너무 깊은 내용은 다루지 않습니다.
💡 선형 회귀
만약 아이스크림을 판매하는데 있어 판매량에 미치는 요인들을 식으로 나타낸다고 하자.
- 온도, 습도, 광고횟수 등의 요인들이 있다.
판매량 = 5*온도 - 8*습도 + 20*광고횟수 + 4이라고 나타낼 수 있다.
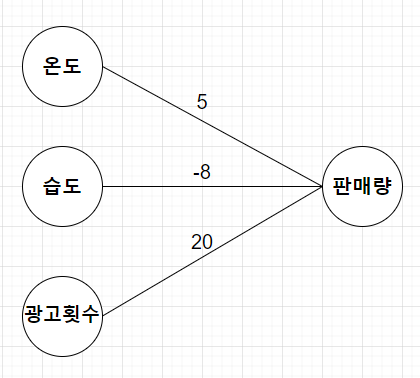
- 식은 이렇게 노드로 표현할 수 있다.
- 온도, 습도, 광고횟수는 x1, x2, x3의 변수로 나타낼 수 있다.
- 5, -8, 20은 가중치로 표현할 수 있다.
- 판매량은 종속변수. y로 나타낼 수 있다.
> y = w1x1 + w2x2 + w3x3 + w0
이것을 코드로 나타내면
model = keras.models.Sequential()
model.add(keras.layers.Input(shape = (3,)))
model.add(keras.layers.Dense(1))위 처럼 작성할 수 있다.
- shape = (3, )이라는 뜻은, 입력 노드로 3개의 변수를 넣겠다는 의미이다.
- Dense(1)이라는 뜻은, 출력 결과를 한 갈래로 표현할 수 있다는 뜻이다.
Dense는 keras에서 제공하는 Fully Connected Layer를 구현한 레이어 모듈이다!
전체 코드로 나타내보자.
자료는 아래 링크를 참고하였습니다.
import numpy as np
num_points = 1000
vectors_set = []
for i in xrange(num_points):
x1= np.random.normal(0.0, 0.55)
y1= x1 * 0.1 + 0.3 + np.random.normal(0.0, 0.03)
vectors_set.append([x1, y1])
x_data = [v[0] for v in vectors_set]
y_data = [v[1] for v in vectors_set]위 코드는 아래와 같은 그래프를 그립니다.
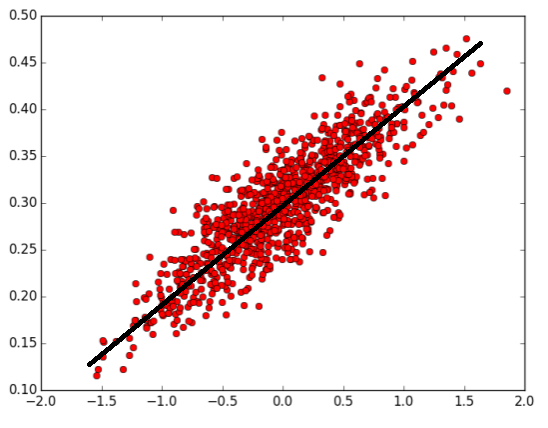
- 상관관계가 보이시나요? y = ax + b 직선을 그릴 수 있을 것 같습니다!
- 선형회귀란, 모든 변수와의 관계를 잘 표현할 수 있는 기울기의 가중치를 찾아가는 과정입니다.
회귀 문제는 변수들이 주어졌을 때, y값을 예측합니다.
💡 로지스틱 회귀
로지스틱 회귀는 분류 문제를 해결할 때 주로 사용합니다.
활성함수로는 Sigmoid가 있습니다.
- Sigmoid 란 ?
회귀로 도출된 결과는 값이기 때문에 분류를 할 수 없습니다.
그러므로 0 or 1로 결과값을 도출해내기 위해선 값을 확률로 바꿔주어야 합니다.
Sigmoid는 값을 확률로 나타내주는 활성화 함수입니다.
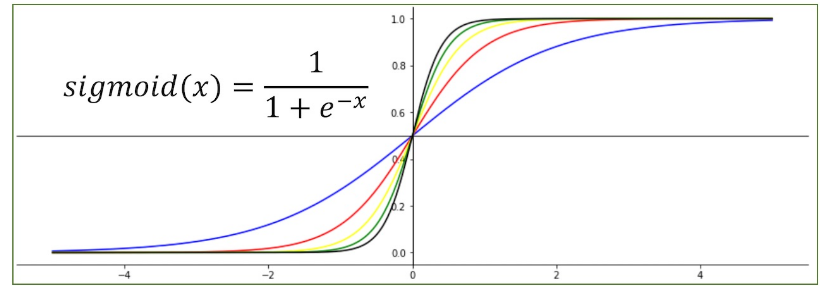
그래프에서 보시는 것 처럼, Sigmoid 함수는 모든 실수 입력 값을 0보다 크고 1보다 작은 미분 가능한 수로 변환하는 특징을 갖습니다.
