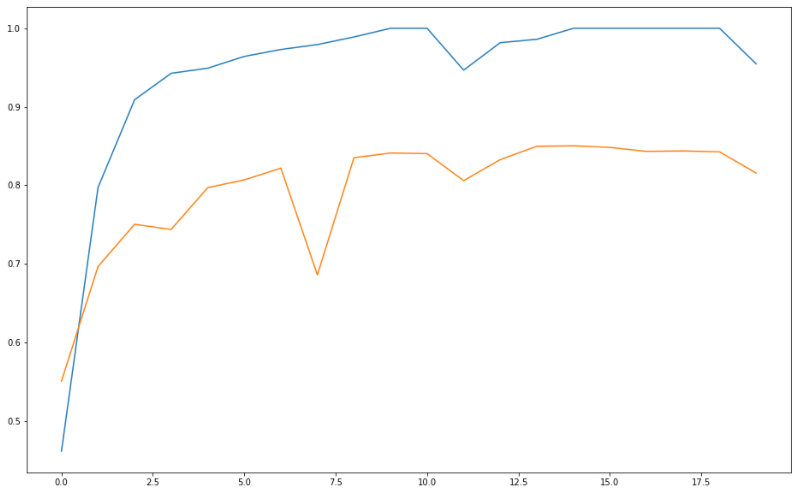
🤖 3주차 숙제
- 라벨 분포 확인하기(각 라벨별로 갯수가 비슷비슷하게 있어야 학습하기 좋다)
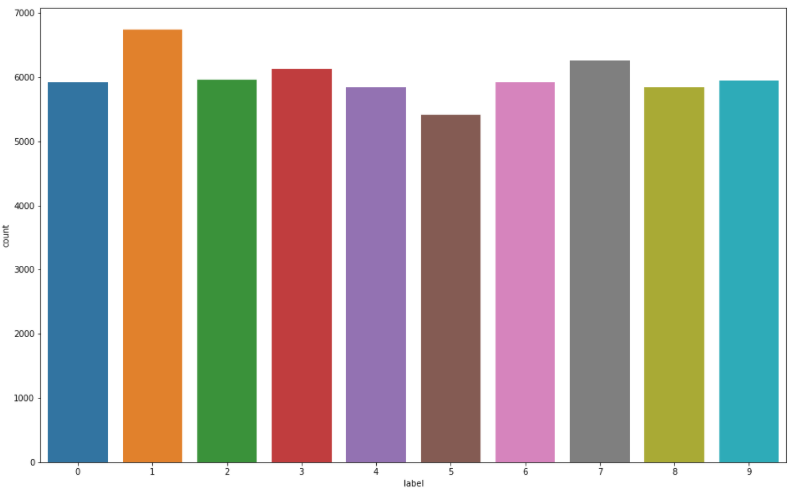
- 다른 부분은 다 실습 예제랑 같고 네트워크 구성할 때 출력 값만 10개로 변경해주면 됨
input = Input(shape=(784,))
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(10, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()-
로스 그래프
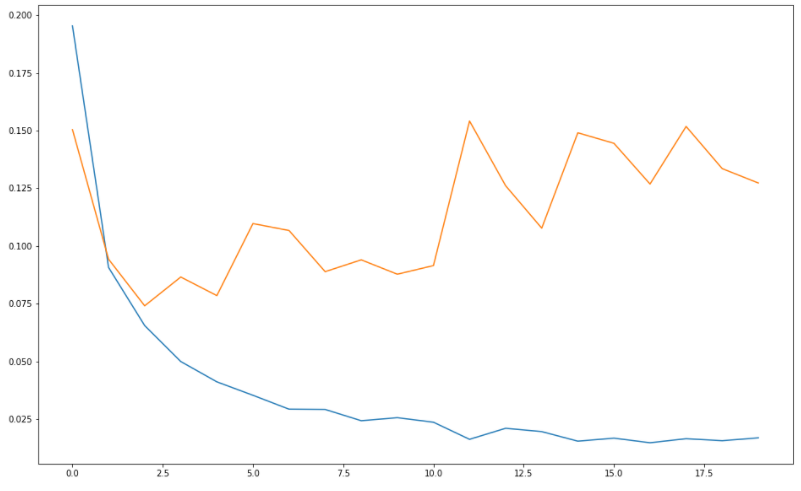
-
어큐러씨 그래프
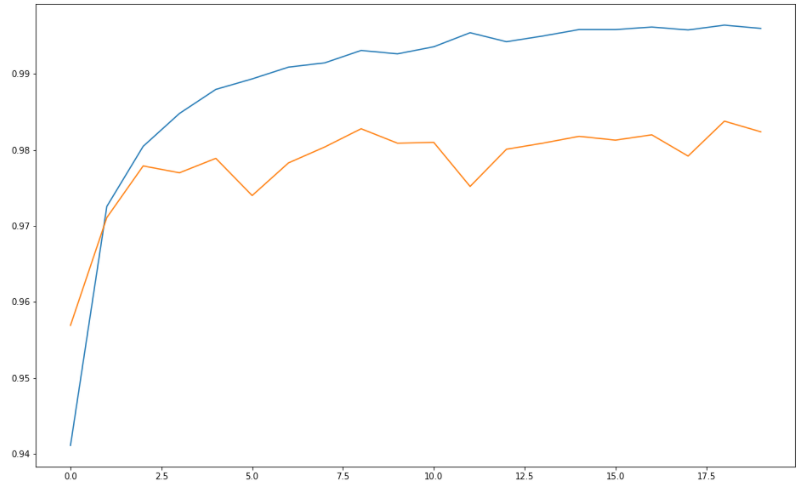
❓ 근데 왜인지 정확도나 그래프 모양이나 이런게 조금씩 다 다르다
모델 써머리에서도 값은 다 같은데 왜 모델이 model_1 이렇게 뜨지??