- 손실 함수로는 binary_crossentropy를 사용합니다.
이진 분류에서 주로 사용됩니다.
해당 데이터에 대한 정답이 1 과 0 중 하나라면 1 일 확률이 출력되고,
해당 확률이 0.5 이상이면, 1 로 판단합니다.
하지만 Sigmoid, binary_crossentropy로는 이진 분류밖에 하지 못합니다.
멀티 클래스 분류를 하기 위해선 다른 방법을 찾아야 합니다.
🧨 코드
model.add(keras.layers.Input(3, ))
model.add(keras.layers.Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', metrics = ['accuracy'], optimizer = 'adam')위 아이스크림 판매량 예제에서 판매량을 구매여부로 변경할 수 있습니다.
이 때, 구매가 1,구매하지 않음이 0 입니다.
- 입력 Layer는 똑같이 shape(3, )을 가집니다.
- 이전 예제의 Dense와 다른 점이 보이시나요? activation = 'sigmoid'가 추가되었습니다!
- 또한 분류 문제이기 때문에 score를 accuracy로 지정했습니다.
💡 멀티 클래스 분류
멀티 클래스 분류를 하기 위해서 Softmax 활성화 함수와 Categorical_crossentropy를 손실 함수로 사용합니다!
- Softmax는 입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화 과정을 거칩니다.
출력 값들의 총합은 항상 1이 되는 특징을 가집니다.
-
label(y, target)값이 one-hot 벡터인 경우 사용 가능합니다.
알파벳 a, b, c는 one-hot 벡터로 나타낼 수 있습니다.
a = [1, 0, 0]
b = [0, 1, 0]
c = [0, 0, 1]
위와 같은 형태의 벡터를 one-hot 벡터라고 부릅니다. -
여러 개(3개 이상)의 결과값에서 가장 확률이 높은 클래스를 고르는 것입니다.
- a, b, c 세 개중 확률이 가장 높은 클래스를 선택하는 과정을 거칩니다.
model = keras.models.Sequential()
model.add(keras.layers.Input(4,))
model.add(keras.layers.Dense(3, activation = 'softmax'))- 만약 네 개의 변수를 갖고, 세 종류의 분류 결과값을 갖는 모델이 있다고 한다면, 위 코드와 같이 나타낼 수 있습니다.
model.compile(loss = 'categorical_crossentropy', metrics = ['accuracy'], optimizer = 'adam')-
categorical_crossentropy를 손실함수로 사용하며, score, optimizer는 이전 예제와 동일합니다.
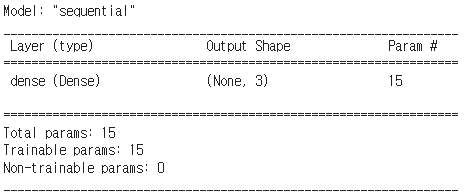
-
위 모델의 parameter 개수를 본다면 15개임을 확인할 수 있습니다.
-
Dense를 사용했기 때문에 Fully Connected Layer입니다.
- 이는 곧 모든 노드가 연결되어 있다는 뜻입니다.
- 이 때, 연결된 모든 간선을 parammeter라고 합니다!
- 모든 노드가 연결되어 있기 때문에 3 * 4 = 12개의 parameter를 가집니다.
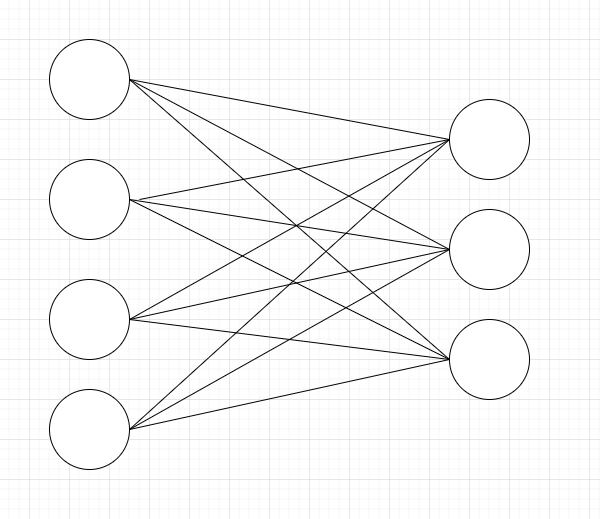
-
위 그림처럼 모든 노드가 연결되어 있는 레이어를 Fully Connected Layer라고 부릅니다.
- 근데 왜 15개일까요?
바로 bias값이 위 그림에선 생략되어 있기 때문입니다.y = ax + b
- 위 식에서 b는 bias라고 하는 값이며, 입력 값에 영향을 받지 않습니다. 이 bias 값 또한 출력 노드에 fully하게 연결되어 있기 때문에 parameter 값이 3개가 증가한 것입니다.
- 근데 왜 15개일까요?
💡 결론
수학적 부분을 다 제외하고 쉽게 설명하고 싶어 중간중간 생략된 부분이 많습니다.
양해 부탁드리겠습니다 ㅜㅜ
